

技术干货 | 详解 MongoDB 中的 null 性能问题及应对方法
source link: https://mongoing.com/archives/82867
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

详解 MongoDB 中的 null 性能问题及应对方法

【背景】
在使用 Oracle、MySQL 以及 MongoDB 数据库时,其中查询时经常遇到 null 的性能问题,例如 Oracle 的索引中不记录全是 null 的记录,MongoDB 中默认索引中会记录全是 null 的文档,MongoDB 查询等于 null 时,表示索引字段对应值是 null 同时还包括字段不存在的文档。因为 MongoDB 是动态模式,允许每一行的字段都不一样,例如记录 1 中包括包括字段 A 等于 1,记录 2 包括字段 A 等于 null,记录 3 不包括字段 A,那么索引中不仅会包括 A 等于 null 的文档,同时也记录不包括 A 字段的文档,同样会赋予 null 值(空数组属于特殊的)。正是由于这些设计规则不同,难免在使用过程中遇到各种性能问题。常见查询包括统计 null 总数以及对应明细数据。其中以汇总统计为例:
- db.xiaoxu.count({fld4:null})
- db.xiaoxu.count({fld4:{$ne:null})
- db.xiaoxu.count({fld4:{$in:[1,2,null]}})
疑问:对于以上三个查询语句,大家可以先思考下能不能用上索引,如能用上索引会是什么样执行计划,例如 IXSCAN+FETCH,是否有优化空间?接下来我们会重点分析这些问题点,也欢迎大家提出自己的看法以及实际环境遇到的相关性能问题。
备注:当前是基于 4.4 版本来验证与测试。同时在集合 xiaoxu 上 fld4 字段存在正常索引{a:1},包括用到 5.0 以及 6.0 版本来解决性能问题(安装与升级不在本次中)。另外索引不是 multikey。
性能问题之查询单个 null 值总数
1. 具体语句以及执行效率
db.xiaoxu.count()
54528512
db.xiaoxu.count({fld4:null})
550000
db.xiaoxu.explain("executionStats").count({fld4:null}).
executionStats.executionTimeMillis
900ms
从以上查询结果来看,null 占比 1%,整个集合 5400 万,如集合总数以及 null 呈现 N 倍数量级上升。例如 null 到500万,预计查询时间至少在 10s。
2. 分析具体的执行计划
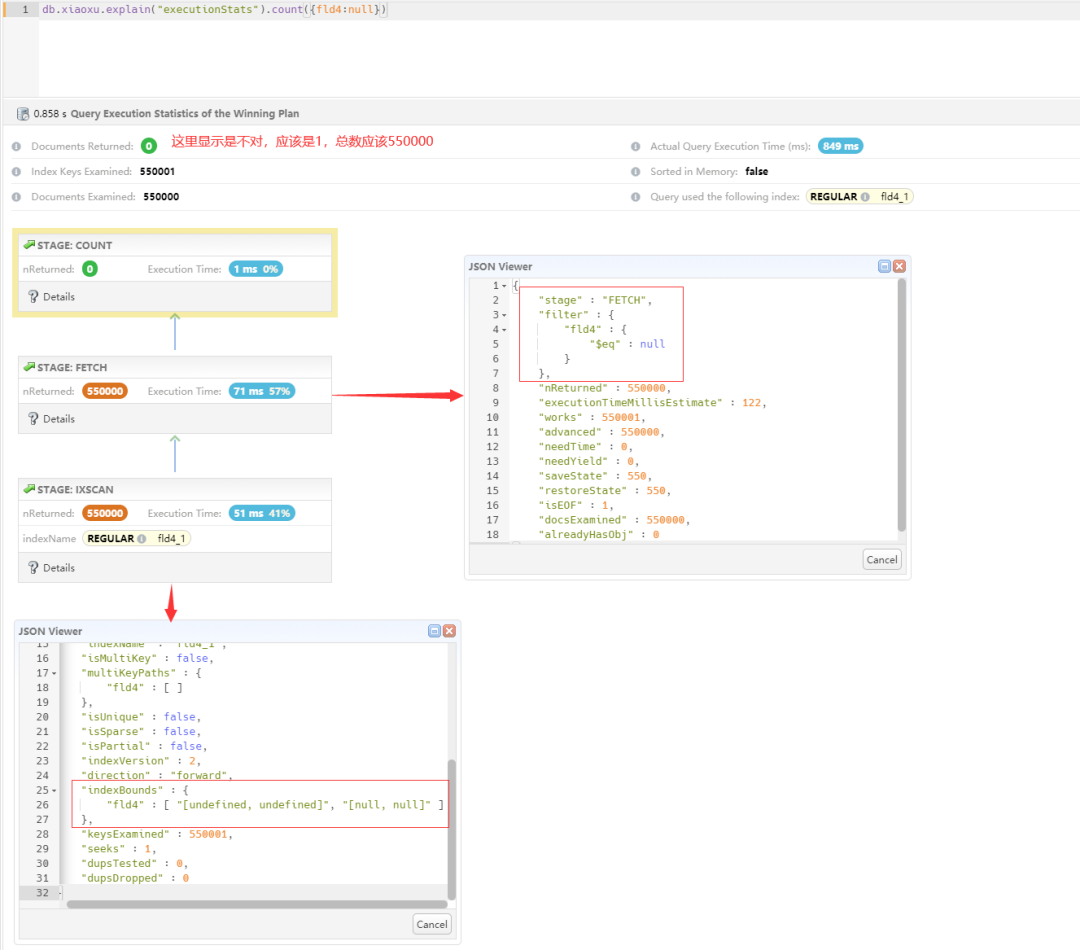
其中 IXSCAN + FETCH + FILTER + COUNT,消耗时间主要消耗在 FETCH + FILTER,IXSCAN 预估消耗才 58ms,占比不到 10%,说明 MongoDB 中查询 null 能够用上索引,需要关注效率问题。
关键点:回表并没有过滤掉什么记录,都是满足记录,为什么不能使用覆盖查询来进行统计?如果是索引覆盖查询,直接采用 COUNT_SCAN 即可,如果把 null 换成其他常量是否可以?
3. 查询等值字符串总数
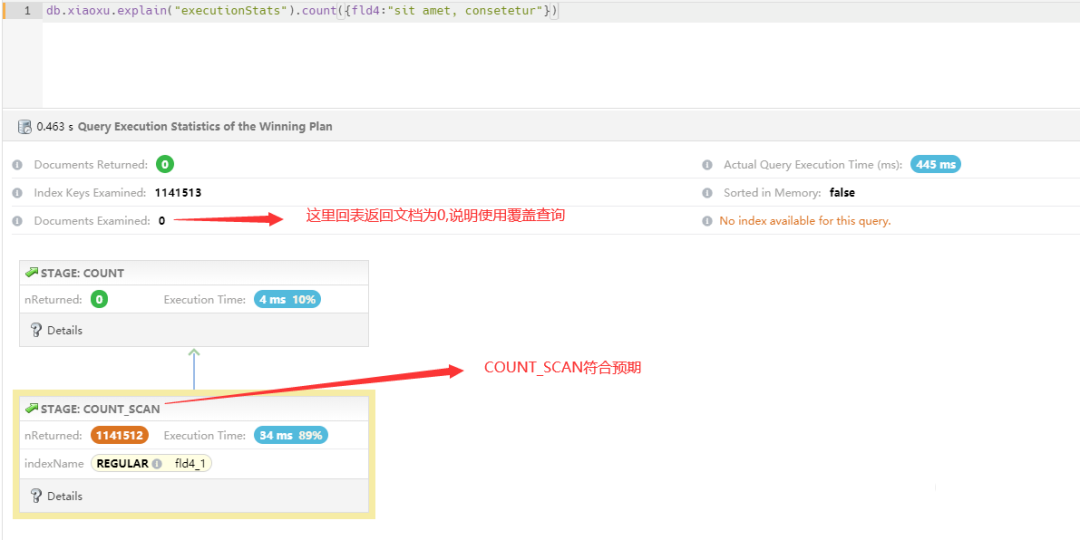
db.xiaoxu.explain("executionStats").count({fld4:"sit"})
经过验证:
查询非空等值汇总时,执行计划走的是覆盖查询,直接 COUNT_SCAN,并没有出现回表 FETCH 以及 FILTER 操作,符合预期行为,而且有 114 万满足条件只需要 445ms,比查询 55 万 null 值还快 500ms。
4. 问题思考
① 查询等于 null 为什么不能使用覆盖查询?需进行 FETCH + FILTER,对于存在少量满足 null 情况的过滤对性能影响小,如随着集合总数以及 null 呈现 N 倍数据量上升,此时进行 FETCH + FILTER 对性能影响非常大。
② 对于查询 null,能否给这些字段赋予默认值,不用 null,使用其他默认值来替代,避免去检查字段值等于 null 或者字段不存在的情况?这种虽然可行,需要提前设计就得考虑进去,另外本身就是动态模式,这样限制它的灵活性,特定场景下是可以使用,例如模式是固定的,或者从关系型数据库改造到 MongoDB。
5. 性能优化思路
针对上述优化方案,第二条虽然可以,但需要前期参与以及牺牲一定灵活性,所以重点考虑问题点①:
① 是否可以采用部分索引
这与 exists:true 不同,fld4:null 可以直接定位到数据,已经实现与部分索引相同的作用,其中都需要回表进行过滤,无法实现覆盖查询。
主要性能在于回表过滤,理论上都满足覆盖查询条件,经过检索 MongoDB Jira 发现,这是由于老的索引格式造成。从 4.9 版本开始,重新设计索引格式,只要索引是非 multikey,查询等于 null 可以使用覆盖查询;对于 multikey 索引,至少 6.0 还是不行。
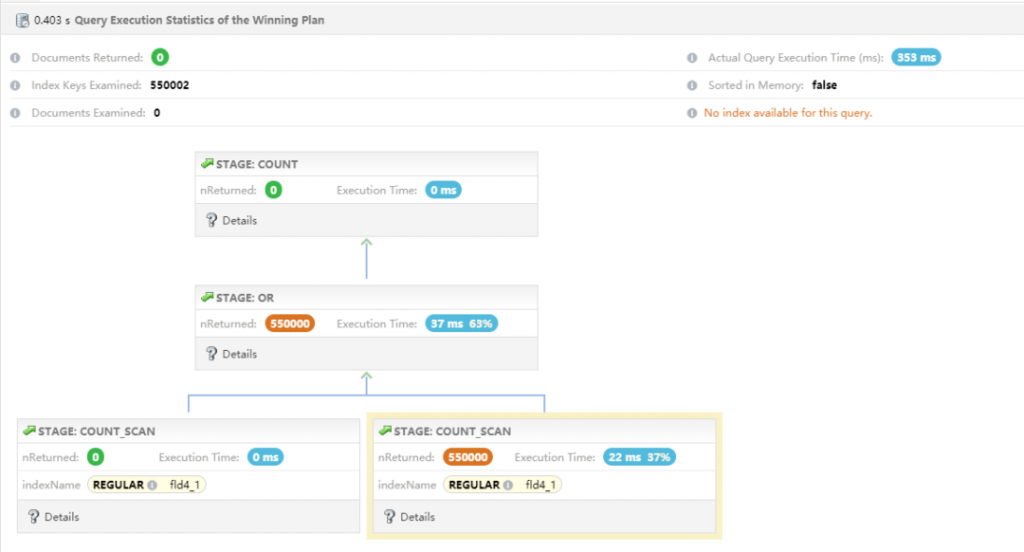
② 升级到 5.0 版本验证下能否实现覆盖查询
备注:升级 5.0 后使用覆盖查询,性能明细提升,响应时间从 900ms 下降到 384ms,性能明显提升。第一个性能问题通过升级完美解决,至于赋予默认值方式也可以解决。
db.xiaoxu.explain("executionStats").count({fld4:null}).executionStats
{
"executionSuccess" : true,
"nReturned" : 0,
"executionTimeMillis" : 384,
"totalKeysExamined" : 550002,
"totalDocsExamined" : 0,
"executionStages" : {
"stage" : "COUNT",
"nReturned" : 0,
"executionTimeMillisEstimate" : 59,
"works" : 550002,
"advanced" : 0,
"needTime" : 550001,
"needYield" : 0,
"saveState" : 550,
"restoreState" : 550,
"isEOF" : 1,
"nCounted" : 550000,
"nSkipped" : 0,
"inputStage" : {
"stage" : "OR",
"nReturned" : 550000,
"executionTimeMillisEstimate" : 59,
"works" : 550002,
"advanced" : 550000,
"needTime" : 1,
"needYield" : 0,
"saveState" : 550,
"restoreState" : 550,
"isEOF" : 1,
"dupsTested" : 550000,
"dupsDropped" : 0,
"inputStages" : [
{
"stage" : "COUNT_SCAN",
"nReturned" : 0,
"executionTimeMillisEstimate" : 0,
"works" : 1,
"advanced" : 0,
"needTime" : 0,
"needYield" : 0,
"saveState" : 550,
"restoreState" : 550,
"isEOF" : 1,
"keysExamined" : 1,
"keyPattern" : {
"fld4" : 1
},
"indexName" : "fld4_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"fld4" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"indexBounds" : {
"startKey" : {
"fld4" : undefined
},
"startKeyInclusive" : true,
"endKey" : {
"fld4" : undefined
},
"endKeyInclusive" : true
}
},
{
"stage" : "COUNT_SCAN",
"nReturned" : 550000,
"executionTimeMillisEstimate" : 19,
"works" : 550001,
"advanced" : 550000,
"needTime" : 0,
"needYield" : 0,
"saveState" : 550,
"restoreState" : 550,
"isEOF" : 1,
"keysExamined" : 550001,
"keyPattern" : {
"fld4" : 1
},
"indexName" : "fld4_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"fld4" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"indexBounds" : {
"startKey" : {
"fld4" : null
},
"startKeyInclusive" : true,
"endKey" : {
"fld4" : null
},
"endKeyInclusive" : true
性能问题之查询单个不等于 null 值总数
具体 SQL
db.xiaoxu.count({fld4:{$ne:null})
备注:对于查询不等于 null 的情况,从 4.2 版本就支持覆盖查询。通常情况下,不等于 null 数据非常大,此时查询速度无法保证,大部分场景下性能都存在瓶颈。这个例子中 5300 万耗时是 38s,这个相对简单些,需要 MongoDB 4.2 版本才支持索引覆盖查询。
场景:适合不等于值少的,否则虽能使用覆盖查询,但对于大集合还是消耗时间。

性能问题之查询组合 null 与其他等值总数
1. 查询语句以及问题
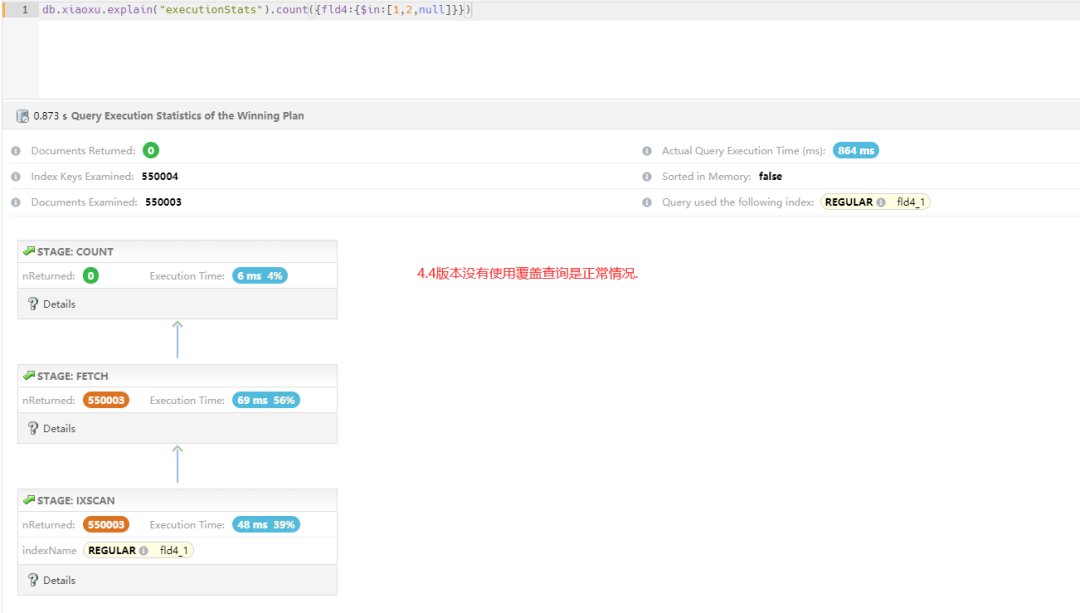
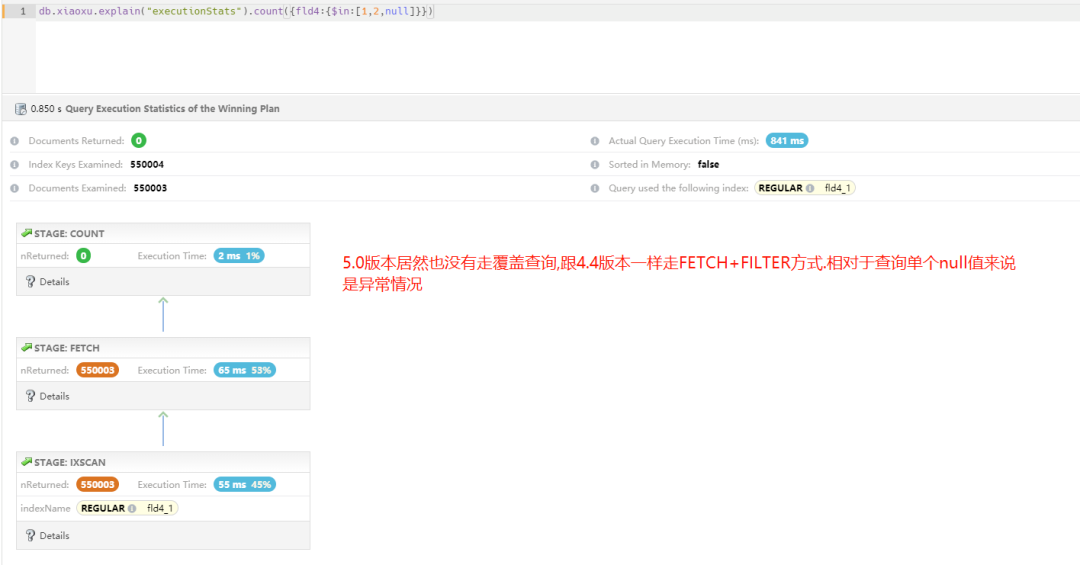
db.xiaoxu.count({fld4:{$in:[1,2,null]}})
550003
备注:4.4 版本执行计划——没有走覆盖索引,依据第一个案例中,这属于正常。
问题来了
5.0 版本执行计划——居然还没有走覆盖索引,根据第一个案例中提到升级 5.0 可以走覆盖查询,组合查询失效。
2. 问题思考
① 5.0 版本为什么查询单个 null 值或者其他非 null 等值组合查询时,可以使用覆盖查询,与 null 值组合到一起后不能使用覆盖查询?
② 5.0 版本中所有值都进行回表过滤,执行计划与 4.4 版本单个等值 null 相同,5.0 版本优化是对 null 进行拆分多个 OR 然后合并?当 null 与非 null 组合出现,拆分成多个 OR 场景并没有出现?——这个是我们的机会。
3. 如何进行优化
如遇到上面的性能问题,5.0 也无法解决,考虑如下 2 个思路:
① 能否继续升级到 6.0 版本——对于生产环境需要从多个角度进行考虑,这里只是验证能否解决性能问题。
② 如果已经是 5.0 版本,能否手动改写 SQL 来调优?(搞 MongoDB 这么久,第一次尝试 SQL 改写来进行优化)
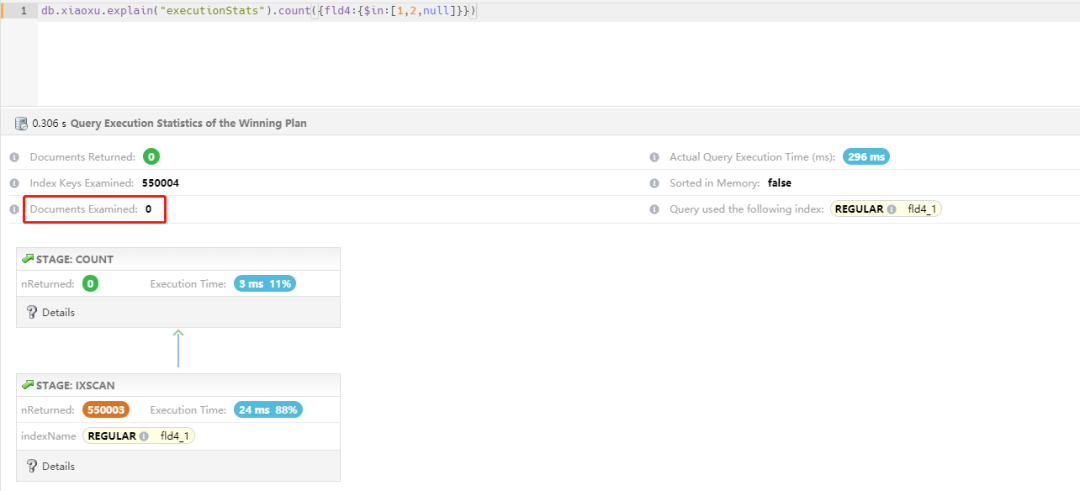
4. 方案1:升级到 6.0 来验证
db.serverStatus().version; 6.0.0-rc8
重点:升级到 6.0 版本发现组合查询使用覆盖查询,查询时间是 300ms,从 850ms 下降到 300ms,提升性能明显。这个只是作为技术验证方案,是否升级需要看实际情况,如果新选型,通常建议选择新版本带来的红利,同时也要忍受一定的 BUG。
5. 方案2:5.0 中改写 SQL 进行优化
改写原因:
① 为什么会想到 SQL 改写,主要受到 5.0 中 null 优化思路影响,在 5.0 中把 null 查询拆分成 2 个 OR,一个是查询 null,一个是查询 undefined,最终合并。
② 在使用 Oracle、MySQL 时由于优化器不足或者设计问题,导致在当前版本需要手动改写 SQL 来进行性能优化或者升级新版本来解决(升级版本已尝到甜头)。
改写要点:
① 用到 unionWith 聚合管道,相当于关系型数据库中 union all,注意不是 union,unionWith 是 4.4 版本新功能。在改写过程中遇到一个诡异的事情——主要研究这个如何改写。
② 在应用端进行拆分,然后应用端进行汇总(需要在应用端修改实现,这里不讨论),因为 5.0 中单个 null 已提升性能。
使用 unionWith 进行改写:
【原始SQL】
db.xiaoxu.count({fld4:{$in:[1,2,null]}})
550003
【改写后SQL】
db.xiaoxu.aggregate([
{$match: {fld4: null}},
{$group: {_id: '$fld4',total: {$sum: 1}}},
{
$unionWith: {coll: 'xiaoxu',
pipeline: [
{$match: {fld4: {$in: [1,2]}}},
{$group: {_id: '$fld4',total: {$sum: 1}}}]}},
{$group: {_id: null,total: {$sum: '$total'}}}])
{ "_id" : null, "total" : 550003 }
问题:发现改写后,依然存在 FETCH 阶段,并没有达到预期覆盖查询,问题点在哪里?
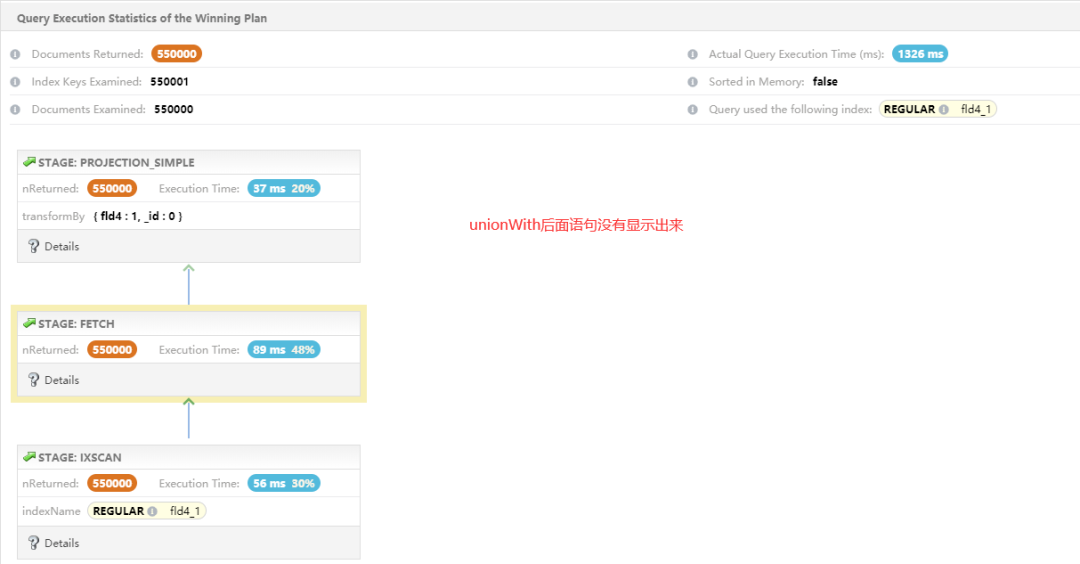
区别:前后二者区别在于 FETCH + PROJECTTION_SIMPLE 以及 PROJECTION_COVERED。那么如果 null 这部分也能实现 PROJECTION_COVERED,那么问题迎刃而解。问题来了:投影是怎么产生的?

【投影如何产生】
拆解下 $match + $group 2个管道组成,那么产生投影就是 $group 作用。对应 SQL: $group:{_id:”$fld4″,total:{$sum:1}},其实求总数,是不需要按列汇总统计,这里应该按照 null 进行聚合。为什么 $in:[1,2] 可以投影覆盖,而 null 不能投影覆盖(有朋友知道可以告知下),具体原因不得而知,如果按照语义来修改成 $group:{_id:null,total:{$sum:1}} 等价于 select count(*) from where a is null
【按照语义来改写语句】
db.xiaoxu.aggregate([
{$match: {fld4: null}},
{$group: {_id: null,total: {$sum: 1}}},
{
$unionWith: {coll: 'xiaoxu',
pipeline: [
{$match: {fld4: {$in: [1,2]}}},
{$group: {_id: null,total: {$sum: 1}}}]}},
{$group: {_id: null,total: {$sum: '$total'}}}])
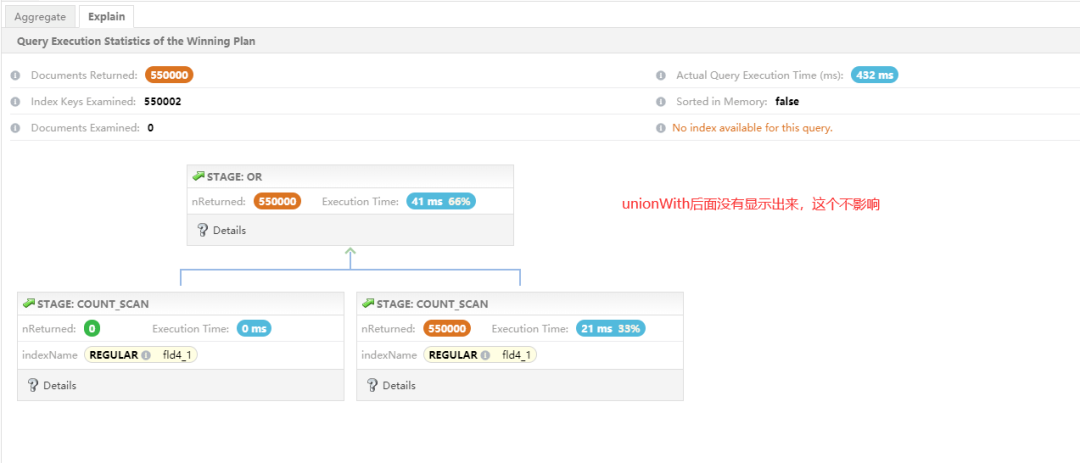
[ { _id: null, total: 550003 } ]
经过改写后,执行时间从 1326ms 下降到 432ms,性能提升 70%。相比 6.0 版本,执行效率要稍微差一点,新版本红利。
总结
1. 对于查询汇总单个 null 值总数,4.9 版本开始(5.0 版本)索引可以实现覆盖查询来解决 FETCH + FILTER 造成性能问题,表越大以及 null 越多效果越明显。4.9 之前版本没有太好的办法,只能在程序设计考虑使用默认值来替代 null。
2. 对于查询汇总组合 null 与其他等值总数,6.0 版本可以完美使用索引实现覆盖查询来解决 FETCH + FILTER 造成性能问题,5.0 版本需要使用 unionWith 改成或者在应用端拆分多个 count 来累加。其实这个改写在 MongoDB 尝试过一次失败了,主要是由单纯 count 与分组聚合 count 的语义理解偏差导致,这次也是偶然发现。
关于作者:
徐靖,数据库工程师,具有丰富的数据库运维经验,精通数据库性能优化及故障诊断,目前专注于MongoDB数据库运维与技术支持,同时也是公众号《DB说》维护者,喜欢研究与分享数据库相关技术。希望能够为社区贡献一份力量。
Recommend
-
4
干货!万亿级数据库MongoDB集群性能优化实践合辑(上) | MongoDB中文社区本文来自OPPO文档数据库mongodb负责人杨亚洲老师2020年深圳Qcon全球软件开发大会《专题:现代数据架构》专场、dbaplus专场:万亿级数据库MongoDB集群性能优化实践、mongodb2020年终盛会...
-
6
技术干货| 如何在MongoDB中轻松使用GridFS? GridFS是用于存储和检索超过16 MB
-
3
技术干货| MongoDB如何查询Null或不存在的字段? 在MongoDB中不同的查询操作符对于null值处理方式不同。 本文提供了使用mongo shell中的
-
8
技术干货| MongoDB时间序列集合 名词解释Glossary
-
2
技术干货| MongoDB 事务原理 MongoDB 作为领先的 NoSQL ,为了支撑更多的需求场景,也在不断完善其功能。从早期支持大吞吐量读/写操作的 MMAPv1 存储引擎,到引入支持高并发操作的 WiredTiger 存储引擎,以及对事务功能的...
-
4
技术干货| 一文读懂如何查询 MongoDB 文档 一.查询文档 本段提供了使用 m...
-
2
技术干货| 如何运用 MongoDB 部分索引优化性能问题? 背 景 最近研发提交业务需求,大概逻辑就是先统计总...
-
9
linux性能调优干货,【干货分享】详解Linux性能调优之tuned特性 | Lenix Blog uned简介 对普通用户而言,Linux应用环境优化是比较困难的。领域多,范围广...
-
7
如何利用 MongoDB Change Streams 实现数据实时同步? 当前实时数据同步的应用场景较多,实现方式主要有两种,一是数据库厂家本身提供了实时数据捕获工具,如 Oracle 的 OGG 等;另外一种是实时解析数据库的事务日...
-
2
纯干货|从“双12”到年终大促,看 CDN/DCDN/GA 技术如何应对流量洪峰 字节跳动技术团队 ...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK