

注意看,她叫小美,在地址栏输入URL地址后发生了什么? - 安木夕
source link: https://www.cnblogs.com/anding/p/16987528.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


注意看,这个用户叫小美,他在地址栏输入了一串URL地址,然后竟然发生了不可思议的事情!
01、输入URL发生了什么?
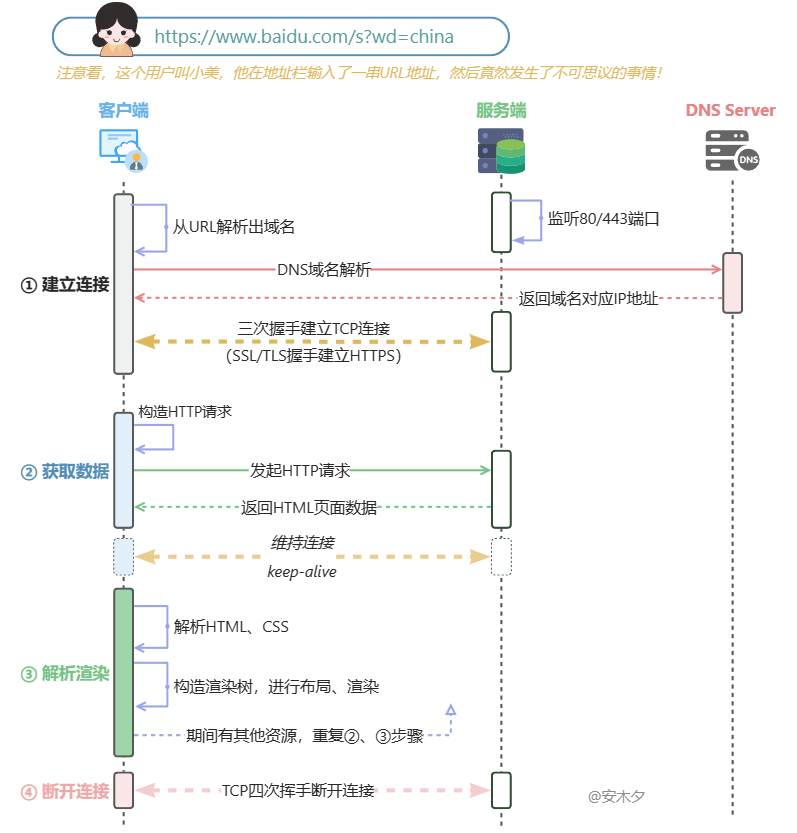
从输入URL开始,到页面呈现出来,简单来说分为四个步骤:

- ① 建立连接:建立与服务器的网络通信连接,为正式数据传输做准备。
- 🔸DNS域名解析:首先是取出URL中的域名,通过DNS域名解析获得到对应IP地址,计算机的TCP连接是基于IP地址的,域名只是给用户看的。
- 🔸建立TCP连接:HTTP连接是建立在TCP协议之上的,其数据传输功能是由TCP完成的。用上面获得IP地址,建立TCP连接:①请求🤝🏻 ➤ ②确认🤝🏻 ➤ ③建立连接🤝🏻,对,就是著名的三次握手🤝🏻。关于HTTP协议及连接过程可看上一篇 HTTP协议图文简述。
- 如果是HTTPS连接,还需要多一步,进行SSL/TLS握手,建立加密通信机制。
- ② 获取数据:向服务端发送HTTP请求获取网页数据。
- 🔸发送HTTP请求:构造HTTP报文:请求头部
header+ 请求包体body,然后发送HTTP请求。 - 🔸服务端响应:服务器监听80、443端口,当收到客户端的请求后响应处理,把HTML网页数据放在HTTP报文的包体
body中,返回给客户端。
- 🔸发送HTTP请求:构造HTTP报文:请求头部
- ③ 解析渲染:客户端解析服务端返回的HTML网页内容,并进行渲染,最终呈现给用户。
- 🔸在解析过程中如果还有其他资源(如图片、JS、CSS),会继续构造相应的HTTP请求,重复步②、③骤获取数据、解析渲染。如果资源来自其他域名,则还需先经过步骤①建立连接。
- ④ 断开连接:完成页面的所有请求后,发起 TCP 四次挥手,断开连接。
✍️画个时序图吧!
02、URL地址的构成?
URL(Uniform Resource Locator)统一资源定位符,用来标识网络上的唯一资源的地址,就是俗称的 网址。
🪧URL格式:
scheme://domain[:port][/path/.../][file][?query][#anchor]
主要包含以下几个部分:
- 协议(schema):网络服务的类型,http、https等。
- 域名(domain):或主机名,一般域名为
www.taobao.com,也可以为IP地址(60.191.55.43)。 - 端口号(port):主机的端口号,HTTP=80,HTTPS=443,默认端口号可省略。
- 网站的资源地址:属于网站内部的内容地址,包括多个部分:
- 资源路径:网站根目录下的子目录(path)+资源名称(filename)。
- 参数(?query):问号"
?"后面的key=value&...结构的参数,用于服务器查询。 - 锚点(#anchor):网址最后
#开头的部分,网页内部定位,在浏览器端使用,服务端不会管。

🔸URL常见协议:
- http:超文本传输协议访问远程网络资源,
https为安全版本的http。 - file:访问本地计算机资源。
- maito:访问电子邮箱地址。
- ftp:访问远程FTP服务器上的文件资源,默认端口21。
03、建立连接
3.1、DNS域名解析
DNS 域名解析系统(Domain Name System) 是用来解析域名的(domain name),把域名解析为计算机能够识别的IP 地址(IP address)。
- 域名 面向用户:为了便于人们使用,易于识别、记忆,相当于是对IP地址的装饰,如
www.baidu.com。 - IP地址 面向机器:是网络IP协议提供的逻辑地址,固定长度的数字符号,给机器用的,IPv4 是 32 位,IPv6 是 128 位。
ping www.baidu.com //14.215.177.38
DNS 系统中保存了一张域名、IP 地址的映射表,记录了互联网上所有的域名和IP的数据。但实际的上这张表不是在单一服务器上,他是分布式存储在全球很多地方。所以域名解析的过程,就是在这些分布式的DNS服务器上去检索,直到找到域名对应的IP地址。
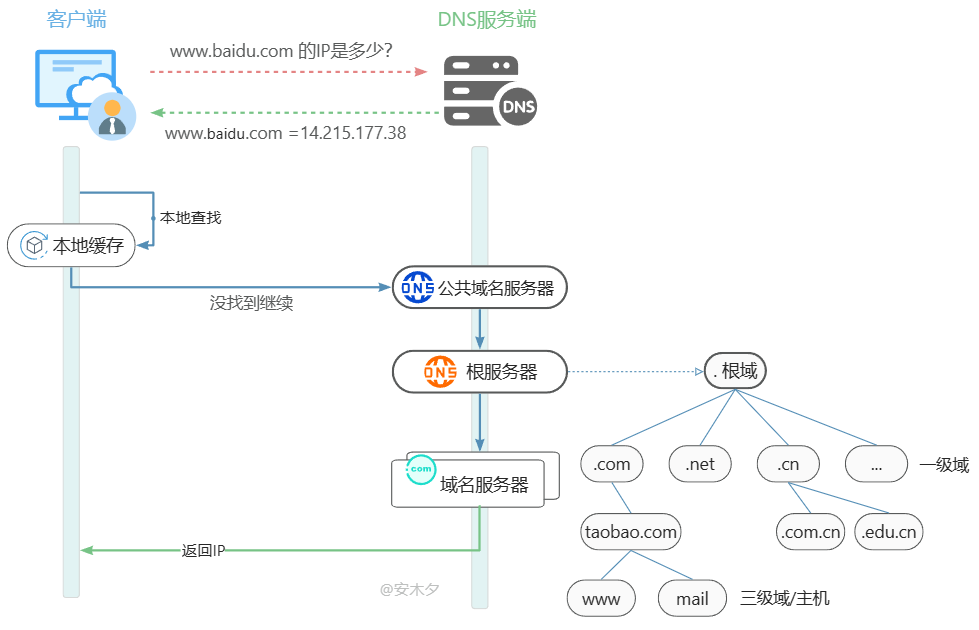
- 🔸本地缓存,如
hosts文件、浏览器的域名缓存、系统域名缓存、路由器缓存。缓存是个好东西,最近解析过的域名会被缓存起来,所以第二次再打开网页更快了,当然这里还有其他原因,如HTTP连接缓存、已下载的资源缓存等。 - 🔸公共域名服务器,一般是网络服务商
ISP(internet server provider )提供的的DNS servers,如如中国电信、中国移动。或本机设置的DNS,如阿里、百度、Google提供的DNS服务器。 - 🔸根服务器:这是整个互联网的核心服务器,属于顶级域名服务器,全球共13台。这里存了所有DNS服务器的索引,在这里查找对应的主域名服务器。
- 🔸域名服务器,如
.com为顶级域名服务器,到该服务器继续查找,如此递归/迭代查询,直到找到对应IP返回给客户端。
📢 DNS 是基于 UDP协议 通信的。
- 在实际网页中,可能有来自多个站点的资源,不仅有自己网站的网页内容,还有A网站的图片、B网站的JS库,C网站的CSS库等,就意味着每一个域名都要先经过DNS查询获取具体的IP地址。
3.2、常用公共DNS服务器
| DNS服务器 | IP地址 |
|---|---|
| 阿里 DNS: | 223.5.5.5 、 223.6.6.6 |
| 百度 DNS: | 180.76.76.76 |
| Google DNS: | 8.8.8.8 、 8.8.4.4 |
| 360 DNS: | 101.226.4.6 、 123.125.81.6 |
| 腾讯云DNS | 183.60.83.19 |
| 114DNS | 114.114.114.114、114.114.115.115 |
3.3、维持连接
完成一次 HTTP 请求后,服务器并不是马上断开与客户端的连接。在 HTTP/1.1 的header中Connection: keep-alive 是默认启用的,表示持久连接,以便后续请求可以复用HTTP连接。实际一个网页往往有多个请求(图片、CSS、JS),后面的请求就不用重新建立网络连接了,从而节约开销,提高加载速度。
但是一直保持TCP连接,是有开销的,特别是大并发场景时的服务端,因此长链接也是有一定限制的,如果长时间都没有请求就关闭了。另外如果一方意外断开了,如浏览器被强制关闭了,服务端也不可能一直等着,这就需要一个保活探测机制,类似心跳来判断对方是否还活着。
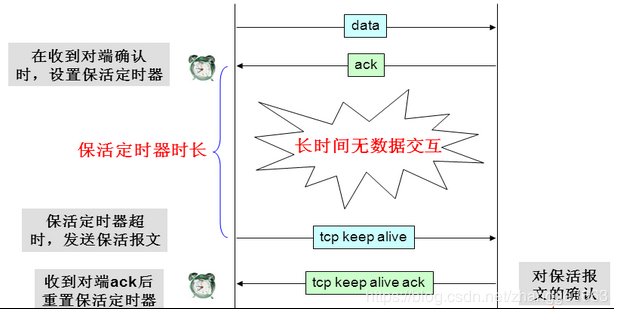
在反向代理软件 Nginx 中,持久连接超时时间默认值为 75 秒,如果 75 秒内没有新到达的请求,则断开与客户端的连接。同时,浏览器每隔 45 秒会向服务器发送 TCP keep-alive 探测包,来判断 TCP 连接状况,如果没有收到 ACK 应答,则主动断开与服务器的连接。
04、请求、响应数据
浏览器构造HTTP报文:请求头部header+请求包体body,然后发送HTTP请求。示例中的“https://www.baidu.com/s?wd=china”请求为GET,参数在URL上,请求头body没有数据。关于HTTP协议及请求、应答过程更多可看上一篇 HTTP协议图文简述。
🪧请求HTTP报文:
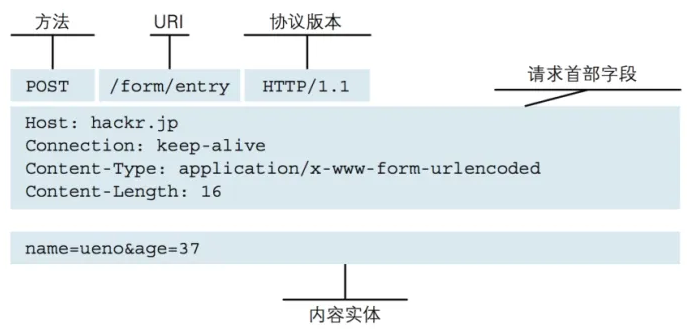
GET /s?wd=china HTTP/1.1Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9Accept-Encoding: gzip, deflate, brAccept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6Connection: keep-aliveHost: www.baidu.comUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.35sec-ch-ua: "Microsoft Edge";v="107", "Chromium";v="107", "Not=A?Brand";v="24"sec-ch-ua-mobile: ?0sec-ch-ua-platform: "Windows"
🪧响应HTTP报文:服务器监听80、443等WEB端口,当监听收到客户端的请求后响应处理,把网页数据放在HTTP报文的包体body中,返回给客户端。服务端的实际处理过程要复杂的多,可能还涉及负载均衡、反向代理、网关、WEB服务器、应用服务器、数据库,及CDN等。
- 如下示例,响应头
header中有些是百度自定义扩展的字段。
HTTP/1.1 200 OKBdpagetype: 3Bdqid: 0xadfe12d00008e897Cache-Control: privateConnection: keep-aliveContent-Encoding: brContent-Type: text/html;charset=utf-8Date: Fri, 25 Nov 2022 09:37:39 GMTServer: BWS/1.1Set-Cookie: delPer=0; path=/; domain=.baidu.comSet-Cookie: BD_CK_SAM=1;path=/Set-Cookie: PSINO=6; domain=.baidu.com; path=/Set-Cookie: BDSVRTM=26; path=/Strict-Transport-Security: max-age=172800Vary: Accept-EncodingX-Frame-Options: sameoriginX-Ua-Compatible: IE=Edge,chrome=1Transfer-Encoding: chunked
- 响应内容:就是HTML字符串内容,共计7084行,这些内容在下一步由浏览器渲染引擎进行解析,并最终渲染展示出来。
<!DOCTYPE html><!--STATUS OK--><html class=""> <head> <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"> <meta http-equiv="content-type" content="text/html;charset=utf-8"> <meta content="always" name="referrer"> <meta name="theme-color" content="#ffffff"> <link rel="shortcut icon" href="/favicon.ico" type="image/x-icon" /> <link rel="icon" sizes="any" mask href="//www.baidu.com/img/baidu_85beaf5496f291521eb75ba38eacbd87.svg"> <link rel="search" type="application/opensearchdescription+xml" href="/content-search.xml" title="百度搜索" /> <title>china_百度搜索</title> </head> <body> </body></html>
05、浏览器解析、渲染
解析服务端返回的HTML网页数据,并进行渲染,这个过程的5个关键步骤:①构建DOM ➤ ②构建CSS规则树 ➤ ③构建渲染树 ➤ ④布局 ➤ ⑤绘制。
✍️画个图大概就是这样:
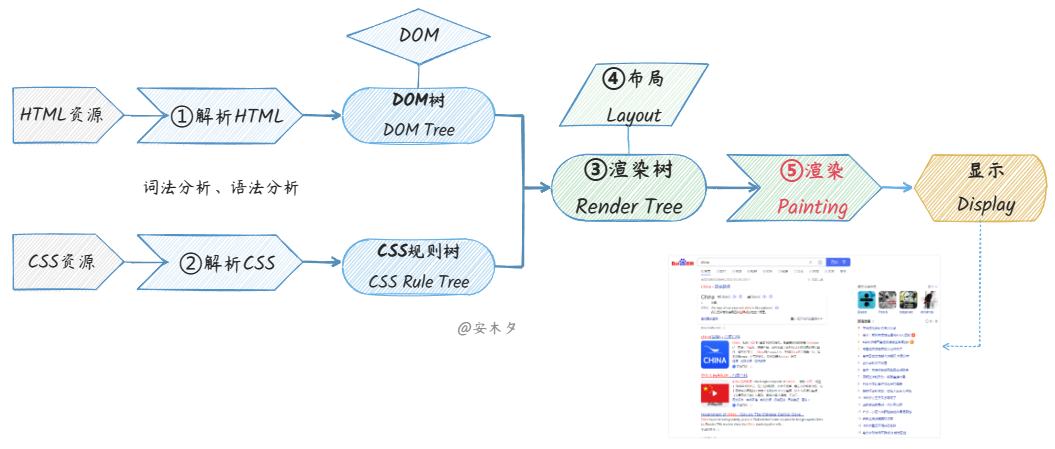
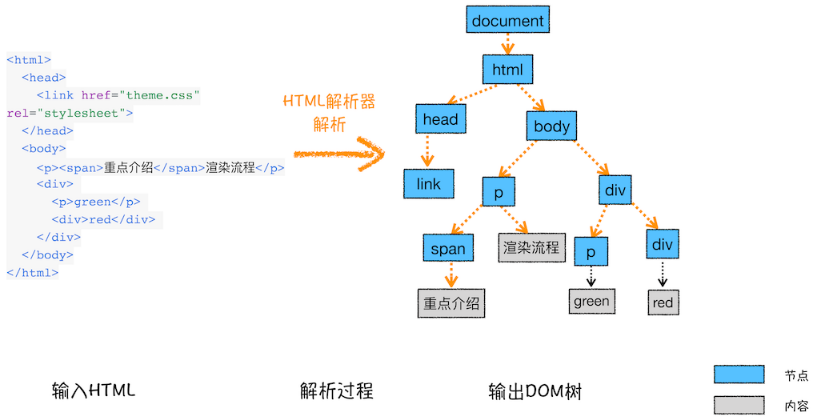
- ① DOM 树:根据 HTML 解析出 DOM 树(DOM Tree)
- 🔸从上往下解析HTML内容,按照标签结构构造DOM树,构建过程采用深度优先遍历,即先构建当前节点的所有子节点,然后才继续下一个兄弟节点。
- 🔸当遇到外部
css链接文件、图片资源时,会异步发起资源请求,不影响HTML解析。 - 🔸解析中如遇到
<script>脚本(没有async、defer),会等待脚本执行完才继续,如果是外部JS文件,还得等JS先下载再执行。这么做的目的是JS代码可能会修改DOM树和CSS样式,避免造成回流和重绘。 - 遇到设置
async和defer的<script>脚本,创建新的线程异步加载,继续解析HTML。async加载完马上执行,defer在DOMContentLoaded前执行。
- ② CSS规则树:根据 CSS 解析生成 CSS 规则树(CSS Rule Tree)
- 🔸对CSS内容进行词法分析、语法分析,解析CSS规则,构建CSS规则树。
- ③ 渲染树:DOM 树 + CSS 规则树,生成 渲染树 (Render Tree)
- 🔸渲染树只包含需要显示的节点,及其样式信息,样式信息是来自CSS规则树的样式规则(CSS Rule)。
- ④ 布局/回流:根据渲染树计算每一个节点的位置的过程,就是布局。
- 🔸布局(Layout):通过渲染树中渲染对象的信息,计算出每一个渲染对象的确切位置和尺寸,就是布局的过程。HTML的布局是自上而下、从左到右流式排列,位置是是会相互影响的,一个元素位置、大小变化会影响整体(其后续)布局,导致回流的发生。布局的开销是比较大的,要尽量避免频繁布局。
- 🔸回流(Reflow):某个部分发生了变化影响了布局,如DOM的新增、删除,某个元素的位置尺寸发生了变化,那就需要倒回去重新布局>渲染。
- ⑤ 渲染:根据计算好的信息绘制页面,通过调用操作系统Native GUI的API绘制,将呈现器的内容显示在屏幕上。
- 🔸重绘(Repaint):某个元素的背景颜色,文字颜色的变化,不影响元素周围或内部布局,不需要重新布局,就需只需要浏览器重绘即可。
06、有什么启示?-优化建议
用户每次上网不就是在干这个事情么,输入网址,等待网页加载,查看网页内容,或者网页加载太慢就咔嚓换一个,就是这么无情。了解从URL输入到页面展现的详细过程,可以更好帮助我们在各个环节去优化我们的WEB页面。
- ① 提高连接速度:
- 🔸尽量合理控制网页中资源的来源,如果来自很多个域名,如第三方、二级域名,每个域名都要DNS解析和建立TCP连接。
- 🔸不过上述方式需要根据实际情况来考虑,过多、过少都不一定就好,还得考虑浏览器的并发请求限制、资源类型、网络环境、终端设备类型、CDN等。
- 🔸DNS预解析,提前解析域名获得IP:
<link rel="dns-prefetch" href="//blog.poetries.top">
- ② 提高资源加载速度:
- 🔸减少请求次数:有些资源可以合并,如小图片,CSS片段等。多利用缓存,本地缓存静态资源。
- 🔸减少资源大小:图片压缩、资源压缩(gzip),减少不必要的资源,按需加载等。
- 🔸启用HTTP2,优化
header,减少请求大小;多路复用,可并行请求响应。 - 🔸预加载与懒加载:预先加载一些需要用到的资源,延后加载一些非必须的资源。
- ③ 提高网页解析、渲染速度:尽量减少回流、重绘。
- 🔸避免频繁操作DOM结构,及改变元素的大小、位置。
- 使用 transform 替代 top、left定位,transform只是DOM节点本身的变换,不影响布局,就不会造成回流。
- 少用table布局,局部的修改会造成整个table的重新布局。
- 将JS放在body的最后面,可以避免资源阻塞,使静态的HTML页面尽快显示。
- 注意防脱,注意远离前端开发...
©️版权申明:版权所有@安木夕,本文内容仅供学习,欢迎指正、交流,转载请注明出处!原文编辑地址-语雀
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK