

Why do you need ontology in your company?
source link: https://uxplanet.org/why-do-you-need-ontology-in-your-company-cdce5fd59e5d
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Why do you need ontology in your company?
In this post, I’d like to touch on and delve into a topic such as the use of taxonomies and ontologies in a company.
Photo by Sam Moghadam Khamseh on Unsplash
Let’s start with the definition of taxonomy. A taxonomy is a hierarchical system of organization and categorization of different types of objects, which is used to classify objects according to different criteria. The purpose of a taxonomy is to provide a structured framework for organizing and accessing information that can help individuals and the company as a whole better understand and use information.
From a business perspective, one of the most key aspects of a company’s success is the ability to communicate, store, use, and reuse all of the information that has been generated. And taxonomy helps us tremendously with that.
The importance of taxonomy in an organization.
Let’s discuss the problems and opportunities of using the right taxonomy and ontologies in a company.
Navigation.
In a good system, the process of finding information is intuitive and fast. If a person understands how the system is organized, he will easily find what he needs and spend a few seconds doing it. But if he doesn’t, finding information is torture for both existing and new employees.
Imagine a situation where you need to find a document from another team to complete your task, but you don’t know how or where to look. You find a suitable employee from another department, write to him, and then wait… And it’s precious time that goes to waste.
Or another situation. A new employee comes in on his first day at work and instead of quickly becoming familiar with all the necessary processes, documents and start solving problems, he starts wandering through your knowledge base reading absolutely everything, even the things he doesn’t need at all. In the end we have a huge amount of wasted time and a new employee who does not really understand what is going on. Onboarding time increases, the quality is low, the situation repeats, and you lose money.
And these are just a few examples. In fact, there are an incredible number of them. If the system is not designed correctly or if there is no system at all, you lose a lot of money and time which your employees waste. Access to information must be clear, everyone must know the logic of its organization.
Information reusing.
This is an incredibly important aspect. A company usually generates an enormous amount of information. And the more it becomes, the harder it is to maintain the system. You have to consider two ways: either you are constantly creating new objects, expanding your knowledge base and making the system less efficient, or you are overusing what you have and constantly adding to it.
If you choose the first way, prepare for the fact that soon your system will stop working. It will grow a huge number of unnecessary tags / folders, in which even you soon will not understand anything. And if you really care about this process, you will want to redo the system. But herein lies the main snag. You solve the consequence, not the problem. You need to change your approach so that the situation does not repeat itself.
And also, you’ll run into the problem that no one understands which document is relevant. If you create a new information object every time, the old ones have to be deleted. You have to spend time on this and keep track of it. But, alas, in experience, no one will do this in the long run and you will have a lot of old documents that will lead to a breakdown in transparent communications. The employee, may not look at the update date and take that document as fact. This will lead to errors, and consequently, you lose money again.
The solution is to start reusing and augmenting the information you have. That way you can keep your database flexible and compact without unnecessary entities.
Taxonomy frameworks.
In Improvado we use several ontology organization frameworks: BFO, SKOS and RDFC.
The whole system is based on BFO (Basic Formal Ontology). BFO is based on the idea that the world can be described in terms of three fundamental categories of entities: continua, events and processes. Continuous entities are entities that exist over time, such as objects and people, and occurring entities are events or states that occur at a particular point in time, such as measurements or observations. Processes are entities that involve change or transformation.

BFO Framework
We also use the part_of and has_part properties from the OWL (Web Ontology Language) ontology, which allows us to create relationships between our nodes.

OWL Framework
The key advantages that these frameworks have are:
- Literally every piece of information can be classified using this framework.
- It is easy to understand and use.
These 2 factors allow us to use and work with it successfully.
When you have more than 200 people working in an organization, it’s incredibly important that everyone is in the same context and understands the logic behind how the system works. And the simpler it is, the fewer mistakes an individual employee makes.
How do we organize taxonomy in Improvado?
We use Tana to organize our system. Tana is an incredibly powerful tool for organizing knowledge and project management.
Over the past six months we have tested more than 30 different tools, each of them trying to organize a clear and convenient system that fits our criteria. We weren’t able to do this because of the limited functionality of these products. But then Tana came along with the idea of supertags.
A supertag is an object that can be assigned properties. For example, for an employee, you can add properties such as department, role, and so on, creating links between objects.

Employee supertag configuration
But the biggest discovery in Tana for us is the ability of supertags to inherit from each other. As I mentioned above, we are using BFO which implies hierarchies. And Tana allows us to do this very effectively. Property inheritance is the same as reuse. And this is very important in order not to produce a huge number of new properties.
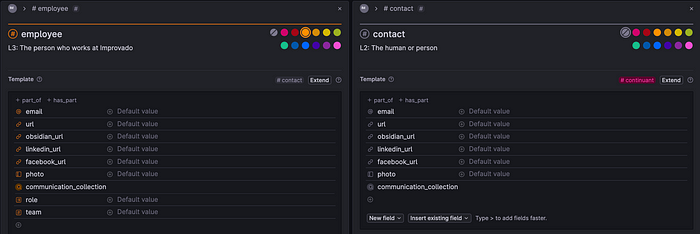
Inheritance in Tana
For example, the photo above shows 2 tags: a contact (top-level) and an employee, which inherits all the fields from the contact tag.
Our ontology at Tana is built on continuants and processes.
Processes are those events that have a moment of beginning and a moment of end. Tags such as task, discussion, onboarding process, and so on.
Continuities are divided into dependent and independent ones. Their main difference is that independent ones can exist by themselves, without additional entities, while dependent ones cannot.
Thus, in independent continuant we use tags of companies (competitors, customers, etc.), product (usage scenarios, features, and so on), and contact. Contact is a universal entity for defining a persona segment. A contact can be like an employee, an investor, a partner, or even a book author.
Dependent continuant contain an information object, which in turn can be like a policy, a rule, a document, a table, a book, and so on.
The important part of the information object is the 3 key properties that all have: has_part, part_of, and is_about. These properties allow us to build relationships between our knowledge base and projects. Not only related relationships with is_about, but also bottom-up and top-down relationships thanks to the part_of and has_part properties.
Here’s what our ontology looks like in Tana.

Our schema in Tana
We have a separate tag called # tag.
Each tag part of a top-level tag (from which it inherits) and has part by lower level tags, and each tag also contains properties (in the example above, the column is called fields).
This depiction of the system is an incredibly important part, because the more accessible and simpler the system is depicted, the easier it is for others to understand. And also, not insignificantly, such a visual representation makes continuous improvement and modification of the ontology a rather simple process.
How Taxonomy Evolves?
The last thing I want to talk about is that ontology and the system are processes that must be continually improved and adjusted. It is impossible to create a system once and hope that it will work forever. Discussion, deliberation, and adjustments are the parts that any system needs in order to do its job well.
I want to share a few examples of how the process of discussion and ontology development at Improvado is structured.
As I said earlier, we have a separate field for each tag that shows its fields.
If we get some idea or topic to discuss some tag or field, we pose the question right there.

Discussion inside you schema
In the photo above, there was a suggestion to discuss the status field. And we always keep those comments because it’s important to see what’s already been discussed and, as I wrote above, reusing what’s been created before is much better than creating a new one.
Such discussions are incredibly convenient because the discussion isn’t taken out of context and everyone understands what we’re talking about.
Conclusions.
Developing a taxonomy and ontology in a company is not a quick and very complex process that requires a fair amount of time to set it up correctly. But trust me, it’s definitely worth it. Once you invest enough time you can create a system that works for you and not against you.
Of course, maintaining a taxonomy takes time. But you will spend much more time dealing with the consequences of a bad system. So let’s solve the problem, not the consequences.
The success of a company is determined by how it knows how to handle information.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK