

沈向洋:IDEA 如何找到创新的「甜区」
source link: https://www.geekpark.net/news/311794
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

沈向洋:IDEA 如何找到创新的「甜区」

把政府撒播的创新种子,和市场化机制连接起来。
2020 年,沈向洋在深圳成立了 IDEA 粤港澳大湾区数字经济研究院,开启了人生的新阶段。他希望能以新的机制,做一些推动技术落地的事情。于是这座国际化创新研究机构的定位为:推动 AI 技术发展,立足社会需求,研发颠覆式创新技术并回馈社会,让更多的人从数字经济发展中获益。
2022 年 11 月 22 日,第二届 IDEA 大会召开,第一天上午的主要议程是沈向洋主讲的「IDEA 技术与产品发布会」。2 个小时的发布会中,沈向洋介绍了这一年来 IDEA 的各项成果,以及每一项成果背后对趋势的思考,既涉及当下大热的 AIGC,也涉及研究方式的转变……除此之外,他从创新-资本范式的视角,梳理了技术创新从实验室走向市场的四个阶段,以及 IDEA 在这其中的定位,要怎样做。
最后他总结,IDEA 一直在寻找属于自己的创新「甜区」,也就是从使命驱动到风险型创新的进程。纵观整场发布会,除了获取前沿趋势的动态,也能在如何思考科技发展上得到的启发。
这是沈向洋当天发布会演讲的主要内容,由极客公园精简整理:
大家早上好!欢迎来到 IDEA 大会。我们非常高兴在深圳这片土地上做一些非常了不起的工作。举办 IDEA 大会的目的有两个,第一是有一个机会可以汇报和展示我们在 IDEA 做出的最新成果。第二是希望能够有机会跟大家分享一下我们对前沿技术的看法和未来趋势的判断。

今天我的演讲分为两部分,第一部分是过去一年多来我个人的体会,在计算机科学、人工智能发展方面有些什么最新的趋势。在这个过程当中,我也会穿插一些我们研究院做的优秀工作,梳理一下我们 IDEA 研究院到底在做什么,我们是什么样的一批人,怎么思考这样的科学的问题,为什么我们要做这样的工作。此外,我想把科学研究这件事情和资本的投入之间的关系用一条创新曲线跟大家分享。
关于人工智能的发展,我以前一直讲两大原因:大数据、大算力。精准的算法推动到整个行业发展到现在,这一点很了不起。现在还不断地有新的了不起的大模型出现,推动着人工智能发展新高潮。
今天,我想跟大家分享四个很有意义的 idea。
01 从一言胜千图到一图胜千言
第一个跟大家分享的 idea,一言胜千图。人工智能最近的蓬勃发展,就是预训练大模型的发展,它整体的规模和速度都到了今天我们不可忽视的地步。还有很多问题人工智能还远远没有解决,但没关系,我今天想跟大家分享一些例子,你讲一句话就可以生成出来非常漂亮的照片,而且结果非常震撼,栩栩如生。我自己做计算机视觉这么多年,三五年前跟我讲大概能做出这样的结果,我是不会相信的。
有一个系统叫做 Open AI,其实也是微软资助的一家公司做的。你讲一句话,日落的时候有一个狐狸在草丛上,能不能用莫奈的风格给它画出来。一年前 DALL·E 就可以做出这样的结果:一个草丛的样子、一个狐狸的样子、一个日落的样子。一年以后的结果,进步非常快。

他能够做出这样的结果有三个原因:巨大的数据量,庞大的算力,了不起的新的深度学习算法,这里特别用到 Diffusion 模型。在互联网上可以找到大量的图像、标注和语言之间的数据对,来做出这样的结果。很多人认为今天深度学习出来这样的结果,技术路线简单粗暴,但是你不得不同意做出来这样的结果已经是非常的细致、漂亮。
有了这样了不起的结果以后,我们应该去想什么样的问题?在 IDEA 技术到了一定地步,我们就想能不能把这些技术做成产品、做成工具。因为我们专注于数字经济,数字生产力的底层,就是以人工智能为代表的工具。这件事情最重要的是可以帮助艺术家,每个人有艺术创作冲动的时候做一些事情。
有人研究过历史上了不起的艺术家他们在做作品的时候,为什么很多艺术家一辈子只能画几张画,而又有其他艺术家可以画很多画。最出名的人是达芬奇,艺术史的研究者研究后得出一个可能性:达芬奇那么多画不是他一个人画的,他带了很多徒弟画。至少我这个外行看不出来达芬奇画的质量和他徒弟画的画的质量。
艺术家要带一堆徒弟,才能够画很多东西。今天 DALL·E 这样的系统出来之后,给我们带来的冲击是什么呢?人工智能就是你的小徒弟,有了人工智能加一些工具,每个人都是「达芬奇」,每个人都有机会做这样的事情,真正提高数字生产力。事实上伟大的艺术家都是非常敏感的技术使用者。达芬奇如果今天在世的话,他肯定第一个尝试像 DALL·E 这样的系统。
看到这样的效果以后,大家是不是觉得人工智能的问题都已经解掉了?当然不是,这里面还是有很多问题的。今天大数据、人工智能还是一个记忆和阐释的过程,还没有真正理解和认知的过程。
举一个简单例子,你让人工智能去做宇航员骑在马上,然后换一个说法,马骑在宇航员的身上,就出来这样的结果。因为以前人类积累的数据里面就没有类似概念,所以很正常。这样一些瑕疵,并不妨碍技术和应用不断迭代和进步,因为有反馈,我们才能闭环、才能有进步、才能有创新。

大模型这件事情已经火到什么样的地步?微软支持的 Open AI 这样一个初创公司 DALL·E,号称估值 200 亿美元。比如美国出来一个 Stable Diffusion 的方法,有一家公司他用开源的方法来做,横空出世,出来就是一个十亿美元估值的独角兽。这家公司的算力远不如DALL·E,但开源出来,就有很多人用,就有闭环,就有可能进步。
IDEA研究院的张家兴博士,两年前就在IDEA对大模型做深入研究。今天非常高兴发布我们 IDEA 研究院在人工智能内容生成领域的「盖亚计划」,一个是模型自动生产力引擎,另外一个方面是预训练模型体系。
整个项目都是开源的,这个项目也自主研发了首个中文开源的 Stable Diffusion 模型,这个项目的开源也标志着中文 AIGC 时代的来临。我们非常高兴能够为中文 AIGC 社区做一些贡献。
大家可以看几个例子,进我们这个系统打一句话:梦回江南,你就可以看到这样的结果。现在我们这个模型已经在 Hugging face 上,在一百多个 Stable Diffusion 中今年已经排名第三。三个星期前下载量已突破 10 万。

02 从分而治之到合而解之
第二个 idea,我自己花了很多时间思考,大模型出来后人工智能深度学习做法。十年后的今天对研究方法的冲击,所以我讲「从分而治之到合而解之」。学过计算机科学的一定会同意我的讲法,以前计算机科学里有个很重要的研究方法是 divide and conquer,一个问题太大了,就分小块,小块之后再拼起来。
十年前,学计算机视觉和学自然语言处理的人基本上老死不相往来,大家都不太清楚对方在做什么。但今天有了深度学习后,大模型把各个环节的人都集合起来,大家今天都是用大模型方法来做这件事。
最近有一篇非常好的论文,文章叫「图像即外语」,Image as a Foreign Language。一张图,想象成外语,它也是一个语言。如果你有这样的视角,剩下的就简单了,所有 NLP 里做的工作,方法论、成果,就可以应用在计算视觉上。
的确是这样,谷歌研究院两三年前出来一篇非常了不起的文章,叫做 「Vision Transformer」。Transformer 是自然语言处理这两年多最了不起的成绩,把图像切成 16×16 的小图像,然后连在一起,就像一串字符,再把 Transformer 的方法用进去。我们在这个基础上,把 Vision Transformer 体系用到计算机视觉里最重要的问题,叫目标检测。
大家看后面这张图,检测出两个物体,一个叫做摩托车,一个叫做人。计算机视觉理解图像有很多下游任务。一旦做到目标检测,可以做目标跟踪、目标分割。这些问题还有很多行业应用,比如医疗检测、自动驾驶,有巨大的应用机会。

过去半年来,张磊博士带领一帮小同学,让 IDEA 研究院在国际上持续霸榜,半年之久,非常了不起。不仅结果最好,而且模型的尺寸、训练的代价、所需要的训练数据,比大多数其他同行做得更强。
这只是结果,给大家感受一下视觉上看起来是怎么回事。 这里有一个非常复杂的视频场景,它检测运动物体、静止物体都能做得非常好。我们还在持续不断推动项目,张磊也把最好的模型开源放在 DETR 上,可以说是最全面的 Transformer 检测开源框架,这件事让计算机视觉可以做得更好,我们也很高兴不断和同行竞争,表现出我们可以做到的结果。
这件事情给我的震撼,不仅仅是科研方法的改变,对人工智能、计算机领域的冲击。这种研究的方法论、深度学习,它对科学研究的冲击会更加大。

最近到处在谈 AI for Science。我们应该选择一些方向,做更多工具,帮助科学家做更好工作。我自己和清华大学蔡峥教授联手做天文方面的工作,我相信很快会有一些非常好的成果向大家报告。
03 从重视计算结果到重视计算过程
第三个 idea,从重视计算结果到重视计算过程。在技术发展过程中,都需要不断看市场和社会需求的反馈。比如 5G 出来后,到底哪些应用推动了 5G,6G 时应该做什么新的东西。在计算机科学发展上,市场推动非常大,只要有了不起的应用,这些聪明的人、聪明的钱就会冲进去。
过去这么多年,从冯诺依曼结构开始,计算就是一个工具,完成的事情是掌握工具的人交给你的任务。我们还在上大学时,最了不起的是科学计算,后来慢慢可以做其他工作。
互联网出来后有巨大的改变。大家用的 APP 掌握在互联网平台手上,平台令你使用更加方便,但同时带来一些问题。平台渗透到我们的工作当中,是一个黑盒子,不透明。你如果希望透明,希望可信可解释,就需要有一种新的计算体系来解决这个问题:我为什么看到这样的结果,你为什么给我这样的结果。这变成一个刚需,能够帮助我们来解决计算过程的问题,不仅是结果的问题。
很多聪明人已经在解这个问题,回归这个问题的本质,如密码学的解法;针对人工智机器学习来讲,有联邦学习。
在 IDEA 研究院,我们选择了一条不一样的技术路线,做硬件。
我们去年做了一个东西叫 SPU,去年只是一个样机,今年已经量产。很多银行的合作伙伴在使用。SPU 的意思叫做 Secure Processing Unit,思路从 GPU 取得一些设计理念,比如打游戏要快不卡,就出现 GPU 这个东西。今天的安全,大家并不是不知道,不去做。英特尔已经做了,CPU 里划了一块物理隔离出来的叫 SGX。但我们的看法是应该拿出来专门做一个芯片。如果要做这件事情,安全体现在各个方面,有安全、可信,开机时就要安全,安全运行的容器,运行的过程要安全,还要有一个安全的虚拟操作。

用硬件的核心好处是不改动原来的算法,以前做的事情今天由硬件来加持,就开箱即用,不用再去改代码。写过程序的软件工程师一定会感谢有这样一些工具可以用。因为改代码是多么痛苦的事情。
有了这样的硬件后,还可以让我们和很多现有的软件解法做结合。比如我们和微众合作,可以把联邦学习的性能提高很多。
我个人觉得未来 SPU 肯定是一个颠覆性的技术,当然还有很长的路,这个判断是否准确,IDEA 是不是真正能够实现,接下来还要验证。
03 从使用语言到创造语言
第四个 idea,关于语言。做计算机、人工智能都是在使用语言,更加重要的是应该创造语言。
全世界的人讲六七千种语言,至今计算机语言有几千种。因为人和人之间需要交流,人和机器之间需要交流,它需要涉及不同的语言。过去这么多年,人工智能想做的事情是,机器能不能学人类的语言,NLP 这样的语言。
但这么多年来,国内对语言的重视非常不够。我们认识的科学家里,真正创造语言的不多。两个月前,我邀请到张宏波离开 Facebook 后加入 IDEA 研究院。宏波以前也是我清华的博士生,他是中国科学家中难得的对计算机编程语言有深度研究而且实践很深的人才。两个月前,IDEA 研究院技术软件中心成立。宏波从 2015 年开始发表一个语言,非常受欢迎,叫 ReScript。宏波来了以后很快在网上开了实践公开课,教 ReScript 编程语言。目前,Rescript 中文版已经发布。有老外说要听宏波上课要学习中文,因为宏波是用中文来上课。期待未来 IDEA 大会,宏波给大家发布一些新的语言方面的工作。

今天我也想介绍另外一方面的语言。王嘉平博士带领团队在 AI 金融、区块链方面做了很多工作,嘉平现在在研发一个 PREDA 并行区块链智能合约语言。它的目的是你不见得要知道底层的工作是什么,但一样可以写有效的并行区块链程序。
05 创新的四个阶段
第二部分,我想谈谈创新这件事情,在研究院里怎么组织起来,怎么去做,为什么选择这样的课题。
我觉得创新至少是有三个层次的,一个层次是科技、技术的创新;第二个层次是产品的创新;第三个层次是商业模式的创新。这都非常重要。但是科技的创新是最根本的、最颠覆的。
基础创新这件事情离不开资本,要创新,就要投入,就需要资本。
要理解创新这件事情,要对创新-资本这个范式做一些分析和描述。在实际运行中,我们看到的都是一些具体技术的突破、具体商业的成功、哪个公司又上市了等等。当中有很多不确定性的原则,慢慢融入到这个组织真正运营的经验里面,沉淀到组织的文化里面,我今天尝试着解释创新的范式。
我想用一条创新曲线介绍创新过程,也映射到我们 IDEA 在做的事情。这个图的纵轴是项目投入的资源,横轴是一个时间线,也包含了一个过程,一个技术从实验室出发,然后走到大市场,最后做到 Mass Market。
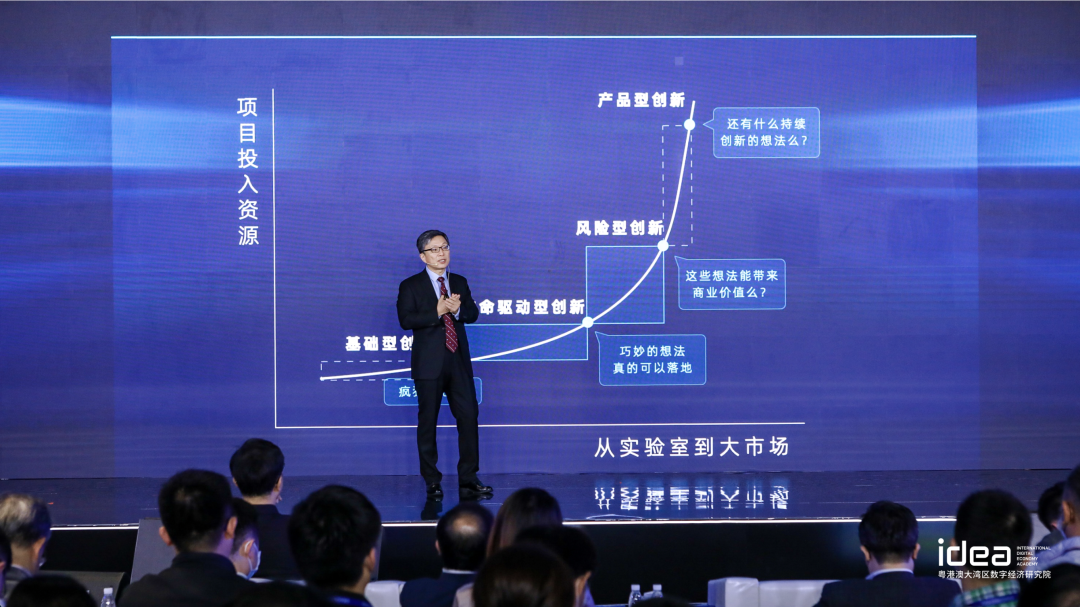
我觉得可以分成四种不同的创新过程,基础型创新、使命型创新、风险型创新、产品型创新。大学实验室做的基础科研,是基础型创新。每个项目砸出去钱的不多,一个老师带一个研究生,可能一开始钱不是很多。有些人有一些 Crazy ideas,想改变世界,就是所谓的使命驱动型创新,他有一个 Mission。比如在医疗上一定要做什么事情,这种是使命驱动型创新,这个单个项目所需要投入的资本就远远升高,很多的钱在做使命驱动型创新。风险型创新项目数量更少,特别是到后期的时候能够投进去钱已经很大了。真正最多钱的创新是在公司,特别是大公司里面 R&D 的创新,research and development。
我举个我师兄的例子,今天语音识别很通用了,我有个大师兄 James Baker 非常了不起,他在 1972 年博士论文的时候,就提出来一个数学模型 Hidden markov Model,以隐马尔可夫模型来解语音。毕业以后,他没有去做大学教授,他有一个 Crazy idea,他就在想如果这个东西能 work 的话,应该能做听写机,所以他是第一个世界上把听写机这件事情弄出来的人,那时候的误差率非常高,应用场景比较受限。
他和他太太两个人成立了一家公司,叫做 Dragon Systems,这是世界上第一家真正做语音识别的公司。一旦这些小公司把这件事情的路趟通了以后,大公司都蜂拥而上。苹果、微软等等都上去了。
整个过程中,我们应该思考资本和项目的配合。在创新过程中,我们要搞清楚谁是真正的参与者、谁是真正的贡献者,这些参与者和贡献者通过什么样的投资回报和资本的模型,连接在一起。
到最后还是需要有钱来支持整体科研过程。资本的模型有很多种,政府的、市场的;短期的、长期的;盈利导向型的、非盈利的。主体也很多,有政府机构、市场化公司、小作坊、甚至一个人在努力奋斗。
在所有投资里,市场才是最大的主体。公司投进来的钱、企业投进来的钱是 R&D 创新里面最大的一部分。给大家看一个数据,是美国从 1956 年到 2020 年的整个国家的 R&D 的投入数字越来越高的。2020 年,美国整个国家的研发预算,公司、市场投入 75%,政府投入 9.4%。是不是就能够有一个结论:政府这边不重要?绝对不是。政府主导的研发虽然在绝对数量上远远低于市场主导的,但它有非常重要的引导作用、指向性作用。没有政府的主体的话,很多未来的创新都是不可能的。
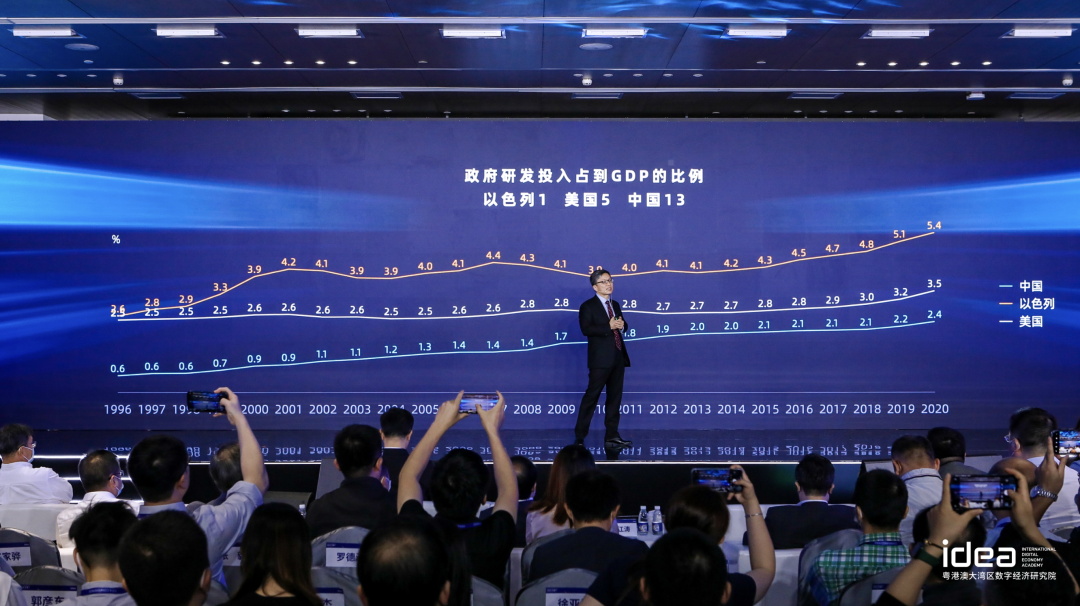
再给大家看一个数字,三个国家的研发对比(图)。全世界排名第一是以色列,它的全国的研发费用占 GDP 在 2020 年在 5.4%。第五是美国、第十三是中国。中国对科技的重视可以从这张图看得非常清楚,在很短的时间之内,中国整体的投入上得快。大家不要小看 2.4%,整个科研的购买力如果也加进去的话,包括人的费用,包括买东西的费用,很多的国内的器件可能都是国外 1/3 的价钱。
结论是非常清楚的。科技是社会进步的根本原因,市场是科技发展的主力军,但政府是持续发展的初动力。市场和政府两个都是投资的主体,这些所有的创新都是钱砸出来的。投了钱,他期望的回报到底在哪里?我的看法很简单,趋于早期的基础的创新,包括使命驱动型的创新,出资方主要是政府,当然也包括一些非盈利机构,他不能也不应该对科技投入的资本回报有诉求,这件事情非常重要,这样才能有长期的观点,投进去的时候,你不应该想马上、什么时候钱就回来了。
基础型创新的例子就是 NSF(国家科学基金会)模式,国内也有 NSF-C。使命驱动的就是 DARPA(国防高级研究计划局)模式。还有 VC 模式,到公司这里就是产品型创新。
NSF 就是撒胡椒面,支持更多的教授、学生。每个项目的资助是很少,一般 1-2 个研究生,5、10 万美元这样的规模。NSF 2020 年预算,在计算机这个行业、信息这个行业总共才 10 亿美金,当然也是不小的钱,但是 Google 买 Deepmind 花了 6 亿美元。所以 NSF 虽然数量不大,但它能够支持很多人去尝试早期的基础科研的东西。最重要是 NSF 从来不说我们这个东西赚了多少钱,他只是讲我们这个支持了多少了不起的学生、后来做了多少了不起的东西。
第二是 DARPA 模型,美国作为一个超级大国崛起,和他们使命型创新做得好是息息相关的。「一战」之前美国并没有这么做,「一战」之后联邦政府才把钱投到公共健康、医疗卫生、公共安全里面。慢慢就走出了一条所谓的 mission driven 的创新道路,特别成功的就是 DARPA,做了全球卫星定位等,这些都是当年使命驱动的,后来对社会、对商业产生了巨大的价值。使命驱动型的创新失败的比例是非常大的,我们听到的都是成功的几个例子。一旦成功,影响力会非常大。
《五角大楼之脑》这本书访问过很多科研人员,大家一致同意 DARPA 至少领先十几二十年,有一批非常聪明的人真正把东西做出来。DARPA 的模式到现在为止还是非常受大家的认可,拜登总统提出来给美国国立卫生研究院增加 90 亿的研究经费,其中 65 亿是专门建立一个以 DARPA 为蓝本的高级健康研究计划署。
风险型投资高风险、高回报,是冒险者的游戏。创业者更加九死一生。90% 以上的初创公司都是会失败的。只有商业上的成功,才有更多的钱,政府征税也好,其他人投钱也好,让创新这件事情不断地做下去。这个时候就是讲的利润了,不管是大公司、实验室也好、小公司也好、自己家车库也好,起步的时候,就是要去想这件事情的利润是什么样。但还有重要的一件事情,如果没有基础型创新和使命型创新的铺垫的话,风险型创新也是很困难的。政府的投入的重要性就是在这里。
最后简单讲产品型创新。
平时听到的也不是太多,就是偶尔类似苹果出来开个发布会,其实砸了很多钱。原因是什么呢?通常公司里面大多数 R&D 的钱都必须要保持现有产品的不断完善,以及这些用户的新需求,他要用新的产品来保证公司有盈利,保证每个季度的业绩给股东有交代,让员工可以继续发工资,所以大多数钱是砸在这里,这个钱是非常庞大的。
这是 Google 2020 年的数字,Google 排名第一、微软排名第三,华为非常了不起,华为 R&D 的数字非常庞大,投入非常巨大。
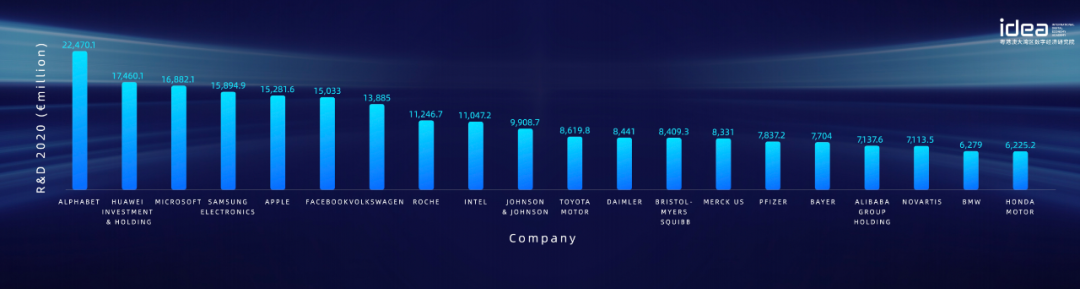
数据来源:欧盟 investment scoreboard
大公司如何创新,这是一个永恒的话题。最后公司不成功、不存在了,其他什么都没有了。要做百年老店,必须创新,而且只有自己颠覆自己,积极拥抱颠覆式创新,才能做这件事情。
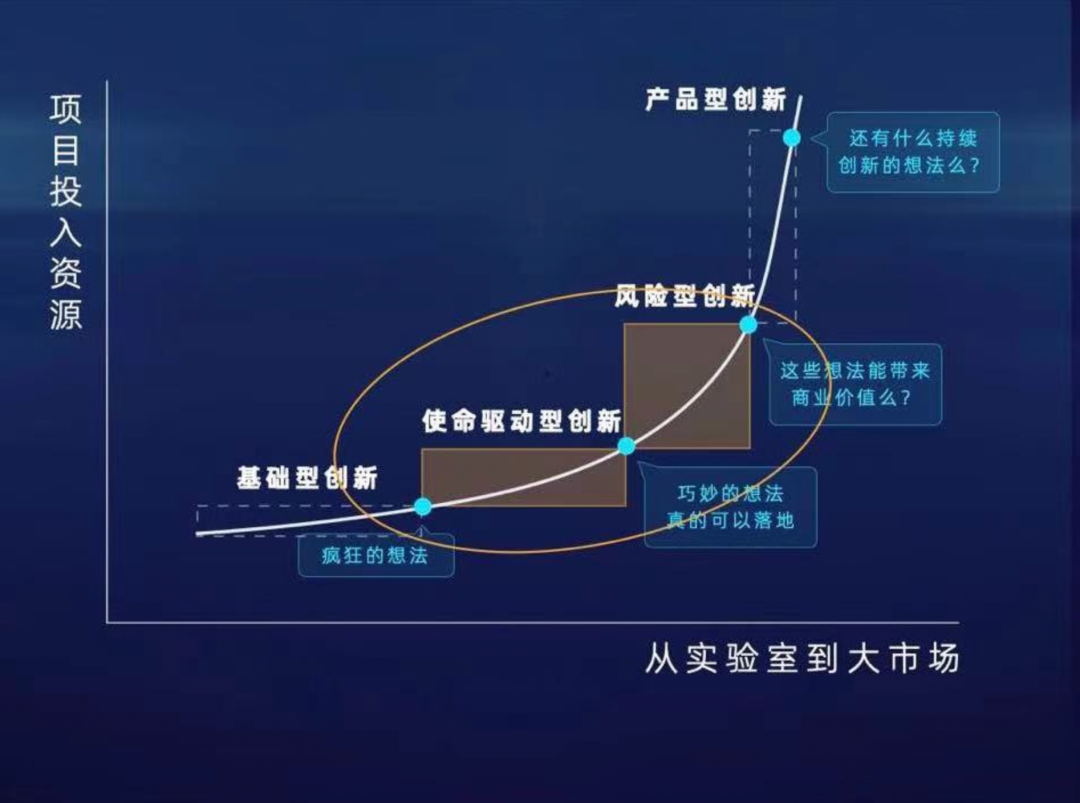
对于 IDEA 来说,应该把有限的资源投向哪里,在创新曲线上我们站在哪一端?
IDEA 研究院是一个国际化新型研究机构,我们把使命驱动的研究成果和未来产业发展的需求连接起来。更加具体来讲,我们是政府支持的二类事业单位,希望把政府科研投入撒播的创新种子和市场化,特别是在大湾区、深圳市场化的资本机制连接起来。在图上我们是坐二望三。
06 IDEA 的 crazy ideas
我想通过一系列的 IDEA 正在做的科研产品给大家做具体阐述,到底这些 Crazy ideas 在做什么。
首先介绍第一个 crazy idea。今天人工智能在发展时,算法可以产生算法,甚至模型可以构建模型了。那我们的 crazy idea 是未来人工智能是不是可以创造人工智能。
这是我们非常喜欢的 James Simons 教授,他 30 岁时就是数学系教授系主任,他做了一段时间数据研究后,突然有一个 Crazy idea,觉得数字建模可以做量化投资,就成立了所谓的文艺复兴公司,里面有一个基金叫做 Medallion,过去年量化率 60% 多。他以前在 UC 伯克利是陈省身教授的博士。
另外一个例子是 Black,Merton 和 Scholes 这三位诺奖经济奖获得者,他们的研究成果也影响了金融量化领域。还有很多计算机科学家,比如UC伯克利2011年的图灵奖,得奖是因为因果推理做得非常好,也影响到了量化。2018年深度学习三剑客的理论也影响了整个行业的发展。

IDEA 研究院郭健教授带领一个非常强的年轻团队,做的工作非常好。郭教授帮我总结,过去 40 年来量化投资经历的三个阶段,1.0 几个聪明的人自己拍拍脑袋想了一些模型出来,2.0 是由小工厂变成大作坊,更多人去找这样的因子,能够做成一条流水线。现在机器学习后,用机器学习来做模型,在 3.0 年代。
即使今天 3.0 也没有真正做到深度学习可以做到的地步,我们提出可以做得更加好,做到 4.0 的阶段。它有几个特点,手工建模到自动建模,从原来是黑盒子到可解释的人工智能,从只是数据驱动变成数据驱动加上自身驱动。我们这方面做了很多工作。
接下来讲第二个 Crazy idea,我想介绍医疗健康方面的,谢育涛在IDEA 做的一个 mission driven (使命驱动)的项目,希望未来让任何疾病都有「谱」可「医」,让医疗知识能够普惠大众。
去年 IDEA 大会,跟大家简单介绍过,我们和哈佛一起合作,和清华俞声教授一直在做,我们想做的是数据驱动的、人工智能帮助的超级知识图谱,能把全世界的医疗知识做成超级知识图谱。我们对标的是全世界最大的美国做的系统 UMLS (unified medical language system)。我们做了不到两年,已经初见成效,也已经在网上公开。

今天 BIOS 整个系统已经是全世界做得最好的,我们的词条数目远远超过美国的 UMLS 系统,概念数量更加远远超过原来的。道理也非常简单,因为我们是数据驱动的,每天都在挖,每天新的医学论文出来后,不断找到新的词条。准确率、覆盖率,也是远远超过竞争对手。
我们还在继续做,希望大家尝试看看我们这样一个系统。未来应用的空间非常广泛,我们希望英语、中文甚至拓展到国际上的其他语言。
第三个 Crazy idea,在教育方面我们有一些想法,我喊了一句口号「让天下没有难读的论文」。
今天做科研都是花很多时间在读论文,论文非常难读,因为大多数论文、包括我们自己的论文,写得很差,还要读,怎么样很快把论文读清楚,我叫做粗读,怎么样读进去,叫做精读,怎么样了解这些东西后还为自己所用。这里有很多方法,包括找论文不方便,管理工具不方便。
今天我在这里非常高兴的发布 readpaper2.0 版,我们的系统都是公开免费的。readpaper2.0 版尝试解决四大问题:找论文问题、智能阅读问题、文献管理问题、学术讨论问题。
最后想跟大家分享一下使命驱动型的方向,谈人工智能在企业方面的应用。题目叫做「第四维度的辅助决策」。我们想做一个商业的事理图谱。大家今天听了很多的事理图谱,它里面最重要的就是多了一个纬度,就是时间维度信息。这样跟传统的知识图谱不一样,你可以知道事件之间发生的因果关系、时序关系。为什么很重要呢?作为一个企业,你必须要关心到底在这样一个动荡的商业环境下应该做一些什么样的决策。

07 寻找创新的「甜区」
最后我想再总结一下,在创新资本的范式中,IDEA 研究院聚焦在哪里。我们其实一直想找一个创新的「甜区」。有这样一些经费的支持,做一些使命驱动型的创新,但又不停留在这里,能够往前走把很多东西真正落地。

如果我们的目标聚焦于这样的创新「甜区」,那选手需要一些什么样的能力?首先需要有选择问题的能力。一流高手选问题、二流高手解问题、三流高手抄问题,当然抄也是不容易的。选择问题的能力是最关键的,然后要有资源调配的能力,然后努力不懈,真有把这件事情从头到尾做起来的能力。IDEA 大多数的项目都是这样选出来的,如果你有科学家头脑、企业家素质、创业家精神,那么 IDEA 就是你的不二之选。
最后我想跟大家分享一个非常激动人心的项目。我们刚刚开始,但已经筹划了很长时间,就是「低空经济」。很多飞行器,比如直升机、无人机一般会在 1000 米以下低空飞行。整个空域是可以利用的。低空经济简单的定义就是:在低空空域,以有人和无人的低空飞行活动为牵引,辐射带动相关领域融合发展的综合性经济形态。现在被浪费掉的低空资源是自然资源,我们可以把它变成非常有价值的经济资源,就像地上的路,路修了以后变成经济资源。
困难在于从今天可以使用、可以通达的空域变成可以计算的空域。空域是非常复杂的事情,今天的无人机飞在天上看不见、管不着、用不着,未来都是需要去做的。我也非常感谢李世鹏院士带领团队正在研发一个智能融合的低空系统 SILAS,把所有的场景数字化问题做深入研究,推动这件事情向前发展。今天我也在这里宣布,隆重发布《低空经济白皮书深圳方案》,欢迎大家多提宝贵意见。

最后我想讲几句话结束今天的演讲。为什么我们对低空经济如此的热衷,为什么我们到深圳来创新创业?我们到底想要做什么?其实原因非常简单,如果我们回过头来看整个人类的简史的话,它就是一部勇闯无人区的历史。从我们的先人走出非洲大陆,到 1492 年哥伦布发现美洲新大陆,到美国西部开发,甚至到最近大家谈得很热的太空的旅行,人类都是在找这样的「无人区」。
今天,我们推开窗户,窗外的这片低空就是离我们最近的「无人区」。所以我想我们在深圳,我们一起努力,团结各方的资源,转化低空为经济资源,实现低空域的可计算,创建工作、生活的新范式,开拓经济增长的新空间。谢谢大家!
Recommend
-
170
404 页面不存在 404. 抱歉,您访问的资源不存在。 可能是网址有误,或者对应的内容被删除,或者处于私有状态。 代码改变世界,联系邮箱 [email protected]
-
79
如何让 HR 找到你? 你需要进行个人SEO优化九章算法·2017-10-19 06:41学会优化个人SEO,获得更多面试机会!撰文丨April Shen 编...
-
65
如果把功能思维看成“点”,产品思维看成“线”,那业务思维就是“面”,这三种思维方式相辅相成,是我所理解的产品进阶路线,也是不同的产品临界点所在。 如果你也跑步,那你一定感受过从跑1公里到3公里、再到5公里的感觉,也一定了解从5公里跑到8公里的感觉,当你跑到1...
-
73
本文作者将在此通过几个实例的分析,与大家一起聊聊:如何从用户的“功能需求”中,找到真正的需求?enjoy~ 很多时候,我们为了避免“闭门造车”式的产品,一定或多或少需要从用户那里获取需求。 但,你有没有发现,他们喜欢给你一些“功能需求”,而不是真正的需求。 什...
-
63
-
46
有问题,上知乎。知乎是中文互联网知名知识分享平台,以「知识连接一切」为愿景,致力于构建一个人人都可以便捷接入的知识分享网络,让人们便捷地与世界分享知识、经验和见解,发现更大的世界。
-
68
很多的朋友经常问到电脑上不了网,怎么判断哪里出问题了吗?这个在实际弱电项目中经常会遇到,做弱电需要掌握电脑知识还是挺多的。
-
63
有问题,上知乎。知乎是中文互联网知名知识分享平台,以「知识连接一切」为愿景,致力于构建一个人人都可以便捷接入的知识分享网络,让人们便捷地与世界分享知识、经验和见解,发现更大的世界。
-
33
问与答 - @dopdopdop - 各位如何找到女朋友的???
-
45
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK