

阿里面试官就是厉害,居然问我分布式事务怎么实现高可用?
source link: https://www.51cto.com/article/740696.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

阿里面试官就是厉害,居然问我分布式事务怎么实现高可用?

一、写在前面
上一篇文章咱们聊了聊TCC分布式事务,对于常见的微服务系统,大部分接口调用是同步的,也就是一个服务直接调用另外一个服务的接口。
这个时候,用TCC分布式事务方案来保证各个接口的调用,要么一起成功,要么一起回滚,是比较合适的。
但是在实际系统的开发过程中,可能服务间的调用是异步的。
也就是说,一个服务发送一个消息给MQ,即消息中间件,比如RocketMQ、RabbitMQ、Kafka、ActiveMQ等等。
然后,另外一个服务从MQ消费到一条消息后进行处理。这就成了基于MQ的异步调用了。
那么针对这种基于MQ的异步调用,如何保证各个服务间的分布式事务呢?
也就是说,我希望的是基于MQ实现异步调用的多个服务的业务逻辑,要么一起成功,要么一起失败。
这个时候,就要用上可靠消息最终一致性方案,来实现分布式事务。
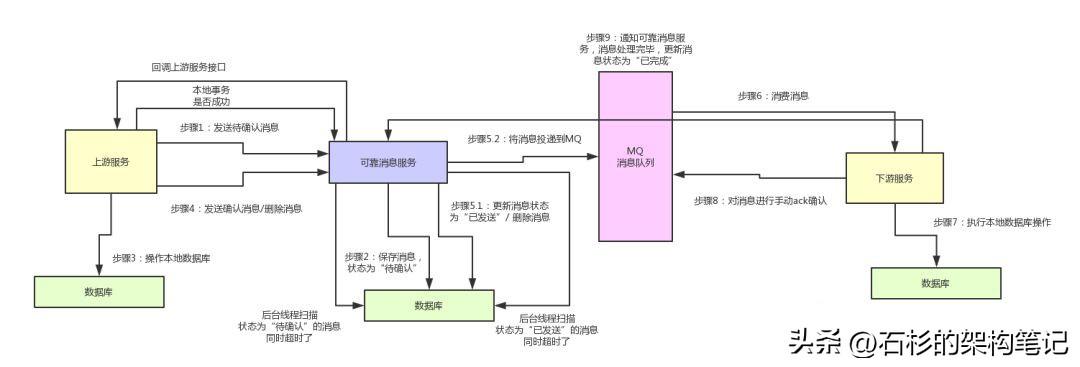
大家看看上面那个图,其实如果不考虑各种高并发、高可用等技术挑战的话,单从“可靠消息”以及“最终一致性”两个角度来考虑,这种分布式事务方案还是比较简单的。
二、可靠消息最终一致性方案的核心流程
1、上游服务投递消息
如果要实现可靠消息最终一致性方案,一般你可以自己写一个可靠消息服务,实现一些业务逻辑。
首先,上游服务需要发送一条消息给可靠消息服务。
这条消息说白了,你可以认为是对下游服务一个接口的调用,里面包含了对应的一些请求参数。
然后,可靠消息服务就得把这条消息存储到自己的数据库里去,状态为“待确认”。
接着,上游服务就可以执行自己本地的数据库操作,根据自己的执行结果,再次调用可靠消息服务的接口。
如果本地数据库操作执行成功了,那么就找可靠消息服务确认那条消息。如果本地数据库操作失败了,那么就找可靠消息服务删除那条消息。
此时如果是确认消息,那么可靠消息服务就把数据库里的消息状态更新为“已发送”,同时将消息发送给MQ。
这里有一个很关键的点,就是更新数据库里的消息状态和投递消息到MQ。这俩操作,你得放在一个方法里,而且得开启本地事务。
啥意思呢?
- 如果数据库里更新消息的状态失败了,那么就抛异常退出了,就别投递到MQ;
- 如果投递MQ失败报错了,那么就要抛异常让本地数据库事务回滚。
- 这俩操作必须得一起成功,或者一起失败。
如果上游服务是通知删除消息,那么可靠消息服务就得删除这条消息。
2、下游服务接收消息
下游服务就一直等着从MQ消费消息好了,如果消费到了消息,那么就操作自己本地数据库。
如果操作成功了,就反过来通知可靠消息服务,说自己处理成功了,然后可靠消息服务就会把消息的状态设置为“已完成”。
3、如何上游服务对消息的100%可靠投递?
上面的核心流程大家都看完:一个很大的问题就是,如果在上述投递消息的过程中各个环节出现了问题该怎么办?
我们如何保证消息100%的可靠投递,一定会从上游服务投递到下游服务?别着急,下面我们来逐一分析。
如果上游服务给可靠消息服务发送待确认消息的过程出错了,那没关系,上游服务可以感知到调用异常的,就不用执行下面的流程了,这是没问题的。
如果上游服务操作完本地数据库之后,通知可靠消息服务确认消息或者删除消息的时候,出现了问题。
比如:没通知成功,或者没执行成功,或者是可靠消息服务没成功的投递消息到MQ。这一系列步骤出了问题怎么办?
其实也没关系,因为在这些情况下,那条消息在可靠消息服务的数据库里的状态会一直是“待确认”。
此时,我们在可靠消息服务里开发一个后台定时运行的线程,不停的检查各个消息的状态。
如果一直是“待确认”状态,就认为这个消息出了点什么问题。
此时的话,就可以回调上游服务提供的一个接口,问问说,兄弟,这个消息对应的数据库操作,你执行成功了没啊?
如果上游服务答复说,我执行成功了,那么可靠消息服务将消息状态修改为“已发送”,同时投递消息到MQ。
如果上游服务答复说,没执行成功,那么可靠消息服务将数据库中的消息删除即可。
通过这套机制,就可以保证,可靠消息服务一定会尝试完成消息到MQ的投递。
4、如何保证下游服务对消息的100%可靠接收?
那如果下游服务消费消息出了问题,没消费到?或者是下游服务对消息的处理失败了,怎么办?
其实也没关系,在可靠消息服务里开发一个后台线程,不断的检查消息状态。
如果消息状态一直是“已发送”,始终没有变成“已完成”,那么就说明下游服务始终没有处理成功。
此时可靠消息服务就可以再次尝试重新投递消息到MQ,让下游服务来再次处理。
只要下游服务的接口逻辑实现幂等性,保证多次处理一个消息,不会插入重复数据即可。
5、如何基于RocketMQ来实现可靠消息最终一致性方案?
在上面的通用方案设计里,完全依赖可靠消息服务的各种自检机制来确保:
- 如果上游服务的数据库操作没成功,下游服务是不会收到任何通知。
- 如果上游服务的数据库操作成功了,可靠消息服务死活都会确保将一个调用消息投递给下游服务,而且一定会确保下游服务务必成功处理这条消息。
通过这套机制,保证了基于MQ的异步调用/通知的服务间的分布式事务保障。
其实阿里开源的RocketMQ,就实现了可靠消息服务的所有功能,核心思想跟上面类似。
只不过RocketMQ为了保证高并发、高可用、高性能,做了较为复杂的架构实现,非常的优秀。
有兴趣的同学,自己可以去查阅RocketMQ对分布式事务的支持。
三、可靠消息最终一致性方案的高可用保障生产实践
1、背景引入
其实上面那套方案和思想,很多同学应该都知道是怎么回事儿,我们也主要就是铺垫一下这套理论思想。
在实际落地生产的时候,如果没有高并发场景的,完全可以参照上面的思路自己基于某个MQ中间件开发一个可靠消息服务。
如果有高并发场景的,可以用RocketMQ的分布式事务支持,上面的那套流程都可以实现。
今天给大家分享的一个核心主题,就是这套方案如何保证99.99%的高可用。
其实大家应该发现了这套方案里保障高可用性最大的一个依赖点,就是MQ的高可用性。
任何一种MQ中间件都有一整套的高可用保障机制,无论是RabbitMQ、RocketMQ还是Kafka。
所以在大公司里使用可靠消息最终一致性方案的时候,我们通常对可用性的保障都是依赖于公司基础架构团队对MQ的高可用保障。
也就是说,大家应该相信兄弟团队,99.99%可以保障MQ的高可用,绝对不会因为MQ集群整体宕机,而导致公司业务系统的分布式事务全部无法运行。
但是现实是很残酷的,很多中小型的公司,甚至是一些中大型公司,或多或少都遇到过MQ集群整体故障的场景。
MQ一旦完全不可用,就会导致业务系统的各个服务之间无法通过MQ来投递消息,导致业务流程中断。
比如最近就有一个朋友的公司,也是做电商业务的,就遇到了MQ中间件在自己公司机器上部署的集群整体故障不可用,导致依赖MQ的分布式事务全部无法跑通,业务流程大量中断的情况。
这种情况,就需要针对这套分布式事务方案实现一套高可用保障机制。
2、基于KV存储的队列支持的高可用降级方案
大家来看看下面这张图,这是我曾经指导过朋友的一个公司针对可靠消息最终一致性方案设计的一套高可用保障降级机制。
这套机制不算太复杂,可以非常简单有效的保证那位朋友公司的高可用保障场景,一旦MQ中间件出现故障,立马自动降级为备用方案。
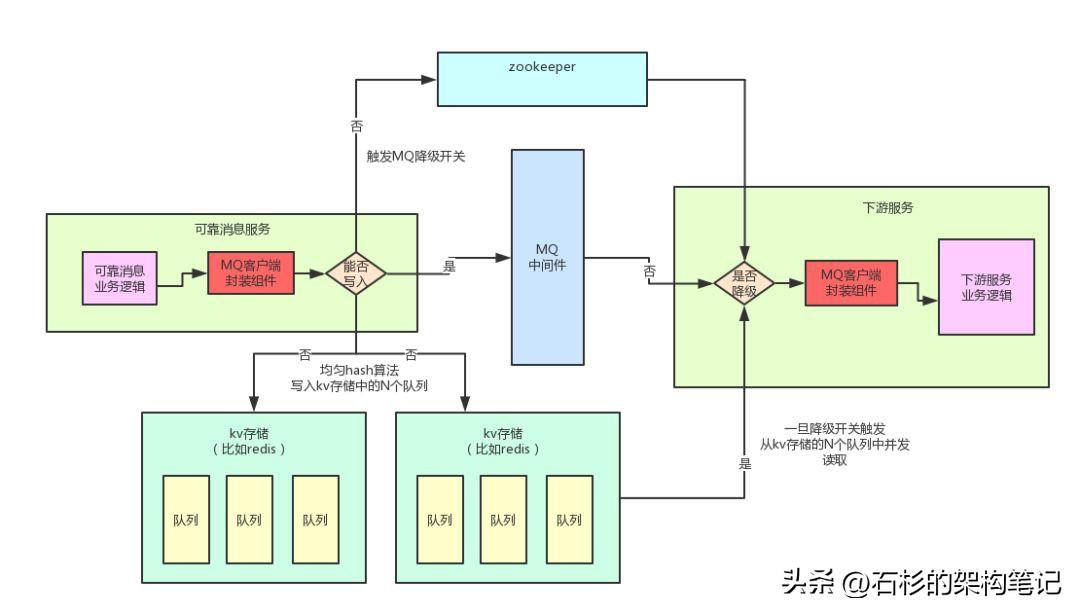
(1)自行封装MQ客户端组件与故障感知
首先第一点,你要做到自动感知MQ的故障接着自动完成降级,那么必须动手对MQ客户端进行封装,发布到公司Nexus私服上去。
然后公司需要支持MQ降级的业务服务都使用这个自己封装的组件来发送消息到MQ,以及从MQ消费消息。
在你自己封装的MQ客户端组件里,你可以根据写入MQ的情况来判断MQ是否故障。
比如说,如果连续10次重试尝试投递消息到MQ都发现异常报错,网络无法联通等问题,说明MQ故障,此时就可以自动感知以及自动触发降级开关。
(2)基于kv存储中队列的降级方案
如果MQ挂掉之后,要是希望继续投递消息,那么就必须得找一个MQ的替代品。
举个例子,比如我那位朋友的公司是没有高并发场景的,消息的量很少,只不过可用性要求高。此时就可以类似redis的kv存储中的队列来进行替代。
由于redis本身就支持队列的功能,还有类似队列的各种数据结构,所以你可以将消息写入kv存储格式的队列数据结构中去。
ps:关于redis的数据存储格式、支持的数据结构等基础知识,请大家自行查阅了,网上一大堆
但是,这里有几个大坑,一定要注意一下。
第一个,任何kv存储的集合类数据结构,建议不要往里面写入数据量过大,否则会导致大value的情况发生,引发严重的后果。
因此绝不能在redis里搞一个key,就拼命往这个数据结构中一直写入消息,这是肯定不行的。
第二个,绝对不能往少数key对应的数据结构中持续写入数据,那样会导致热key的产生,也就是某几个key特别热。
大家要知道,一般kv集群,都是根据key来hash分配到各个机器上的,你要是老写少数几个key,会导致kv集群中的某台机器访问过高,负载过大。
基于以上考虑,下面是笔者当时设计的方案:
- 根据他们每天的消息量,在kv存储中固定划分上百个队列,有上百个key对应。
- 这样保证每个key对应的数据结构中不会写入过多的消息,而且不会频繁的写少数几个key。
- 一旦发生了MQ故障,可靠消息服务可以对每个消息通过hash算法,均匀的写入固定好的上百个key对应的kv存储的队列中。
同时此时需要通过zk触发一个降级开关,整个系统在MQ这块的读和写全部立马降级。
(3)下游服务消费MQ的降级感知
下游服务消费MQ也是通过自行封装的组件来做的,此时那个组件如果从zk感知到降级开关打开了,首先会判断自己是否还能继续从MQ消费到数据?
如果不能了,就开启多个线程,并发的从kv存储的各个预设好的上百个队列中不断的获取数据。
每次获取到一条数据,就交给下游服务的业务逻辑来执行。
通过这套机制,就实现了MQ故障时候的自动故障感知,以及自动降级。如果系统的负载和并发不是很高的话,用这套方案大致是没没问题的。
因为在生产落地的过程中,包括大量的容灾演练以及生产实际故障发生时的表现来看,都是可以有效的保证MQ故障时,业务流程继续自动运行的。
(4)故障的自动恢复
如果降级开关打开之后,自行封装的组件需要开启一个线程,每隔一段时间尝试给MQ投递一个消息看看是否恢复了。
如果MQ已经恢复可以正常投递消息了,此时就可以通过zk关闭降级开关,然后可靠消息服务继续投递消息到MQ,下游服务在确认kv存储的各个队列中已经没有数据之后,就可以重新切换为从MQ消费消息。
(5)更多的业务细节
其实上面说的那套方案主要是一套通用的降级方案,但是具体的落地是要结合各个公司不同的业务细节来决定的,很多细节多没法在文章里体现。
比如说你们要不要保证消息的顺序性?是不是涉及到需要根据业务动态,生成大量的key?等等。
此外,这套方案实现起来还是有一定的成本的,所以建议大家尽可能还是push公司的基础架构团队,保证MQ的99.99%可用性,不要宕机。
其次就是根据大家公司的实际对高可用需求来决定,如果感觉MQ偶尔宕机也没事,可以容忍的话,那么也不用实现这种降级方案。
但是如果公司领导认为MQ中间件宕机后,一定要保证业务系统流程继续运行,那么还是要考虑一些高可用的降级方案,比如本文提到的这种。
最后再说一句,真要是一些公司涉及到每秒几万几十万的高并发请求,那么对MQ的降级方案会设计的更加的复杂,那就远远不是这么简单可以做到的。
Recommend
-
121
相关新闻:阿里王帅:刘强东很擅长碰瓷有时候得自己爬起来阿里王帅谈乌镇饭局:给中国互联网企业整体抹黑了阿里王帅:腾讯整条命都是小学生给的腾讯张军回应阿里王帅:得道多助失道寡助王帅:阿里整体盈利是从2012年才开始的穷过很多年阿里王帅:功守道不
-
43
问与答 - @omyhao - 直接申请读取服务器短信记录这种操作真的是 666 了,还事先排除了伪基站陷害的可能性
-
49
一、Java基础和高级 1.String类为什么是final的。 2.HashMap的源码,实现原理,底层结构。 3.反射中,Class.fo...
-
37
全球工单系统 - @zturns - 去年七月买的阿里云 t5 乞丐版,1c1g40g 配置,10%基线使用,买的时候价格 293 人民币,刚刚看了续费需要 569 元。到底有何硬件升级,能够涨价接近 300 元,难道我去年买的时候是优惠
-
6
网络 卧槽!牛皮了,面试官居然把TCP三次握手四次挥手问的这么详细
-
8
你的位置:Android开发中文站 > 热点资讯 > 这键盘得有磨损多厉害?网友:简直就是骨灰级程序员 1、一女同学在食堂吃饭时...
-
5
欧雷说:「不得不佩服阿里真厉害,能把光棍节变成购物节,把阳具变成办公工具。」 欧雷 发表于 2021-07-28 08:03 不得不佩服阿里真厉害,能把光棍节变成购物节,把阳具...
-
4
原创:微信公众号 码农参上,欢迎分享,转载请保留出处。 前几天,一个小伙伴告诉我,他在面试的时候被面试官问了这么一个问题: 在for循环中,到底应该用 i++...
-
0
6个月的开发,来面试居然要18K,我一问连5K都不值。
-
4
一次面试阿里之后的感慨:TCC分布式事务原理真的得搞明白 作者:石杉的架构笔记 2022-11-24 17:34:04 咱们这篇文章,就用大白话+手工绘图,并结合一个电商系统的案例实践,来给大家讲清楚到底什么是TCC分布式事务...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK