

cpu设计和实现(基础)_嵌入式-老费的博客-CSDN博客_设计cpu
source link: https://feixiaoxing.blog.csdn.net/article/details/127762243
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】
差不多在20年前,也就是2002-2003年的时候,市场上关于cpu设计的书还是很少的。那个时候比较火的是各种各样的web技术,比如html、js、java web之类的。学习好web,就可以获得一份不错的工作。真正嵌入式获得重视,是开始国内有能力生产、设计芯片之后,简单的比如gd32的mcu,复杂的比如瑞芯微的rk3399等等。
1、初识cpu
读书的时候,有一门课程叫《微机原理》,如果再结合另外一门课程《数字电路设计》,是完全有可能自己设计出来cpu的。当时的时候,我们自己其实还不知道有fpga这个技术,所以只会用与非门、与或门、触发器这些来搭一个数字电路。等到后来知道了altera、xilinx之后,发现原来是可以用verilog或者vhdl来设计数字电路的。
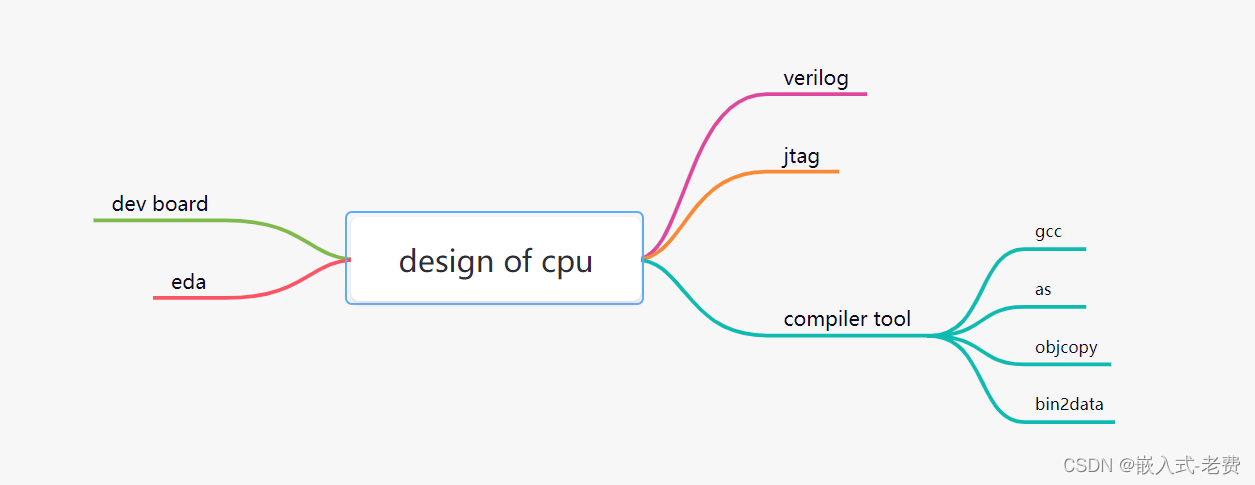
要做好cpu的设计,涉及到技术很多。至少,我们需要了解一门设计语言,至于是verilog,还是vhdl,这个没有关系。其次,需要一个fpga开发板,一个jtag工具,还需要和fpga适配的eda工具。当然,如果是作为纯软件在pc上面仿真也是可以的。不过个人觉得,还是最好在实际板子上跑一跑才能发现更多的问题。以上说的都是硬件层面,除此之外,还需要编译器工具。cpu毕竟需要运行各种各样的指令代码,所以这个时候就需要熟悉一下gcc、as、objcopy这些汇编工具,当然为了方便,还需要一个把bin二进制转换成16进制的工具。
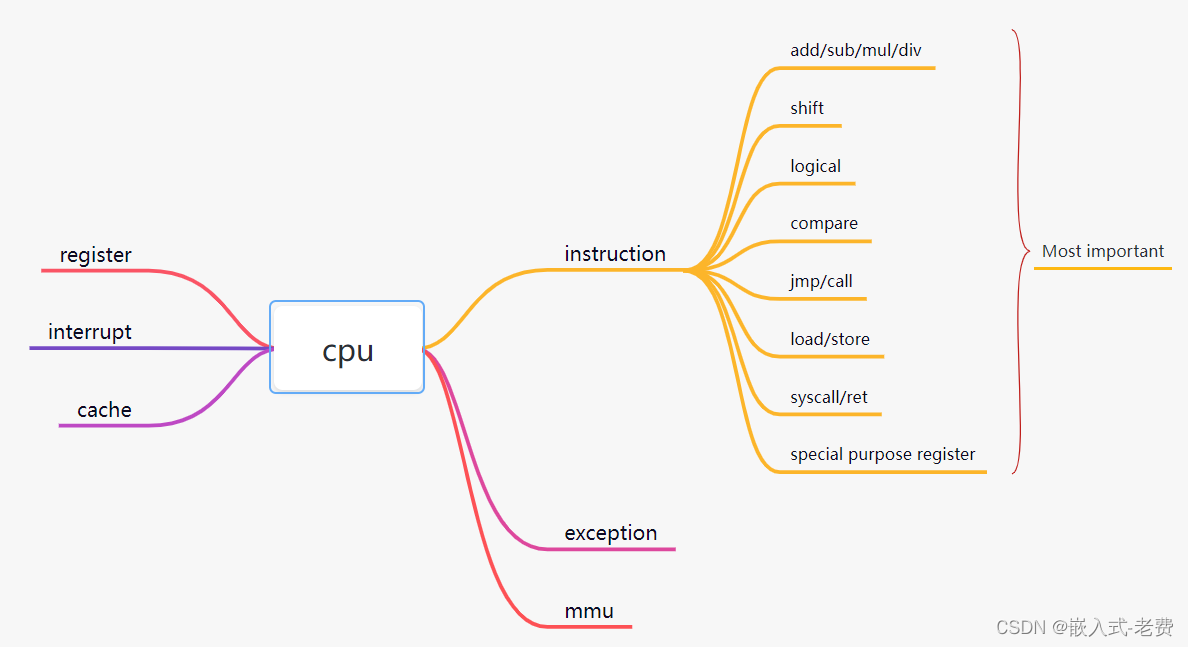
市场上的cpu种类很多,使用频率比较高的就是x86、arm、mips、powerpc这几个,riscv这几年虽然很火,但是目前使用还没那么多。不同cpu之间最大的差别就是指令集的差别和设计理念的差别。x86为代表的cisc cpu总是希望最大化单条指令的性能,而arm为代表的risc cpu总是希望单条指令做的事情越简单越好。一般来说,这些指令索要实现的功能都差不多,比如加减乘除、移位、逻辑运算、比较、跳转和调用、加载和保存、系统调用和返回、特殊目的寄存器的访问等等。
为了cpu的运算,在cpu的内部有很多的寄存器,当然一些寄存器是告诉开发者的,有一些是没有告诉开发者的,这就是所谓的影子寄存器。除了正常的alu运算,cpu还要处理中断和异常。不仅如此,为了适配高级os,比如linux这样完备的大型操作系统,cpu一般还会提供mmu和cache功能。
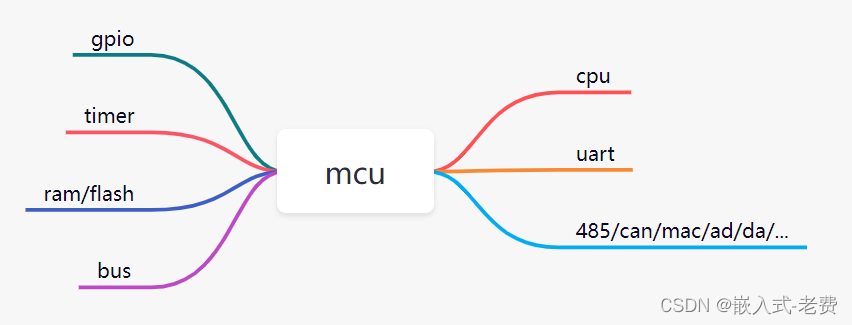
有了cpu之后,之上我们可以做出一个mcu出来,就类似于stm32这样的mcu。一个完整的mcu除了cpu之外,内部还集成了很多其他ip。比如mcu里面一般会有一个或者多个总线,低速ip连接低速总线,高速ip连接高速总线。cpu和其他ip都是连接到这个总线上面。肯定存在的ip一般有gpio、uart、timer、ram和flash。其他可以配置的ip一般有485、 can、mac、ad、da等等这样的ip。这些都是根据市场需求灵活进行配置。
2、设计cpu
2.1 指令的执行
cpu和软件之间的接口就是汇编指令。软件本身,就是编译器将软件翻译成一条一条的汇编指令交给cpu来翻译执行。至于怎么翻译,目前一般来说,指令的执行有两种方法。一种是单周期执行,一种是流水线执行。举个例子,
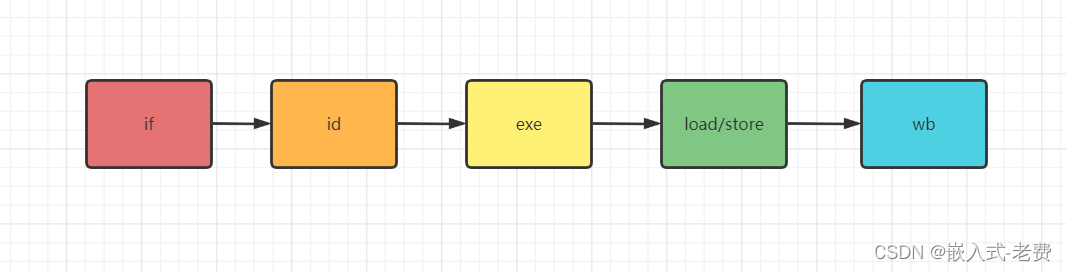
假设我们将指令的执行分成5个步骤,分别是取指if、翻译指令id、执行执行exe、内存访问、写回这5个步骤,那么单周期的执行访问就是采用状态机的方法一次就执行一个指令。比如有一条ori指令,它的汇编是这样的,即ori bx, ax, 0xffff,
那么单周期指令首先取指,接着状态机就切换到id,然后切换到exe,这样依次类推。这样,每一条指令都要划上5个周期才能执行完成。这中间还不包括因为等待mem、exe计算损失掉的时间。虽然方法不复杂,实现起来也比较容易,但是事实上实际产品中用单周期指令的实现并不多。用的比较多的还是流水线,比如像这样,
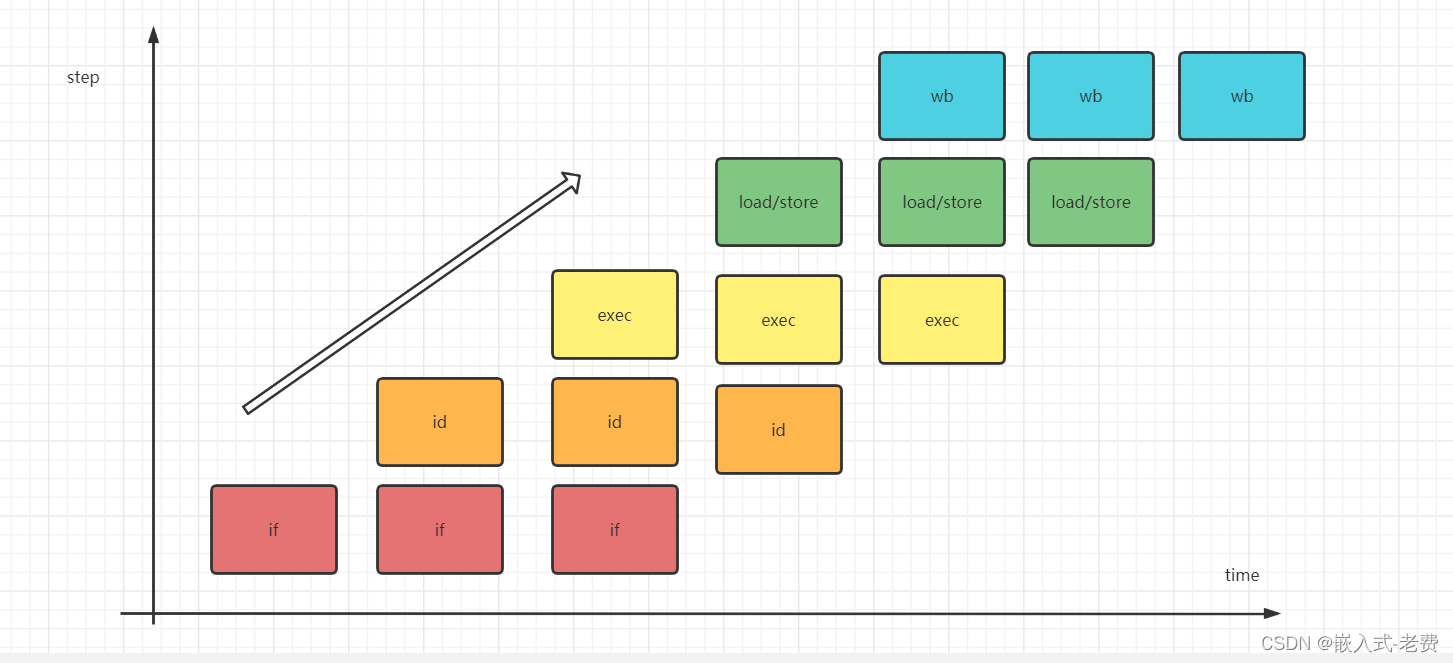
从上图可以看出,虽然每条指令花费的周期还是5个甚至更多,但是在同一个时刻内,并发处理的指令也更多了。这就相当于,在同样的时钟频率下,我们仅仅采用了流水线的方法就使得吞吐量扩大了5倍,并发的效果可想而知。
2.2 组合逻辑和时序逻辑
很多同学不明白组合逻辑和时序逻辑。其实两者关系不复杂。作为流水线来说,在时钟上升沿或者下降沿完成的动作就是时序逻辑,其他中间时刻完成的动作就是组合逻辑。组合逻辑可能会有很多种可能性,但是时序逻辑会在边沿触发的那一刻只选择一种状态,并且在下一个边沿触发到来之前一直保持这种状态。
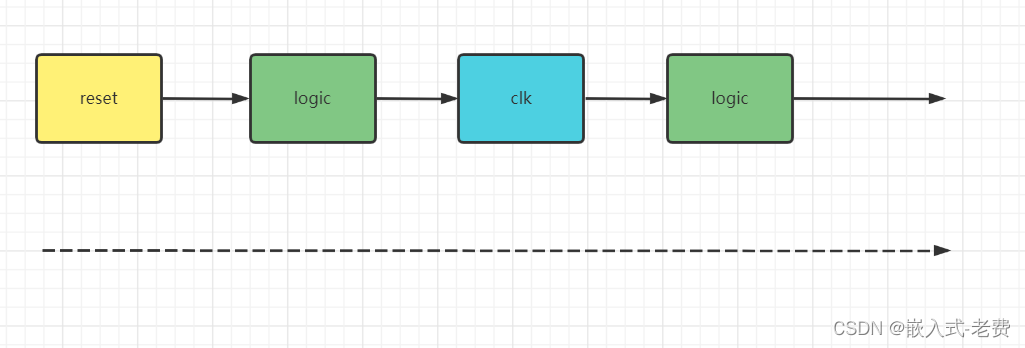
对于cpu来说,复位是所有工作的开始,就如同盘古开天辟地一般。在这一刻,所以的状态都有一个初始值。有了这个初始值之后,后续的电路就按照组合逻辑、时序逻辑、组合逻辑这样的步骤逐步执行。有一点需要注意的,那就是fpga所有的操作都是并发处理的,这个是需要记在心里的。
2.3 数据预取
之前谈到了流水线,它可以加快数据的处理流程,但是实际上除了带来的好处之外,它所带来的问题也是我们需要 及时进行处理的。举例来说,假设有两条指令,
ori bx, ax, 0xff
mov cx, bx
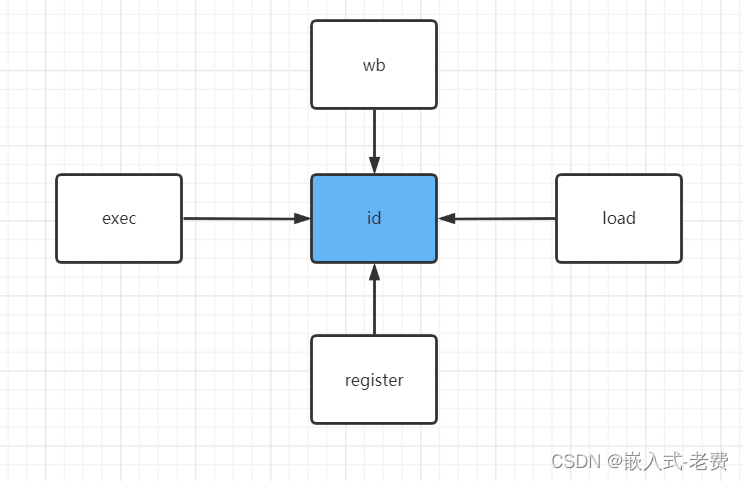
咋看这两条相临的指令似乎是没有问题。但是,大家可以思考一下,作为mov cx,bx来说,如果在译码阶段获得的bx寄存器不是最新的ax|0xff里面的数值,而是从register里面拷贝的数值,这个是不是其实就是一个误操作呢?所以对于每一条指令的寄存器,一般都要判断下寄存器是不是wb里面的数值,是不是mem里面的数值,是不是exe里面的数值等等。否则,一不小心,就会有错误发生。
2.4 流水线停滞
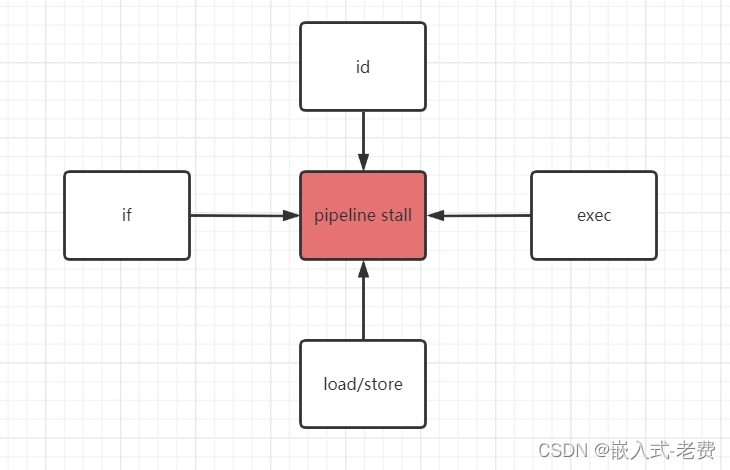
流水线停滞的原因很多,这里我们主要说三种。第一种,就是if、mem阶段的停滞。一般来说,外部mem的访问速率要比cpu内部寄存器的访问速率低很多,所以这个时候指令或者数据没有获取到,整个流水线只能停下来。第二种,就是exe阶段的停滞。这个也比较好理解,有的计算alu是可以很快处理,比如加减、移位、逻辑运算等等。但是有的运算,cpu也需要若干个周期才能完成的,比如乘除、mac计算等等。第三种,就比较隐晦一点,就是指令间的依赖等等,比如这两条指令,
load bx, [ax]
mov cx, bx
还是从mov cx,bx的角度来看,这个时候如果需要获取bx的寄存器,那么只能是译码阶段来做这件事情。但是当mov指令处于译码阶段的时候,load指令还在执行阶段。所以就算要最快获取bx寄存器的数值,也要load指令到访存阶段才能完成。等load指令从exe阶段过渡到mem阶段的时候,mov指令干什么呢,它其实什么也做不了,能做的就是id、if部分流水线停滞一下而已。等到load指令执行结束,整个流水线才继续执行。
2.5 跳转指令
指令的指令并不总是顺风顺水的。比如pc地址,一般都认为是这么设计的
除了复位阶段,pc清空为0之后,其他时刻都是pc自增为4。但是实际上,在比较指令执行的时候,pc往往会跳到另外一个我们需要的地址。但是pc地址的计算,就算最快处理也要等到译码阶段才能完成,而这个时候compare后面的指令已经被取进来了。所以针对这种情况,像mips这样的cpu就专门做了规定,跳转、比较指令后面紧跟的那一条指令也会强制执行,称之为延迟槽。看上去,有了延迟槽之后,这个跳转的问题就解决了,其实这又带来了另外一个问题,如果延迟槽的命令在exe阶段发生了异常了,那么返回地址应该如何记录?
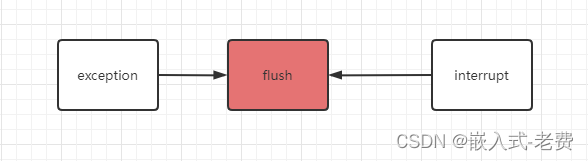
2.6 流水线清空
对于cpu来说,异常和中断差不多是一回事。此外,cpu普遍采用一种叫精准异常的技术,就是说cpu只会在某一个阶段处理异常,其他阶段发生的异常也会等流水线到了这个阶段之后,cpu才会进行处理。通常情况下,cpu只会在mem阶段处理异常,因为下一个阶段就是wb写回了,这个阶段是不可能出现异常的。中断也是这样,一般也是mem阶段的时候处理,换句话说,如果此刻没有异常而且流水线也没有被stall住,那么mem及之前的pipeline数据都会被flush掉,在记录中断源、返回地址之后,pc马上切换到中断处理向量指向的地址上去。
关于精确异常,我们再举个例子,假设id译码出现了异常。这个时候异常是不会立马处理的,它会随着流水线依次进入exe、mem,直到mem阶段,cpu才会处理这个异常。也就是说,就算id发生了异常,exe和mem的指令还是会正常执行,等到前两个指令都执行结束,没有问题了之后,cpu才会接管这个异常的。因为,谁也保不齐,万一mem、load也出现异常呢,那不应该是先处理load、mem的异常吗?
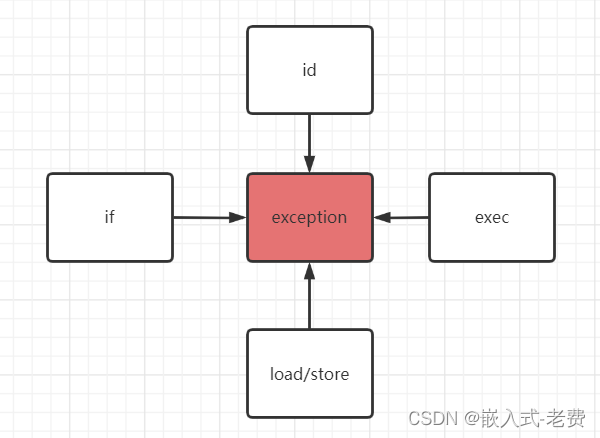
如上图所示,异常发生的情况很多,比如,
1)if取指,address越界;
2)id译码错误;
3)exec出现div 0,即div ax, 0x0
4) load/store出现访问异常等等
3、实验和练习
关于实验,一般有两种方法。一种是纯软件的实验,也就是利用modelsim,或者是iverilog+gtkwave这样的软件来进行一下逻辑测试。另外一种就是上板子,将verilog代码综合成最终的电路,烧入到altera或者xilinx的开发板上。我个人建议,前期可以将大部分时间放到仿真上面,毕竟用pc电脑来进行仿真是比较方便,也是比较高效的。等到后期,自己fpga的经验上来之后,这个时候就可以慢慢在开发板上进行调试和测试。
与此同时,大家也可以慢慢在cpu上面添加一些额外的设备,比如之前说到的bus、gpio、uart这样的外设。就算他们都不是很复杂,但是毕竟也是自己一行一行写出来的。有了这些经历之后,后面再学习其他的cpu、soc、mcu等等,心里也不会发怵,这就是我个人学习cpu、编译原理和操作系统最大的体会。有的同学也许会把这些工作称之为造轮子,认为在工作中也用不到,浪费时间。但事实上,有了这些基本原理作为铺垫之后,你再做一些类似应用类的工作其实就非常容易上手了。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK