

Advanced Data Structures & Algorithms: Implementing a Bloom Filter in JavaSc...
source link: https://blog.bitsrc.io/advanced-data-structures-algorithms-implementing-a-bloom-filter-in-javascript-703f04e9e2e9
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Advanced Data Structures & Algorithms: Implementing a Bloom Filter in JavaScript
Gain huge performance improvements with a small error trade-off

Have you ever tried to sign-up for a website and the website keeps telling you that your chosen username is already taken? You then start using your personal data, like your name, and then add your last name to the mix, and the site keeps telling you: “username already taken” and you’re like…. “Did I actually sign up here before?”
The answer is no, you didn’t, but that website has so many users that instead of checking against all valid usernames, they’re estimating that you’re probably trying to use an existing username. They’re using a bloom filter.
Let’s take a look at how that can be implemented in JavaScript.
What’s a bloom filter?
Alright, so if you want a full detailed explanation of how bloom filters work, you should check out this article.
That said, if you want a simple explanation and practical implementation, keep reading.
A bloom filter can be seen as an array of bits and a function to map a word to that array. Every time you add a word into the filter, all the mapped places of the array are set to 1, and if you want to check if a word is already there, you check for the bit array if all the mapped indices are set to 1.

Look at the above image, you can think of the “Bloom Filter” as a black box right now. It translates a word into a set of positions inside the bits array.
Our job is now to break open that black box called “Bloom filter” and find a way to implement it.
Implementing the bloom filter
According to the theory, to do the mapping you’ll need k hash functions, one for every position inside the array.
So the positions inside the array will be calculated by hashing the word and then doing a modulus operation by the number of bits inside the array (let’s call that number M).
So a pseudo algorithm for this would look like this:
Essentially, we’re saying that we have a 5 bits array and 2 different hash functions. We’re using them to get the indices to know which bits to enable on the bits array.
Looking at it like that, it’s not that complicated, is it?
Let’s see how we could implement it using JavaScript.
Writing the JavaScript
The first function I want to look at is the last one, I called it saveWord because essentially I’m trying to save words into the filter.
This is what it looks like:
The function takes the word we want to save and uses 3 global variables:
SEEDSwhere we store the random seeds for the different hashing functions.ARRAY_LENGTHwhich determines the number of positions inside the bits array.BLOOM_FILTERwhich is essentially the bits array.
The hashing algorithm we’re using is the MurmurHash, which is a non-cryptographic hashing function. Essentially a quick hashing function that gives us a number back. And we’ll use that number to determine the index inside the BLOOM_FILTER array that we have to set to 1.
I’m also keeping count of the number of indices that were already set to 1 (with the taken variable), because if at the end, the total number of taken positions equals the number of positions we needed, it means the whole word is already inside the filter.
And that’s it, the bloom filter is ready to be used.
Let’s take a look at how you can use this filter.
Did you like what you read? Consider subscribing to my FREE newsletter where I share my 2 decades’ worth of wisdom in the IT industry with everyone. Join “The Rambling of an old developer” !
Using our bloom filter to read words from a book
For this example, I’m going to read the TXT version of the Frankenstein book taken from The Gutenberg Project.
We’ll take the file, split it by the blank spaces and then take each word and add them into the filter. We’ll keep count of how many words are actually inserted into the filter, and at the same time, we’ll keep count of how many words are correctly ignored and how many are false positives.
The following code does all of that:
There are two constants at the top of the script that you can play around with and see the type of results you get. They’re the number of hash functions to use and the size of the bits array.
With the given values, these are the results I get:
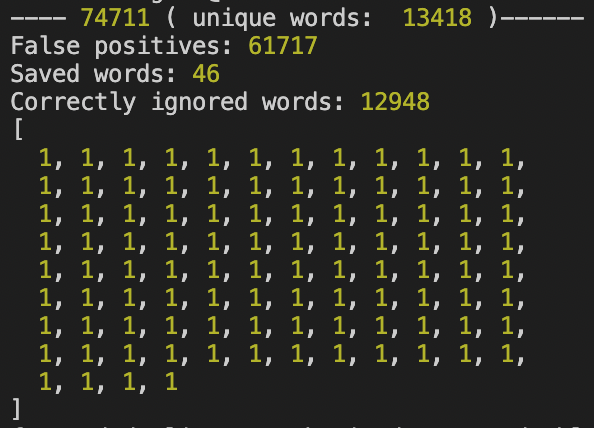
You can see the total number of words processed at the top (74.711) and then how many of them were false positives and how many of them were correctly ignored because they were added.
Our bloom filter, as it is implemented right now, only accepts 44 words out of a total of 13.418 unique ones. That’s a .3% of effectiveness. Let’s see if we can change that a bit.
Essentially, the bigger our bits array becomes, the fewer chances we have for our algorithm to create collisions with different words, thus, the number of false positives is reduced. For example, with 100.000 bits in the array, and 5 hashing functions (we’re not changing that part), we can get much better numbers:

We’re saving 99% of all words, and we only have 93 false positives (which given how I’m counting them, could be the same word).
Of course, if you use a different hashing algorithm, or your universe of potential words is different, your mileage may vary.
The point here is that we’re processing over 70k words, and for every word we only have to do 5 checks (in our case), instead of checking each word against all potential words (potentially thousands of them) to make sure it’s not there already. If you take this same case and apply it to the logging service of a massive online multiplayer game (for instance, or a massively used web app), you’ll probably be OK with a small percentage of false positives and a huge performance increase.
Finding the best configuration
So far I tried to keep the Math out of the equation (pun intended), but this algorithm is heavily dependent on it, so the more you understand it, the better suited you’ll be to use it.
I’m not a Math expert, so I did what anyone would do, I went to Wikipedia and read what the optimal number of hash functions is and how to calculate it. No, that’s not cheating, that’s being efficient.
Anyway, according to someone a lot smarter than me, the optimal number of hashing functions is calculated like this (with k being the number we’re looking for).
k = ( SIZE OF THE FILTER / NUMBER OF ELEMENTS ) x Ln(2)
So, let’s take that to our example, we were testing with a filter made up of 100k slots, and we were using 13k unique words. If we put those numbers in there, we get: 5.17
And you can try it, with 5 hashing functions, we got the lowest number of false positives.
Let’s do another experiment, and let’s double the size of our array. Let’s try with 200k slots. If we use the same formula, we get: 10,3
And lo and behold, if we try with 10 hashing functions and a 200k size filter, we get:

Just 2 false positives! Amazing!
Try with 8, or with 11 hashing functions, and the numbers will not be as good.
Bloom filters can solve a huge performance issue for big systems. Of course, as we’ve seen, there is an error percentage that we have to make sure stays low, to avoid affecting our users, but the trade-off is massive!
Keep in mind that as the filter starts filling up (more and more slots are set to 1) the false positive rates will go up until all values are set. When that happens all queries to the filter will yield false matches. So if you’re using one of these filters for an ever-growing number of elements, you’ll have to eventually grow it and keep adapting the parameters to make sure it stays optimal.
I’ve personally never had the opportunity of implementing one of these in a production environment, have you had to do something similar in the past? Leave a comment, I’d love to know how it went!
Build composable web applications
Don’t build web monoliths. Use Bit to create and compose decoupled software components — in your favorite frameworks like React or Node. Build scalable and modular applications with a powerful and enjoyable dev experience.
Bring your team to Bit Cloud to host and collaborate on components together, and speed up, scale, and standardize development as a team. Try composable frontends with a Design System or Micro Frontends, or explore the composable backend with serverside components.

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK