

生产环境的数据表变更很麻烦?那这个功能你应该用的上
source link: https://www.51cto.com/article/740630.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

生产环境的数据表变更很麻烦?那这个功能你应该用的上

离线开发是大数据平台的基础模块,提供大规模数据存储与计算能力,帮助数据开发人员完成数据加工工作,例如将数据从源头表加工成明细表,再加工成汇总表等。可选择搭载其它大数据产品,实现数据集成、数据研发、数据治理、数据服务等功能,灵活满足客户的各类场景。
1、实际场景
在数据开发中,我们经常会碰到要对一些生产环境的表进行一些变更,包括增加字段等操作,但是生产环境的表又不能随意变更,因为往往这些表格存在复杂的上下游关系,所以一般都会需要经过测试,通过测试验证的代码才能提交到线上。
例如,当前线上调度任务中运行着如下的代码,代码中的表intern_new.ods_user_info被下游所使用,代码示例如下:
insert overwrite table intern_new.dim_user_info_p
partition (ds='2021-07-25')
select id as user_id,
name as user_name,
province,
age
from intern_new.ods_user_info
where ds='2021-07-25';此时需要对该表进行逻辑修改或增加字段等操作,通常来说会有两种方式进行线上表的修改:
- 第一种,开发人员选择新建一个临时表,并复制出现有代码,先进行测试验证。当验证通过时,再将该表更新,并更新代码,然后将任务提交上线。
- 第二种,开发人员选择直接修改该表,并修改原有代码,修改完成后,将任务提交上线。
对于上述两种方法,第一种方法更可靠,能保证所有操作不影响线上数据,也不影响下游,但是会多一些额外的工作;第二种方法可以节约额外的创建临时表,以及代码反复拷贝修改的时间,但是特别容易出纰漏,影响线上数据。
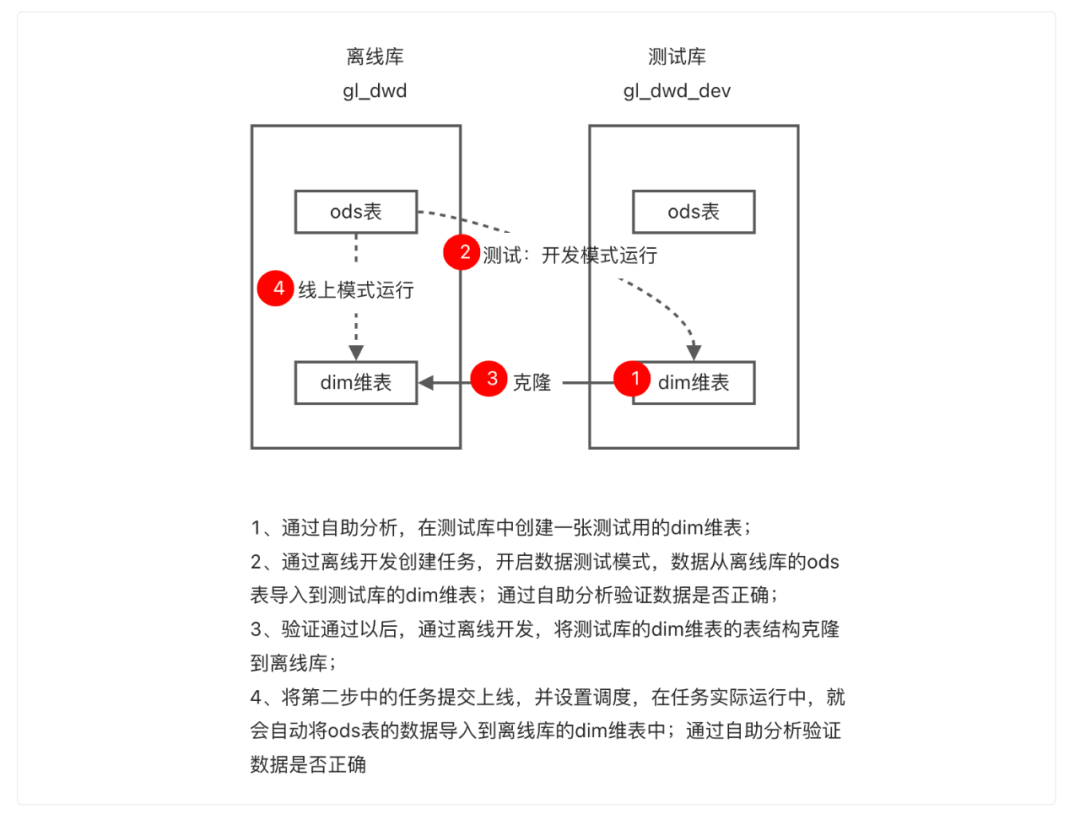
为了更好解决上述问题,数开平台支持数据测试功能。数据测试功能通过引入“${db}”占位符,来解决db自动替换的问题,能够控制同一份代码根据运行环境不同,自动进行部分参数替换,实现操作离线表或测试表的功能,以及操作默认HDFS文件或测试HDFS集群文件的功能。当前可生效在离线开发和自助分析两个子产品中,解决了数据开发过程中的线上数据和开发数据隔离问题。
2、实践内容
假设现在有一张dwd表为”gl_dwd.ods_user_info“,该表是由“gl_ods_user_info”任务每天下午15:27:00产出,需要将这张表加工为dim维表。
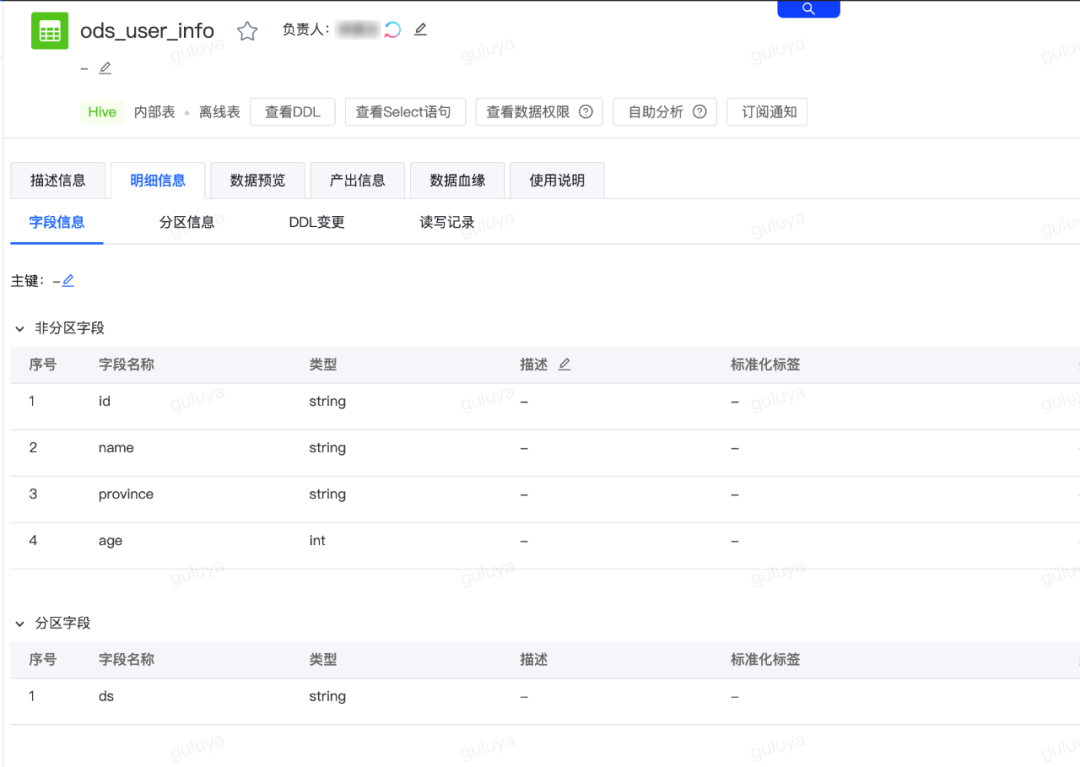
涉及的产品模块:离线开发、自助分析
数据开发的流程:
第一步:通过自助分析创建测试表
首先我们需要通过自助分析,在gl_dwd_dev库中建一张测试用的dim维表,dim维表的表结构:
字段类型 | ||
user_id | string | |
user_name | string | |
province | string | |
dim维表的建表语句示例:
CREATE TABLE gl_dwd_dev.gly_dim_user_info_p (
user_id STRING COMMENT '用户id',
user_name STRING COMMENT '用户姓名',
province STRING COMMENT '省份',
age INT COMMENT '年龄')
PARTITIONED BY (ds STRING COMMENT '时间分区')
STORED AS PARQUET;操作效果页面如下,点击运行:
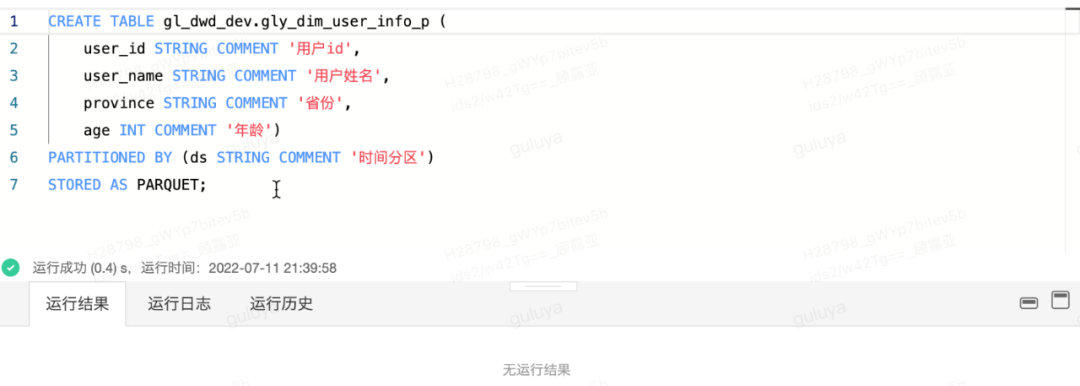
看到“运行成功”的提示,则说明测试库中的dim维表已经成功创建~
第二步:通过离线开发创建任务
我们通过离线开发创建任务,使得ods表的数据能够写入dim维表。
先新建一个任务,然后在画布中拖入SQL节点,进入SQL编辑页面后输入下方代码,将gl_dwd.ods_user_info表的数据写入gl_dwd_dev.gly_dim_user_info_p这张表中:
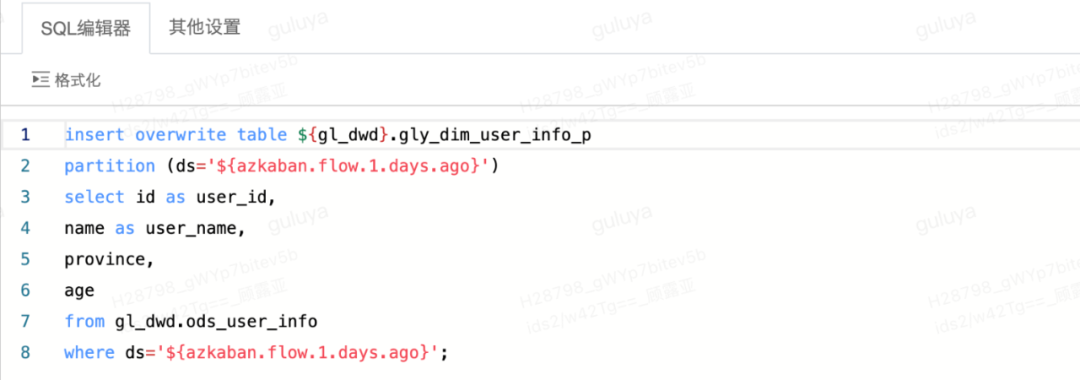
然后通过在开发模式下运行节点,若运行结果为成功,则表示代码能够正常执行,代码验证通过以后,我们可以去自助分析对数据进行验证。
通过select语句,检查dim表中是否确实有了新的数据,select语句示例如下:
SELECT * from gl_dwd_dev.gly_dim_user_info_p where ds='2022-07-10';点击运行后,运行成功,可在运行结果中查看数据,一共有200条记录,说明数据正确。
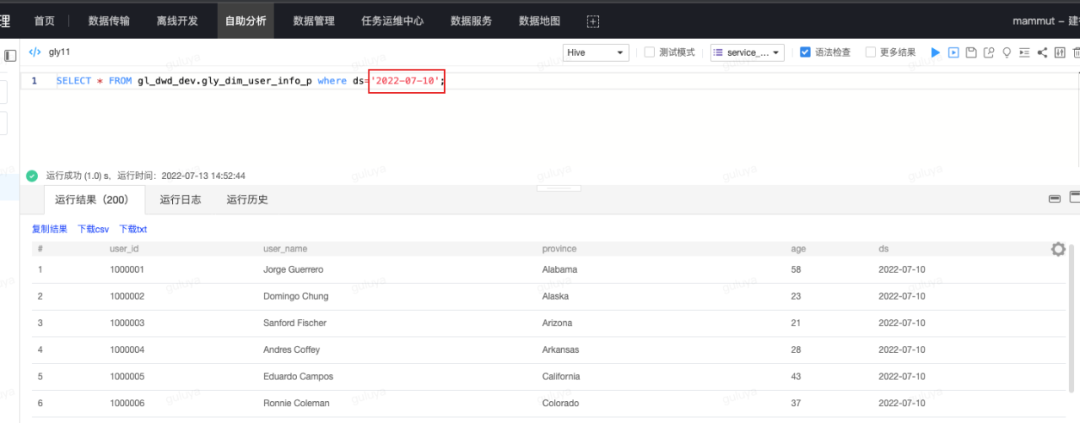
至此,我们就成功地通过离线开发,创建了一个开发任务,并且利用测试模式,完成了代码和表结构的验证!下一步,就可以将通过测试的测试库的表克隆到离线库,并将任务提交上线,让离线库中的我们真正的生产表也能有产出的数据。
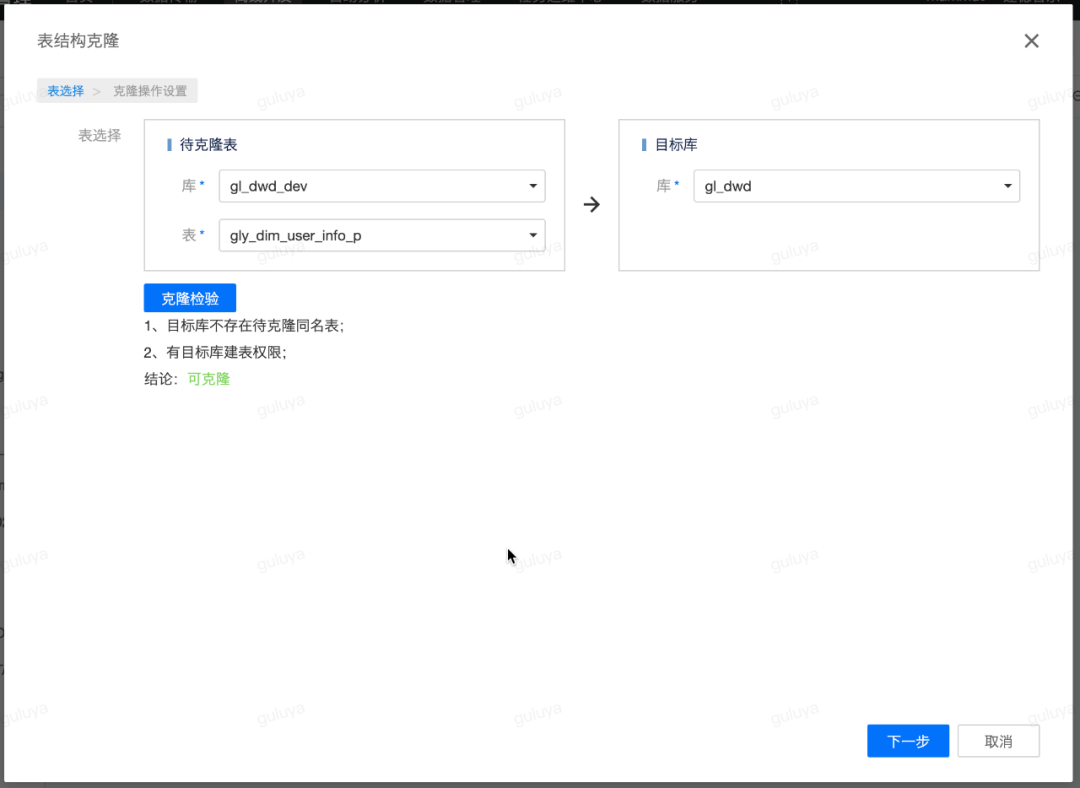
第三步:通过表克隆将测试完成的表结构克隆到离线库中
仍然在离线开发,点击页面左上角的表克隆,选择待克隆的库表,以及目标库,即gl_dwd_dev库下在上一步骤中新建的dim维表,要将其克隆到离线库gl_dwd中,选择好以后点击克隆检验,检验通过后,即可点击下一步:
系统会自动生成对应表的DDL语句:
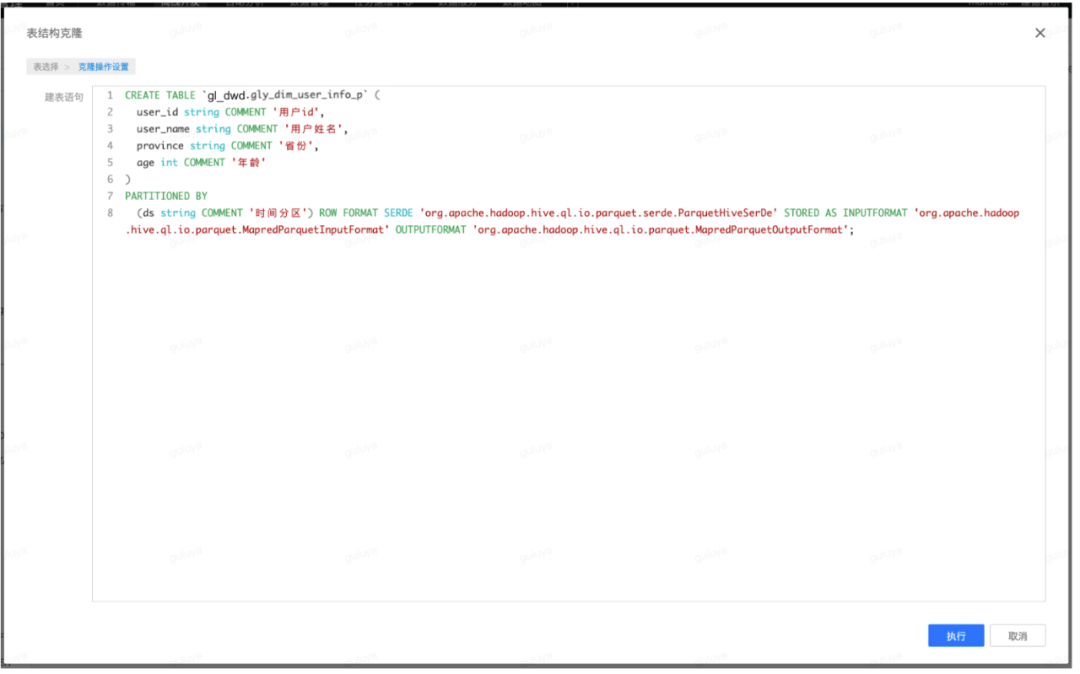
点击“执行”,会提示执行成功,即已经在gl_dwd库中生成了与gl_dwd_dev库中dim表结构一致、表名也一致的表。
第四步:将任务提交上线并设置调度
(1)提交上线:
最后,就是将通过测试的任务提交上线并设置调度,让它能够按时产出数据,提供给下游使用。
这里需要注意的是,我们用到的gl_dwd.ods_user_info表是任务gl_ods_user_info的产出表,这张表同时又是任务gly_demo的输入表,这两个任务均为每日调度产出,因此在实际数据加工的过程中,我们就需要保证,在任务gly_demo运行之前,同一调度周期内,任务gl_ods_uers_info必须已经成功产出数据,因此形成任务依赖关系:gl_ods_user_info-----> gly_demo,即任务gly_demo必须依赖任务gl_ods_user_info。
离线开发支持通过自动解析任务的产出表,智能推荐任务依赖。在编辑调度页面,点击智能依赖,系统会自动计算并推荐上游任务及节点,点击确定后,就可以看到页面新增了任务依赖,表示该任务会在其依赖的任务,即gl_ods_user_info任务的实例产出后,才会开始运行。
将任务调度信息设置完成之后,任务就会开始按照计划执行时间生成实例,在实际执行时,就会执行如下代码,将数据插入到“gl_dwd.gly_dim_user_info_p”表中:
insert overwrite table gl_dwd.gly_dim_user_info_p
partition (ds='${azkaban.flow.1.days.ago}')
select id as user_id,
name as user_name,
province,
age
from gl_dwd.ods_user_info
where ds='${azkaban.flow.1.days.ago}';(2)验证数据:
最后再来到自助分析,验证我们的数据是否成功地写入了离线库gl_dwd中,即查看gly_dim_user_info_p表中2022-07-10分区是否有完整的200条记录:
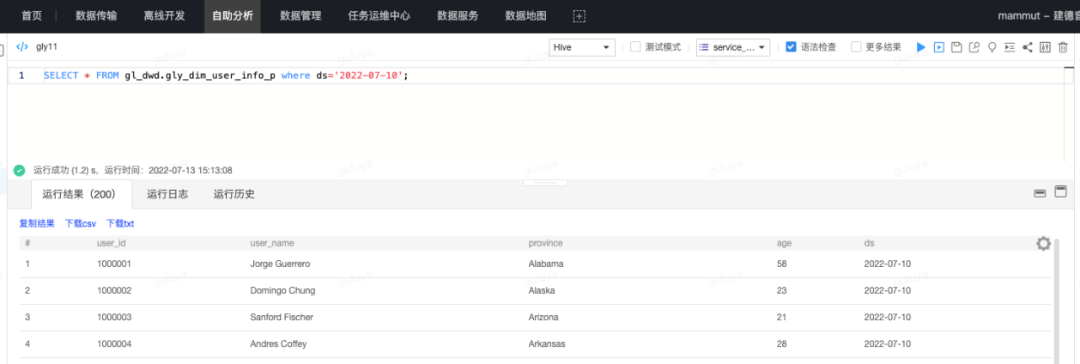
运行结果显示,离线库中的dim表已经拥有了正确的数据。至此,我们的离线开发任务就完成了开发、验证与上线的全部过程!
3、总结
以上通过一个简单案例完成了数据测试功能,引入“${db}”占位符,实现了db自动替换,解决了数据开发过程中的线上数据和开发数据隔离问题。
在实际业务场景中,企业出于数据安全考虑往往存在着更复杂的数据存储方式与数据测试规范,大数据开发工作也逐渐往更规范、高效的方向发展,由此也对产品提出了更多的要求和挑战。离线开发产品也在不断吸收来自数据开发工作一线的用户使用场景与姿势,不断努力打磨产品,给用户带去更智能、更高效的大数据数据开发与测试体验。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK