

Magic3D: High-Resolution Text-to-3D Content Creation
source link: https://deepimagination.cc/Magic3D/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

High-Resolution Text-to-3D Content Creation
Magic3D: High-Resolution Text-to-3D Content Creation
Magic3D is a new text-to-3D content creation tool that creates 3D mesh models with unprecedented quality. Together with image conditioning techniques as well as prompt-based editing approach, we provide users with new ways to control 3D synthesis, opening up new avenues to various creative applications.
Video
High-Resolution 3D Meshes
Magic3D can create high-quality 3D textured mesh models from input text prompts. It utilizes a coarse-to-fine strategy that leverages both low- and highresolution diffusion priors for learning the 3D representation of the target content. Magic3D synthesizes 3D content with 8× higher-resolution supervision than DreamFusion while also being 2× faster.
[...] indicates helper captions added to improve quality, e.g. "A DSLR photo of".
Videos are best viewed with Google Chrome.
Click on the text prompts to reveal the 3D meshes!
Prompt-based Editing
Given a coarse model generated with a base text prompt, we can modify parts of the text in the prompt, and then fine-tune the NeRF and 3D mesh models to obtain an edited high-resolution 3D mesh.
Other Editing Capabilities
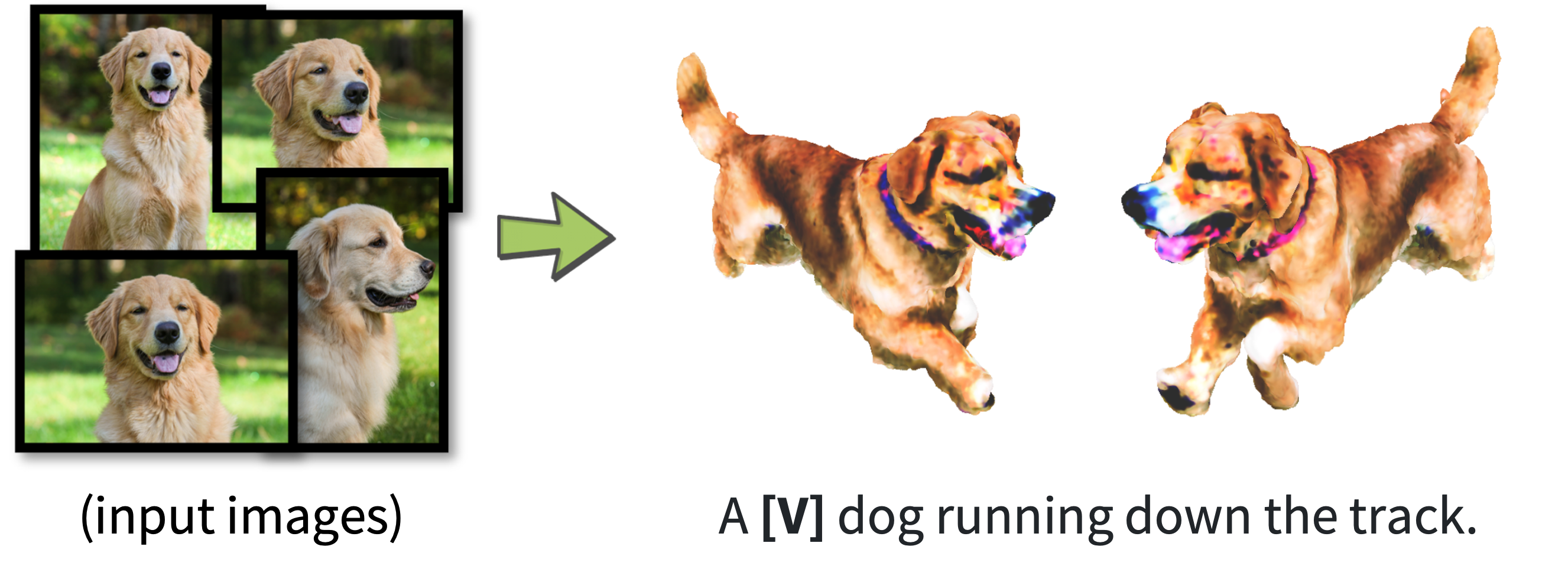
Given input images for a subject instance, we can fine-tune the diffusion models with DreamBooth and optimize the 3D models with the given prompts. The identity of the subject can be well-preserved in the 3D models.

We can also condition the diffusion model (eDiff-I) on an input image to transfer its style to the output 3D model.

Method
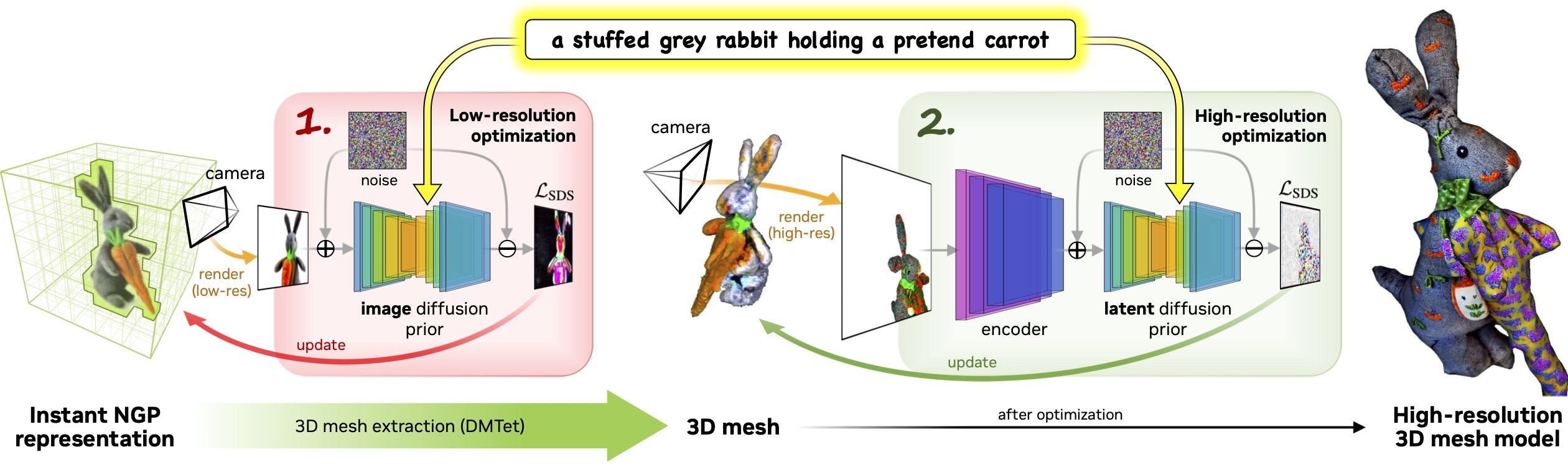
We utilize a two-stage coarse-to-fine optimization framework for fast and high-quality text-to-3D content creation. In the first stage, we obtain a coarse model using a low-resolution diffusion prior and accelerate this with a hash grid and sparse acceleration structure. In the second stage, we use a textured mesh model initialized from the coarse neural representation, allowing optimization with an efficient differentiable renderer interacting with a high-resolution latent diffusion model.
Citation
title={Magic3D: High-Resolution Text-to-3D Content Creation},
author={Chen-Hsuan Lin and Jun Gao and Luming Tang and Towaki Takikawa and Xiaohui Zeng and Xun Huang and Karsten Kreis and Sanja Fidler and Ming-Yu Liu and Tsung-Yi Lin},
journal={arXiv preprint arXiv:2211.10440},
year={2022}
}
Recommend
-
11
Generative High Resolution Desktop Wallpapers with code Sunday, April 22, 2018 I have been playing around with openFrameworks and some Perlin noise this weekend, and put together...
-
13
Real-Time High-Resolution Background Matting
-
9
Extracting high resolution images from hostile web sites I have a friend in the printed media business. He gets to handle weird requests for technical things which have to happen, no matter what it entails. Sometimes this means...
-
8
High-Resolution Monotonic TimerAvailable since PHP 4, the microtime() function returns the current Unix timestamp with microseconds: ...
-
7
How do you want to play? That’s the question your purchasing decision revolves around when it comes to gaming. ...
-
12
Dear integration consultants, I developed a free tool that can help with your SAP Cloud Integration documentation workflow. You can get the Flow image in PNG or SVG format and paste it into the documentation in seconds. While it has so...
-
9
MacGyver would approve — German scientists built a high-resolution microscope out of Lego bricks The only non-Lego components are the lenses, salvaged from smartphone cameras....
-
6
July 30, 2021 ...
-
2
Now entering the third dimension — 3D for everyone? Nvidia’s Magic3D can generate 3D models from text New AI aims to democratize 3D content creation, no modeling skills req...
-
1
Synthesis AI debuts high-resolution text-to-3D capabilities with synthesis labs
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK