

超精准!AI 结合邮件内容与附件的意图理解与分类!⛵ - ShowMeAI
source link: https://www.cnblogs.com/showmeai/p/16903829.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


💡 作者:韩信子@ShowMeAI
📘 深度学习实战系列:https://www.showmeai.tech/tutorials/42
📘 TensorFlow 实战系列:https://www.showmeai.tech/tutorials/43
📘 本文地址:https://www.showmeai.tech/article-detail/332
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容

对于很多企业而言,电子邮件仍然是主要沟通渠道之一,很多正式的内容也要基于邮件传达,供应商、合作伙伴和公共管理部门也每天会有大量的电子邮件。邮件的信息提取和处理可能是一项耗时且重复的任务,对拥有大量客户的企业而言尤其是这样。
💡 场景 & 背景
有一些场景下,如果我们能借助于AI自动做一些内容和附件等识别,可以极大提高效率,例如以下这些场景:
- 保险公司的客户索赔管理。
- 电信和公用事业企业客户投诉处理。
- 银行处理各种与抵押贷款相关的请求。
- 旅游行业公司的预订相关电子邮件。
如果我们希望尽量智能与自动化地进行电子邮件处理,我们需要完成以下任务:
- 电子邮件分流。我们希望智能理解邮件,并将其转到相应的专门业务部门进行处理。在AI的视角我们可以通过电子邮件的意图分类来尝试解决这个问题。
- 信息提取。根据确定的意图,提取一些信息给到下游流程,例如在CRM系统中记录客户案例进行跟踪。
在本篇文章中,ShowMeAI 将专注于意图检测部分,我们将一起看一看如何设计一个AI系统来解决这个任务。
💦 场景 1
假设一家保险公司客户,想申请理赔与报销。 这个场景下他会填写保险报销表,并将其连同药物收据和银行 ID 文件附在电子邮件中。可能的一个电子邮件可能长这样:
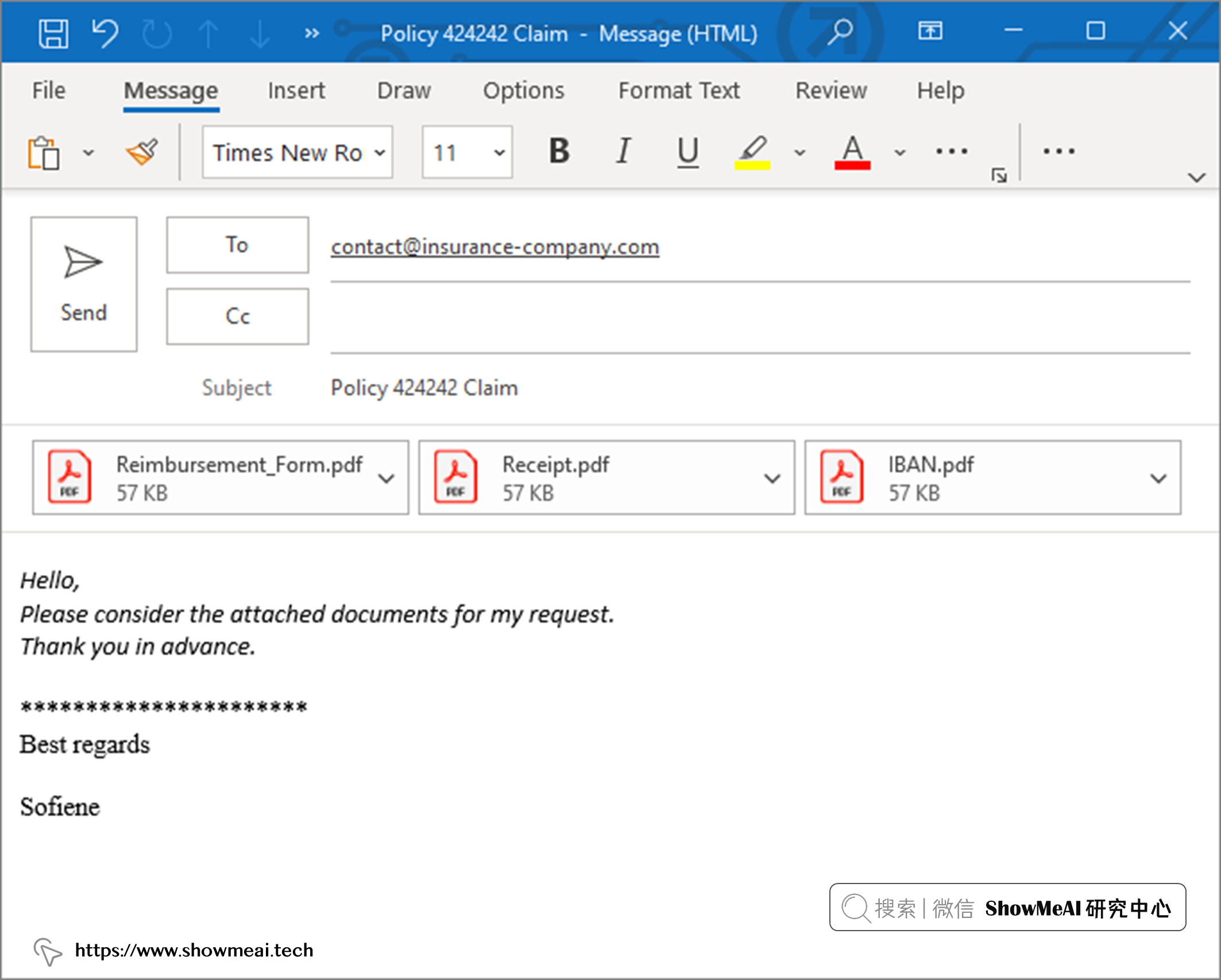
💦 场景 2
假设一家银行的客户,搬家并对之前的某项服务费有疑问。 如果选择发送电子邮件来进行申请和处理,邮件可能长这样:
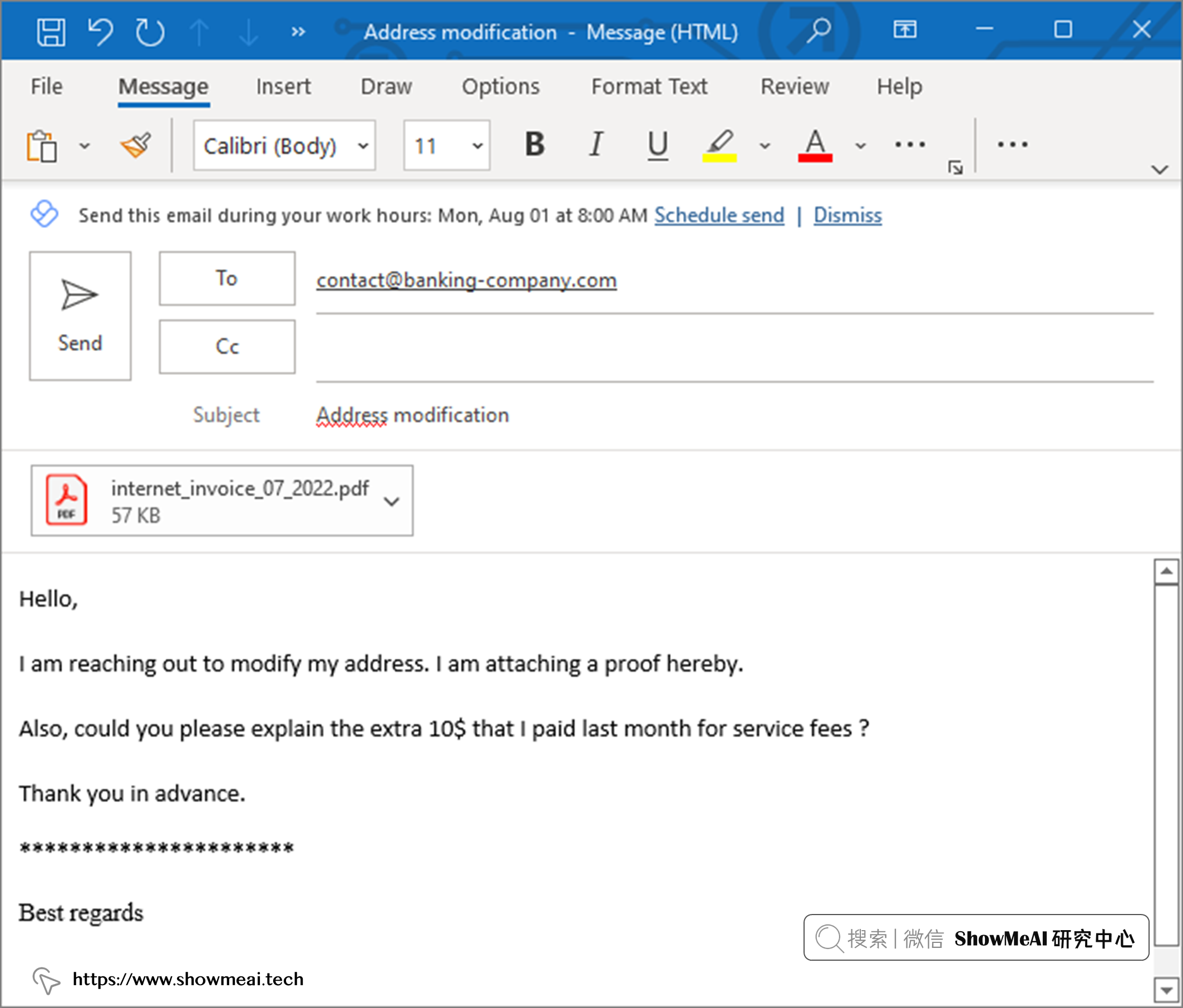
💡 实现方案

本文会涉及到NLP相关知识,有兴趣更系统全面了NLP知识的宝宝,建议阅读ShowMeAI 整理的自然语言处理相关教程和文章
📘深度学习教程:吴恩达专项课程 · 全套笔记解读
📘深度学习教程 | 自然语言处理与词嵌入
📘NLP教程 | 斯坦福CS224n · 课程带学与全套笔记解读
📘NLP教程(1) - 词向量、SVD分解与Word2Vec
📘NLP教程(2) - GloVe及词向量的训练与评估
💦 架构初览
我们前面提到了,在意图识别场景中,我们经常会视作『多分类问题』来处理,但在我们当前场景下,有可能邮件覆盖多个意图目的,或者本身意图之间有重叠,因此我们先将其视为多标签分类问题。
然而,在许多现实生活场景中,多标签分类系统可能会遇到一些问题:
-
电子邮件在大多数情况下是关于一个主要意图,有时它们具有次要意图,在极少数情况下还有第三个意图。
-
很难找到涵盖所有多标签组合的标签数据。
我们可以试着构建一个融合方案来解决,可以预测主要意图并检测剩余的次要意图和第三意图,我们可以设计多输出神经网络网络来实现这一点,如下图所示。
我们涉及到2类输入:电子邮件正文 和 附件,在深度学习场景下,我们都需要对它们做向量化标准。如下图的架构是一个可行的尝试方案:我们用transformer类的模型对正文进行编码和向量化标注,而对于附件,可以用相对简单的NLP编码器,比如TF-IDF。
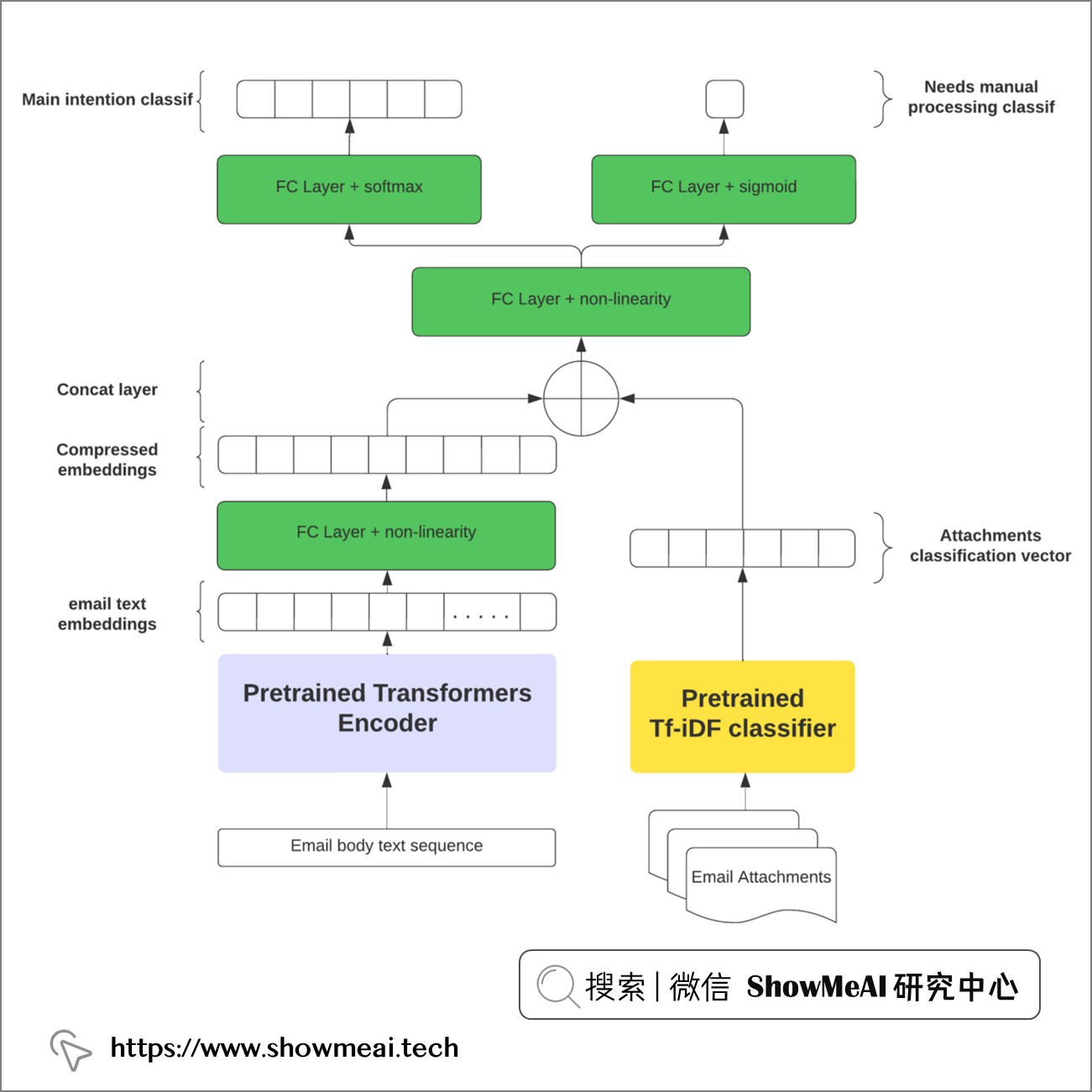
💦 实现细节
① 电子邮件正文:AI理解&处理
整个方案中最重要的输入是正文数据,我们在深度学习中,需要把非结构化的数据表征为向量化形式,方便模型进行信息融合和建模,在自然语言处理NLP领域,我们也有一些典型的向量化嵌入技术可以进行对文本处理。
最『简单』的处理方法之一是使用 📘TF-iDF + 📘PCA。
对于文本(词与句)嵌入更现代一些的 NLP 方法,例如 Word2Vec 和 📘Doc2Vec ,它们分别使用浅层神经网络来学习单词和文本嵌入。大家可以使用 gensim 工具库或者 fasttext 工具库完成文本嵌入,也有很多预训练的词嵌入和文本嵌入的模型可以使用。

关于 TF-IDF 和 DocVec 的详细知识,可以查看ShowMeAI 的文章 📘基于NLP文档嵌入技术的基础文本搜索引擎构建。

现在最先进的技术是基于 transformer 的预训练语言模型(例如 📘BERT)来构建『上下文感知』文本嵌入。我们上面的方案中也是使用最先进的深度学习方法——直接使用 📘HuggingFace的 📘预训练模型 和 📘API 来构建正文文本嵌入。
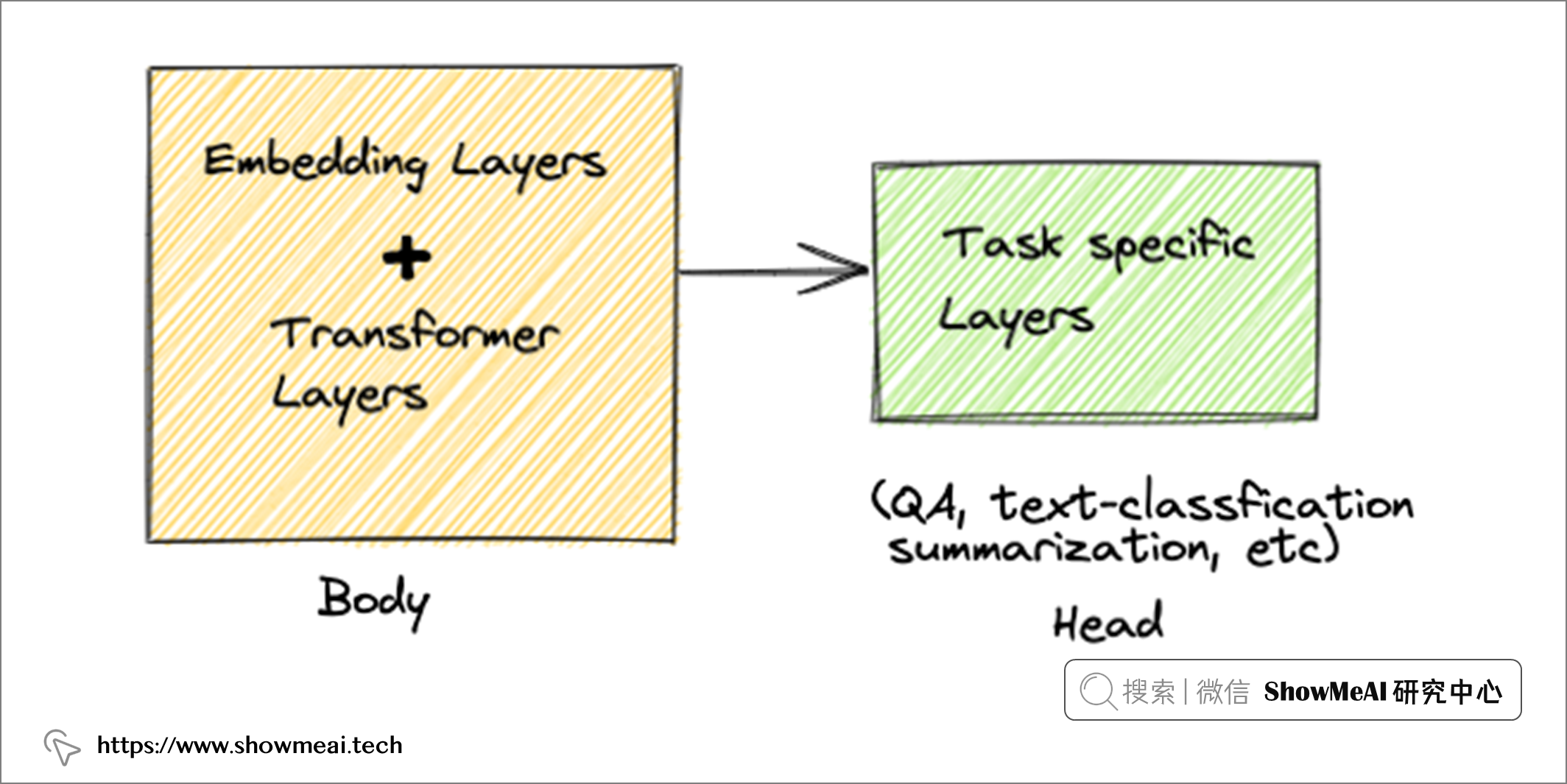
transformer 系列的模型有很多隐层,我们可以有很多方式获取文本的向量化表征,比如对最后的隐层做『平均池化』获得文本嵌入,我们也可以用倒数第二层或倒数第三层(它们在理论上较少依赖于训练语言模型的文本语料库)。
对文本做嵌入表示的示例代码如下:
# 大家可以先命令行执行下列代码安装sentence-transformers# pip install -U sentence-transformers from sentence_transformers import SentenceTransformer# 需要编码的文本内容列表sentences = ["This is example sentence 1", "This is example sentence 2"] # 编码,文本向量化嵌入表征model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')embeddings = model.encode(sentences)print(embeddings)
② 电子邮件附件:AI理解&处理
我们在这个解决方案中,单独把邮件附件拿出来做处理了。在有些处理方式中,会把附件的内容和正文直接拼接,用上面介绍的方式进行编码,但这样处理不够精细,可能有如下问题而导致最后模型效果不佳:
-
附件文本可能非常大,包含许多多余的内容,这些内容可能会淹没电子邮件正文中更重要的微妙细节。
-
对于意图检测而言,重要的是文档的性质或类型,而不是详细的内容。
基于上述考虑,我们单独训练附件分类器来生成附件的密集向量表示。可能我们的附件包含不规则的 PDF 或者图片,我们可能要考虑用 OCR 引擎(例如 Tesseract)进行识别和提取部分内容,
假设我们的附件数量为N,DC 是经过训练的附件分类器。DC对每个附件预测处理输出一个向量(文档类型分布概率向量)。 由于最终的附件向量表示需要具有固定长度(但是N是不确定的),我们在附件维度上使用最大池化得到统一长度的表征。
以下是为给定电子邮件生成附件向量化表征的代码示例:
# DC是文档分类器distributions = []for attachment in attachments: current_distribution = DC(attachent) distributions.append(current_distribution)np_distributions = np.array(distributions) #维度为(X,N)的附件向量组attachments_feat_vec = np.max(np_distributions, axis=0) #最大池化
③ 搭建多数据源混合网络
下面部分使用到了TensorFlow工具库,ShowMeAI 制作了快捷即查即用的工具速查表手册,大家可以在下述位置获取:
在上述核心输入处理和表征后,我们就可以使用 Tensorflow 构建一个多分支神经网络了。参考代码如下:
def build_hybrid_mo_model(bert_input_size, att_features_size, nb_classes): emb_input = tf.keras.Input(shape=(bert_input_size,), name="text_embeddings_input") att_classif_input = tf.keras.Input(shape=(att_features_size,), name="attachments_repr_input") DenseEmb1 = tf.keras.layers.Dense(units=256, activation='relu')(emb_input) compressed_embs = tf.keras.layers.Dense(units=32, activation='relu', name="compression_layer")(DenseEmb1) combined_features = tf.keras.layers.concatenate([compressed_embs,att_classif_input], axis=1) Dense1= tf.keras.layers.Dense(units=128)(combined_features) Dense2= tf.keras.layers.Dense(units=128)(Dense1) out1 = tf.keras.layers.Dense(units=nb_classes, name="intention_category_output")(Dense2) out2 = tf.keras.layers.Dense(units=1, name="information_request_output")(Dense2) model = tf.keras.Model(inputs=[emb_input,att_classif_input], outputs=[out1, out2]) losses = { "intention_category_output" : tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), "information_request_output" : tf.keras.losses.BinaryCrossentropy(from_logits=True)} model.compile(optimizer="adam",loss= losses, metrics=["accuracy"]) print (model.summary()) return model
构建完模型之后,可以通过tf.keras.utils.plot_model打印出模型架构,如下图所示:
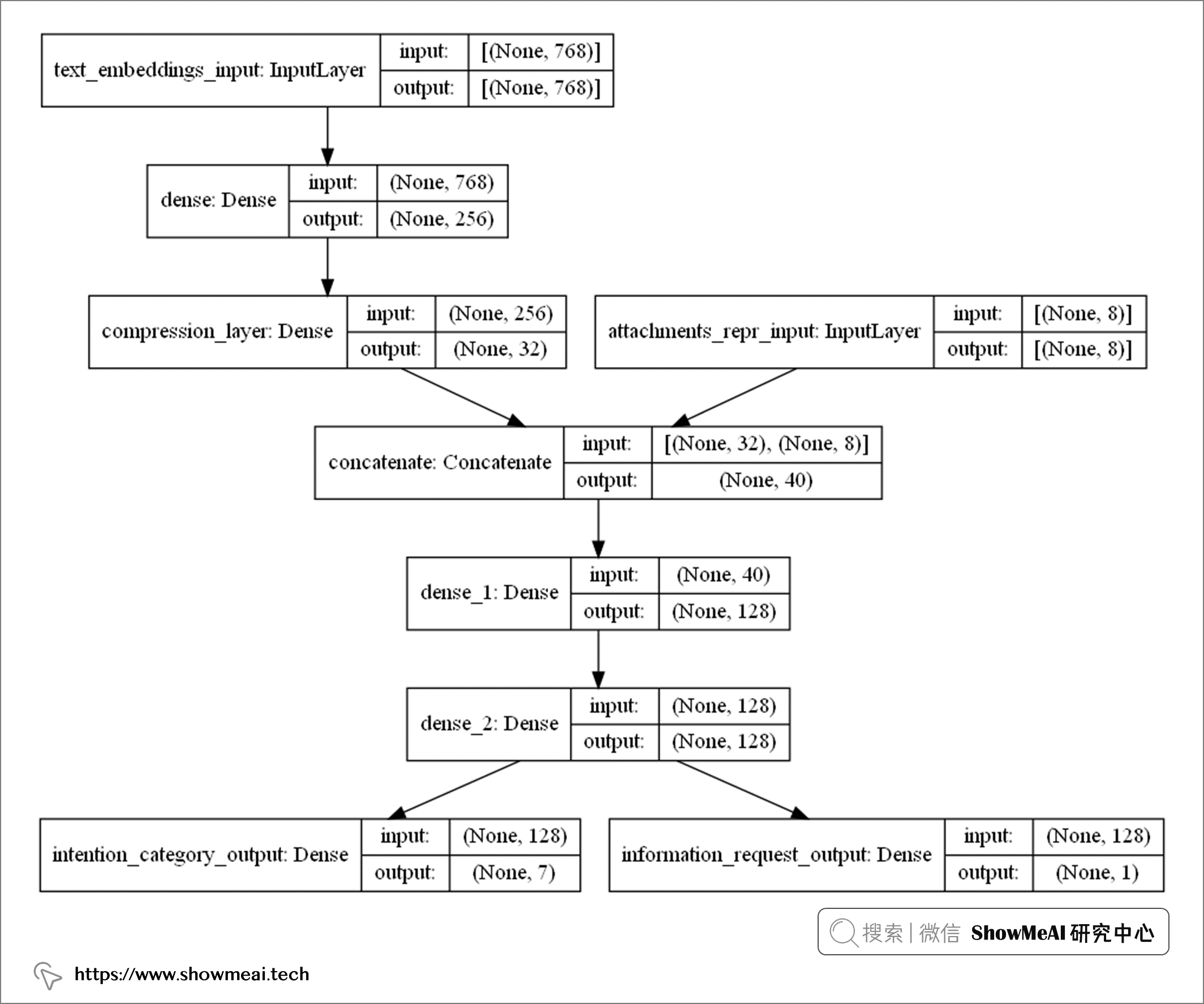
上图的模型架构,和我们在『架构初览』板块的设计完全一致,它包含更多的细节信息:
- 电子邮件正文文本嵌入,维度为768维
- 附件文件包含8种类型,向量化表征为8维
模型的输出部分包含:
- 7个主要意图
- 1个次要意图
④ 训练&评估
作为测试,作者在银行业务相关电子邮件的专有数据集上训练了模型,具体情况如下:
- 数据集由 1100 封电子邮件组成,包含 7 个主要意图,但分布不均。
- 构建的神经网络包含 22.7w 个参数( 具体细节如上图,大家也可以通过model.summary()输出模型信息)。
- 以batch size大小为32训练了 50 个 epoch
- 实际没有使用到GPU,在16核的CPU上做的训练(但大家使用GPU一定有更快的速度)
- 主要意图分类任务上达到了 87% 的加权 F1 分数平均值。如果不使用附件,加权 F1 分数平均值降低10%。(可见2部分信息都非常重要)
我们通过对电子邮件自动意图识别和归类场景进行分析和处理,构建了有效的混合网络高效地完成了这个任务。这里面非常值得思考的点,是不同类型的数据输入与预处理,合适的技术选型(并非越复杂越好),充分又恰当的输入信息融合方式。
大家在类似的场景问题下,还可以尝试不同的正文预处理和附件分类模型,观察效果变化。其余的一些改进点包括,对于预估不那么肯定(概率偏低)的邮件样本,推送人工审核分类,会有更好的效果。
- 📘 AI实战 | 基于NLP文档嵌入技术的基础文本搜索引擎构建:https://showmeai.tech/article-detail/321
- 📘 TensorFlow 速查手册:https://www.showmeai.tech/article-detail/109
- 📘 深度学习教程:吴恩达专项课程 · 全套笔记解读:https://www.showmeai.tech/tutorials/35
- 📘 深度学习教程 | 自然语言处理与词嵌入:https://www.showmeai.tech/article-detail/226
- 📘 NLP教程 | 斯坦福CS224n · 课程带学与全套笔记解读:https://www.showmeai.tech/tutorials/36
- 📘 NLP教程(1) - 词向量、SVD分解与Word2Vec:https://www.showmeai.tech/article-detail/230
- 📘 NLP教程(2) - GloVe及词向量的训练与评估:https://www.showmeai.tech/article-detail/232
- 📘 TF-iDF:https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
- 📘 PCA:https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
- 📘 Doc2Vec:https://radimrehurek.com/gensim/models/doc2vec.html
- 📘 BERT:[https://huggingface.co/docs/transformers/model_doc/bert](https://huggingface.co/docs/transformers/model_doc/bert)
- 📘 HuggingFace:https://huggingface.co/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK