

AlphaZero的黑箱打开了!DeepMind论文登上PNAS
source link: https://www.51cto.com/article/740208.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

AlphaZero的黑箱打开了!DeepMind论文登上PNAS
国际象棋一直是 AI 的试验场。70 年前,艾伦·图灵猜想可以制造一台能够自我学习并不断从自身经验中获得改进的下棋机器。上世纪出现的「深蓝」第一次击败人类,但它依赖专家编码人类的国际象棋知识,而诞生于 2017 年的 AlphaZero 作为一种神经网络驱动的强化学习机器实现了图灵的猜想。
AlphaZero 无需使用任何人工设计的启发式算法,也不需要观看人类下棋,而是完全通过自我对弈进行训练。
那么,它真的学习了人类关于国际象棋的概念吗?这是一个神经网络的可解释性问题。
对此,AlphaZero 的作者 Demis Hassabis 与 DeepMind 的同事以及谷歌大脑的研究员合作了一项研究,在 AlphaZero 的神经网络中找到了人类国际象棋概念的证据,展示了网络在训练过程中获得这些概念的时间和位置,还发现了 AlphaZero 与人类不同的下棋风格。论文近期发表于 PNAS。

论文地址:https://www.pnas.org/doi/epdf/10.1073/pnas.2206625119
AlphaZero 在训练中获得人类象棋概念
AlphaZero 的网络架构包含一个骨干网络残差网络(ResNet)和单独的 Policy Head、Value Head,ResNet 由一系列由网络块和跳跃连接(skip connection)的层构成。
在训练迭代方面,AlphaZero 从具有随机初始化参数的神经网络开始,反复与自身对弈,学习对棋子位置的评估,根据在此过程中生成的数据进行多次训练。
为了确定 AlphaZero 网络在多大程度上表征了人类所拥有的国际象棋概念,这项研究使用了稀疏线性探测方法,将网络在训练过程中参数的变化映射为人类可理解概念的变化。
首先将概念定义为如图 1 中橙色所示的用户定义函数。广义线性函数 g 作为一个探针被训练用于近似一个国际象棋概念 c。近似值 g 的质量表示层(线性)对概念进行编码的程度。对于给定概念,对每个网络中所有层的训练过程中产生的网络序列重复该过程。
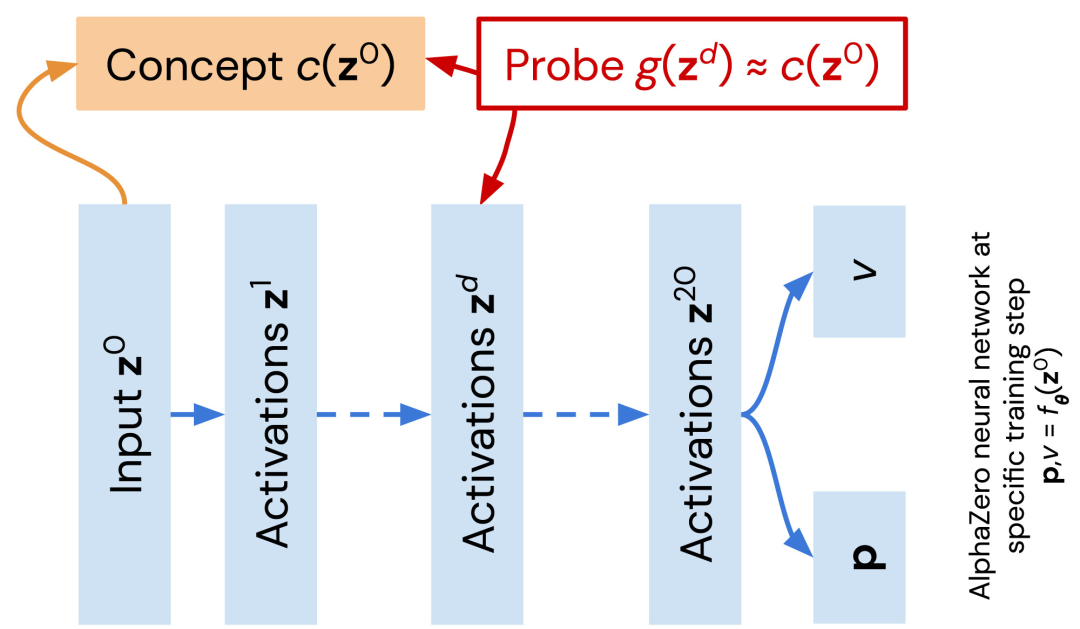
图 1:在 AlphaZero 网络(蓝色)中探索人类编码的国际象棋概念。
比如,可以用一个函数来确定我方或地方是否有「主教」 (♗) :
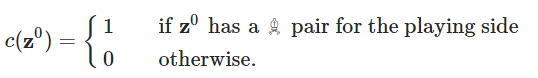
当然,还有很多比这个例子更复杂的象棋概念,比如对于棋子的机动性(mobility),可以编写一个函数来比较我方和敌方移动棋子时的得分。
在本实验中,概念函数是已经预先指定的,封装了国际象棋这一特定领域的知识。
接下来是对探针进行训练。研究人员将 ChessBase 数据集中 10 的 5 次方个自然出现的象棋位置作为训练集,从深度为 d 的网络激活训练一个稀疏回归探针 g,来预测给定概念 c 的值。
通过比较 AlphaZero 自学习周期中不同训练步骤的网络,以及每个网络中不同层的不同概念探针的分数,就可以提取网络学习到某个概念的时间和位置。
最终得到每个概念的 what-when-where 图,对「被计算的概念是什么」、「该计算在网络的哪个位置发生」、「概念在网络训练的什么时间出现」这三个指标进行可视化。如图2。
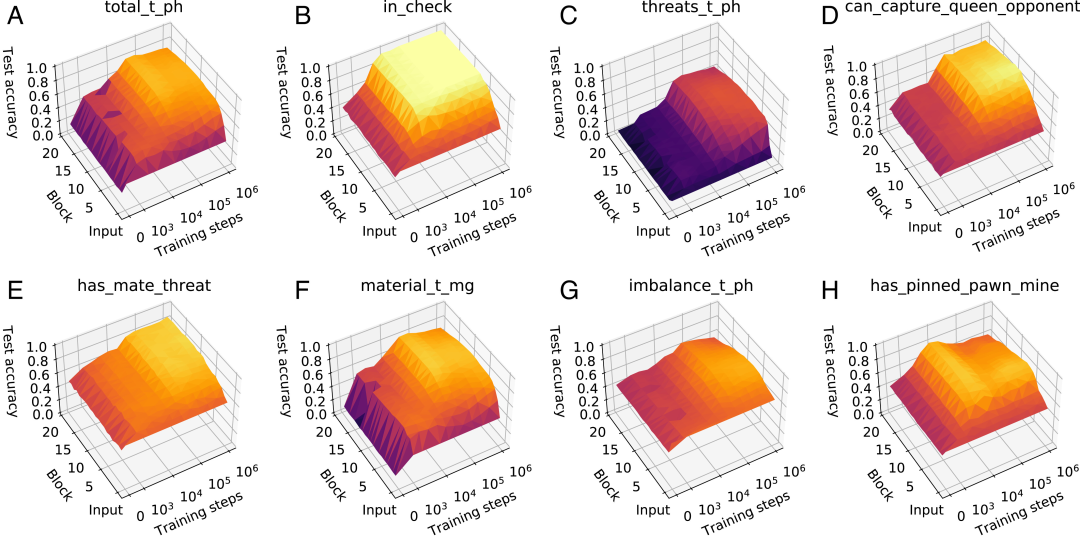
图2:从 A 到 B 的概念分别是「对总分的评估」、「我方被将军了吗」、「对威胁的评估」、「我方能吃掉敌方的皇后吗」、「敌方这一步棋会将死我方吗」、「对子力分数的评估」、「子力分数」、「我方有王城兵吗」。
可以看到,C 图中,随着 AlphaZero 变得更强,「threats」概念的函数和 AlphaZero 的表征(可由线性探针检测到)变得越来越不相关。
这样的 what-when-where 图包括探测方法比较所需的两个基线,一是输入回归,在第 0 层显示,二是来自具有随机权重的网络激活的回归,在训练步骤 0 处显示。上图的结果可以得出结论,回归精度的变化完全由网络表征的变化来决定。
此外,许多 what-when-where 图的结果都显示了一个相同的模式,即整个网络的回归精度一直都很低,直到大约 32k 步时才开始随着网络深度的增加而迅速提高,随后稳定下来并在后面的层中保持不变。所以,所有与概念相关的计算都在网络的相对早期发生,而之后的残差块要么执行移动选择,要么计算给定概念集之外的特征。
而且,随着训练的进行,许多人类定义的概念都可以从 AlphaZero 的表征中预测到,且预测准确率很高。
对于更高级的概念,研究人员发现 AlphaZero 掌握它们的位置存在差异。首先在 2k 训练步骤时与零显著不同的概念是「material」和「space」;更复杂的概念如「king_safety」、「threats」、「mobility」,则是在 8k 训练步骤时显著得变为非零,且在 32k 训练步骤之后才有实质增长。这个结果与图 2 中 what-when-where 图显示的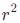 急剧上升的点一致。
急剧上升的点一致。
另外,大多数 what-when-where 图的一个显著特征是网络的回归精度在开始阶段增长迅速,随后达到平稳状态或下降。这表明目前从 AlphaZero 身上所发现的概念集还只是检测了网络的较早层,要了解后面的层,需要新的概念检测技术。
AlphaZero 的开局策略与人类不同
在观察到 AlphaZero 学习了人类国际象棋概念后,研究人员进一步针对开局策略探讨了 AlphaZero 对于象棋战术的理解,因为开局的选择也隐含了棋手对于相关概念的理解。

研究人员观察到,AlphaZero 与人类的开局策略并不相同:随着时间的推移,AlphaZero 缩小了选择范围,而人类则是扩大选择范围。
如图 3A 是人类对白棋的第一步偏好的历史演变,早期阶段,流行将 e4 作为第一步棋,后来的开局策略则变得更平衡、更灵活。
图 3B 则是 AlphaZero 的开局策略随训练步骤的演变。可以看到,AlphaZero 的开局总是平等地权衡所有选择,然后逐渐缩小选择范围。
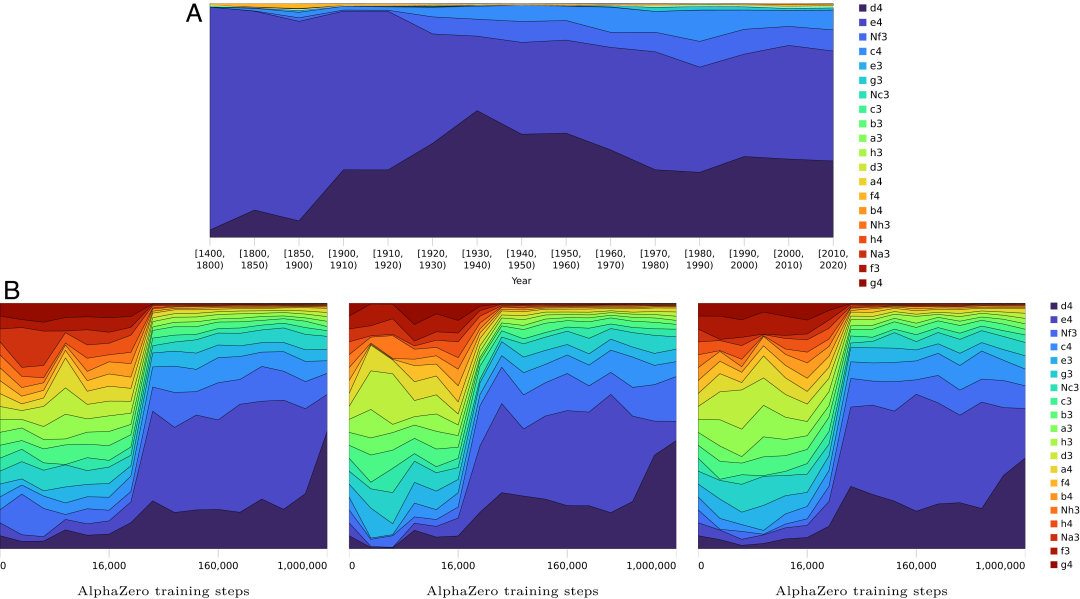
图 3:随着训练步骤和时间的推移,AlphaZero 和人类对第一步的偏好比较。
这与人类知识的演变形成鲜明对比,人类知识从 e4 开始逐渐扩展,而 AlphaZero 在训练的后期阶段明显偏向于 d4。不过,这种偏好不需要过度解释,因为自我对弈训练是基于快速游戏,为了促进探索增加了许多随机性。
造成这种差异的原因尚不清楚,但它反映了人类与人工神经网络之间的根本差异。一个可能的因素,或许是关于人类象棋的历史数据更强调大师玩家的集体知识,而 AlphaZero 的数据包括了初学者级别下棋和单一进化策略。
那么,当 AlphaZero 的神经网络经过多次训练后,是否会出对某些开局策略显示出稳定的偏好?
研究结果是,许多情况下,这种偏好在不同训练中并不稳定,AlphaZero 的开局策略非常多样。比如在经典的Ruy Lopez 开局(俗称「西班牙开局」)中,AlphaZero 在早期有选择黑色的偏好,并遵循典型的下法,即 1.e4 e5,2.Nf3 Nc6,3.Bb5。
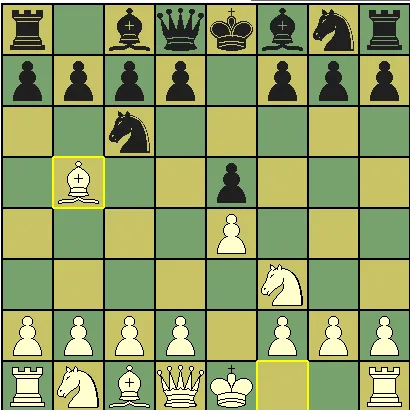
图 4:Ruy Lopez 开局
而在不同的训练中,AlphaZero 会逐渐收敛到 3.f6 和 3.a6 中的一个。此外,AlphaZero 模型的不同版本都各自显示出对一个动作的强烈偏好,且这种偏好在训练早期就得以建立。
这进一步证明,国际象棋的成功下法多种多样,这种多样性不仅存在于人与机器之间,也存在于 AlphaZero 的不同训练迭代中。
AlphaZero 掌握知识的过程
那么,以上关于开局策略的研究结果,与 AlphaZero 对概念的理解有什么关联呢?
这项研究发现,在各种概念的 what-when-where 图中有一个明显的拐点,与开局偏好的显著变化正好相吻合,尤其是 material 和 mobility的概念似乎与开局策略直接相关。
material 概念主要是在训练步骤 10k 和 30k 之间学习的,piece mobility 的概念也在同一时期逐步融入到 AlphaZero 的 value head 中。对棋子的 material 价值的基本理解应该先于对棋子 mobility 的理解。然后 AlphaZero 将这一理论纳入到 25k 到 60k 训练步骤之间开局偏好中。
作者进一步分析了 AlphaZero 网络关于国际象棋的知识的演变过程:首先发现棋力;接着是短时间窗口内基础知识的爆炸式增长,主要是与 mobility 相关的一些概念;最后是改进阶段,神经网络的开局策略在数十万个训练步骤中得到完善。虽然整体学习的时间很长,但特定的基础能力会在相对较短的时间内迅速出现。
前国际象棋世界冠军 Vladimir Kramnik 也被请来为这一结论提供佐证,他的观察与上述过程一致。
最后总结一下,这项工作证明了 AlphaZero 网络所学习的棋盘表示能够重建许多人类国际象棋概念,并详细说明了网络所学习的概念内容、在训练时间中学习概念的时间以及计算概念的网络位置。而且,AlphaZero 的下棋风格与人类并不相同。
既然我们以人类定义的国际象棋概念来理解神经网络,那么下一个问题将会是:神经网络能够学习人类知识以外的东西吗?
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK