

数据治理丨埋点上线前中后,数据分析师的工作有哪些
source link: https://www.woshipm.com/data-analysis/5679108.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

数据治理丨埋点上线前中后,数据分析师的工作有哪些
一个埋点的上线,一般可以分成需求阶段、埋点需求评审 / 埋点开发、灰度测试、正式上线这四个阶段,在这些环节中,数据分析师的重要价值和工作内容是怎么样的呢?本文作者对此作出了分析,一起来看一下吧。

昨天面试了一个偏数据基建和治理的分析岗位,结合昨天的面试问题,对埋点全流程中,数据分析师的角色定位和主要做的事情做一个梳理,也对上个阶段关于这部分的工作内容浅做一个总结~
顺便也对市面上拥有较成熟的埋点平台的大厂的公开资料做了了解。这个系列估计还可以有很多延伸,比如埋点的设计规范和把控,成熟的埋点平台可以解决那些问题……
当然每个公司人员分工会有细节上的不同,但是初心一定是提升埋点质量,更好的沉淀数据资产。
首先来看一下一个埋点上线全流程及涉及的具体人员,我们可以看到一个埋点的上线通常可以分成四个阶段:需求阶段 → 埋点需求评审 / 埋点开发 → 灰度测试 → 正式上线。
接下来我们来看看各个环节数据分析师的主要价值和工作内容是怎么样的。
一、需求阶段
这个阶段通常会有两种场景,一种是业务方/分析师自身需要统计某种数据于是找到分析师,分析师首先要判断现有埋点是否能支持该需求,如不能且判断需求价值高,可由分析师发起新埋点需求,或者对旧埋点做增补。
第二类则是伴随产品功能迭代/新功能上线,也是实际工作场景中更为常见的一种。通常功能产品经理需要预先产出PRD和原型图,做出初版的DRD(数据需求文档)。
因为每个人的埋点习惯不同,单单由功能产品负责这一环可能会出现漏埋错埋,或者对历史埋点不了解重复造轮子等现象,所以需要与数据产品进行一轮沟通,由数据产品来把控埋点是否可以和历史埋点做兼容。
对于较为重要影响面较广的项目,数据分析同学也需要在这一环节提前参与进来,作为分析师,首先需要明确现阶段埋点要统计的有哪些指标(尤其是确保功能的目标提升指标可以被统计到),其次要对未来有哪些数据分析需求预判,哪怕现在不需要,未来规划中有需要的也要保留下来。
举个栗子,比如某次某业务首页做改版,用户首次进入该业务需要选择内容偏好标签,后续分析首页改版时分析师可能暂时不会对用户的标签做细节分析,而主要更关注首页改版对用户行为(比如内容渗透率,留存率)是否有正向影响,但是这类选择信息可以为算法同学后续统计用户内容偏好提供一定信息,所以设计埋点时就需要统计到。
埋点设计过程中,我的习惯是先做加法,再做减法。首先力求能简洁完整的概括用户行为,对于后续分析不大可能涉及的属性要敢于「断舍离」。
数据分析师判断埋点可以满足业务需求,数据产品判断埋点可以被很好的吸纳到现有的埋点体系,功能产品回去「改作业」后二次确认,就可以进入需求评审环节了。
这一环,有两个细节需要数据产品&分析师格外注意。
1. 埋点易用性
此外,埋点设计除了考虑到自身使用的易用性,也要尽量考虑到业务方的易用性,所以分析师除了要熟练使用代码语言查询数据,也要尽可能让埋点在数据工具(前司为例,使用神策)上更好用。
这也要求数据分析师对数据工具有比业务方更深的了解,不要只依赖一种方法解决问题,这样做有两点好处:
1)可以对业务方能否自身处理需求有更好的判断,不然人说不能做 / 做起来效率低,你对这工具自己都用不利落,怎么判断到底能不能做呢。
2)不断帮助业务方提升自己使用数据工具解决问题的能力,确定好两者边界,才能腾出手来做更多只有分析师可以做到的事情。
举个简单的例子,一个运营活动主会场需要更换n轮,每个主会场都要求开发单独开发,这时候有两种方案:
1)每个会场的浏览和点击都采用单独的埋点事件,比如:活动a_浏览,活动b_浏览。
2)使用两个公用事件,在事件属性中去做细分,比如:活动_浏览,属性增加活动名称,限制a/b。
这时候需求来了,运营想知道有多少用户是两场活动都有参与的。代码层面,两种埋点设计都可以很容易的解决问题。但是如果在数据工具中需要对两个事件取交集就相对比较麻烦了,当然用虚拟事件也可以解决问题,代价是每增加一个会场就得维护虚拟事件,灵活性很差。这时候用属性去限制活动的好处就凸显出来了。
2. 评估多方业务诉求
作为数据分析,我们要了解不同的业务方诉求。比如产品需要考量功能本身的使用情况和漏斗转化效率,用户运营同学会考量功能上线对用户的后续影响,比如对用户的后续留存是否有帮助,开发需要对产品性能和体验做评估,比如会考虑埋点:应用响应时长,应用崩溃率。
作为分析师,需要对各方诉求逐一了解并完成整合。
二、需求评审 & 开发阶段
这一环,数据分析师可以先干点儿别的,需要咱们处理的不多。功能产品需要在需求评审给开发讲解PRD和埋点需求,对于「能埋不能埋」/「需要换方案」的情况也做一轮反馈。
如果开发提出不能埋的埋点对业务很重要,数据分析也需要介入进来,说明该埋点对于业务的关键性,推进工作顺利进行。对于比较重要的功能改版,也可以考虑在需求评审阶段就介入,协助产品经理一起解答开发伙伴对于一些埋点的疑问。
三、埋点测试阶段
等到开发自测完成,埋点就进入灰度测试阶段。通常开发会进行一轮自测,而后交给测试小伙伴做测试。但因为目前一些测试的习惯还是以功能测试为主,对于比较重要的功能/项目,数据分析师也可以主动加入灰度测试。
不同公司在不同业务发展阶段有不同的测试方式,这里援引迪普老师的总结图如下:
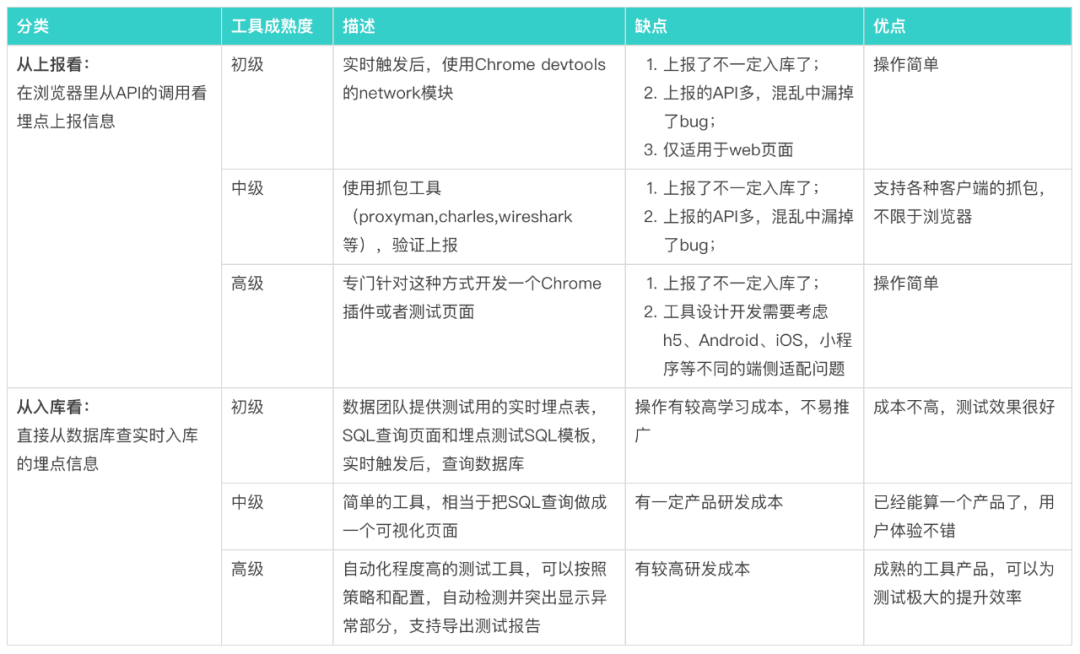
而作为神策用户,我们通常是在测试环境里直接在app里手动模拟真实用户行为,去看用户实时日志情况。通常我们需要做以下信息的验收:
1)验收用户标识在一系列事件中是否连贯过往我们就曾有用户进入某h5页面其用户标识失效的情况。
2)验收事件是否重复上报 / 漏报
3)验收事件触发时间 / 上报时机 / 上报顺序是否正确主要是为了保障漏斗分析的可用性,本来用户是进了商品详情页才购买,你愣是先报购买才报进商品详情页,这漏斗可就歇菜了。
4)验收是否所有属性都有上报
验收上报的属性是否符合预期,主要包括以下几点:
- 内容是否符合预期
- 字段格式是否符合预期
- 是否有空值
而后对上报有误的信息做反馈。这个环节对于数据分析师来说往往是很折磨人的,既害怕验不出问题(万一没验出问题,上线才发现问题修改周期长),又害怕验出问题(要反馈开发小伙伴修改,改完还得重验)。
等到各方确定功能/埋点都没问题了,产品顺利发版。严谨一点的话,测试完成后最好设计一定的测试用户白名单机制,在日志层面对测试用户的信息做清除。
四、上线阶段
发版以后是否就万事大吉了呢?测试环境毕竟咱们只有有限的设备,对用户变化多端的设备/网络/以及其他复杂场景缺少预判,所以实际上线以后我们还要继续紧盯数据,不可懈怠。
主要的监控方向和灰度环节的验收一致,但是会站在数据分析的视角来看,出现问题再去详查具体数据,监控的主要粒度和方式如下:
平台(安卓,IOS等):首先对平台做拆分是因为很多场景下安卓/IOS的开发是由不同团队负责的,发现问题便于反馈;此外,虽然两端用户行为有一定差异,但一端出问题另一端完好的情况下,也可以互为对比参考。
搭建漏斗检验关键流程是否顺畅,对比漏斗各环数据情况和独立事件实际触发情况:这是作为数据分析师的主要武器,不但可以对事件的上报顺序和时间做一轮验证,也可以对用户标识是否连贯做验证,同时也检验事件是否出现多报 / 少报。
举个例子,一个通用的业务场景是,业务同学常常反馈「某事件作为独立事件触发数远高于在漏斗中的触发数」,排除对起点事件的入口的穷举不到位,大多由以上几种原因导致。
之前检验出一个较为严重的bug,就是通过漏斗分析发现的,大意是没有点击tab的用户也触发了该tab页面曝光,后来经过数据产品同学几轮精细排查,才发现是因为安卓端tab两端页面存在预加载现象,比如tab顺序为a,b,c时,用户点击tab b,a和c也会触发曝光埋点。还有一个case是业务反馈付费用户数在漏斗中大幅下降,但付费用户数未见明显下滑,后来发现当日出现了大量日志堆积现象,导致了上报时间混乱影响了漏斗数据。
检验事件属性值的分布情况:主要是为了排查属性内容是否符合预期,是否上传大量空值。一个case是运营同学反馈某个内容的播放数据后期出现暴跌,后来发现是某一天后台修改了该内容的名称,所以当属性名称本来应该有a,b,c,哪天突然变成a,b,d,我们也应该引起警觉
在数仓日志层面做检查,主要分成以下几种维度:检查重复数据条数,总日志数波动情况,区分「具体事件」和「具体属性」的数据波动情况。
主要排查是否出现大量重复上报,注意重复上报的数据也未必是一条数据长得一毛一样,有时候可能是大体一致但个别字段有差异,这种情况仍然值得我们仔细排查原因。对于埋点健康,在数仓层面,我们也可以设计一定的指标去做监控,比如事件属性错误率(根据埋点文档约束的实际期望内容),事件属性新增字段占比,字段非空占比,重复值个数等,好对异常情况进行报警。
另外,除了本埋点的验证,我们还需要做好关键指标的回归测试,即判断新埋点上线有没有影响核心埋点的数据上报。关键指标不宜太多,否则也会造成一定的人力浪费,关注app主路径行为即可。
回归测试主要是防止合并代码过程中影响到核心埋点,这一块常常被忽略,但出现问题往往后果又很严重,成熟的埋点平台大多支持采用通用规则去进行自动化的回归测试。
埋点反馈「礼仪」
最后,提一下反馈问题的「礼仪」。也许我们未必要做到这么精细,但是有余力的情况下,做到这么精细解决问题的效率更高。
我们反馈埋点问题时不要只说现象,尽量自己先初步排查原因,缩小范围,比如问题什么时候/什么版本出现的(帮忙定位出现问题的版本),什么平台(ios/安卓)?提供案例用户(如果两端都有问题,最好ios和安卓各提供一个)和相关代码,适当看日志,结合数仓取数结果给出自己的猜想。
反馈问题不是把问题丢出去就完了,既然最终目标是解决问题,想推动问题的解决,你就要深入了解问题如何发生,尽量帮忙一起解决问题。
有些问题的发现,本来就是一个小分析,对于提升我们的数据分析思维也是有裨益的。
当然,埋点出现问题的场景非常多,错误方式也五花八门,没有一套方法论能覆盖掉所有问题,所以要求我们对平时出现的问题场景,有意识做沉淀和积累,提升解决埋点问题的效率。
Reference:
[1]爱奇艺埋点投递治理实践,i技术会
[2]严选埋点质量保障体系建设,严选技术
[3]埋点系列-埋点数据质量如何保障,迪普观点
本文由 @Ver 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK