

OpenHarmony集成OCR三方库实现文字提取
source link: https://www.51cto.com/article/722829.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
OpenHarmony集成OCR三方库实现文字提取

Tesseract (Apache 2.0 License)是一个可以进行图像OCR识别的C++库,可以跨平台运行 。本样例基于Tesseract 库进行适配,使其可以运行在 OpenAtom OpenHarmony(以下简称“OpenHarmony”)上,并新增N-API接口供上层应用调用,这样上层应用就可以使用Tesseract提供的相关功能。
二、效果展示
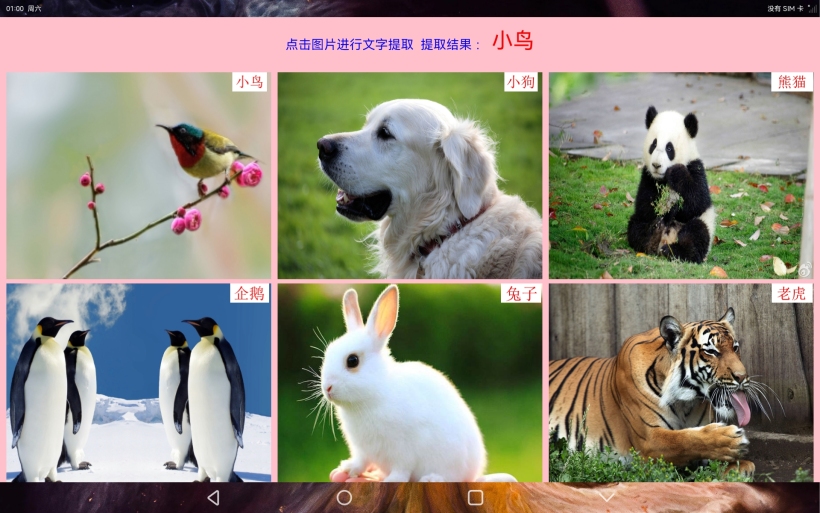
动物图片识别文字
身份信息识别:

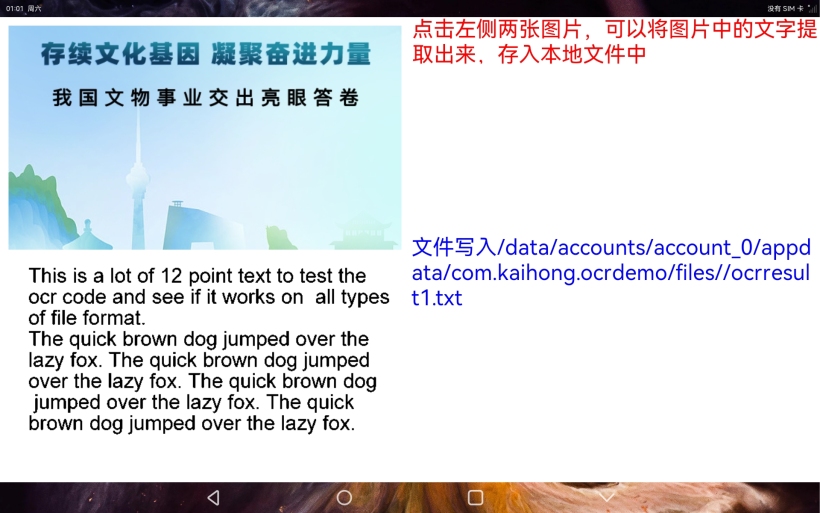
提取文字信息到本地文件:
相关代码已经上传至SIG仓库,链接如下:
https://gitee.com/openharmony-sig/knowledge_demo_temp/tree/master/FA/OCRDemo。
三、目录结构
四、调用流程
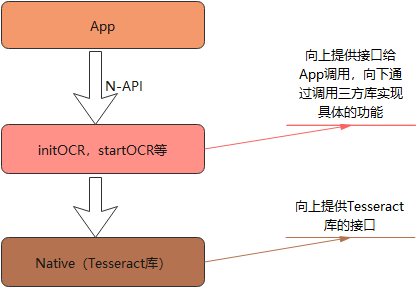
调用过程主要涉及到三方面,首先应用层实现样例的效果,包括页面的布局和业务逻辑代码;中间层主要起桥梁的作用,提供N-API接口给应用调用,再通过三方库的接口去调用具体的实现;Native层使用了三方库Tesseract提供具体的实现功能。
五、源码分析
本样例源码的分析主要涉及到两个方面,一方面是N-API接口的实现,另一方面是应用层的页面布局和业务逻辑。
N-API实现
1、首先在index.d.ts文件中定义好接口
/**
* 初始化文字识别引擎
* @param lang 识别的语言, eg:eng、chi_sim、 eng+chi_sim,为Null或不传则为中英文(eng+chi_sim)
* @param trainDir 训练模型目录,为Null或不传则为默认目录
*
* @return 初始化是否成功 0=>成功,-1=>失败
*/
export const initOCR: (lang: string, trainDir: string) => Promise<number>;
export const initOCR: (lang: string, trainDir: string, callback: AsyncCallback<number>) => void;
/**
* 开始识别
* @param imagePath 图片路径(当前支持的图片格式为png, jpg, tiff)
*
* @return 识别结果
*/
export const startOCR: (imagePath: string) => Promise<string>;
export const startOCR: (imagePath: string, callback: AsyncCallback<string>) => void;
/**
* 销毁资源
*/
export const destroyOCR: () => void;代码中可以看出N-API接口initOCR和startOCR都采用了两种方式,一种是Promise,一种是Callback的方式。在样例的应用层,使用的是它们的Callback方式。
2、注册N-API模块和接口
EXTERN_C_START
static napi_value Init(napi_env env, napi_value exports) {
napi_property_descriptor desc[] = {
{
"initOCR", nullptr, InitOCR, nullptr, nullptr, nullptr, napi_default, nullptr
},
{
"startOCR", nullptr, StartOCR, nullptr, nullptr, nullptr, napi_default, nullptr
},
{
"destroyOCR", nullptr, DestroyOCR, nullptr, nullptr, nullptr, napi_default, nullptr
},
{
};
napi_define_properties(env, exports, sizeof(desc) / sizeof(desc[0]), desc);
return exports;
}
EXTERN_C_END
static napi_module demoModule = {
.nm_version = 1,
.nm_flags = 0,
.nm_filename = nullptr,
.nm_register_func = Init,
.nm_modname = "tesseract",
.nm_priv = ((void *)0),
.reserved = {
0
},
};
extern "C" __attribute__((constructor)) void RegisterHelloModule(void) {
napi_module_register(& demoModule);
}通过nm_modname定义模块名,nm_register_func注册接口函数,在Init函数中指定了JS中initOCR,startOCR,destroyOCR对应的本地实现函数,这样就可以在对应的本地实现函数中调用三方库Tesseract的具体实现了。
3、以startOCR的Callback方式为例介绍N-API中的具体实现
static napi_value StartOCR(napi_env env, napi_callback_info info) {
OH_LOG_ERROR(LogType::LOG_APP, "OCR StartOCR 111");
size_t argc = 2;
napi_value args[2] = { nullptr };//1. 获取参数
napi_get_cb_info(env, info, &argc, args, nullptr, nullptr);
//2. 共享数据
auto addonData = new StartOCRAddOnData{
.asyncWork = nullptr,
};
//3. N-API类型转成C/C++类型
char imagePath[1024] = { 0 };
size_t length = 0;
napi_get_value_string_utf8(env, args[0], imagePath, 1024, &length);
addonData->args0 = string(imagePath);
napi_create_reference(env, args[1], 1, &addonData->callback);
//4. 创建async work
napi_value resourceName = nullptr;
napi_create_string_utf8(env, "startOCR", NAPI_AUTO_LENGTH, &resourceName);
napi_create_async_work(env, nullptr, resourceName, executeStartOCR, completeStartOCRForCallback, (void *)addonData, &addonData->asyncWork);
//将创建的async work加到队列中,由底层调度执行
napi_queue_async_work(env, addonData->asyncWork);
napi_value result = 0;
napi_get_null(env, &result);
return result;
}首先通过napi_get_cb_info方法获取JS侧传入的参数信息,将参数转成C++对应的类型,然后创建异步工作,异步工作的方法参数中包含,执行的函数以及函数执行完成的回调函数。
我们看一下执行函数:
static void executeStartOCR(napi_env env, void* data) {
//通过data来获取数据
StartOCRAddOnData * addonData = (StartOCRAddOnData *)data;
napi_value resultValue;
try {
if (api != nullptr) {
//调用具体的实现,读取图片像素
PIX * pix = pixRead((const char*)addonData->args0.c_str());
//设置api的图片像素
api->SetImage(pix);
//调用文字提取接口,获取图片中的文字
char * result = api->GetUTF8Text();
addonData->result = result;
//释放资源
pixDestroy (& pix);
delete[] result;
}
} catch (std::exception e) {
std::string error = "Error: ";
if (initResult != 0) {
error += "please first init tesseractocr.";
} else {
error += e.what();
}
addonData->result = error;
}
}这个方法中通过data获取JS传入的参数,然后调用Tesseract库中提供的接口,调用具体的文字提取功能,获取图片中的文字。
执行完成后,会回调到completeStartOCRForCallback,在这个方法中会将执行函数中返回的结果转换为JS的对应类型,然后通过Callback的方式返回。
static void completeStartOCRForCallback(napi_env env, napi_status status, void * data) {
StartOCRAddOnData * addonData = (StartOCRAddOnData *)data;
napi_value callback = nullptr;
napi_get_reference_value(env, addonData->callback, &callback);
napi_value undefined = nullptr;
napi_get_undefined(env, &undefined);
napi_value result = nullptr;
napi_create_string_utf8(env, addonData->result.c_str(), addonData->result.length(), &result);
//执行回调函数
napi_value returnVal = nullptr;
napi_call_function(env, undefined, callback, 1, &result, &returnVal);
//删除napi_ref对象
if (addonData->callback != nullptr) {
napi_delete_reference(env, addonData->callback);
}
//删除异步工作项
napi_delete_async_work(env, addonData->asyncWork);
delete addonData;
}应用层实现
应用层主要分为三个模块:动物图片文字识别,身份信息识别,提取文字到本地文件
1、动物图片文字识别
build() {
Column() {
Row() {
Text('点击图片进行文字提取 提取结果 : ').fontSize('30fp').fontColor(Color.Blue)
Text(this.ocrResult).fontSize('50fp').fontColor(Color.Red)
}.margin('10vp').height('10%').alignItems(VerticalAlign.Center)
Grid() {
ForEach(this.images, (item, index) => {
GridItem() {
AnimalItem({
path1: item[0],
path2: item[1]
});
}
})
}
.padding({left: this.columnSpace, right: this.columnSpace})
.columnsTemplate("1fr 1fr 1fr") // Grid宽度均分成3份
.rowsTemplate("1fr 1fr") // Grid高度均分成2份
.rowsGap(this.rowSpace) // 设置行间距
.columnsGap(this.columnSpace) // 设置列间距
.width('100%')
.height('90%')
}
.backgroundColor(Color.Pink)
}布局主要使用了Grid的网格布局,每个Item都是对应的图片,通过点击图片可以对点击图片进行文字提取,将提取出的文字显示在标题栏。
2、身份信息识别
build() {
Row() {
Column() {
Image('/common/idImages/aobamao.jpg')
.onClick(() => {
//点击图片进行信息识别
console.log('OCR begin dialog open 111');
this.ocrDialog.open();
ToolUtils.ocrResult(ToolUtils.aobamao, (result) => {
console.log('111 OCR result = ' + result);
this.result = result;
this.ocrDialog.close();
});
})
.margin('10vp')
.objectFit(ImageFit.Auto)
.height('50%')
Image('/common/idImages/weixiaobao.jpg')
.onClick(() => {
//点击图片进行信息识别
this.ocrDialog.open();
ToolUtils.ocrResult(ToolUtils.weixiaobao, (result) => {
console.log('111 OCR result = ' + result);
this.result = result;
this.ocrDialog.close();
});
})
.margin('10vp')
.objectFit(ImageFit.Auto)
.height('50%')
}
.width(this.screenWidth/2)
.padding('20vp')
Column() {
Text(this.title).height('10%').fontSize('30fp').fontColor(this.titleColor)
Column() {
Text(this.result)
.fontColor('#0000FF')
.fontSize('50fp')
}.justifyContent(FlexAlign.Center).alignItems(HorizontalAlign.Center).height('90%')
}
.justifyContent(FlexAlign.Start)
.width('50%')
}
.width('100%')
.height('100%')
}身份信息识别的布局最外层是一个水平布局,分为左右两部分,左边的子布局是垂直布局,里面是两张不同的身份证图片,右边子布局也是垂直布局,主要是标题区和识别结果的内容显示区。
3、提取文字到本地文件
Row() {
Column() {
Image('/common/save2FileImages/testImage1.png')
.onClick(() => {
//点击图片进行信息识别
ToolUtils.ocrResult(ToolUtils.testImage1, (result) => {
let path = this.dir + 'ocrresult1.txt';
try {
let fd = fileio.openSync(path, 0o100 | 0o2, 0o666);
fileio.writeSync(fd, result);
fileio.closeSync(fd);
this.displayText = '文件写入' + path;
} catch (e) {
console.log('OCR fileio error = ' + e);
}
});
})
Image('/common/save2FileImages/testImage2.png')
.onClick(() => {
//点击图片进行信息识别
ToolUtils.ocrResult(ToolUtils.testImage2, (result) => {
let path = this.dir + 'ocrresult2.txt';
let fd = fileio.openSync(path, 0o100 | 0o2, 0o666);
fileio.writeSync(fd, result);
fileio.closeSync(fd);
this.displayText = '文件写入' + path;
});
})
}
Column() {
Text(this.title)
Column() {
Text(this.displayText)
}
}
}这个功能首先通过接口识别出图片中的文字,然后再通过fileio的能力将文字写入文件中。
样例通过Native的方式将C++的三方库集成到应用中,通过N-API方式提供接口给上层应用调用。对于依赖三方库能力的应用,都可以使用这种方式来进行,移植三方库到Native,通过N-API提供接口给应用调用。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK