

elasticsearch聚合之bucket terms聚合 - huan1993
source link: https://www.cnblogs.com/huan1993/p/16886488.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

此处简单记录一下bucket聚合下的terms聚合。记录一下terms聚合的各种用法,以及各种注意事项,防止以后忘记。
2. 前置条件
2.1 创建索引
PUT /index_person
{
"settings": {
"number_of_shards": 1
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "keyword"
},
"sex": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"province": {
"type": "keyword"
},
"address": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
2.2 准备数据
PUT /_bulk
{"create":{"_index":"index_person","_id":1}}
{"id":1,"name":"张三","sex":"男","age":20,"province":"湖北","address":"湖北省黄冈市罗田县匡河镇"}
{"create":{"_index":"index_person","_id":2}}
{"id":2,"name":"李四","sex":"男","age":19,"province":"江苏","address":"江苏省南京市"}
{"create":{"_index":"index_person","_id":3}}
{"id":3,"name":"王武","sex":"女","age":25,"province":"湖北","address":"湖北省武汉市江汉区"}
{"create":{"_index":"index_person","_id":4}}
{"id":4,"name":"赵六","sex":"女","age":30,"province":"北京","address":"北京市东城区"}
{"create":{"_index":"index_person","_id":5}}
{"id":5,"name":"钱七","sex":"女","age":16,"province":"北京","address":"北京市西城区"}
{"create":{"_index":"index_person","_id":6}}
{"id":6,"name":"王八","sex":"女","age":45,"province":"北京","address":"北京市朝阳区"}
3. 各种聚合
3.1 统计人数最多的2个省
3.1.1 dsl
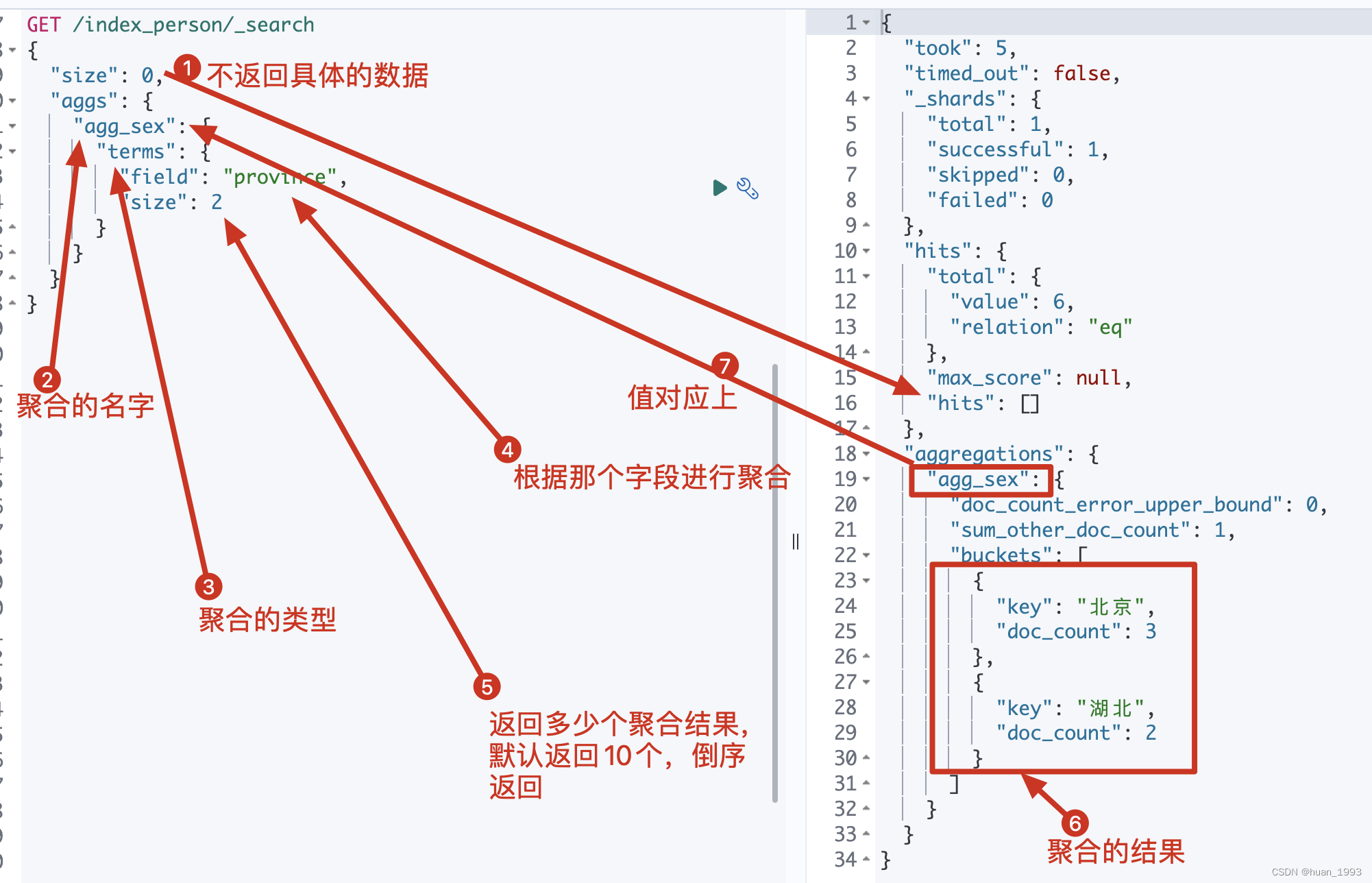
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_sex": {
"terms": {
"field": "province",
"size": 2
}
}
}
}
3.1.2 运行结果
3.2 统计人数最少的2个省
3.2.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_sex": {
"terms": {
"field": "province",
"size": 2,
"order": {
"_count": "asc"
}
}
}
}
}
注意: 不推荐使用 _count:asc来统计,会导致统计结果不准,看下方的总结章节。
3.2.2 运行结果
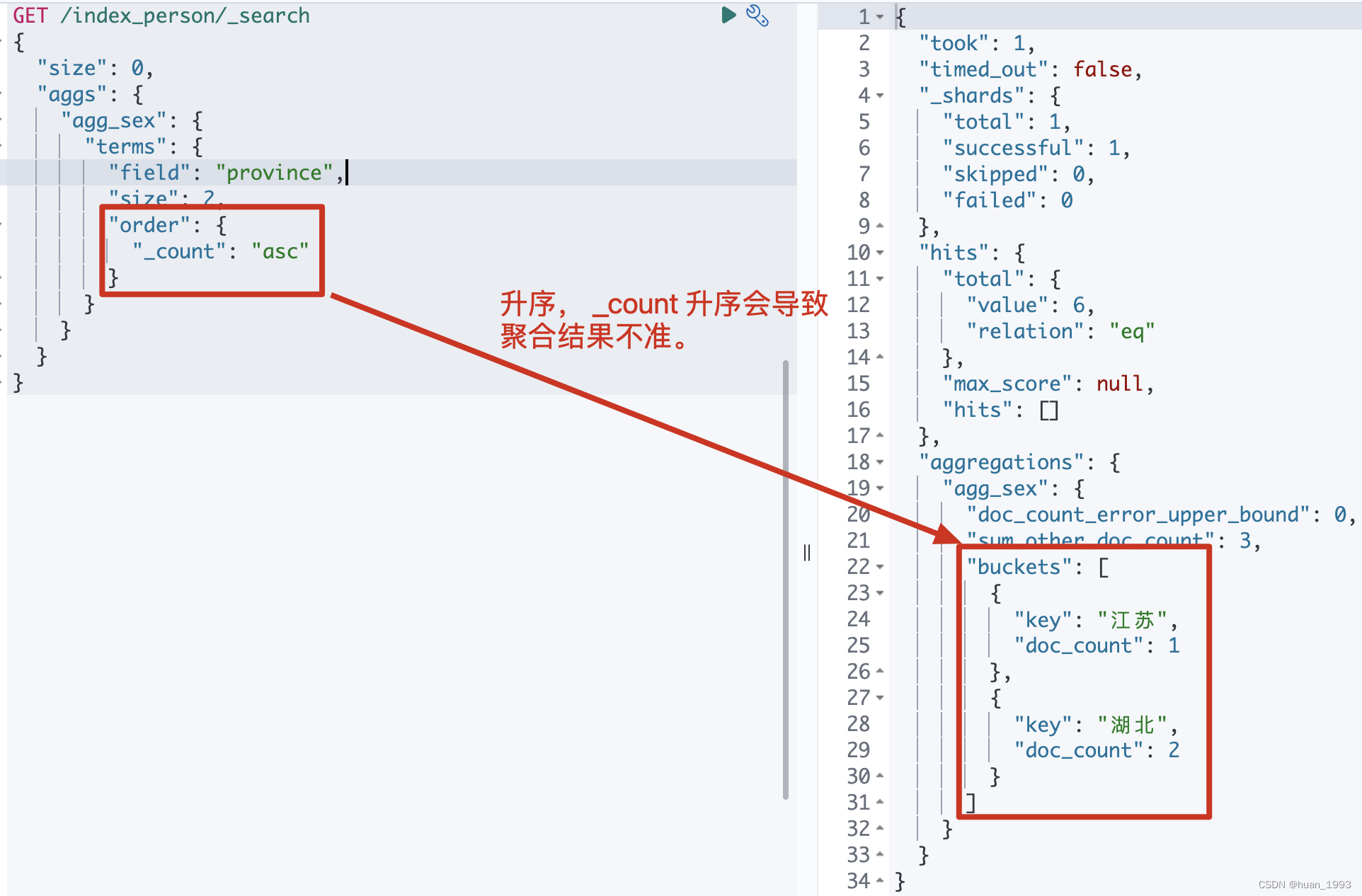
3.3 根据字段值排序-根据年龄聚合,返回年龄最小的2个聚合
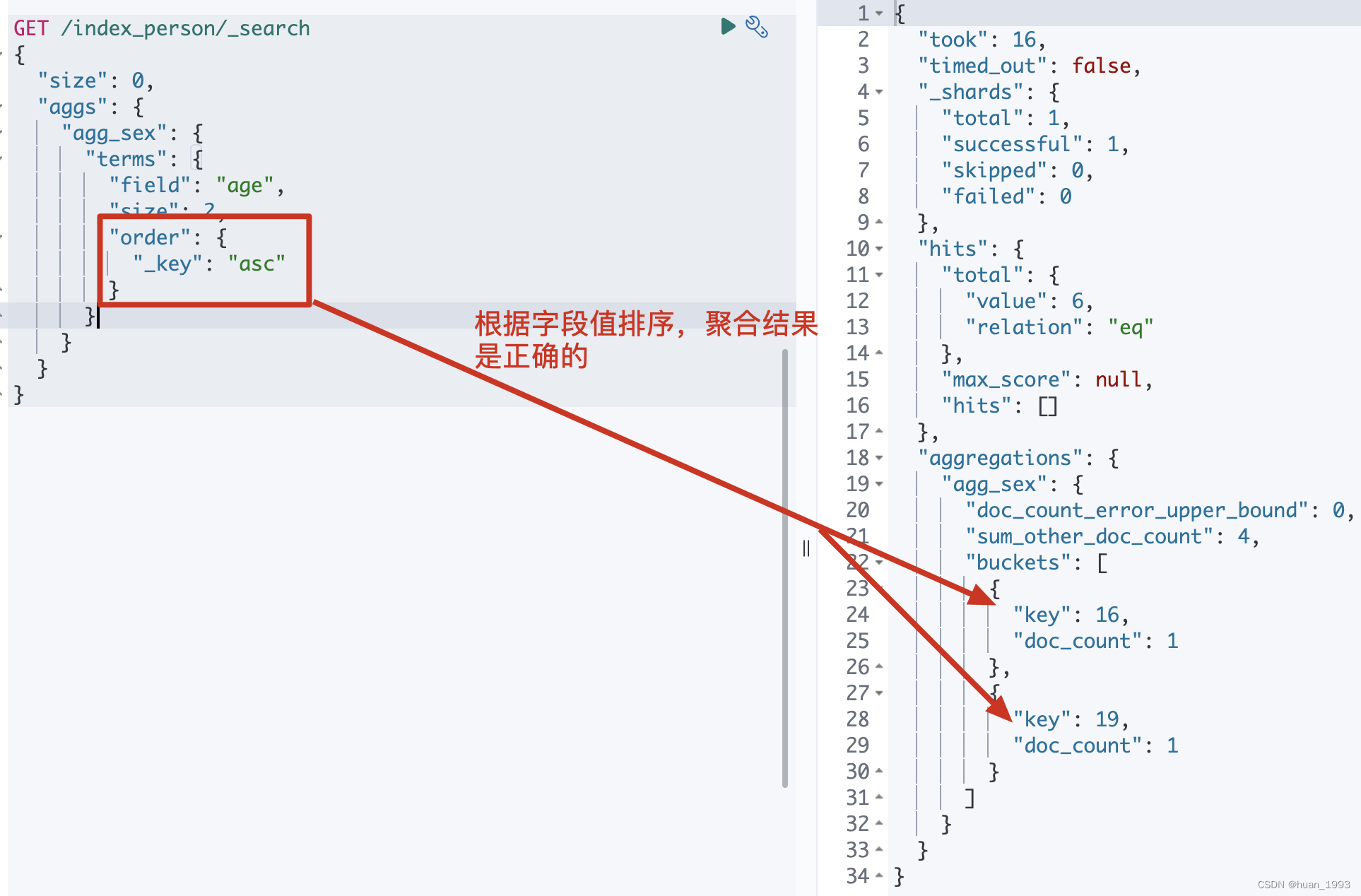
3.3.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_sex": {
"terms": {
"field": "age",
"size": 2,
"order": {
"_key": "asc"
}
}
}
}
}
注意: 这种根据字段值来排序,聚合的结果是正确的。
3.3.2 运行结果
3.4 子聚合排序-先根据省聚合,然后根据每个聚合后的最小年龄排序
3.4.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_sex": {
"terms": {
"field": "province",
"order": {
"min_age": "asc"
}
},
"aggs": {
"min_age": {
"min": {
"field": "age"
}
}
}
}
}
}
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_sex": {
"terms": {
"field": "province",
"order": {
"min_age.min": "asc"
}
},
"aggs": {
"min_age": {
"stats": {
"field": "age"
}
}
}
}
}
}
注意: 子聚合排序一般也是不准的,但是如果是根据子聚合的最大值倒序和最小值升序又是准的。
3.4.2 运行结果

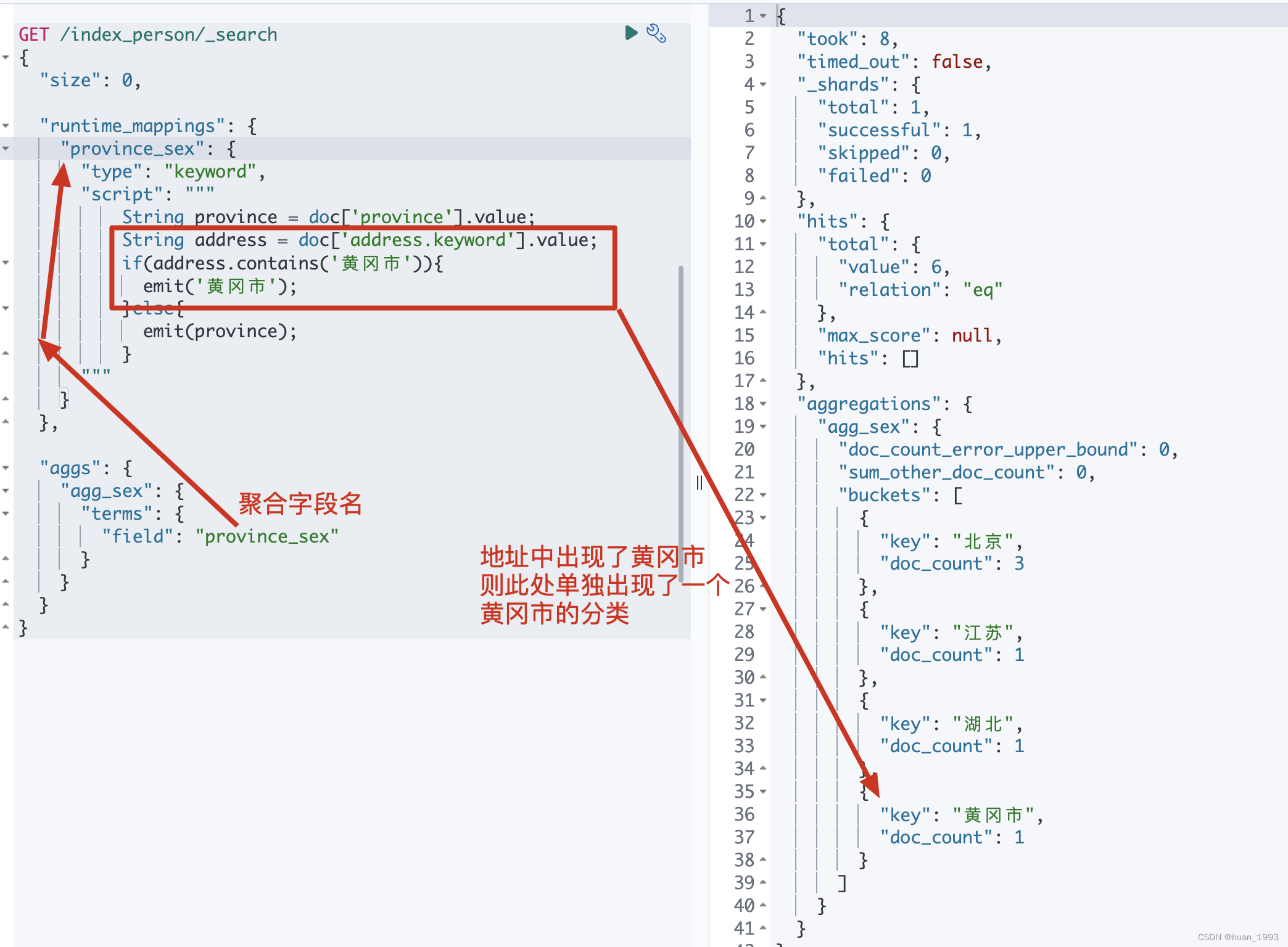
3.5 脚本聚合-根据省聚合,如果地址中有黄冈市则需要出现黄冈市
3.5.1 dsl
GET /index_person/_search
{
"size": 0,
"runtime_mappings": {
"province_sex": {
"type": "keyword",
"script": """
String province = doc['province'].value;
String address = doc['address.keyword'].value;
if(address.contains('黄冈市')){
emit('黄冈市');
}else{
emit(province);
}
"""
}
},
"aggs": {
"agg_sex": {
"terms": {
"field": "province_sex"
}
}
}
}

3.5.2 运行结果
3.6 filter-以省分组,并且只包含北的省,但是需要排除湖北省
3.6.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_province": {
"terms": {
"field": "province",
"include": ".*北.*",
"exclude": ["湖北"]
}
}
}
}
注意: 当是字符串时,可以写正则表达式,当是数组时,需要写具体的值。
3.6.2 运行结果

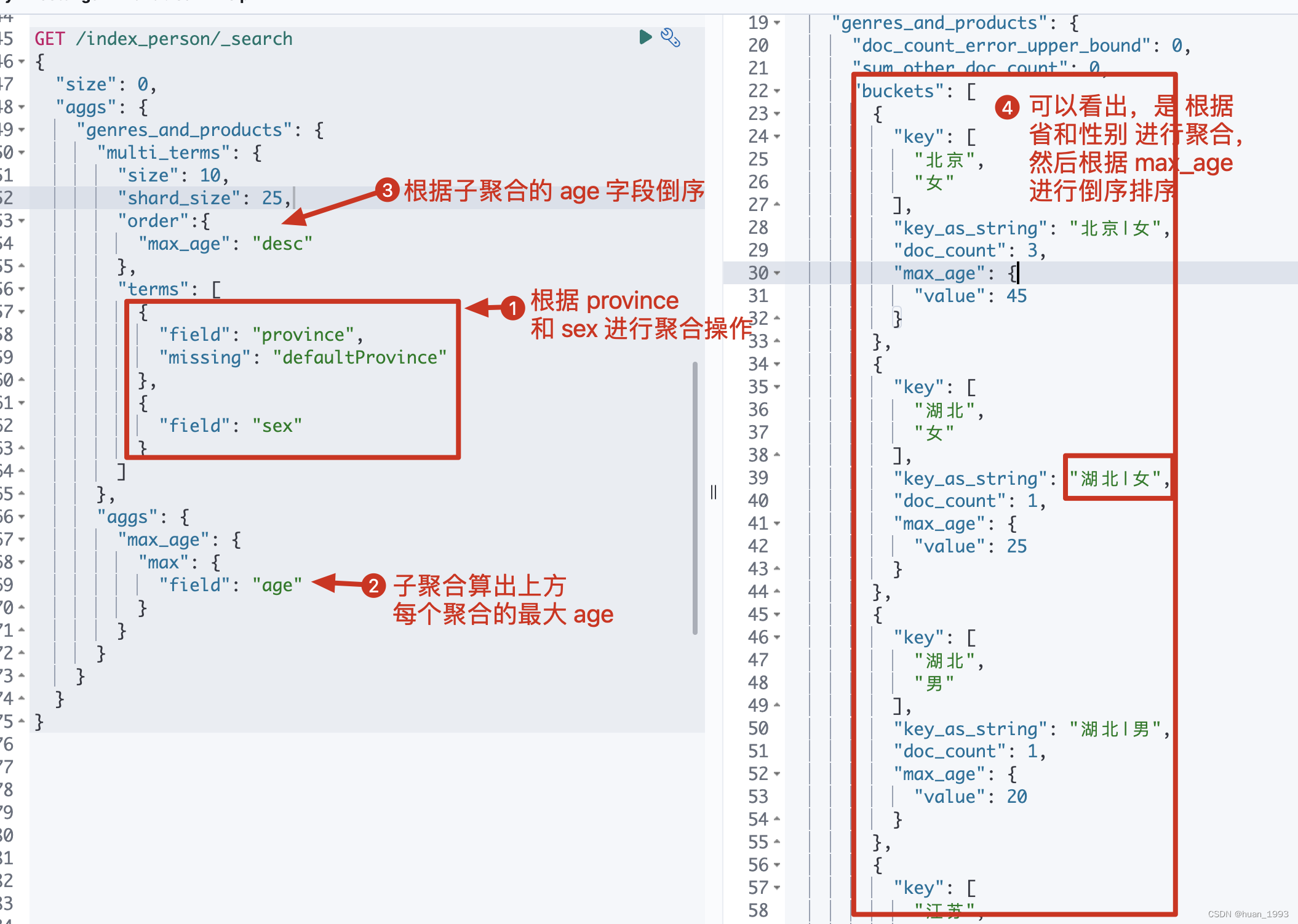
3.7 多term聚合-根据省和性别聚合,然后根据最大年龄倒序
3.7.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"genres_and_products": {
"multi_terms": {
"size": 10,
"shard_size": 25,
"order":{
"max_age": "desc"
},
"terms": [
{
"field": "province",
"missing": "defaultProvince"
},
{
"field": "sex"
}
]
},
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
}
}
}
}
注意: terms聚合默认不支持多字段聚合,需要借助别的方式。此处使用multi terms来实现多字段聚合。
3.7.2 运行结果
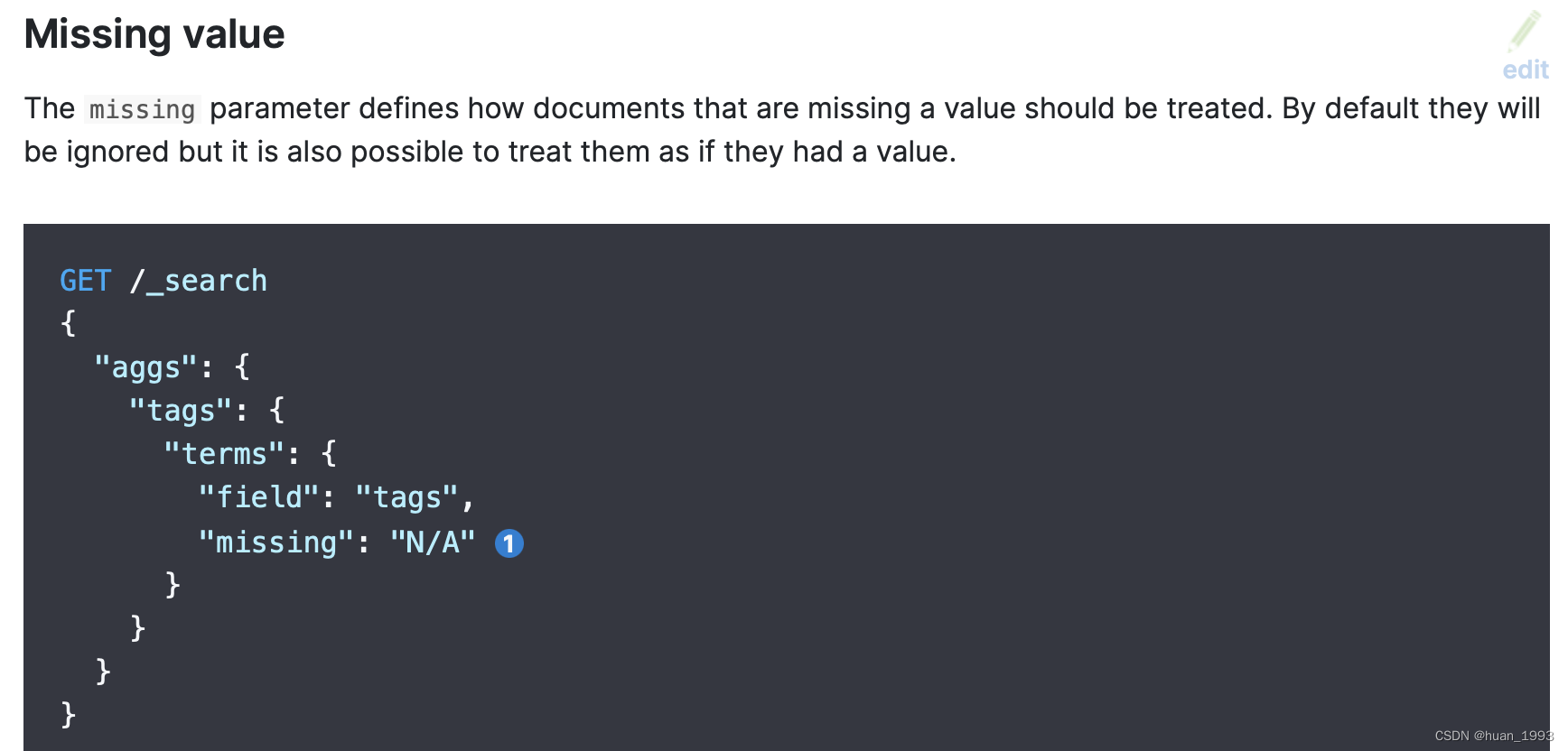
3.8 missing value 处理
3.9 多个聚合-同时返回根据省聚合和根据性别聚合
3.9.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_province": {
"terms": {
"field": "province"
}
},
"agg_sex":{
"terms": {
"field": "sex",
"size": 10
}
}
}
}
3.9.2 运行结果

4.1 可以聚合的字段
一般情况下,只有如下几种字段类型可以进行聚合操作 keyword,numeric,ip,boolean和binary类型的字段。text类型的字段默认情况下是不可以进行聚合的,如果需要聚合,需要开启fielddata。
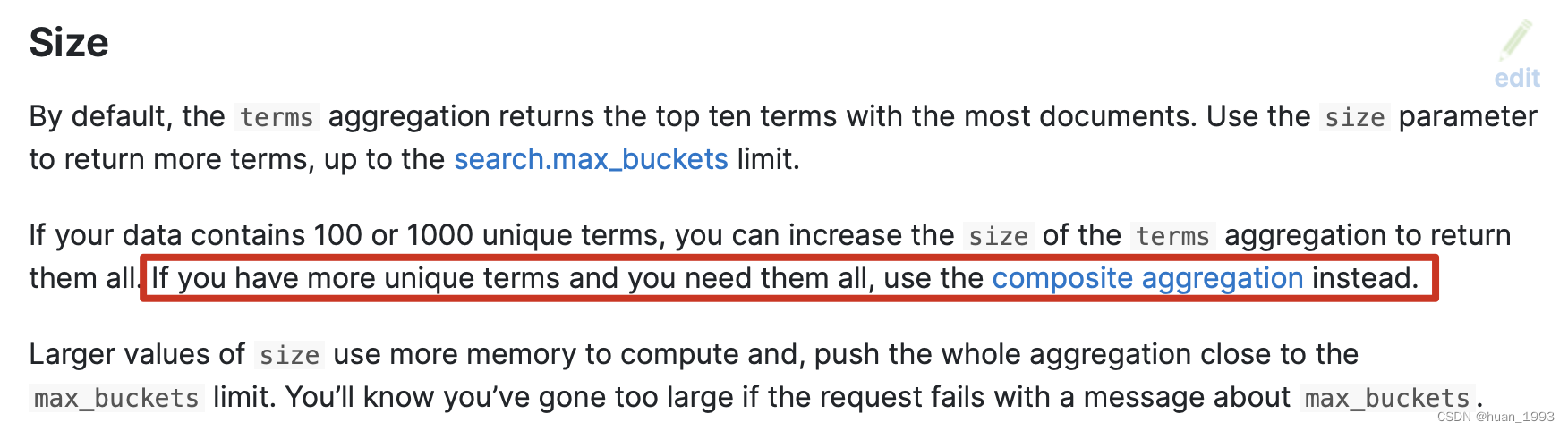
4.2 如果我们想返回所有的聚合Term结果
如果我们只想返回100或1000个唯一结果,可以增大size参数的值。但是如果我们想返回所有的,那么推荐使用 composite aggregation
4.3 聚合数据不准
我们通过terms聚合到的结果是一个大概的结果,不一定是完全正确的。为什么?.
举个例子: 如果我们的集群有3个分片,此处我们想返回值最高的5个统计。即size=5,假设先不考虑shard_size参数,那么此时每个节点会返回值最高的5个统计,然后再次聚合,返回,返回最终值最高的5个。这个貌似没什么问题,但是因为我们的数据是分布es的各个节点上的,可能某个统计项(北京市的用户数),在A节点是是排名前5,但是在B节点上不是排名前5,那么最终的统计结果是否是就会漏统计了。
如何解决:
我们可以让es在每个节点上多返回几个结果,比如:我们的size=5,那么我们每个节点就返回 size * 1.5 + 10 个结果,那么误差相应的就会减少。 而这个size * 1.5 + 10就是shard_size的值,当然我们也可以手动指定,但一般需要比size的值大。

4.4 排序注意事项
4.4.1 _count 排序
默认情况下,使用的是 _count 倒序的,但是我们可以指定成升序,但是这是不推荐的,会导致错误结果。如果我们想要升序,可以使用 rare_terms聚合。

4.4.2 字段值排序
使用字段值排序,不管是正序还是倒序,结果是准确的。
4.4.3 子聚合排序

4.5 多term聚合

5、源码地址
6. 参考链接
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK