

Doris 物化视图
source link: https://timemachine.icu/posts/56052ea3/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Doris 物化视图
物化视图(Materialized View)本质是一种预计算,即把某些耗时的操作(例如JOIN、AGGREGATE)的结果保存下来,以便在查询时直接复用,从而避免这些耗时的操作,最终达到加速查询的目的。其作为一种检索加速技术,应用在许多 olap 引擎中,本文以 Doris 为例,主要介绍 Doris 的物化视图实现、应用场景以及如何查看是否命中物化视图、如果没有命中的话,原因又是哪些。
物化视图一般在数据摄入的时候实时异步或者延时生成,会加剧写放大问题,并且占用额外的物理存储空间,会对集群造成一定的存储压力,数据摄入速度也会受到影响。因此一般在碰到比较严重的性能问题,并且物化视图加速比较明显的时候才会使用。另外物化视图常用于基于明细数据的固定维度查询上,这也是其和 rollup 预聚合的主要区别。
Doris 中的物化视图主要应用在以下两个场景中。
Doris 默认的索引机制只有前缀索引(类似于 LSM 中的稀疏索引),在数据摄入的时候会根据排序列来构建,并且最长只有 36 个字节,超过之后就会被截断。如果第一个字段就是 varchar 类型,大多数情况下单独以其它 key 列作为谓词来过滤查询的时候是不会命中前缀索引的,需要扫描所有的 tablet 分片,这时候在大数据量下,olap_scan_node 节点就会产生的一定的性能问题,尤其是后缀 key 列经常作为条件来过滤查询的场景。
这个时候就可以通过物化视图来解决,针对常用的 key 列查询构造基于不同排序列的物化视图,从而让查询能够更多的命中前缀索引,来减少 scan 节点的压力。这里举个例子
存在 base 表如下,有k1,k2 作为排序列,用于构造前缀索引。默认只有 k1 参与谓词过滤的条件时,才会命中前缀索引加速查询。
create table `temp.redbook_ecm_base`(
`k1` varchar(10),
`k2` varchar(10),
`k3` varchar(10),
`v1` bigint
) ENGINE=OLAP
DUPLICATE KEY(`k1`, `k2`)
DISTRIBUTED BY HASH(`k1`) BUCKETS 4
如果 k3 作为经常过滤查询的维度的话,可以创建物化视图把 k3 列作为排序列,从而应用到前缀索引。
CREATE MATERIALIZED VIEW mv_1 AS
SELECT k3, k2, k1,v1
FROM tableA
针对后缀列的过滤加速,除了采用改变排序列的物化视图外,还可以手动对后缀列添加 bitmap 或者 bloomfilter 索引,一般是低基维采用 bitmap,高基维采用 bloomfilter。
举个例子,比如广告流量链路数据,特点是数据量大,涉及到了广告、策略、算法、落地页、转化等多个方向的维度。在不同的分析场景下,查询的维度频次有比较明显的差异,并且也确实需要组合多个方向维度的明细数据查询。像这种分析场景覆盖明细数据查询以及部分高频维度的场景,也比较适合于物化视图。
可以对高频维度建立对应的物化视图,比如某张 base 表存在 adpos、adunit、campaign、strategy、rank_mondel、page、order 等维度,而算法同学往往只关注相关模型带来的曝光成单转化。因此可以直接建立对应的物化视图
CREATE MATERIALIZED VIEW mv_1 AS
SELECT
rank_mondel,
sum(deliver),
sum(click),
sum(order)
FROM tableA
GROUP BY rank_mondel;
在查询的时候,仍使用查询 base 表的 sql 语句即可。在执行计划解析时,会自动选择是否命中物化视图,并改写 sql 语句将查询打到选择的物化视图上去。
命中物化视图
建立了物化视图就一定会命中吗?答案是否定的,要想命中物化视图,必须保证查询的 key、value 列属于物化视图包含的 key、value 列的子集。
如果存在多个物化视图的话,又会选择哪个呢?之前只看过 Druid 的物化视图命中的源码,Doris 其实也是类似的。当存在多个物化视图的时候,命中会经历以下几个步骤
- 查询元数据,获取该 base 表的所有物化视图信息。
- 比较查询的 key、value 列是否属于物化视图的子集,如果属于,则放入有序集合中,这里的有序会按照物化视图大小进行升序或者降序排序。
- 直接选择物理大小最小的物化视图进行查询。
如何查看是否命中物化视图?一般是通过查看执行计划或者 profile 来实现。这里以 profile 为例。
- 对于应用前缀索引的物化视图,着重关注 olap_scan_node 节点的耗时以及相关参数。一般 rollup 参数为物化视图名称时,则代表命中物化视图,此时可以在对比下命中物化视图前后扫描的 tablet 分片数以及行数是否降低。如果没有减少,可以考虑下是否存储是均匀划分的。
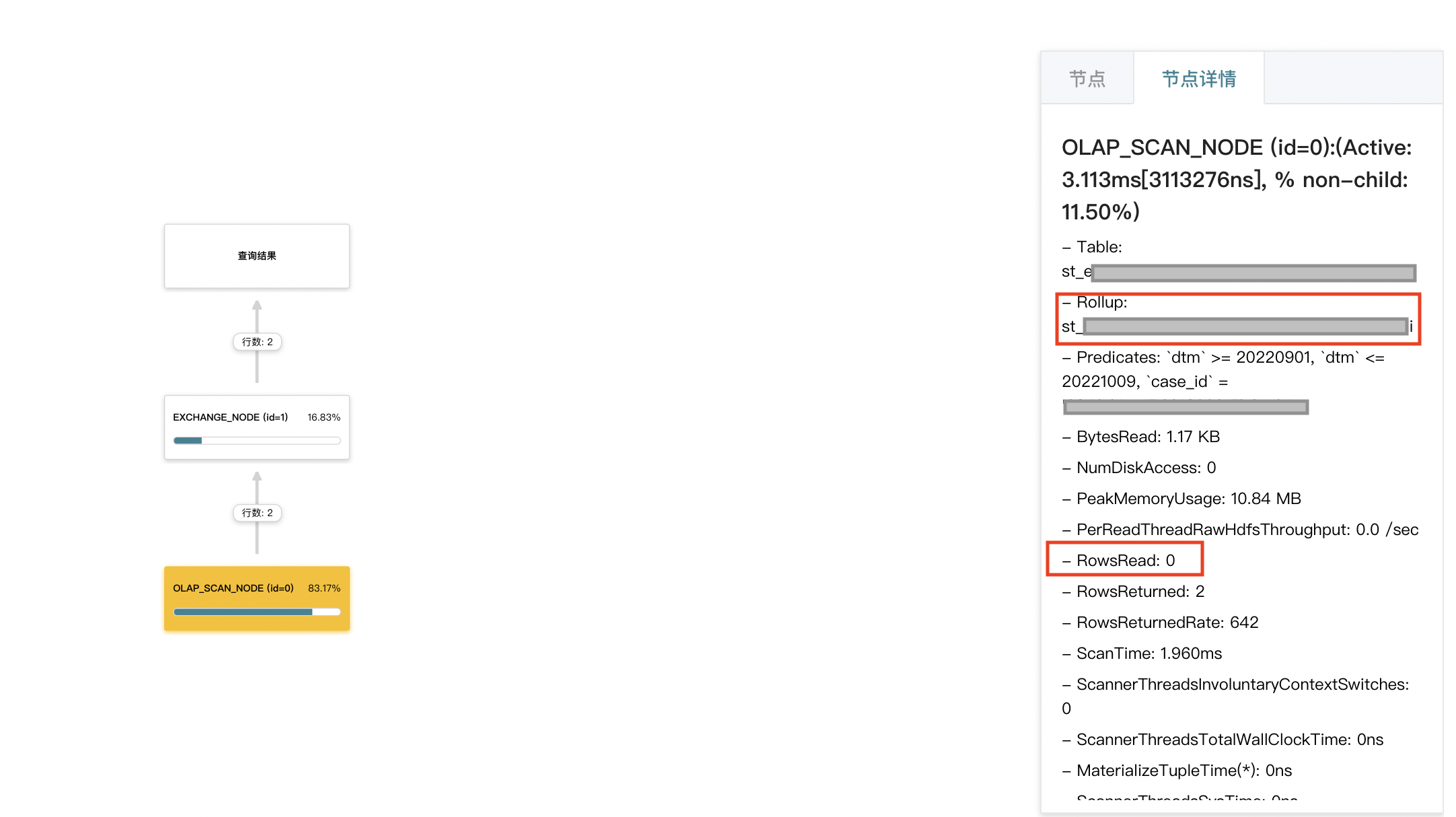
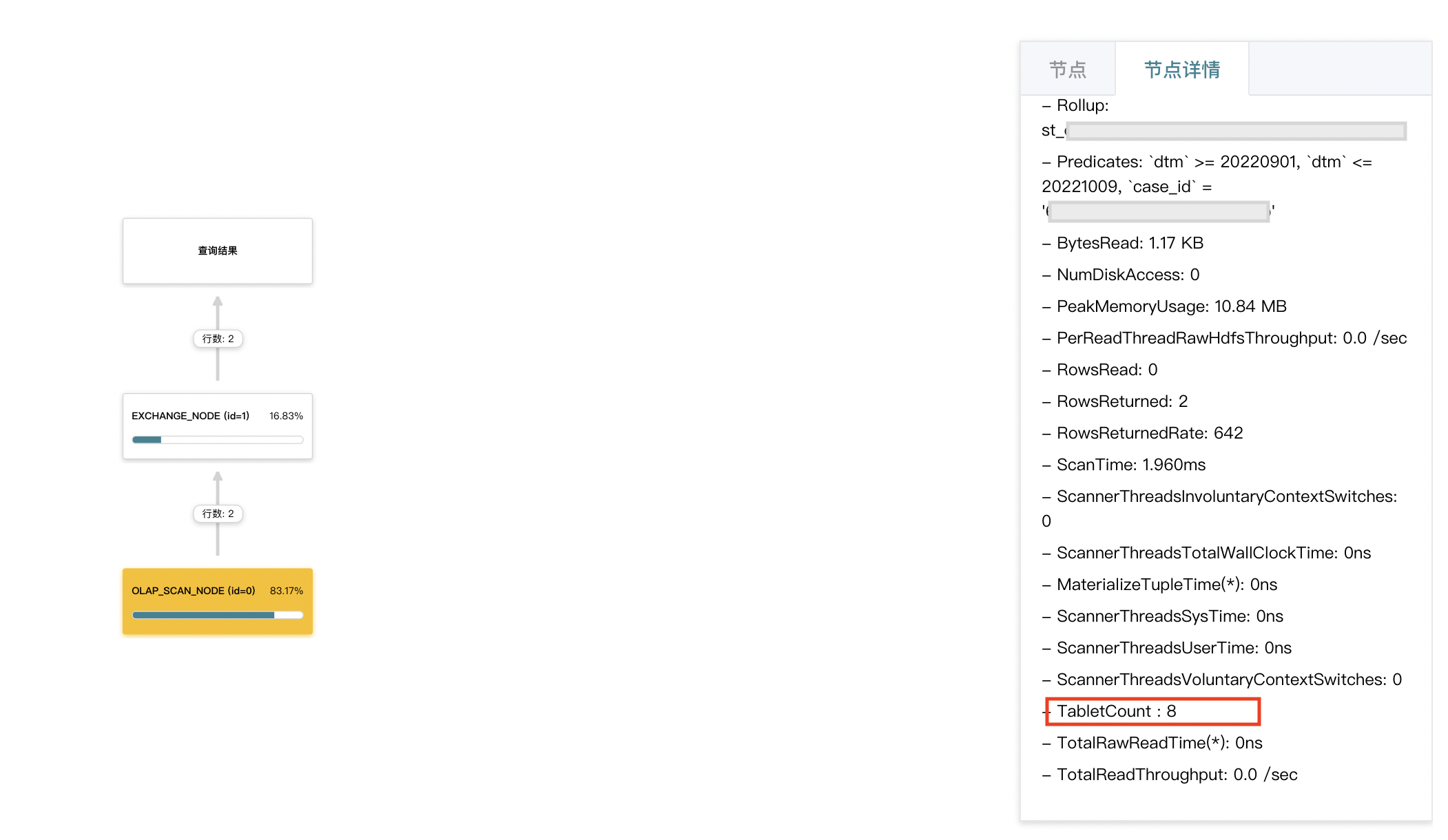
- 对于预聚合的物化视图,着重关注 olap_scan_node 和 aggergate_node 节点的耗时以及相关参数。
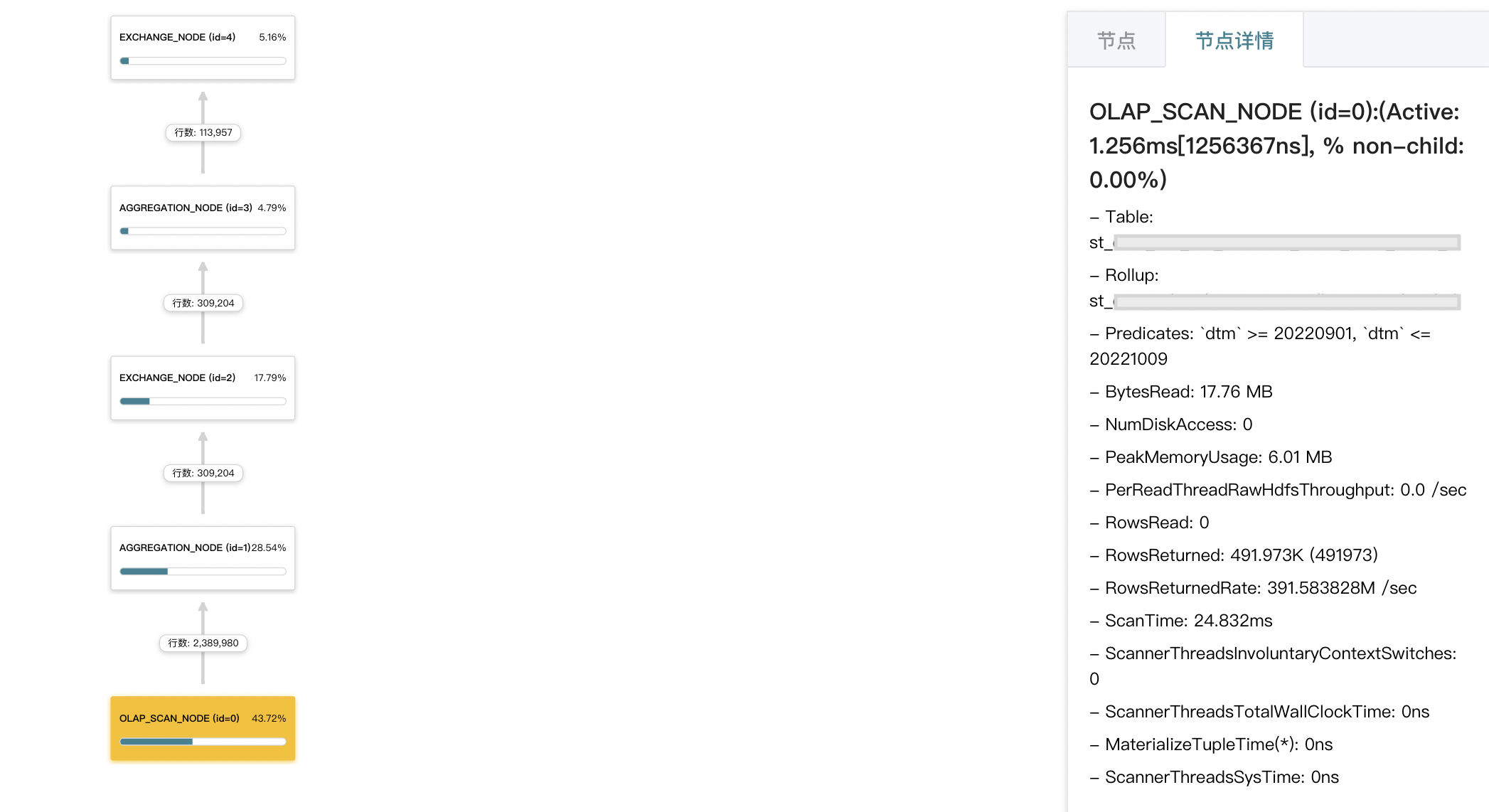
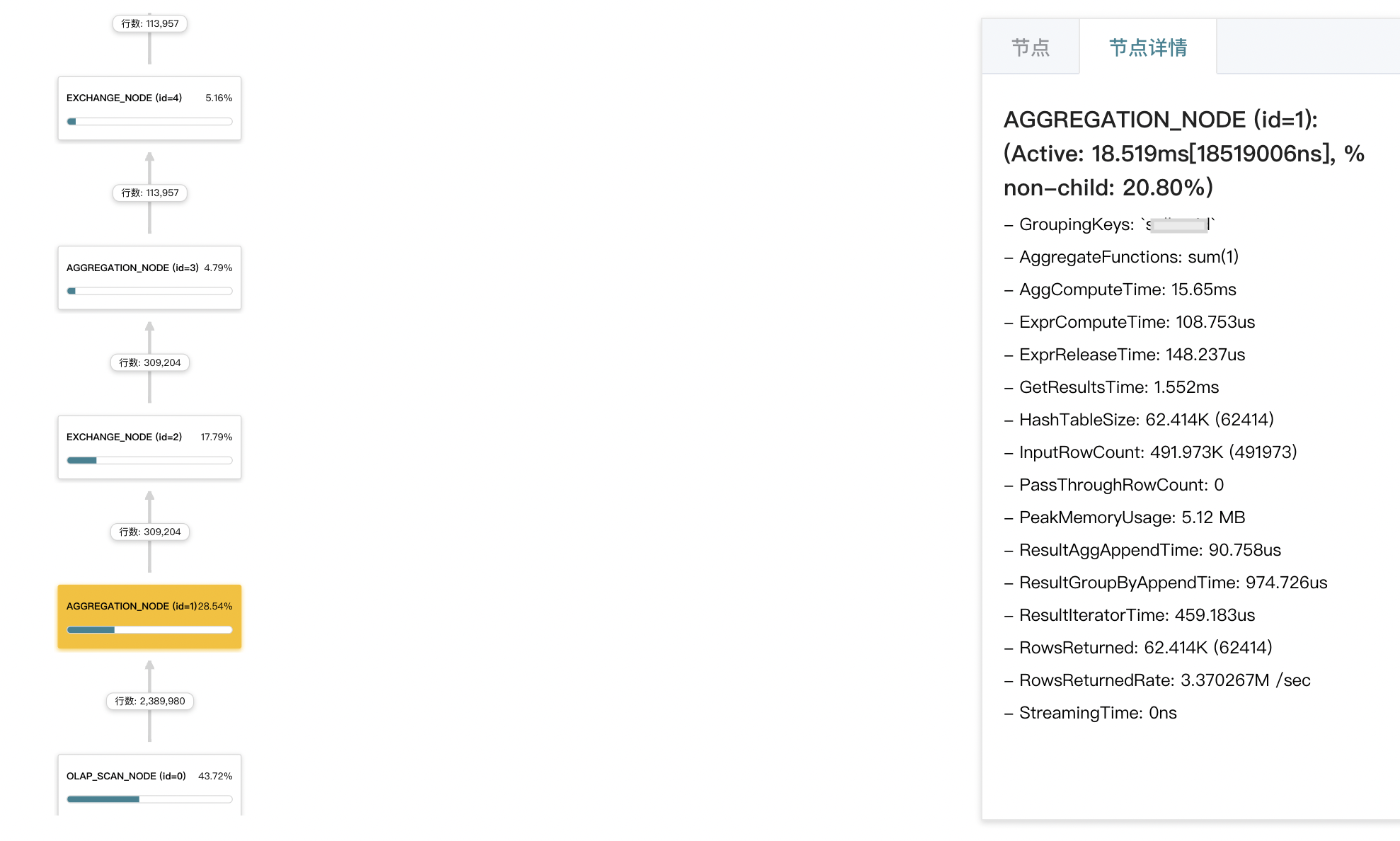
物化视图适合于即需要大数据量明细数据查询又有高频维度聚合的场景,其经常作为性能优化手段出现,一般不预先设计。本质上是拿存储空间换查询效率,并且有写放大问题。因此需要把握好存储、摄入、查询三者间的平衡,往往在使用前需要做好基础的性能测试。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK