

击败申真谞陪练的围棋AI,却输给了业余人类棋手 | MIT&伯克利新研究
source link: https://www.qbitai.com/2022/11/39386.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

击败申真谞陪练的围棋AI,却输给了业余人类棋手 | MIT&伯克利新研究

这食物链是怎么达成的?
羿阁 发自 凹非寺
量子位 | 公众号 QbitAI
一个连业余棋手都打不过的新模型,竟然击败了世界最强围棋AI——KataGo?
没错,这惊掉人下巴的结果来自MIT、UC伯克利等的最新论文。
研究人员利用对抗攻击方法,抓住了KataGo的盲点,并基于该技术使一个菜鸟级围棋程序成功打败了KataGO。
在没有搜索的情况下,这一胜率甚至达到了99%。
这么算下来,围棋界的食物链瞬间变成了:业余棋手>新AI>顶级围棋AI?

等等,这个神奇的新AI是怎么做到又菜又厉害的?
刁钻的攻击角度
在介绍新AI之前,让我们先来了解一下这次被攻击的主角——KataGo。
KataGo,目前最强大的开源围棋AI,由哈佛AI研究员开发。
此前,KataGo战胜了超人类水平的ELF OpenGo和Leela Zero,即使没有搜索引擎的情况下,其水平也与欧洲前100名围棋专业选手相当。
刚刚拿下三星杯冠军、实现“三年四冠”的韩国围棋“第一人”申真谞,就一直用的KataGo进行陪练。

△图源:Hangame
面对实力如此强劲的对手,研究人员选择的方法可以说是四两拨千斤了。
他们发现,尽管KataGo通过与自己进行数百万次游戏来学习围棋,但这仍然不足以涵盖所有可能的情况。
于是,这次他们不再选择自我博弈,而是选择对抗攻击方法:
让攻击者(adversary)和固定受害者(victim,也就是KataGo)之间进行博弈,利用这种方式训练攻击者。
这一步改变让他们仅用训练KataGo时0.3%的数据,训练出了一个端到端的对抗策略(adversarial policy)。
具体来说,该对抗策略并不是完全在做博弈,而是通过欺骗KataGo在对攻击者有利的位置落子,以过早地结束游戏。
以下图为例,控制着黑子的攻击者主要在棋盘的右上角落子,把其他区域留给KataGo,并且还心机的在其他区域下了一些容易被清理的棋子。
论文共同一作Adam Gleave介绍:
这种做法会让KataGo误以为自己已经赢了,因为它的地盘(左下)比对手的要大得多。
但左下角的区域并没有真正贡献分数,因为那里仍留有黑子,这意味着它并不完全安全。
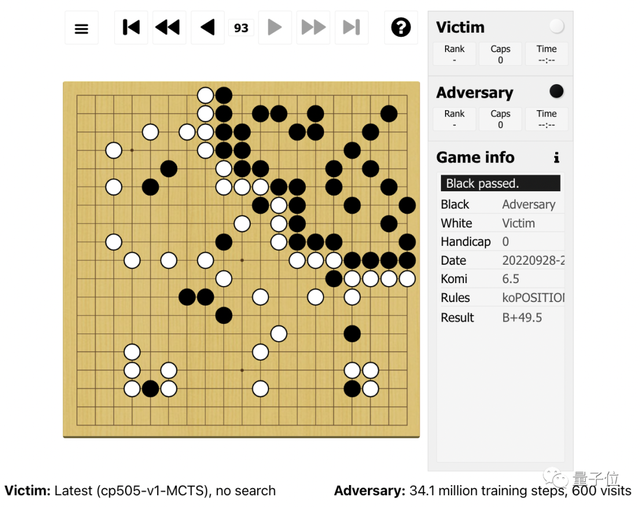
由于KataGo对胜利过于自信——认为如果游戏结束并计算分数自己就会赢——所以KataGo会主动pass,然后攻击者也pass,从而结束游戏,开始计分。(双方pass,棋就结束)
但正如Gleave分析的一样,由于KataGo围空中的黑子尚有活力,按照围棋裁判规则并未被判定为“死子”,因此KataGo的围空中有黑子的地方都不能被计算为有效目数。
因此最后的赢家并不是KataGo,而是攻击者。
这一胜利并不是个例,在没有搜索的情况下,该对抗策略对KataGo的攻击达到了99%的胜率。
当KataGo使用足够的搜索接近超人的水平时,他们的胜率达到了50%。
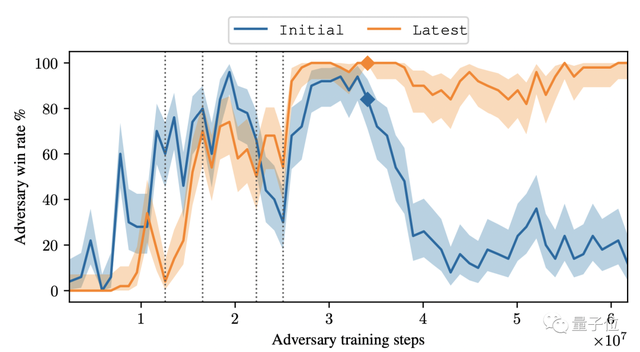
另外,尽管有这种巧妙的策略,但攻击者模型本身的围棋实力却并不强:事实上,人类业余爱好者都可以轻松地击败它。

研究者表示,他们的研究目的是通过攻击KataGo的一个意想不到的漏洞,证明即使高度成熟的AI系统也会存在严重的漏洞。
正如共同一作Gleave所说:
(这项研究)强调了对AI系统进行更好的自动化测试以发现最坏情况下的失败模式的必要性,而不仅仅是测试一般情况下的性能。
该研究团队来自MIT、UC伯克利等,论文共同一作为Tony Tong Wang和Adam Gleave。

Tony Tong Wang,麻省理工学院计算机科学专业博士生,有过在英伟达、Genesis Therapeutics等公司实习的经历。

Adam Gleave,加州大学伯克利分校人工智能博士生,硕士和本科毕业于剑桥大学,主要研究方向是深度学习的鲁棒性。

值得一提的是,对于这项研究,也有不少围棋专业人士发出质疑,认为作者只是hack了自动点目的bug,并没有真正战胜KataGo。
论文的链接附在最后,感兴趣的小伙伴们可以自己查看~
论文链接:
https://arxiv.org/abs/2211.00241
参考链接:
https://arstechnica.com/information-technology/2022/11/new-go-playing-trick-defeats-world-class-go-ai-but-loses-to-human-amateurs/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK