

让ML跑起来
source link: https://weedge.github.io/post/let-ml-go/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
让ML跑起来
上文提到通过用户的行为数据存放在S3中,这些数据包括结构化和非结构化数据,怎么让这些数据变得有价值呢?一种是人为进行数据挖掘,对相关指标转化率进行评估;还有一种是通过这些数据来训练模型,然后将预测模型用于生产环境中进行A/B测试,选出适合的模型,这个模型需要不断更新迭代,并且自动化半自动化运行起来;
XGBoost, Gradient Boosting框架下实现机器学习算法。XGBoost 提供了一种并行树提升(也称为 GBDT、GBM),可以快速准确地解决许多数据科学问题。支持在多台机器上进行分布式训练,包括 AWS、GCE、Azure 和 Yarn 集群;可与 Flink、Spark 等云数据流系统集成。
如果说把机器学习问题分成,常规机器学习(conventional machine learning)和深度学习(deep learning)的话,那么XGBoost就是在常规ML竞赛获奖最多的算法。XGBoost 的全称是 Extreme Gradient Boosting,是gradient boosting的一种开源实现。gradient boosting 把若干弱模型通过决策树的方式聚合(ensemble)在一起, 形成一个最终的模型,这个过程是一个持续的、不断迭代优化过程,每次迭代优化的方向通过计算loss function的梯度来实现,然后采取梯度下降的方式不断的降低loss function,从而得到一个最终的模型。
XGBoost最常用来解决常规ML中的分类(regression)和回归(classification)问题。回归问题,举例来说:根据一个人的年龄、职业、居住环境等个人信息推算出这个人的收入,这种推理的结果是一个连续的值(收入)的情况就是一个回归问题;分类问题,比如在欺诈检测中,根据有关交易的信息,来判断交易是不是欺诈,这里的判断是或者否就是一个二分类问题。通常这两类问题都是给出一个表格类型数据,表格中的每列数据都是跟推理的目标(属于某个分类或者推理值)有着潜在关系的数据,XGBoost特别擅长处理这类的表格数据(tabular data),并据此作出推断。对于表格数据,无非由行、列来组成,在ML中对于表格数据中的行和列,我们有很多约定俗称的称谓,在各种关于ML的文章中这些称谓会经常出现,为了便于大家理解,在这里对这些叫法做一个梳理:
- 行(row),叫做一个观察(observation),或者一个样本(sample)
- 列(column) ,也叫字段(field),属性(attribute),或者特征(feature)
keras: 深度学习模型库,高级神经网络,同时支持卷积神经网络和循环神经网络,以及两者的组合。
如果使用TF(tensorflow)框架, 使用TF serving来支持加载训练好的模型发布到生产环境,并且可以进行A/B测试;
操作demo参考:https://www.tensorflow.org/tfx/tutorials/serving/rest_simple
用于生产环境需要考虑的问题
-
训练模型的数据来源,以及采集存放(格式和压缩);这些数据根据使用场景而定,比如demo中的电商场景,识别物品,需要大量的非结构化图片数据,这些用户上传的原始图片和加工后的图片存放于对象存储中比如S3,OSS,COS;
-
特征数据清洗过滤存放;
-
数据如何快速训练;数据量一般很大,PB级别,单机肯定是加载不了这么多数据训练,即使分割成多个小文件,单机处理需要大量中间结果存放,处理效率非常低;所以模型训练需要考虑集群模式,进行分布式训练模型,需要一个训练平台来支持,充分调度计算资源(CPU,GPU,TPU,FPGA),并行计算,并且根据数据量进行可伸缩扩展,保证训练中途中断的可用性(failover,checkpoint);
开源框架:
-
将训练好的模型导出序列化pb格式,存放到文件系统中(SavedModel);然后TF serving启动服务加载模型,对外以 HTTP REST API或 gRPC API的方式提供模型服务;正式用于线上,需要考虑服务性能问题(高并发场景,延迟和吞吐量,模型预热(warmup),批处理(batching)等性能优化点),生产环境模型更新(构建,无损服务切换,流量A/B测试),容器化部署(serving on K8S)(扩缩容,流控,容错等高可用设计),服务监控等工程上的问题;本地demo可参考: Serving a TensorFlow Model
-
监控模型数据,如何对其进行评估;
-
模型迭代更新速度快,需要引入CI/CD pipelines 来自动化支持模型闭环迭代;
-
计算资源机器成本预估;
Kubeflow 在 Kubernetes 上部署机器学习 (ML) 工作流变得简单、可移植和可扩展。提供一种直接的方式来将用于 ML 的同类最佳开源系统部署到不同的基础设施;在任何运行 Kubernetes 的地方,都应该能够运行 Kubeflow。
TFX with kubeflow on GKE
https://github.com/tensorflow/tfx
ML on Amazon SageMaker
分布式训练: https://aws.amazon.com/cn/sagemaker/distributed-training/
文档:Amazon SageMaker Example Notebooks, Amazon SageMaker Workshop
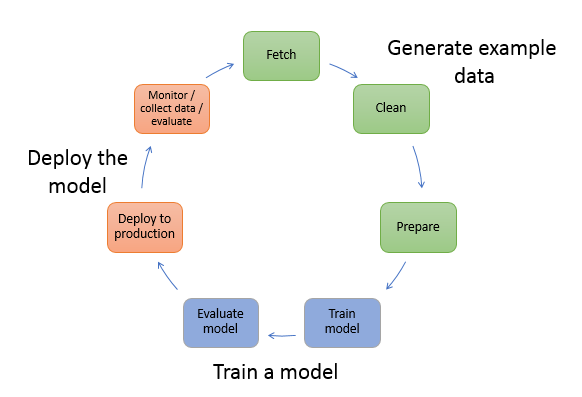
SageMaker框架直接集成了多种机器学习框架,一条龙服务,也可以集成Kubeflow方案;机器学习整体生命周期包括训练数据准备,模型训练,模型评估,评估ok之后部署上线提供在线预测推理服务,通过监控搜集数据,重复迭代模型;整体生命周期如图所示:

将数据处理准备到模型上线整个过程可以自动化,通过sageMaker平台直接组合成工作流pipeline进行自动化处理,demo请参考:自动化机器学习工作流 sagemaker tutorial
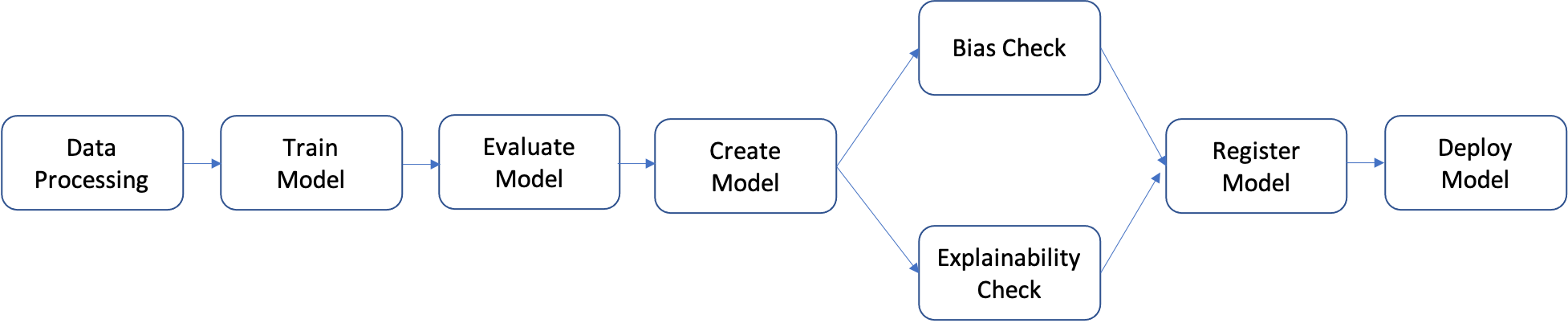
Tips: 这里只是整体概括下机器学习工程化的过程;机器学习以及深度学习相关的算法知识待深入边动手边学习;待续~ :)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK