

使用CDC模式改造遗留系统
source link: https://www.51cto.com/article/722340.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

作者 | 张双海

项目改造背景及挑战
在我们经历的各种遗留系统改造之旅中,使用绞杀者模式来改造一个巨大的单体服务,是一种被广泛采用且验证行之有效的手段,在应用传统的绞杀者模式时,通常采用逐步替换的方式,将遗留系统中某一独立的部分抽取出来进行改造,最后通过反向代理等方式,将流量倒入到新的服务中。
但是在我们的案例中,被改造的领域服务是客户的核心业务,客户强烈希望在整个改造过程中,不要对现有正在运行的系统造成影响,所以仅仅采用绞杀者模式是不够的,我们还需要采用新老并行模式来完成整个迁移改造。
当使用并行运行时,我们不是调用新旧实现的其中之一,而是同时调用二者,以允许我们比较其结果以确保它们是等效的。尽管调用了两种实现,但在任何给定的时间内,只有一个实现的结果是正确的。一般而言,在不断校验并相信我们的新实现之前,我们认为旧实现的结果是正确的。
「《Monolith To Microservices》」
通过新老并行模式,原有的系统不会受到影响,可以继续提供服务,待新的服务完成迁移并通过验证之后,再将流量迁移到新的系统。采用新老并行模式可以以增量的模式进行迁移改造,并且在出现问题的时候能够轻松回滚,确保核心业务的安全。具体介绍可以参考zalando 的工程实践。
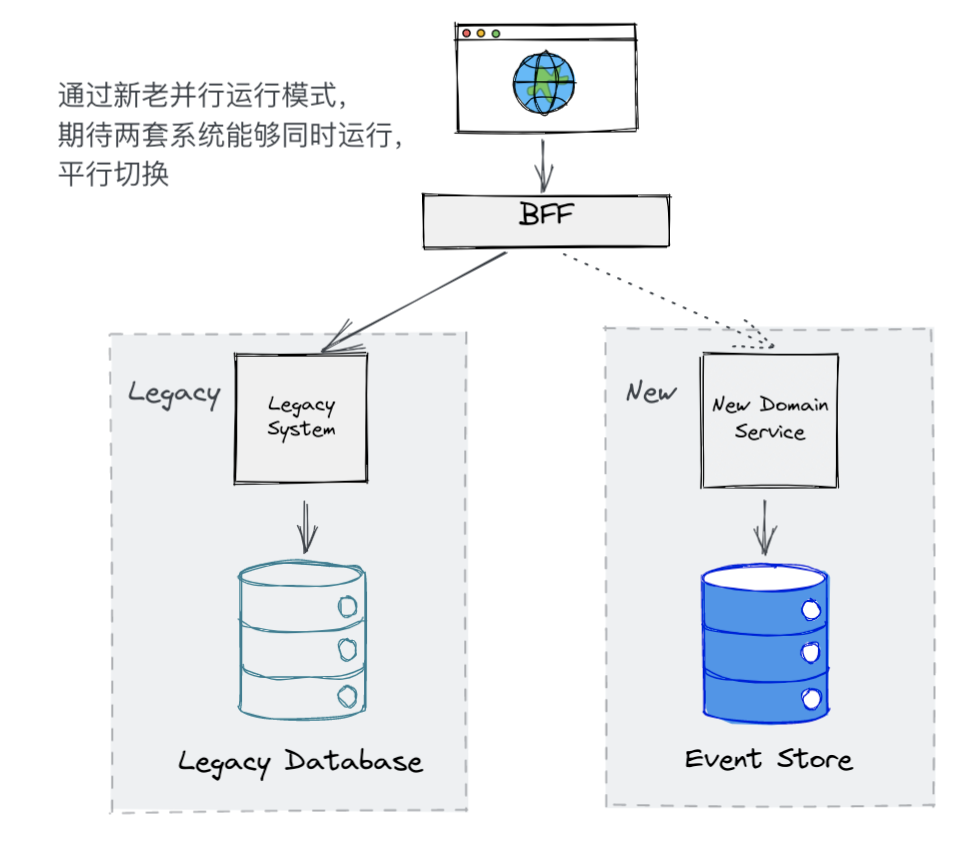
在新老并行模式运行过程中,为了达到使新服务能够完全平行替代旧服务,需要将旧服务里新产生的变化,及时同步到新服务里来(对于遗留数据只需要一次性的迁移即可)。在各种因素以及客户业务需求的影响下,我们选择了 Event Sourcing 作为基本架构来构建我们新领域服务。Event Sourcing 是一种通过记录一系列的领域事件来完成对系统状态的持久化,对于 Event Sourcing 更加详细的介绍可以参看之前的这篇《被误解的Event Sourcing》。
鉴于新服务中持久化的都是一系列的领域事件,所以很难将遗留系统中产生的变化直接持久化到新服务中,最好的方式是通过调用新服务提供的 API,由新服务通过 Command 产生 Event,然后再存储到 Event Store 中,完成持久化。
同时遗留单体系统中的代码仓库已经非常庞大,并且复杂到难以修改,任何对于遗留系统的代码修改都需要经过繁复的测试和严格的 Code Review,同时也会增加交付开发人员的认知负担,并且还会给现有系统带来一定的风险。
基于以上背景,我们发现,通过修改遗留系统代码的方式来完成新老两个系统之间数据的同步代价是比较大的,而且会引入一定的风险。
以上种种限制使得我们选择了CDC(Change data capture)模式来完成我们对遗留系统数据的捕捉与迁移。
使用 CDC 模式来完成新老数据同步
什么是 CDC 模式和 Debezium
CDC 模式是一种对变化的数据进行监控并捕获,以便其他服务也能够响应这些变化的模式。对于监控数据库的变化而言,Debezium 是 CDC 模式的一个非常成熟的实现。当使用 Debezium 来连接 MySQL 时,Debezium 会读取 MySQL 的 binary log (binlog) 获取到数据库产生的变化。同时,Debezium 还是一个 Kafka connect,通过配置,能够将数据库产生的变化推送到特定的 Kakfa Topic 中。
通过 Debezium,我们便可以捕获到所有遗留系统数据库产生的变化,并将其推送到 Kafaka 特定的 Topic 中去,只要新服务能够响应这些变化,就可以将旧系统中数据产生的变化同步到新系统里去。
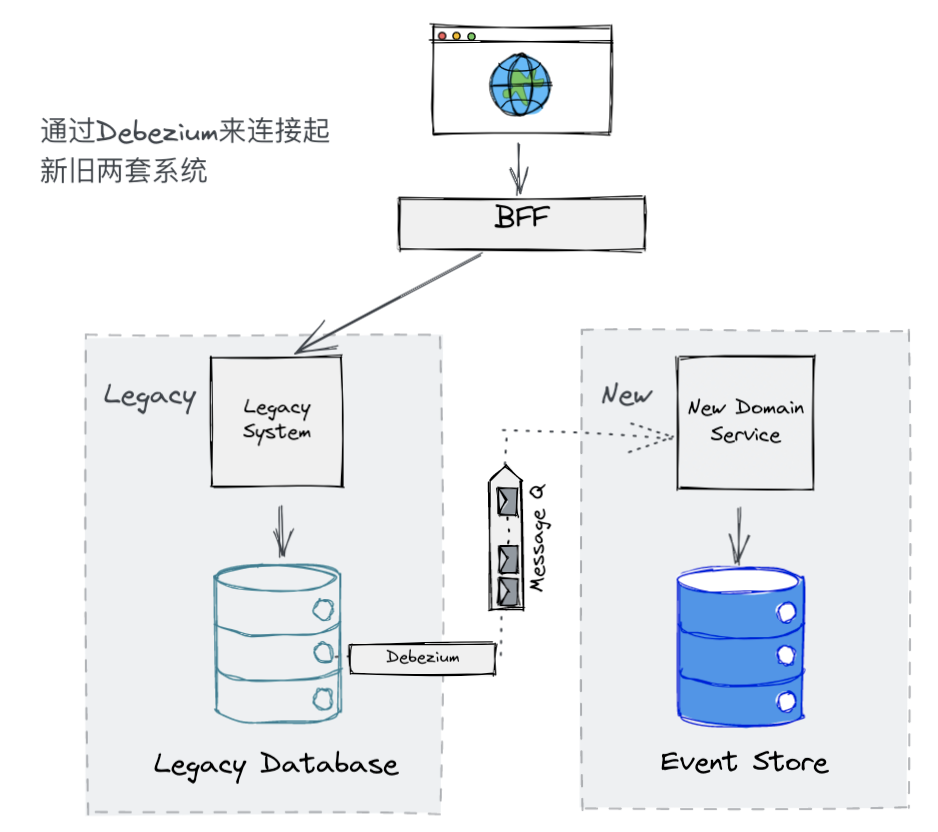
但目前而言,新服务是无法直接响应这些遗留系统数据库的变化的,原因是新服务接受的是有业务含义的 Command,而不仅仅是一些数据库的变化。但根本原因在于,我们捕获到的数据库变化只是数据库行级别的变化,缺失了特定的业务含义,所以我们也无法直接利用这些数据与我们的新服务连接起来。
将这些捕获到的数据库变化赋予业务含义,并将其转换为特定的 Command,这是我们面临的下一个挑战。
从 CDC 到 Command
要完成这个挑战,就需要深入细节了。为了方便说明,我在这里准备了一个非常简单的例子。
还是以我们非常熟悉的电商领域商品项为例,假设一个 Product 聚合根,管理着多个 Photo 聚合,它们之间的关系在遗留系统数据库中用 ERD 表示如下:
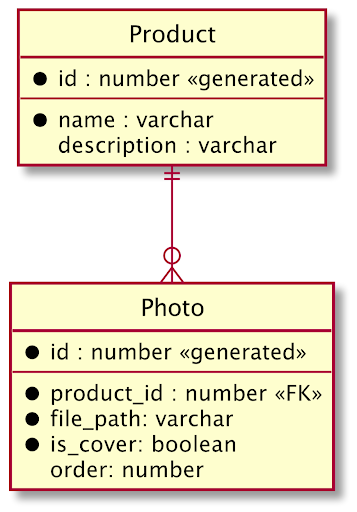
经过前期的事件风暴工作坊,我们可以得到一系列关于 Product 聚合根的领域事件:
- Product 已增加
- Product 的 Photo 已增加
由于我们的新服务采用了 Event Sourcing 架构,并且系统内的 Event 设计严格遵循事件风暴工作坊产出的领域事件,在新服务中,接受的是像在 Product A 下增加 Photo这样的 Comand。
有了例子之后, 我们可以将之前描述的问题更加具体一点:当收到一条消息表明 Photo 表中的数据发生了变化,应将其识别并转变为在 Product A 下增加 Photo或更改 Photo A 为封面图片这样的 Command。
接下来让我们仔细分析一下 Debezium 所捕获到的变化数据的结构,继续上面的例子,如下是一个典型的 Debezium 产生的 Kafka 消息的 payload 结构:
{
"before": null,
"after": {
"id": "61CFF6E6-A7AA-43BB-8D6D-A8676CFF59AE",
"productId": "E78E3F5A-2275-4C2D-AA6E-1F0282E6CC08",
"filePath": "48F3AE46-D6A5-4F14-8FE3-7B82B7EB6537",
"order": 0,
"isCover": true,
}
"source": {...some source meta information},
"op": "c",
"ts_ms": 1631690854515,
"transaction": {
"Id": "file=mysql-bin-changelog.000010,pos=40908353",
"total_order": 1,
"data_collection_order": 1
}
}从这个消息的结构和内容可以看出,该消息里面不仅完整的展示了数据库里某项记录在变化前后的所有信息,同时还有一些附加的元信息。在这些元信息中,有两项数据最值得我们去注意。
一个是op,根据Debezium 的官方文档,这个字段表明了这次变化的变化类型,这个字段可能的值有:
- C: 表示创建
- U: 表示更新
- D: 表示删除
- R: 表示读取(如果是一个 Snapshot 的话)
通过这个字段,我们可以快速且准确的推断出当收到某条变化的消息时,遗留系统数据库的某项数据发生了怎样的变化。比如上面这个例子,我们可以推断出来,有一张新的图片被添加到某个 Product 上面。
但是到目前为止,可以将这样的消息转换为在Product A下增加Photo这样的 Command 吗?
很遗憾还不能,因为根据 Debezium 的实现以及我们的配置,每张表的更新都会被发送到不同的 Kafka Topic 中去,当收到图片被添加的消息时,还有可能是添加了一个 Product 的同时添加了这个 Product 的 Photo,所以这个行为不应该被识别为添加图片的 Command,而应该被识别为创建一个 Product的 Commnd。
为了能够准确地将数据库中发生的变化识别为 Commnd,我们需要收集并分析更多的数据,这就需要利用消息体里的另外一个字段——transaction。
Transaction 字段描述了捕获到的这一次变化里关于 Transaction 的一些信息,这些信息包括了这次变化的“transactionId”,以及这个变化在这次 transaction 里的顺序。
同时,Debezium 捕获到的不仅仅是某个表中的某项记录发生变化,同时它还会捕获到每次数据库关于 Transaction 的一些原始信息,消息格式如下:
{
"status": "END",
"id": "file=mysql-bin-changelog.000010,pos=40908353",
"event_count": 2,
"data_collections": [
{
"data_collection": "product-service@photo",
"event_count": 1
},
{
"data_collection": "product-service@product",
"event_count": 1
}
]
}在每一次数据库的 transaction 开始或者结束的时候,我们都能通过 debezium 收到这样一条消息,这个消息里面,我们可以得知某一个 Transaction 的状态,id,这次 Transaction 里面有哪些表发生了变化,以及变化的数量是多少。
在这些数据中,我们最为关注的就是 Transaction 的id,可以发现在前述关于数据表变化的消息体里面也存在这个字段,通过这个字段,我们可以将某一个 Transaction 下所有产生的变化都聚合到一起,根据聚合之后的数据再来判断应该将其识别转换为哪种 Command。比如说,要是这个变化的聚合里面有一个 Product 被新增了,那么我们就可以确定的是这肯定是一个新增Product的 Command,即便这个变化的聚合里面显示出有 Photo 被新增,那也不应该被识别为成添加图片的 Command。
其实作出上面的推论还是有一个隐含前提,就是遗留系统的一些行为和操作,都是在一个 Transaction 中,如果同一个操作不在同一个 Transaction ,那么我们的推论也就无法成立。好在在我们的真实案例中,客户采用了成熟的 ORM 框架(Prisma),每一个有业务含义的行为所造成的修改都在同一个 Transaction 中并保存到数据库。在开发过程中,也需要在遗留系统的前端不断操作验证并加以单元测试才能确保我们能够准确地识别出所对应的 Command。
至此,我们所有要解决的问题都能够得到解决了,我们已经能够将遗留系统数据库与新系统的数据库之间的 gap 填平了,两者之间的通道也能够建立了。我们终于胜利了!
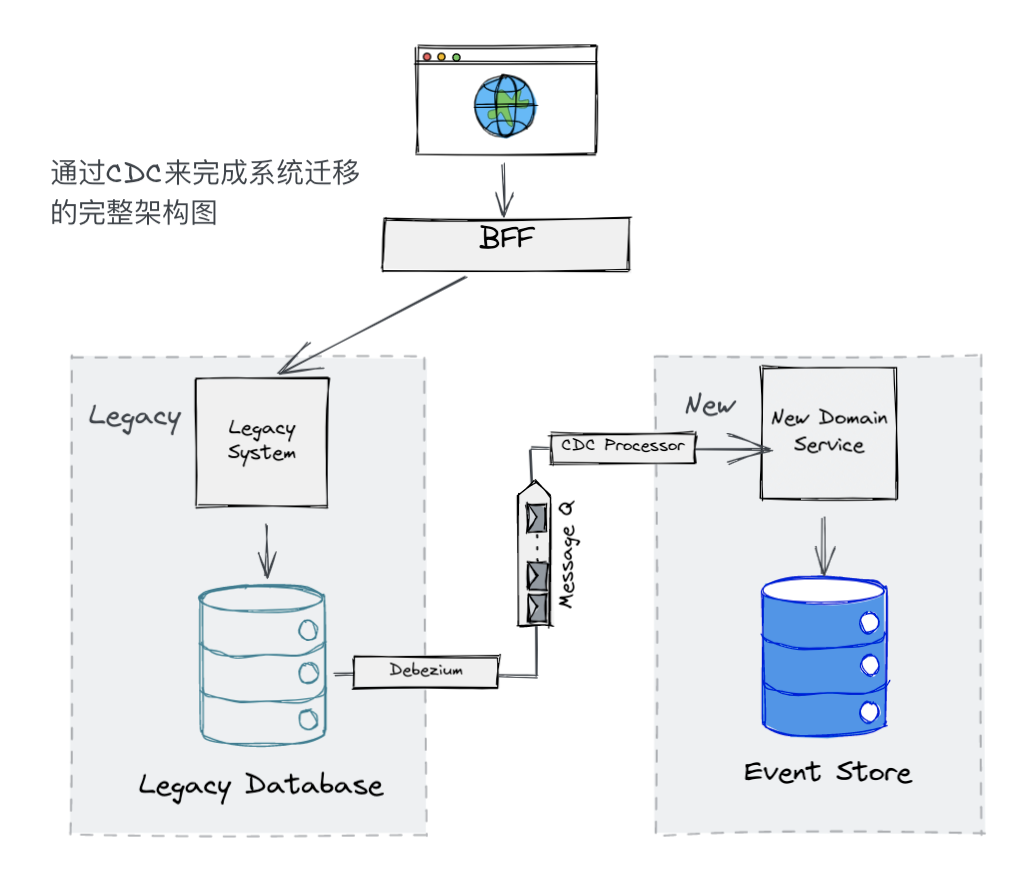
基于此种解决方案,我们将整个遗留系统改造分为了三个阶段,
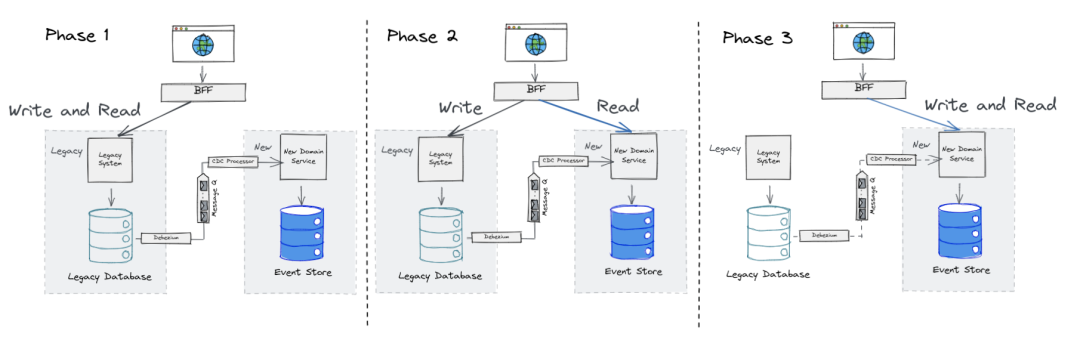
- 阶段一:前端对遗留系统读和写,但是对遗留系统所造成的修改都会被同步到新系统中
- 阶段二:前端对遗留系统进行写操作,但是对于读操作都会被引向新系统
- 阶段三:待对新系统做好完整的验证后,新系统就会被作为唯一可信的数据源进行读写了
更多的细节
常言道,魔鬼都在细节里,不过鉴于篇幅有限,已经无法再用文字展开更多了,只能通过时序图来介绍 CDC Procrssor 服务里更多的细节,包括如何通过Transaction来聚合 Debezium 消息以及整个消息处理流程。
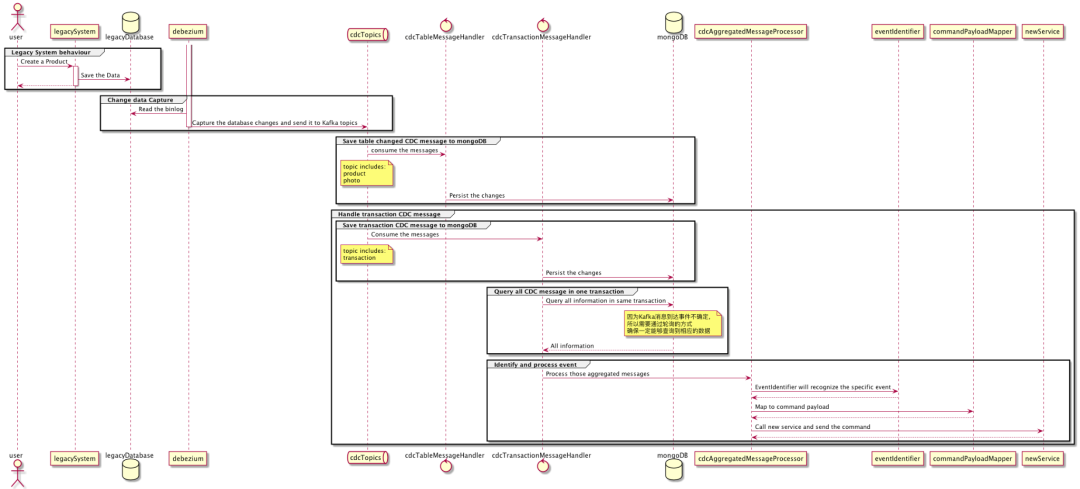
最后总结一下,因为被改造的业务是客户的核心业务,基于不影响原有业务的考虑下选择了新老并行模式来完成整个遗留系统改造。我们选择了 CDC 模式(Debezium)来将遗留系统中产生的变化同步到新服务中。在同步过程中,由数据层的变化推导出业务意图是成功的关键。在其他运用绞杀模式的改造中,如果能够在更上层的地方做分支也是一种好的思路(参考 Decorating Collaborator Pattern),这样可以更好地还原业务。最后,在使用 CDC 模式来完成遗留系统改造时,数据完整性和性能都是关键指标,在不丢失数据的情况下应越快越好。
原文链接:使用CDC模式改造遗留系统 (qq.com)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK