

Oracle收集统计信息的一些思考 - 小豹子加油
source link: https://www.cnblogs.com/ddzj01/p/16870176.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Oracle收集统计信息的一些思考
- Oracle在收集统计信息时默认的采样比例是DBMS_STATS.AUTO_SAMPLE_SIZE,那么AUTO_SAMPLE_SIZE的值具体是多少?
- 假设采样比例为10%,那么在计算单个列的distinct时与实际的差别大吗?
- 有哪些采样算法?
准备三张实验表,t1/t2/t3,这三张表的数据内容完全一致,我们分别使用100%、10%、AUTO_SAMPLE_SIZE的比例去收集他们的统计信息。
SQL> begin
2 dbms_stats.gather_table_stats(
3 ownname => 'BAO',
4 tabname => 'T1',
5 estimate_percent => 100
6 );
7 end;
8 /
PL/SQL procedure successfully completed.
SQL> begin
2 dbms_stats.gather_table_stats(
3 ownname => 'BAO',
4 tabname => 'T2',
5 estimate_percent => 10
6 );
7 end;
8 /
PL/SQL procedure successfully completed.
SQL> begin
2 dbms_stats.gather_table_stats(
3 ownname => 'BAO',
4 tabname => 'T3',
5 estimate_percent => dbms_stats.auto_sample_size
6 );
7 end;
8 /
PL/SQL procedure successfully completed.
查看这三张表的统计信息,可以看到采用100%和AUTO_SAMPLE_SIZE这两种方式收集的统计信息的SAMPLE_SIZE相同,都是全量收集。
SQL> select table_name, num_rows, sample_size from user_tables where table_name in ('T1', 'T2', 'T3');
TABLE_NAME NUM_ROWS SAMPLE_SIZE
-------------- ---------- -----------
T1 145334 145334
T2 146190 14619
T3 145334 145334
官方文档并没有说明AUTO_SAMPLE_SIZE具体的值是多少,但是从实验结果来看,这个值就是100。这就回答了文章的第一个问题。
Oracle为什么会默认采用100%的方式来收集统计信息呢,在ASKTOM有同行就提出过这个问题“DBMS_STATS.AUTO_SAMPLE_SIZE seems to always generate 100%”,他们的回复是为了得到精确的distinct列值。接下来我们就来看下全量采集和部分采集列的distinct区别。
SQL> select a.column_name, a.num_distinct "t1.num_distinct", b.num_distinct "t2.num_distinct",
2 round((a.num_distinct - b.num_distinct) * 100 / a.num_distinct, 1) "diff",
3 a.sample_size "t1.sample_size", b.sample_size "t2.sample_size"
4 from (select table_name, column_name, num_distinct, sample_size from user_tab_col_statistics where table_name in ('T1')) a,
5 (select table_name, column_name, num_distinct, sample_size from user_tab_col_statistics where table_name in ('T2')) b
6 where a.column_name = b.column_name and a.num_distinct > 0 order by "diff" desc;
COLUMN_NAME t1.num_distinct t2.num_distinct diff t1.sample_size t2.sample_size
------------------------------ --------------- --------------- ---------- -------------- --------------
OBJECT_NAME 64552 10300 84 145334 14619
SUBOBJECT_NAME 1015 385 62.1 68251 6856
TIMESTAMP 2585 1240 52 145212 14610
LAST_DDL_TIME 2490 1257 49.5 145212 14610
CREATED 2312 1209 47.7 145334 14619
NAMESPACE 21 15 28.6 145212 14610
OBJECT_TYPE 45 39 13.3 145334 14619
OWNER 80 71 11.3 145334 14619
TEMPORARY 2 2 0 145334 14619
DUPLICATED 1 1 0 145334 14619
STATUS 2 2 0 145334 14619
SHARDED 1 1 0 145334 14619
GENERATED 2 2 0 145334 14619
SECONDARY 1 1 0 145334 14619
SHARING 4 4 0 145334 14619
EDITIONABLE 2 2 0 25433 2531
ORACLE_MAINTAINED 2 2 0 145334 14619
APPLICATION 1 1 0 145334 14619
DEFAULT_COLLATION 1 1 0 16886 1705
DATA_OBJECT_ID 77785 78100 -.4 77822 7813
OBJECT_ID 145212 146100 -.6 145212 14610
T1表是全量收集,T2表是按10%的比例收集,从上面的结果可以看到,对于大部分字段通过部分采样的方式都能估算得很准确。但对于OBJECT_NAME这个列,估算出来的值和全量统计的差别很大,我们来看一下是什么原因导致的。
SQL> select count(*), object_name from t1 group by object_name order by count(*) desc;
COUNT(*) OBJECT_NAME
---------- -----------------
690 S_AAA_CCD
690 S_ABA_CED
690 S_ACA_CCD
690 S_ADA_CCD
690 PK_AEA_CED
...
1 GV_$CON_SYSSTAT
1 GV_$DATAFILE
1 GV_$TABLESPACE
1 GV_$ROLLSTAT
1 GV_$PARAMETER
可以看到OBJECT_NAME这个列的数据分布极不均匀。因此对于分布不均匀的列,通过部分采样方式得到的distinct值与实际的distinct值差别就会比较大。这就回答了文章的第二个问题。
三、采样算法
以下是个人的一些娱乐性思考
-
等比放大,即(采样得到distinct值 / 采样行数) x 总行数。
举个例子,假设表有1000行数据,只采样100行,A列有95个不同的值,即count(distinct A) / count(A) = 95%,那么等比放大很容易推导出1000行数据,有950个A的不同值。但是如果这100行中B列只有2个不同的值,即count(distinct B) / count(B) = 2%,那么对于1000行的表来讲,B的不同值是不是等于2% * 1000呢?很有可能不是,说不定全表就这两个不同值,例如性别。所以通过等比放大得到的distinct值就不准。这种算法有明显的缺陷。 -
按增长率估算,即将采样得到的前5%作为一个基数,采样得到的后5%作为一个增长率。(假设采样比例是10%)
还是举个例子,假设表有1000行数据,只采样100行,采样的前50行,C列有40个不同值。采样的后50行,C列又多了30个不同值,即总共有70个不同值。那么后面的90%都会保持这个增长速度。则总体的C列不同值为40 + 30 * ((100-5)/5) = 610。再来看一种情况,假设采样的前50行,D列有2个不同值。采样的后50行,D列多了0个不同值,即不同值总数保持不变。那么后面的90%都会保持这个增长速度。则总体的D列不同值仍为2。这种方式似乎比等比采样更加合乎实际情况一点。接下来就用python去实现这个算法,看看与oracle的估算差别有多大。以下为python代码。
import random
import cx_Oracle
def func(ins):
SAMPLE_PERCENT = 10 # 采样比例%
sample_size = int(len(ins) * SAMPLE_PERCENT / 100)
# 对数据进行采样
sample = random.sample(ins, sample_size)
head_half_sample = sample[0:int(len(sample)/2)] # 采样数据的前一半
head_half_sample_distinct = len(set(head_half_sample)) # 采样数据的前一半的distinct值
full_sample_distinct = len(set(sample)) # 采样数据的全量distinct值
tail_half_inc = full_sample_distinct - head_half_sample_distinct # 采样数据的distinct增量
estimate_distinct = round(head_half_sample_distinct + tail_half_inc * (100 - SAMPLE_PERCENT/2) / (SAMPLE_PERCENT/2))
return estimate_distinct
def test(colname):
DATABASE_URL = 'xxxxx'
conn = cx_Oracle.connect(DATABASE_URL)
curs = conn.cursor()
sql = 'select {} from t1'.format(colname)
curs.execute(sql)
tmpdata = []
for i in curs.fetchall():
tmpdata.append(i[0])
res = func(tmpdata)
curs.close()
conn.close()
return res
for i in ['OBJECT_NAME', 'SUBOBJECT_NAME', 'TIMESTAMP', 'LAST_DDL_TIME', 'CREATED', 'NAMESPACE', 'OBJECT_TYPE',
'OWNER', 'TEMPORARY', 'DUPLICATED', 'STATUS', 'SHARDED', 'GENERATED', 'SECONDARY', 'SHARING', 'EDITIONABLE',
'ORACLE_MAINTAINED', 'APPLICATION', 'DEFAULT_COLLATION', 'DATA_OBJECT_ID', 'OBJECT_ID']:
print(i, '估算的distinct->', test(i))
运行结果
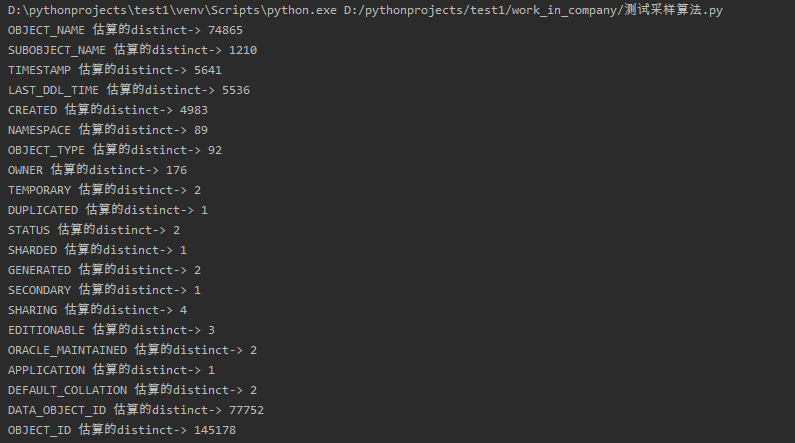
再来跟之前的一个表格进行对比,按增长率的方式估算的distinct值看上去也能接受。
COLUMN_NAME 实际的distinct 数据库估算的distinct python估算的distinct
------------------------------ --------------- -------------------- --------------------
OBJECT_NAME 64552 10300 74865
SUBOBJECT_NAME 1015 385 1210
TIMESTAMP 2585 1240 5641
LAST_DDL_TIME 2490 1257 5536
CREATED 2312 1209 4983
NAMESPACE 21 15 89
OBJECT_TYPE 45 39 92
OWNER 80 71 176
TEMPORARY 2 2 2
DUPLICATED 1 1 1
STATUS 2 2 2
SHARDED 1 1 1
GENERATED 2 2 2
SECONDARY 1 1 1
SHARING 4 4 4
EDITIONABLE 2 2 3
ORACLE_MAINTAINED 2 2 2
APPLICATION 1 1 1
DEFAULT_COLLATION 1 1 2
DATA_OBJECT_ID 77785 78100 77752
OBJECT_ID 145212 146100 145178
限于时间,测试到此结束。后面有时间再学点统计相关的知识。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK