

图数据挖掘:网络中的级联行为 - orion-orion
source link: https://www.cnblogs.com/orion-orion/p/16856006.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

1 网络中的传播
1.1 一些传播的例子
我们现在来研究网络中的传播。事实上,在网络中存在许多从节点到节点级联的行为,就像传染病一样。这在不同领域中都有所体现,比如:
-
生物学 传染性疾病
-
信息技术 级联故障,信息的传播
-
社会学 谣言、新闻、新技术的传播,虚拟市场
下图就展示了一个信息经由媒体扩散(diffusion)的过程:
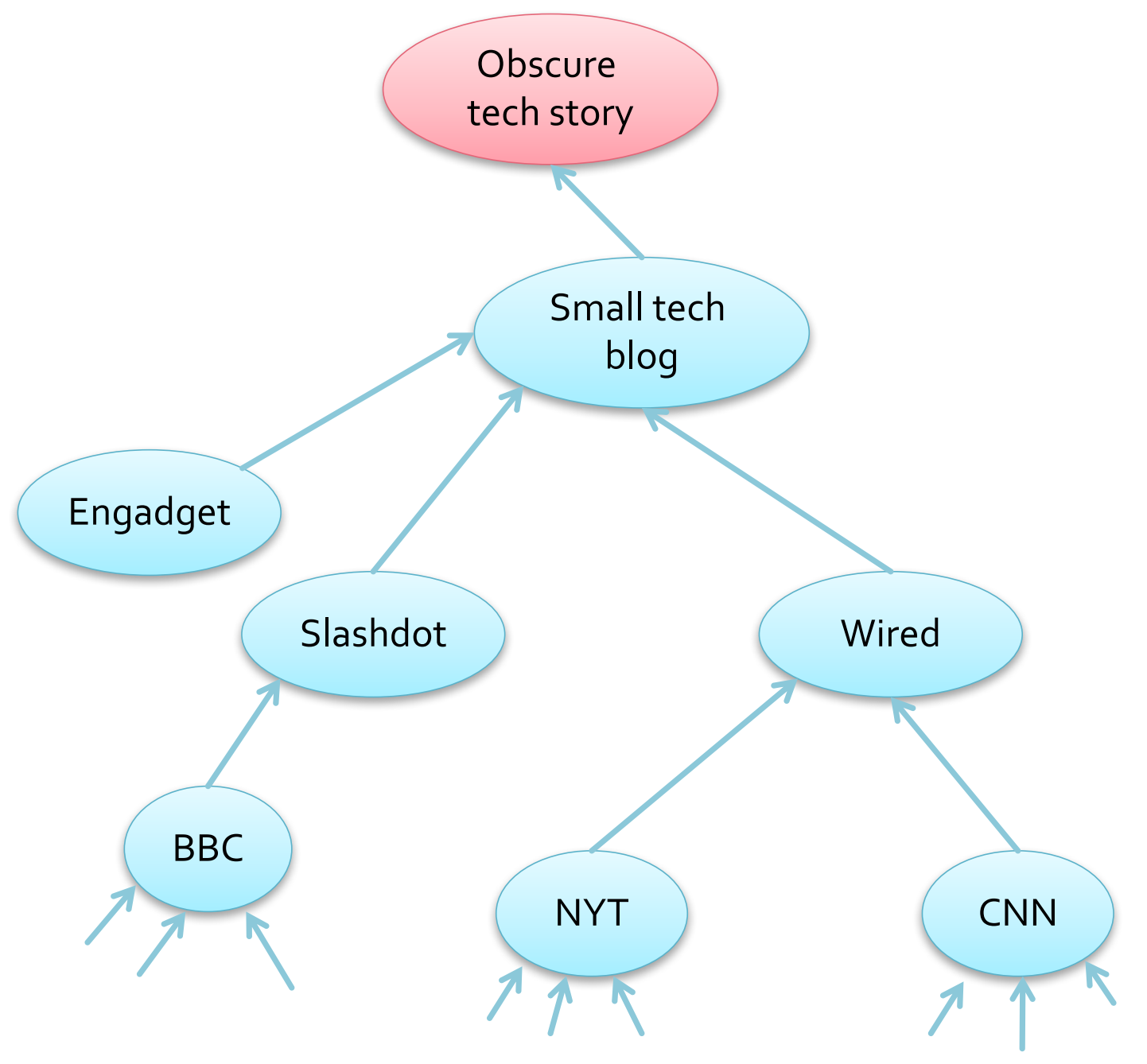
1.2 基于网络构建传播模型
接下来我们看如何基于网络构建传播模型。以传染病为例,传染病会沿着网络的边进行传播。这种传播形成了一个传播树,也即级联,如下图所示:
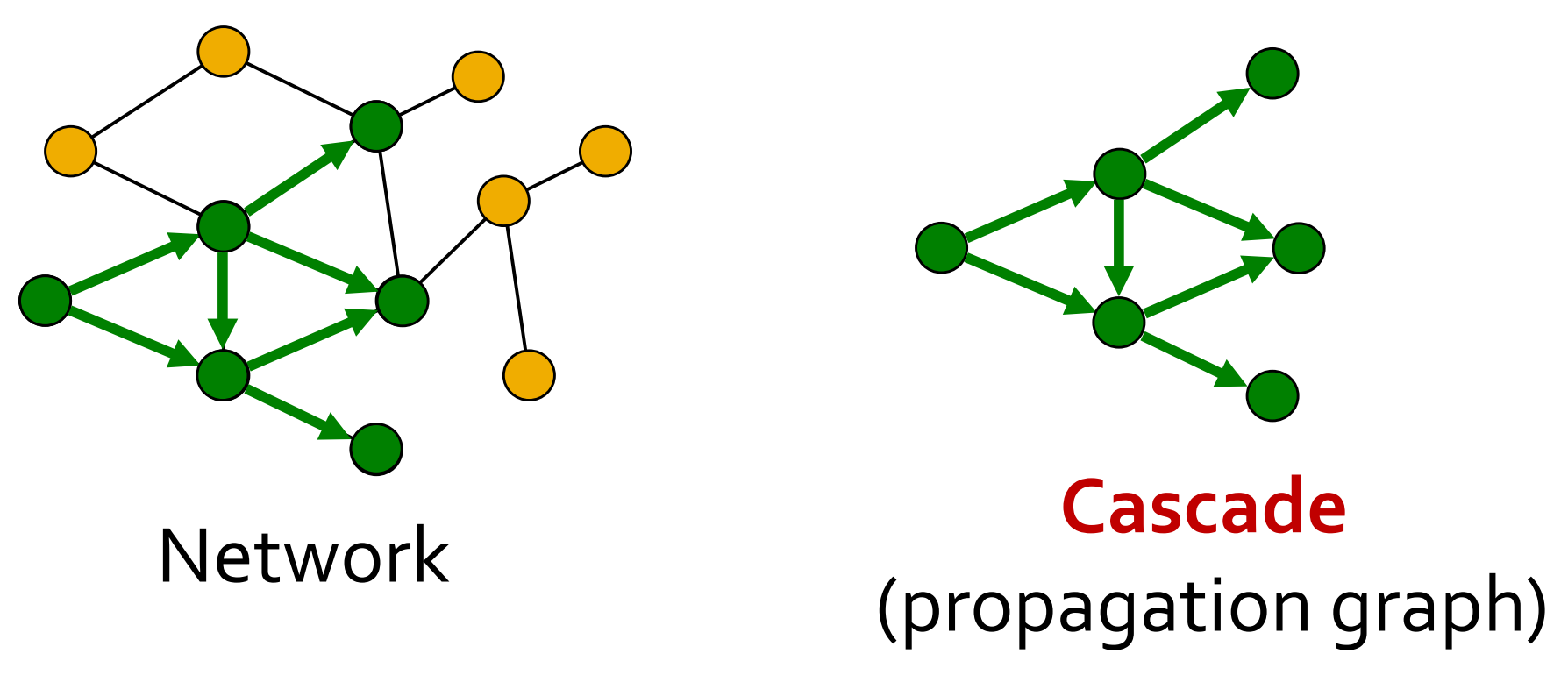
我们定义一些术语:将其中传播的对象为contagion;被传染这一事件称为adoption、infection或activation;已被传染的节点称为infected/active nodes或adoptors。
接下来我们来看如何为扩散进行建模。目前已经提出了决策模型和概率模型两种模型。
- 决策模型 在这种模型中每个节点会先观察其邻居的决策,然后再以此为依据做出自己的决策。比如若我的kk个朋友去参加了游行,那么我就去。
- 概率模型 在这种模型中一个已被传染的节点会以一定概率传染其它没有被传染的节点。比如我有几个邻居已经被传染,那么我也有一定概率被传染。这种模型通常用于影响或疾病传播建模。
本篇文章我们介绍决策模型中的集体行动模型和协调博弈模型,下篇文章我们再介绍概率模型。
2 集体行动模型
2.1 模型介绍
Granvetter于1978年提出了集体行动(collective action)模型[1]。在这种模型中,每个人都可以看见任何人的行为并以此为依据进行行动(这也就意味着我们假设网络是完全图)。该模型在日常生活中的一些常见例子包括:在剧院鼓掌或起身离开、在股市中是否存钱以及日常生活中的抗议、罢工等等。接下来我们来探究参与某个给定活动的人数是如何随着时间的推移而增减的。
设有nn个人且每个人可以观测到彼此的行动。对每个人ii都有一个阈值ti(0≤ti≤1)ti(0≤ti≤1)。当且仅当至少有占比titi的人采取了某个行为时,节点ii也会采取该行为。事实上ii节点采取行动的概率是如下的阶跃函数(横轴是采取行动的人数比例):
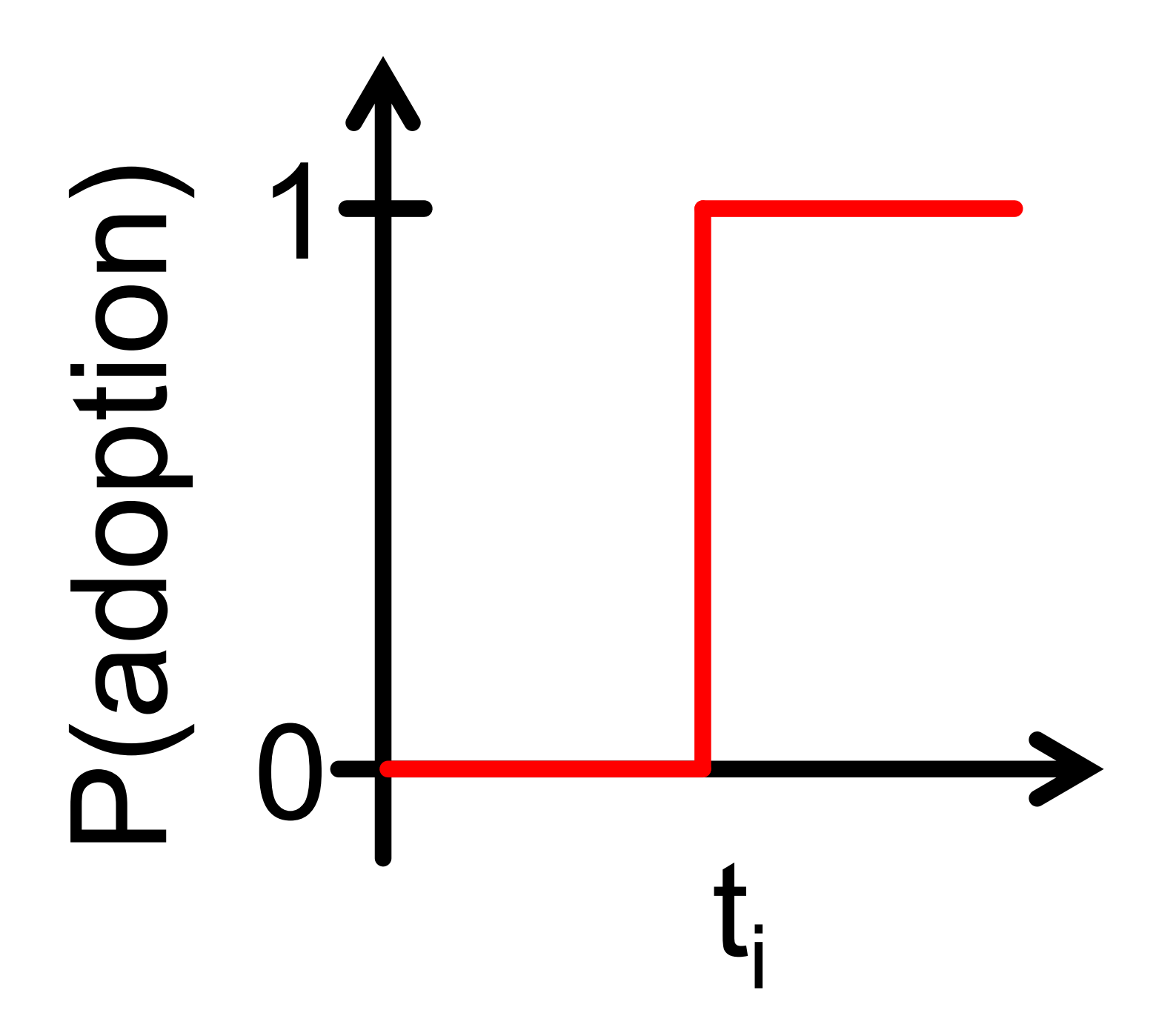
小的titi也就意味着ii是一个早采纳者(early adopter),而大的t1t1则意味着ii是一个迟采纳者(late adopter)。我们假设这里的时间步是离散的。
我们设{t1,⋯,tn}{t1,⋯,tn}为所有人的行动阈值集合。设F(x)F(x)为阈值ti≤xti≤x的人数比例(F(⋅)F(⋅)事先已给定,它是传染一个的属性),它是非递减的,即满足:
该模型是一个动态的模型,采取行动的人数会一步步地变化,如下图所示:
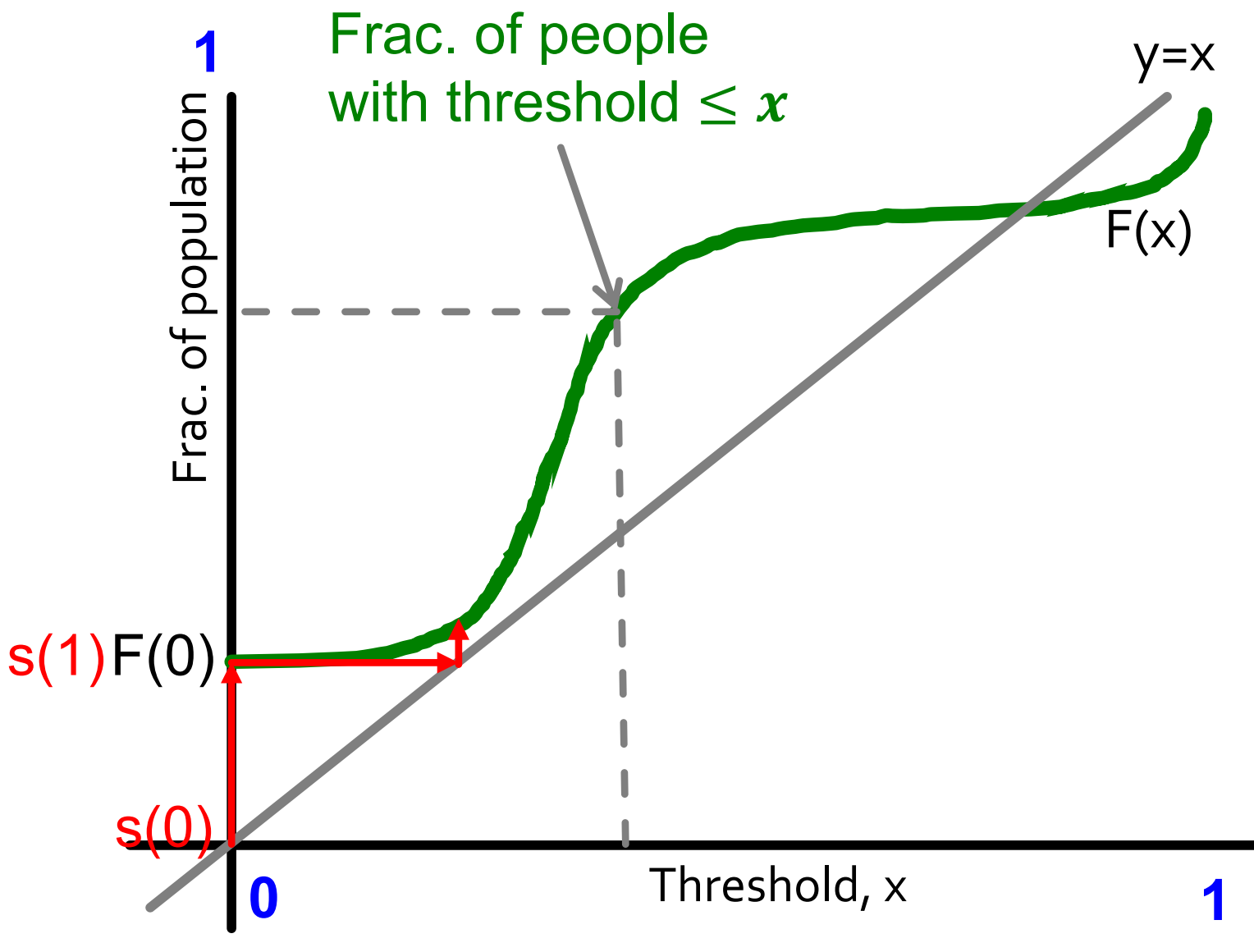
图中F(x)F(x)表示阈值ti≤xti≤x的人数比例,s(t)s(t)表示在tt时刻已加入行动的人数比例。我们发现行动人数的变化速率并不均匀:中间最陡,说明大多数人的阈值比较集中,而左右两端则可分别视为早采纳者和晚采纳者的阈值。
我们模拟s(t)s(t)随着tt的迭代过程:
我们进一步地进行模拟,有:
直观地理解该迭代,就是tt时刻已加入的行动人数s(t)s(t)会在t+1t+1时刻带动更多的人(F(s(t))F(s(t)))加入行动。最终模型会收敛到不动点(fixed point)F(x)=xF(x)=x,如下图所示:
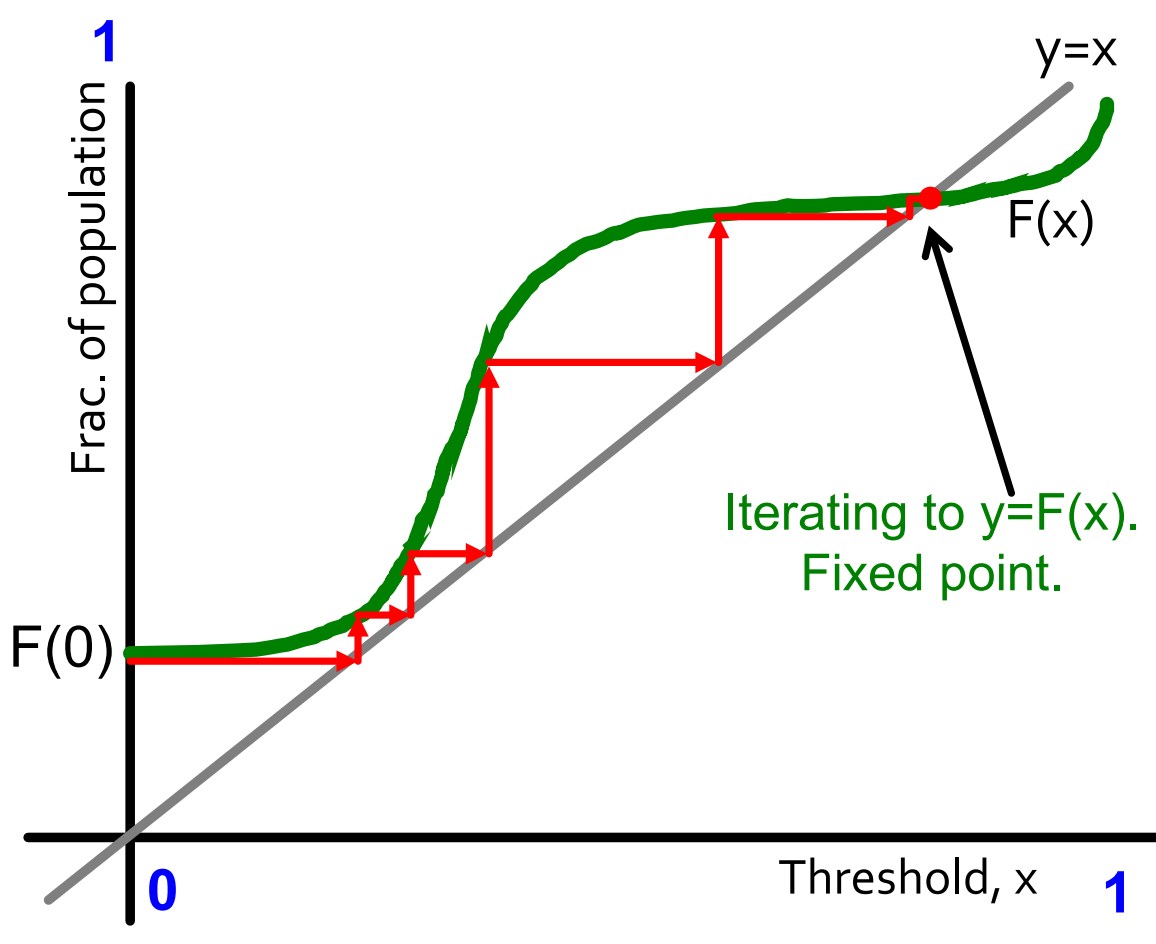
当然,可能也存在其它不动点。不过从00开始我们只能到达其中的第一个。
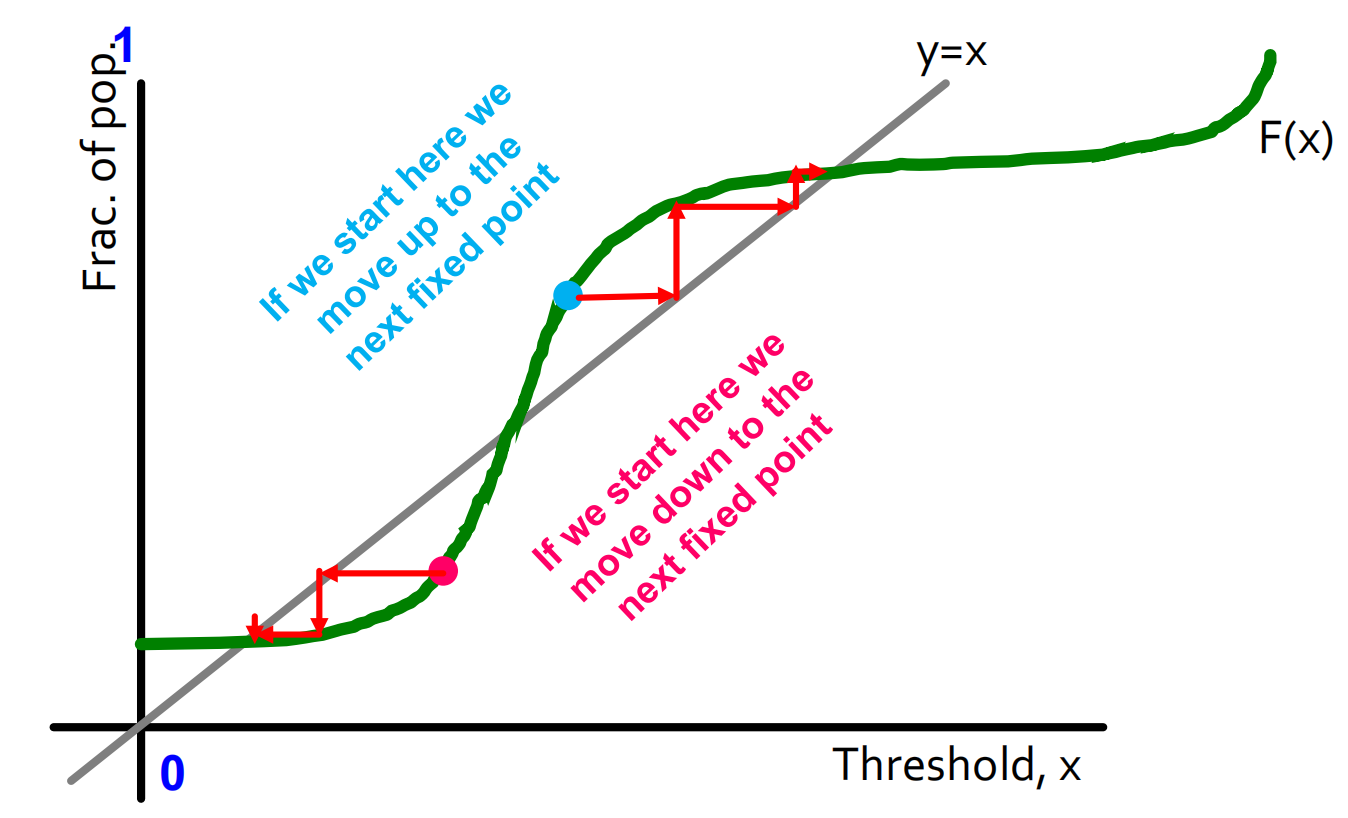
如果我们想要从某个其它的地方开始这个过程,则可以往上/往下移动到下一个不动点:
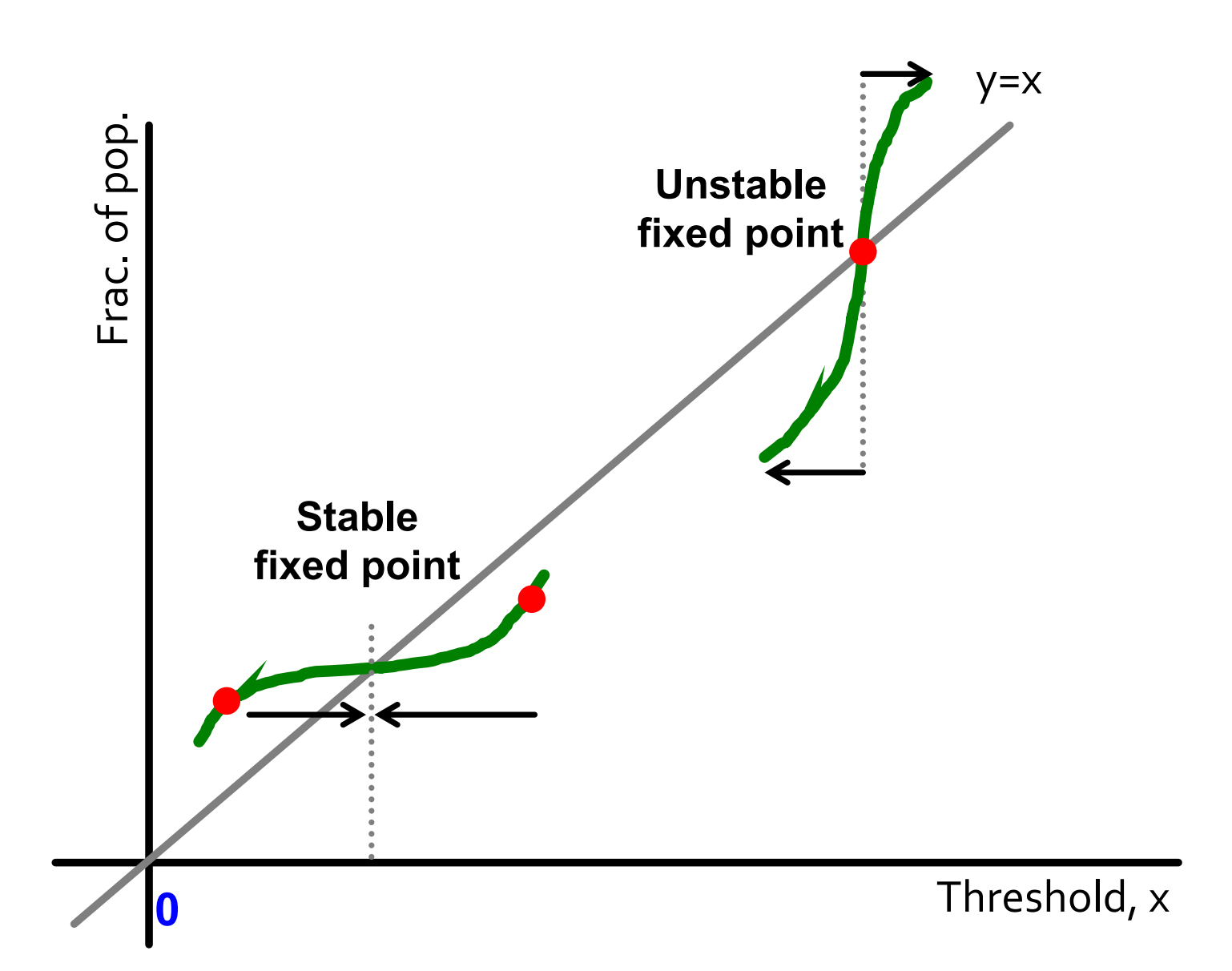
如下图所示,不动点有稳定不动点和不稳定不动点之分。稳定不动点周围坡度较为平缓,不稳定不动点周围坡度较为陡峭。
2.2 不连续的过渡
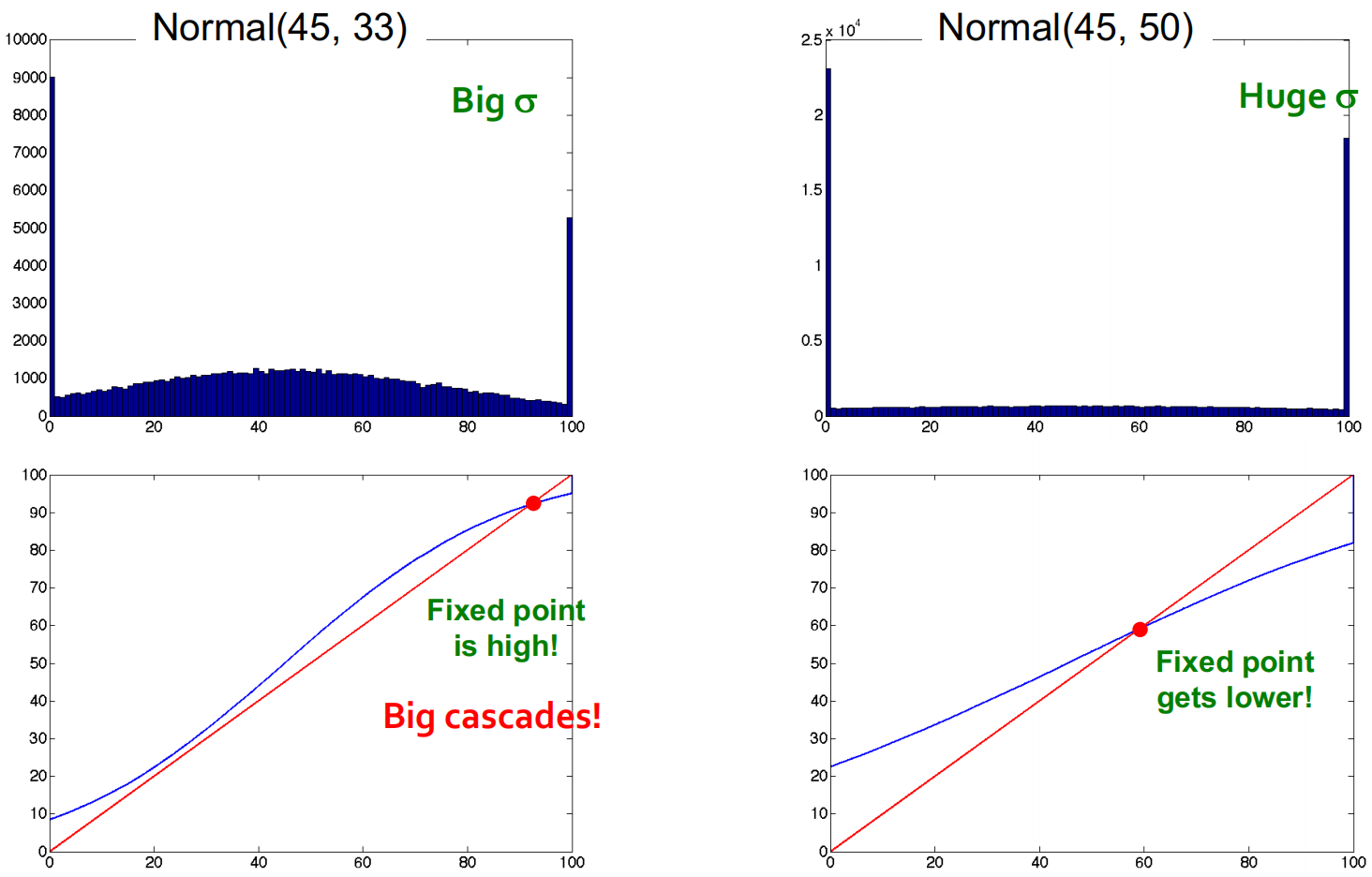
我们假设每个节点的阈值t1t1是独立地从分布F(x)=Pr[ thresh ≤x]F(x)=Pr[ thresh ≤x]中采样得到的。假定该分布为μ=45μ=45的截断(truncated)正态分布,则F(x)F(x)的图像会根据该分布的方差进行变化,如下图所示:

可以看见,大的方差会使早采纳者和主流人群之间的过渡更为平稳。
我们尝试再增大方差则不动点会升高,然而如果我们再进一步增大方差则不动点又会降低:
2.3 模型的弱点
首先,该网络缺少一些社交网络中的概念。比如在社交网络中有一些人是易受影响的。而这直接关系到谁是早采纳者,而不仅仅是早采纳者有多少。
此外,该模型仅仅是建模了人们对参与人数的认识,而不是实际参与人数的多少。也即和“你认为谁会采取该行为”和“谁实际采取了该行为”的区别。这会导致人们在一段时间被“锁定”在某些选择上。
最后,在对阈值的建模上,我们还可以探索更多的分布,或者从一些基础理论(如博弈论模型)来对阈值进行推导。
2.4 多元无知现象
上述的模型需要假设网络是完全图的。然而在现实世界,每个人接受的信息其实大都是片面的,而这会导致他们根据周围的信息来对集体行动做出的决定并不靠谱。比如若某个专制政府限定公民之间的沟通,那么就算已经有足够大的人口比例想反对当前政府并采取极端措施,他们也会觉得自己是一个小群体,并认为这种反抗有很大风险。
多元无知(pluralistic ignorance) 是指人们普遍地错误估计整个民众对一些意见的反应。这是一个使用广泛的原则,不仅仅是在一个中央集权制度限制信息的流通环境。例如,1970年在美国进行的一项调查表明(同一时期实施的几个调查也得到了类似的结果),虽然那个时期只有少数美国白人主张种族隔离,大大超过50%50%的人认为他们所在地区大多数美国白人支持这个主张[2]。
3 协调博弈模型
3.1 模型介绍
该模型基于两个玩家的协调博弈(coordination game)理论,假设每人只能从行为AA或BB中选一个来采纳,且如果你和你的朋友采取了相同的行为,则你会获得回报(payoff)。
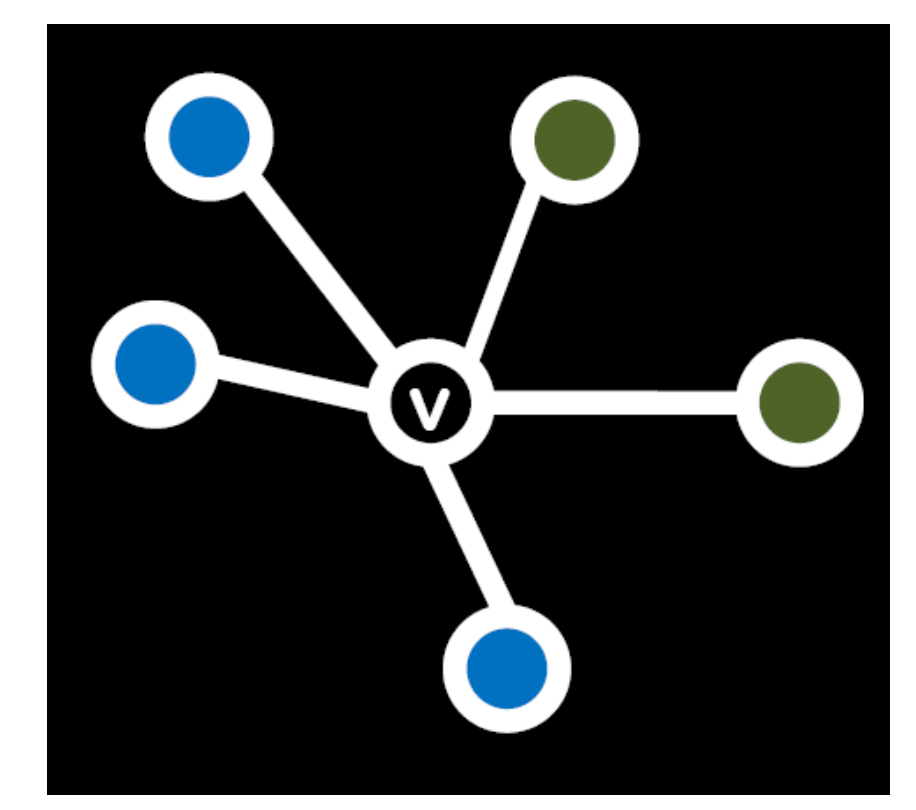
我们定义一个如下图所示的关于节点vv和ww的回报矩阵,使得当vv和ww都采取行为AA的时候,它们获得回报a>0a>0;当vv和ww都采取行为BB的时候,它们获得回报b>0b>0;当vv和ww采取相反行为的时候,它们获得00回报。
| w-A | w-B | |
|---|---|---|
| v-A | a,aa,a | 0,00,0 |
| v-B | 0,00,0 | b,bb,b |
每个节点vv和会和所有其邻居进行一次这个游戏,最终算将每次进行游戏的回报进行求和。
接下来我们来看节点vv如何做出决策。
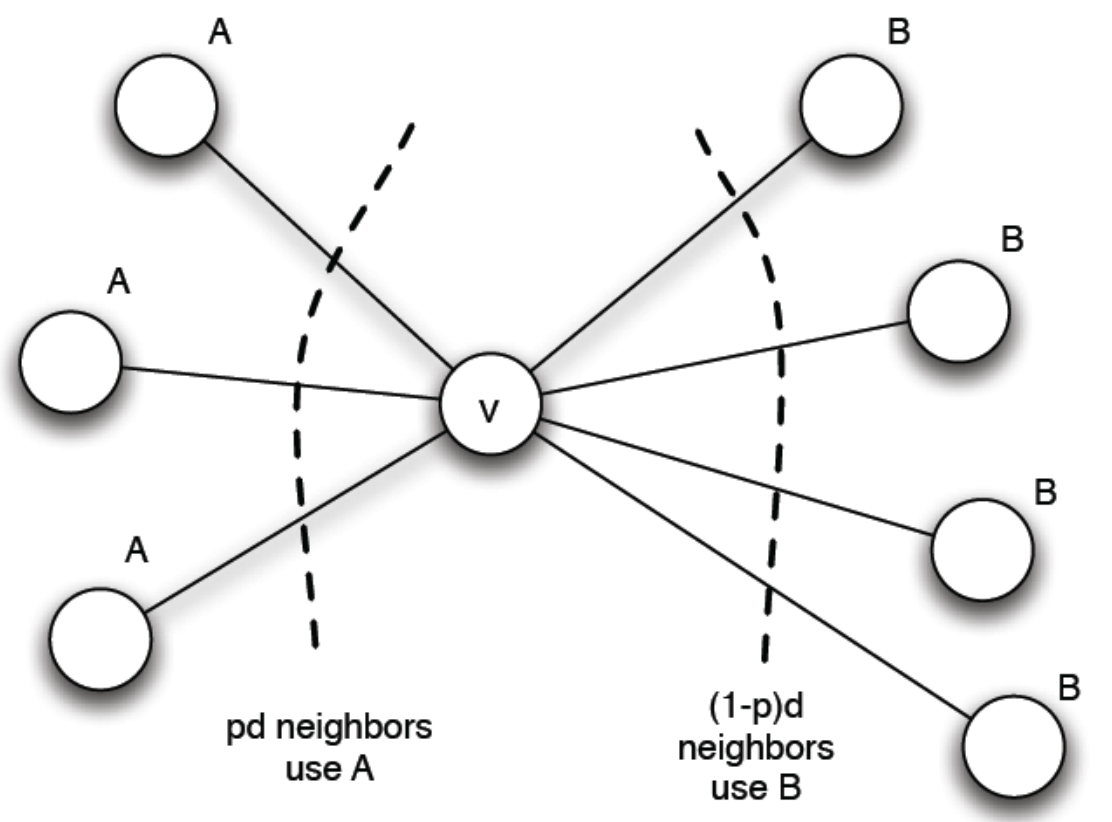
我们设节点vv拥有dd个邻居,pp为其邻居中采取行动AA所占的数量,(1−p)d(1−p)d为其邻居中采取行动BB所占的数量。则vv采取行动AA和BB分别获得的总回报分别为:
当a⋅p⋅d>b⋅(1−p)⋅da⋅p⋅d>b⋅(1−p)⋅d时vv会采取行为AA。进一步化简得到
我们设q=ba+bq=ba+b为回报阈值,即当p>qp>q时vv会选择行为AA。
3.2 传播实例
接下来我们来看一个协调博弈模型的传播实例。给定一个图,我们设每个人最开始都采取的行为BB。设存在一个由行为AA的早采纳者所组成的小子集SS,且我们假定他们是顽固派(Hard-wire),也即他们始终会采取行为AA而不管使用多少回报来企图改变他们。
我们假定有以下的回报设置:对于一个节点而言,如果他的朋友中有大于q=50%q=50%的人采取行为AA,则他也采取行为AA。这也就意味着a=b−ϵa=b−ϵ(ϵ>0ϵ>0是一个小的正常数)且q=12q=12。
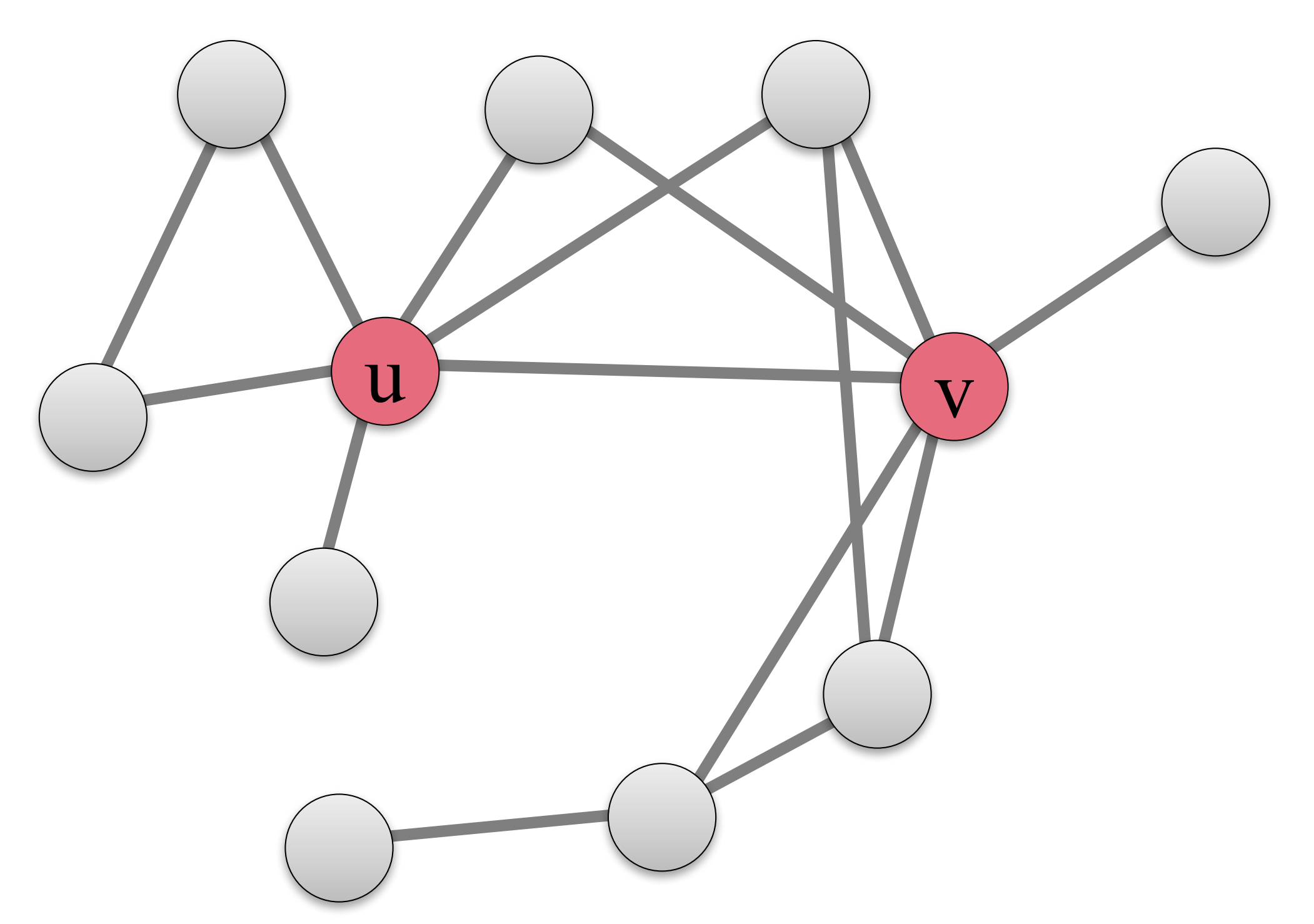
我们接下来看传播的模拟情况。初始时,S={u,v}S={u,v},它们采取行为AA,被标记为红色。
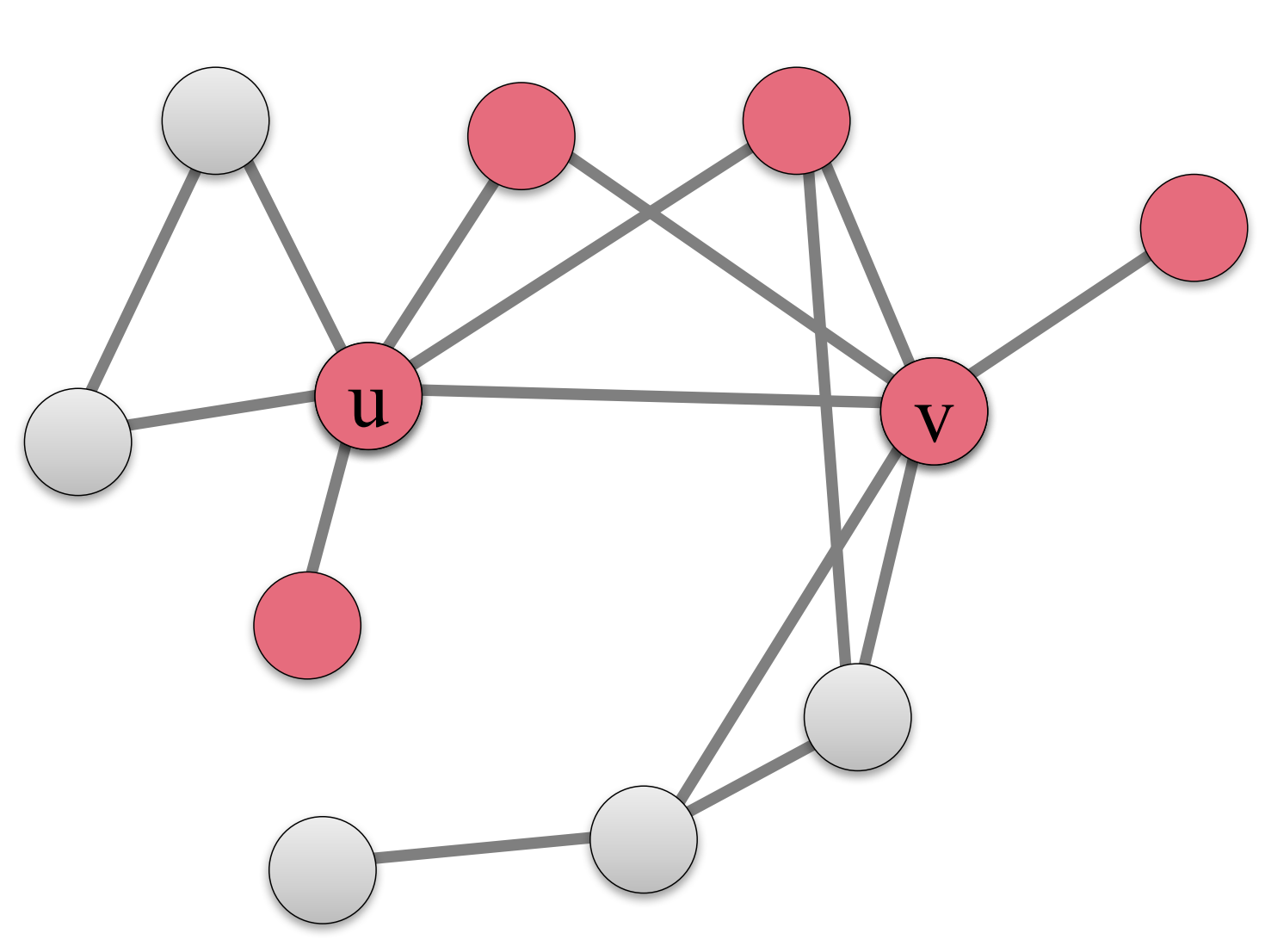
如果我的朋友超过q=50%q=50%是红色,则我也为红色。于是下一步该网络变化为:
又过了一个时间步变为:
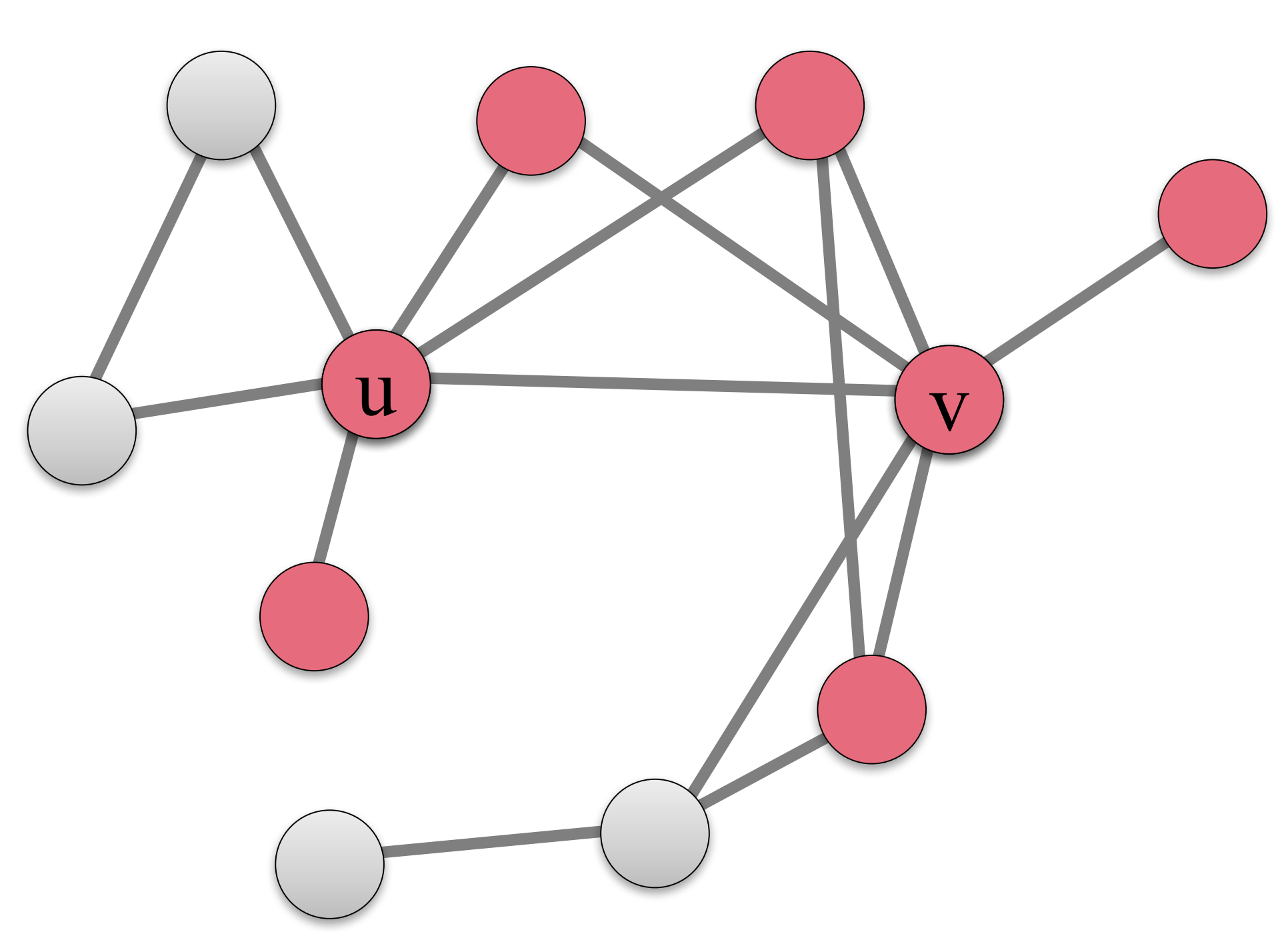
最后,网络变化为:

-
[1] Granovetter M. Threshold models of collective behavior[J]. American journal of sociology, 1978, 83(6): 1420-1443.
-
[2] O'Gorman H J, Garry S L. Pluralistic ignorance—A replication and extension[J]. Public Opinion Quarterly, 1976, 40(4): 449-458.
-
[4] Easley D, Kleinberg J. Networks, crowds, and markets: Reasoning about a highly connected world[M]. Cambridge university press, 2010.
-
[5] Barabási A L. Network science[J]. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 2013, 371(1987): 20120375.
__EOF__
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK