

An Assessment of Kubernetes and Machine Learning
source link: https://dzone.com/articles/an-assessment-of-kubernetes-and-machine-learning
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

An Assessment of Kubernetes and Machine Learning
Learn how K8s is uniquely suited for supporting machine learning, how to use it to make your ML pipelines run faster and better, and tools for ETL and ML.
This is an article from DZone's 2022 Kubernetes in the Enterprise Trend Report.
Read the Report
For more:
Kubernetes and machine learning (ML) are a perfect match. As the leading container orchestrator, Kubernetes' scalability and flexibility make it the perfect platform for managing extract-transform-load (ETL) pipelines and training ML models. That's why there's a thriving ecosystem for running ML tasks on Kubernetes. Let's look at how Kubernetes is uniquely suited for supporting machine learning, how you can use it to make your ML pipelines run faster and better, and some of the most popular Kubernetes tools for ETL and ML.
ETL and ML Pipeline Challenges
When it comes to building ML and ETL pipelines, engineers face many common challenges. While some are related to data access and formatting, others are the result of architectural problems.
- Resource management – Data volumes change over time and pipelines need a cost-effective way to manage resources.
- Dependency management – Pipelines need to execute tasks in the proper order and with the correct timing.
- Platform upgrades – Keeping up with security patches and vendor releases is a challenge for any platform engineer.
- Code upgrades – As data changes, so do the requirements for the systems that process it. Pipelines must be built on a platform that makes it easy to deploy and test new code.
Benefits of Kubernetes and ML
Kubernetes addresses many of the platform problems that data engineers wrestle with when they need to build or upgrade ETL and ML pipelines. By combining containers with automatic scaling, support for all major cloud providers, and built-in GPU support, it makes deploying code easier and allows engineers to focus on their core capabilities.
Kubernetes Has the Power To Support ML
Kubernetes automates the deployment, scaling, and management of containers. This makes it the preferred platform for running ETL pipelines and ML algorithms. Automated scalability means that the system can adjust to differing loads on the fly without your intervention. Whether it's an unusually large dataset or fewer training sessions than normal, Kubernetes will scale your cluster up or down to compensate. This means less engineering time bringing newer systems online and lower cloud costs because unused systems stay shut down.
The advent of cloud-based Kubernetes systems like EKS and GKE has made building and managing Kubernetes clusters easier. But that doesn't mean you want to build one for every project. Kubernetes namespaces make multi-tenancy easy. You can share a single cluster across multiple projects and teams. You can even create namespaces for different versions of projects when you want to test new containers or algorithms.
Tracking versions and maintaining code consistency across different servers has always been a headache. Containers solve this issue by abstracting the infrastructure for you. You can target your model code for a single container runtime and Kubernetes can execute it anywhere. When it's time to update your code, you do it once in the container. You can even deploy your model against different code versions in the same cluster.
Kubernetes has experimental support for scheduling AMD and NVIDIA GPUs. You can attach GPUs to containers that need them, and Kubernetes will manage access and ensure that they're not overallocated. So the scalability Kubernetes provides you for training algorithms extends to advanced GPU hardware, too.
Kubernetes Facilitates ETL
ETL pipelines are, by nature, modular workflows. The name tells you that there are at least three steps:
- Extract data
- Transform data into a usable format
- Load data into storage for the training models that use it
Containers and Kubernetes make it easy to break down these processes into reusable components. And just like with models, the steps that run in containers are abstracted from the underlying hardware. Kubernetes also simplifies managing parallel pipelines for multiple datasets and establishing dependencies between steps in a pipeline.
Let's look at a pipeline in Figure 1 that has more than one data source. It needs to download two datasets, transform them, then collate them before loading.
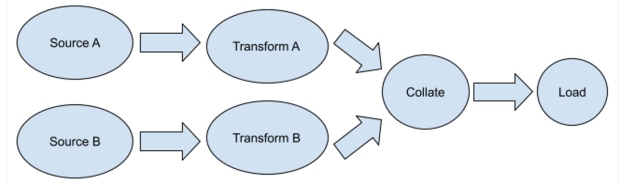
Figure 1
The pipeline needs to extract data from Sources A and B. Then it needs to transform them in independent processes. Only when both transformations are done can the collation step begin. Since each of these steps is a container, Kubernetes manages starting each one in order and ensures that the transform step doesn't load until both transform steps have completed their work. This is a straightforward example. You can manage more complicated pipelines with Kubernetes scripting tools like Airflow or Argo Workflows, which make it easy to run pipelines as directed acyclic graphs.
Finally, Kubernetes manages secrets for you, so it even makes pipelines that need to access data via logins or with PKI more secure.
Kubernetes Facilitates MLOps
Machine learning operations (MLOps) is a collection of machine learning tools and strategies. They make a data scientist's life easier by formalizing and automating the running of models. Kubernetes simplifies MLOps. A container orchestration system makes it possible for a team to run more than one version of a model in parallel. So instead of waiting for a single experiment to complete before trying the next, you can deploy more than one container in parallel and collect your results as they complete.
We've already mentioned how Kubernetes brings scalability to ML, but it bears mentioning again. With Kubernetes, you can drive models at a massive scale, and when you're done, you can destroy the nodes to cut costs.
Kubernetes ML Tools
Kubernetes' native ability to orchestrate containers originally drew data scientists to it, but since then, teams have developed powerful tooling to make using it even better. Kubeflow is an open-source ML toolkit for deploying ML workflows on Kubernetes. It brings best-of-breed ML tools to Kubernetes in a way that makes them easier to use while taking advantage of container orchestration.
With Kubeflow, you can:
- Manage interactive Jupyter notebooks to experiment with models and deploy them to the cluster
- Train TensorFlow models and configure them for GPUs
- Build custom Kubeflow pipelines
- Export TensorFlow containers to the cluster
There are also several workflow orchestrators like the Argo Workflows and Airflow tools mentioned above. They make creating an ML pipeline with parallel processing and dependencies easy thanks to simple script languages.
Kubernetes ML Platforms
The list of tools that aid in running ML pipelines on Kubernetes doesn't stop there. There are many open-source and commercial tools that you can use to manage ETL and models on your K8s clusters:
| Name | Open Source or Commercial | Programmatic and/or GUI | Description |
|---|---|---|---|
| Kubeflow | Open source | Both | Collection of ML tools for managing and running models on a cluster |
| Open MLOps | Open source | Both | Collection of Terraform scripts for setting up ML tools on a cluster |
| Bodywork | Open source | Programmatic | Python-based tools for deploying and using ML pipeline tools on a cluster |
| Apache Airflow | Open source | Both | Scripting platform for orchestrating workflows |
| Argo Workflows | Open source | Both | Scripting platform for orchestrating workflows |
| AWS Sagemaker | Commercial | Both | AWS ML platform that will work with AWS EKS |
| Azure ML | Commercial | Both | Azure ML platform that will work with Azure Kubernetes |
Conclusion
We've covered how Kubernetes makes running ML pipelines faster, easier, and more cost-efficient. With containers, you can create ETL jobs and models that run anywhere. With Kubernetes, you can run those containers in parallel and at scale. We also took a brief look at some of the open-source and commercial tools available to make setting up your ML jobs even simpler. Now that you're familiar with the power Kubernetes can bring to your ML and ETL jobs, we hope you'll integrate it into your next ML project.
This is an article from DZone's 2022 Kubernetes in the Enterprise Trend Report.
Read the Report
For more:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK