

Key Takeaways From the Amazon DynamoDB Paper - DZone Database
source link: https://dzone.com/articles/key-takeaways-after-reading-latest-amazon-dynamodb-paper
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Key Takeaways After Reading the Latest Amazon DynamoDB Paper
It’s been a long time since DynamoDB published a paper. A few days ago, I read its newly published one, and I think it’s one of the most practical papers.
It’s been a long time since DynamoDB published a paper. A few days ago, I read its newly published one, “Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service,” and I think it’s one of the most practical papers in recent years for large-scale distributed systems from an engineering perspective. It doesn’t even explain much about the architecture because it doesn’t need to. Shared-nothing systems look similar, and the authors know exactly who the readers of this paper are ^_^. What’s more, the paper is written simply, and there’s no math!
After all, DynamoDB doesn’t need to try to “prove” anything. It has fully proven itself in the past ten years, both in terms of scale and stability. I found that the paper is relatively new, and not too many blogs talk about it, so why don’t I write something about it?
Predictable Performance > High Performance
I always believe that stable slow is better than unstable fast. 99 latency is more reflective of system design skills than average latency.
I don’t know if this is intentional, but it is also presented in the first section of the DynamoDB 2022 paper to see the importance.
DynamoDB wants to provide predictable performance. The first step is to abstract the workload, which introduces the concept of reading capacity unit (RCU) and write capacity unit (WCU). In fact, RCU and WCU are very close to queries per second (QPS) in the traditional sense: only the size of the target item is added so that you can do relatively accurate workload planning. For example, 1 WCU = 1 KB item’s 1 QPS. The first step to predictability is complete when the user can describe the workload in terms of RCU and WCU. DynamoDB’s scheduler can do many things, like pre-partitioning and pre-allocating resources, because the hardware capabilities for different models are abstracted into a combination of WCUs and RCUs.
Once you know the quota of each partition, it is probably a backpack problem for the scheduling. DynamoDB considers the sum of the quotas of the partitions of the same machine. The sum should be less than the total RCUs or WCUs that the machine can provide when allocating the quota of partitions, which is about 20%-30% from the example given in the paper. In the real world, inexperienced developers or system administrators usually squeeze the last bit of CPU and I/O out of the machine to pursue the “ultimate” performance. They must see 100% CPU usage before they are satisfied. However, the machine is already in a very unhealthy state in such cases. The long tail latency of requests will become very high, even though there may be an increase in throughput, but because of this unstable long tail, the observed performance from the user’s perspective will be “unpredictable.” In a production environment, we recommend over-provisioning about 30% of the machines for the same reason.
Burst is a simple idea. When allocating a quota, DynamoDB reserves some capacity for each partition. When the traffic spikes in the short term, it uses the reserved capacity. Adaptive capacity dynamically adjusts the quotas of different partitions after the user’s workload is skewed (but the total amount cannot exceed the total quota of the table).
It is important to note that burst and adaptive capacity are based on the assumption that the user’s workload does not change much and that the flow control is focused on the partition level (almost at the storage node level), that is, local scheduling.
This part of DynamoDB’s paper is a bit vague. My understanding of the strategy is that the request router periodically applies a request quota to global admission control (GAC). GAC maintains a global allocation policy; if a partition has been overloaded, the corresponding request router can directly deny service to customers to protect the rest of the system. The flow control at the partition level is also kept as the last line of defense at the node level.
For a shared-nothing storage system, the key to scale-out is the sharding strategy. DynamoDB chooses a dynamic sharding strategy. It also uses range split, but the difference is that DynamoDB’s partition concept uses size as the default splitting threshold. DynamoDB directly adopts a Load-based Split. Partitions have a default throughput threshold, which is split when it exceeds this value. Once you start monitoring the state of the load distribution over the key range, it is easy to get the optimal splitting point (which is not always the midpoint).
Another important splitting concept is when to avoid it. The paper mentions:
- Single row hotspot, which is well understood.
- The access pattern is the sequential order of keys (similar to iteration on Key). In this case, DynamoDB avoids splitting.
To summarize, the core of DynamoDB’s predictable performance:
- Uses a more accurate abstraction of workloads (WCU and RCU) instead of simple transactions per second (TPS), QPS, and data size.
- Pre-allocates quotas to partitions and strictly limits the flow.
- Leaves a margin on the node level as a temporary resource pool for unexpected scenarios (Burst).
- Uses global information for traffic scheduling and controls flow at all levels.
Failover With as Little Observable Impact as Possible
Let’s first talk about write-ahead logging (WAL). DynamoDB replicates logs to multiple replicas (the paper implies that the default is three) via a distributed consensus algorithm (Multi-Paxos for DynamoDB). However, DynamoDB also synchronizes WALs (it’s not a DB snapshot) to S3 periodically for higher durability. I understand that this is not only for higher durability but also for point-in-time recovery (PITR).
Another interesting detail about failover is that when a node in DynamoDB’s replication group fails, for example, if one of the three copies fails, the group leader immediately adds a log replica to the replication group. The log replica is actually what we often call a witness. I will also use the witness below instead of the log replica. This is a node that only stores logs and does not provide services. This is a very smart approach since, in the above case, although it also meets the majority, the system is very fragile at this time. To completely restore a new member, the time is usually longer (first copy the DB snapshot and then apply the recent logs), especially if the partition snapshot is relatively large. The process of copying the snapshot may introduce extra pressure on existing peers.
Adding a witness is low cost. The time mentioned in the paper is in seconds. It can at least ensure the security of the logs during data recovery. What’s more, for cross Availability Zone (AZ) deployment scenarios, this optimization can also reduce the write latency in the failover phase. For example, we have two AZs, one of which is the primary. We call it AZ-A, and it carries the main write traffic. Another AZ, AZ-B, is a standby for disaster recovery (or serves some local read traffic). When a node in AZ-A hangs, the Raft group of the data in this node does not stop writing (after leader reelection). However, according to the classical Raft, to meet the requirements of the majority, it must ask the peers in AZ-B and make sure the log persists successfully. It then could return the success to the client, which means the performance jitter is observed from the client (until a new peer in AZ-A is added). When we detect a node failure, immediately find a healthy node in AZ-A as a witness, and add it to this unhealthy group, the write to AZ-A can still achieve a majority, which saves the latency of synchronizing the log to AZ-B’s replica. From the client’s point of view, the system does not show significant jitter.
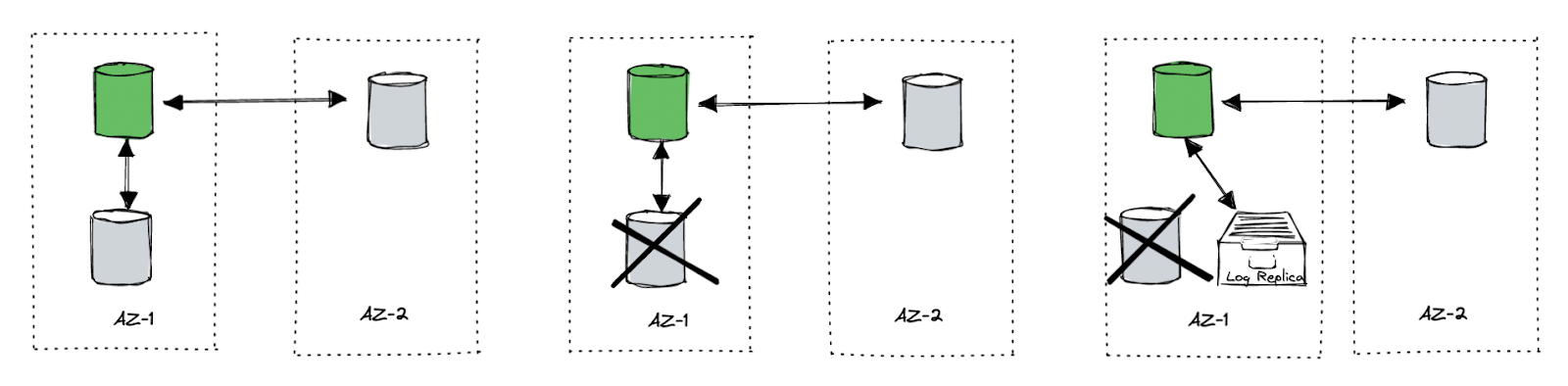
How DynamoDB deals with failover.
To reduce observable impact during failover, DynamoDB also improves Leader election for replication groups. For large-scale systems, network jitter or network partitioning are common. For example, there’s a peer in a replication group called peer X. Once X cannot connect to the group leader, according to the traditional election protocol, it rashly initiates a new election with a bigger voting term. Other peers stop voting for it. Observed from the user side, this part of the data is unavailable (service will be stopped during the election for data consistency), but the old leader might still be alive.
This is a common problem, but the solution is very straightforward. When a peer wants to initiate an election, it first asks other peers whether they will vote for it, confirming whether the older leader is alive or available. If not, then the peer can launch a new election. The DynamoDB paper mentions a similar mechanism. Before a peer initiates a new election, it asks other peers whether they also think the old leader is disconnected, and if not, it means that it is the candidate’s own problem and does not affect the normal nodes.
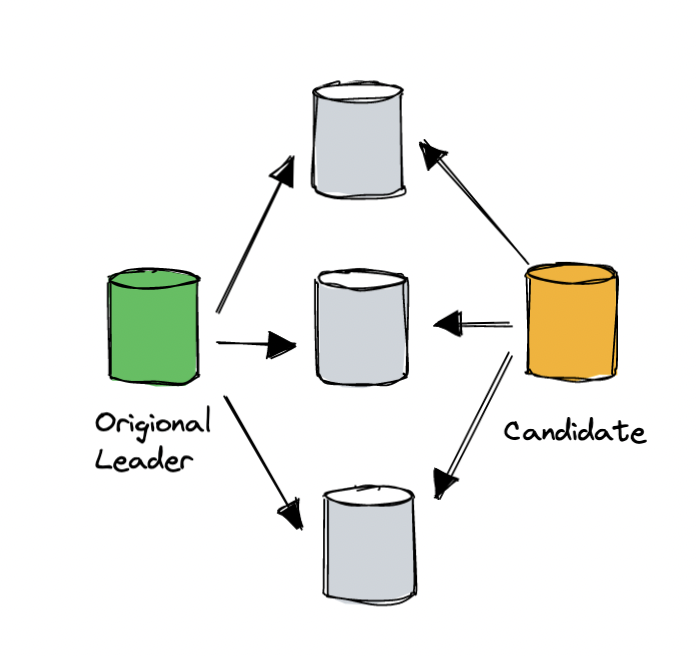
DynamoDB ‘s leader election process.
The worst failure of a large system is a cascading failure. The DynamoDB failure in 2015 is a typical one. The improvements mentioned in this paper for the metadata service remind me of this case. (I guess it was probably because of this case those improvements were made.) The solution is very intelligent, so I’ll paraphrase it a little.
DynamoDB observed that one of the root causes of cascading failures is traffic mutation in a short time. One of the common factors that cause traffic mutation is cache failure. Although we mostly think that the higher the cache hit rate, the better (the paper mentions that the cache hit rate of the partition router table is about 99.75%), such a high cache hit rate means that when there is a cache failure (or a cache warm-up phase when a large number of new nodes join), the metadata service must be able to carry 400 times the traffic surge (worst case, 0.25% → 100%). DynamoDB solves this problem in the following ways:
- DynamoDB adds a level of distributed memory cache MemDS in the middle of the request router and the metadata service. After the local cache of the request router is missed, it does not access the meta service directly but accesses MemDS first. Then MemDS accesses the metadata service in the background to fill in the data. Adding a layer of cache for peak shaving is equivalent to adding another layer of insurance, which is a common way.
- The second way is very smart. I just mentioned that the request router gets metadata through MemDS when the request does not hit the cache in MemDS. This is easy to understand. But what is really smart is that even if the cache hits, MemDS will also asynchronously access the metadata service. The reasons are:
- It ensures that the existing cache in MemDS is updated as soon as possible.
- It brings “stable” traffic to the metadata service (although it may be larger).
The ‘stable’ but larger traffic is, for example, the equivalent of playing in the water so that you can have good confidence when a flood comes.
3. GAC based on limited token (capacity) reduces the impact of cascading failures.
In addition, for services on the cloud, one big advantage is that updates are released faster than traditional enterprise software. However, the deployment of a new release is usually the most vulnerable time of the system, and DynamoDB, as a large-scale system, is unlikely to do offline updates. For rolling updates, the old and new versions of nodes will coexist during the update process. Therefore, the new version needs to communicate with the nodes running in the old version and then switch to the new protocol after all nodes have deployed the new version.
DynamoDB’s work on stability and failover can be summarized in one phrase: minimizing the observable client-side impact, which I think is part of the “predictable” performance.
Database ≠ Database as a Service
I would say the Dynamo described in the paper a decade ago is more like a DB (laugh). This DynamoDB is actually an accurate Database as a Service (DBaaS). You may wonder what the difference is. I think building a DBaaS is not simply deploying multiple database instances to the cloud and hosting them. From the user’s point of view, the endpoint provided by a DBaaS may act like a database instance, but under the hood, the implementation may not be so straightforward. Take an extreme example: let’s say a DBaaS provides SQLite as a service. I think it is unlikely that it will really create a new container for every user, provision the environment, and then start an SQLite process to expose it publicly. It is likely to be a shared service and just behaves the same as SQLite externally to better utilize the resources.
So to build a DBaaS, the first thing to consider is multi-tenancy. The reason DynamoDB has to be redesigned is that the old Dynamo does not support multi-tenancy. This is unacceptable for cloud services. When transitioning to the cloud, we learned that cloud-native is not simply moving a database to the cloud and deploying it for different users. It requires a deep transformation from the kernel to the control platform for the capabilities and environment provided by the cloud.
Another significant difference between DBaaS and a database is that DBaaS is often difficult to deploy locally. In fact, modern DBaaS is built with many microservices or heavily dependent on features provided by cloud vendors (especially storage and security-related services). You can also see in the DynamoDB paper that the request router is a service in charge of connections from different tenants; GAC is a service; the authentication system is a service; metadata is a service, and storage is a service. This is not to mention the dependencies on other services like S3/IAM and so on. It’s interesting that the paper doesn’t mention any EC2 or EBS, which makes me guess that DynamoDB’s hardware infra is probably maintained by itself; that is, it runs on a bare-metal machine.
Finally, here are my takeaways from this paper:
- The more you understand the abstraction of workloads, the better it is to build predictable systems. The more granular the measurement of workloads, the more room you have to make money (or save costs).
- Consider multi-tenancy for your system from the beginning and from a global perspective.
- On the cloud, the access layer is very important. We can do many things in the access layer to improve the predictability of the system, including flow control, high availability, tenant isolation, and non-stop updates.
- For abstract scheduling, do flow control at different layers.
- Use microservices to build a platform that achieves multitenancy.
- The use of cloud infrastructure will save a lot of work, such as S3.
After reading this paper, I feel that there are many things that it didn’t address, including serverless architectures, GC strategy, and distributed transactions (ACID), but these don’t stop this paper from being a classic. I learned a lot from this paper.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK