Introduction to Snowflake
When we talk about the “doing” part of data engineering, people usually want to say something about ETL, like, “How is your ETL working today?” This is a terrible term and worse in the plural. What’s new is flipping the “T” and “L” to get an ELT, which unfortunately isn’t a delicious sandwich, but thankfully is a delicious data movement pattern. However, I think a more general and less confusing term for my hunger pangs is called a data feed. If data is the new oil, it should be moving through the pipeline! However, unlike oil pipelines, data pipelines are very easy to build and maintain. There is no need to call that tough guy to drill a hole in your apps and extract that sweet, sweet byte gold. Let’s take a look at every bit of integrated data engineering that Snowflake has to offer.
Image Source: -docs.snowflake.com
A data lake is one of the terms in our industry that has changed a lot over the years. When I think of a data lake as a workload that organizations run, my first thought goes back to the days of Hadoop.
Hadoop promises that processing real big data in its raw form is possible and optimal for organizations that want to unlock insights with all their data in one place. If you’ve been in the industry and witnessed Hadoop’s meteoric rise and fall, you know how the rest of this story goes. Hadoop was difficult to maintain, required knowledge of unfamiliar programming languages, was expensive to get right, and was cumbersome to access. Since Hadoop was a de facto data lake at the time, many organizations still had a bad taste in their mouths from failed projects that didn’t add any value to the business. The challenges brought about by data lake technology have resulted in the underutilization of the data lake and the unrealized value of the organization’s data.
Snowflake the Modern Data Lake
Snowflakes’ features and architecture have changed the landscape of the data lake. The Snowflake Data Platform offers a true cloud solution that enables all an organization’s data activities to live under a single source of truth. Snowflake approaches the historical challenges of the data lake by combining the best parts of the data warehouse and the data lake. Using Snowflake virtual warehouses for computing enables organizations to unlock fast insights from their data lake, allowing businesses to realize their data’s value fully.
Unlike Hadoop, Snowflake was built with several architectural concepts that perfectly match the goals of a data lake. Snowflake is a platform built from the ground up to take advantage of low-cost storage available in the cloud, provide the on-demand computing power necessary for big-power data, and offer structured and semi-structured data storage in one place. Snowflake’s unique architecture fits this requirement perfectly, all behind a SQL interface familiar to technicians and database administrators.
Built for the Cloud
When looking at Snowflake for data lake workloads, it’s important to remember why Snowflake may perform better in this situation. At its core, Snowflake uses a multi-cluster shared data architecture. This architecture enables Snowflake to scale on-demand computing while democratizing access to shared datasets across the organization. When you think about a data lake, it’s useful for two reasons:
- Entire organizations can query the data lake in pure SQL with different Snowflake compute clusters.
- Compute clusters are not dependent on data stored in Snowflake; Snowflake can augment existing cloud data lakes purely as a query engine.
Snowflake unlocks deployment patterns that complement the data lake paradigm in an efficient, powerful, and analyst-friendly way.
Snowpipe
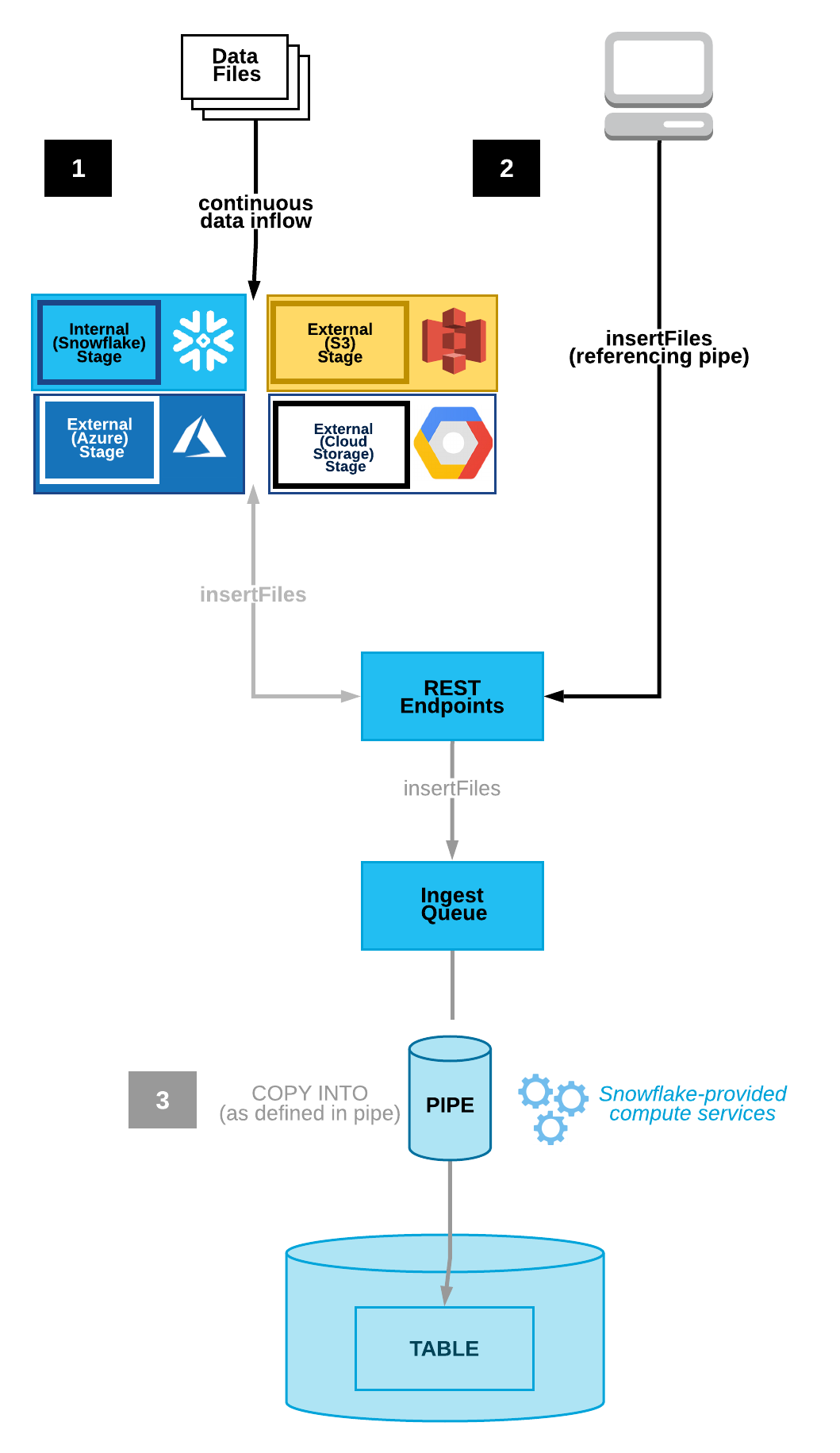
First – you need to get your data into Snowflake. This is usually done using the COPY INTO command. When your files are already available in cloud object storage, you must tell Snowflake, “Hey, Snowflake, copy those files to this table.” It’s not exactly simple, but it’s pretty close. The only problem is that you have to tell Snowflake to do it. Kind of like my wife telling me to take out the trash. This is where Snowpipe can help. Snowpipe is a service that automatically loads data into Snowflake from cloud storage systems. All you have to do is create a template in the form of a COPY INTO statement that will do the job.
Image Source: -docs.snowflake.com
The interesting part is how Snowflake uses event notifications from the cloud object store to tell Snowpipe what to fetch. For example, an Event message can be sent to AWS Simple Queue Service from AWS Simple Storage Service when a new file appears. Snowpipe is set up to watch for these notifications and will respond when it sees a new notification in the message queue. Of course, it’s not just for AWS. You can use similar services available in Google Cloud Platform and Microsoft Azure.
Next, we’ll want to capture these changes in the table data and play with them.
Streams
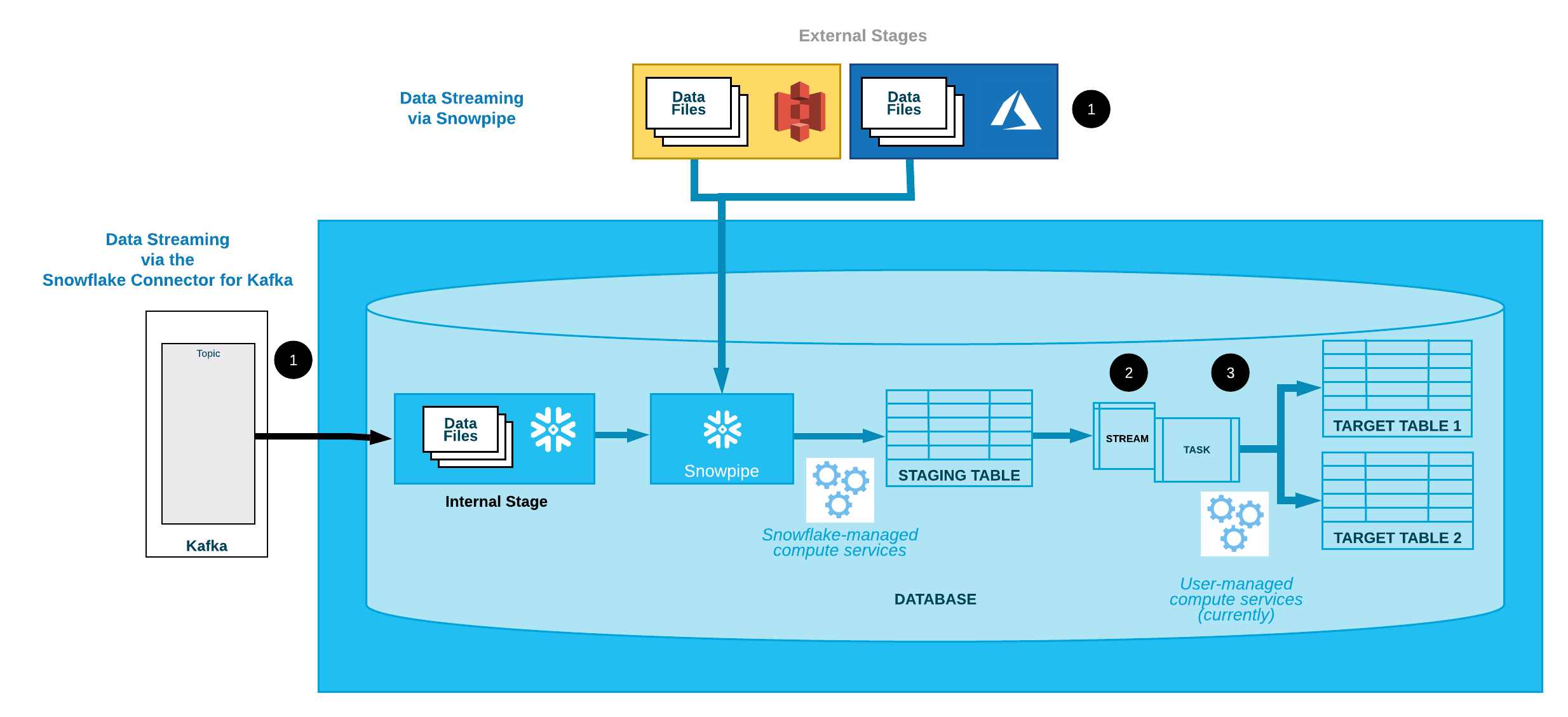
Streams are how Snowflake changes data collection. The data stream keeps track of what data has changed in the table – inserted, updated, or deleted. Streams work like any other table object in Snowflake. For example, you can query a data stream just like you can query a table. The interesting thing is that the stream contains the data in the table and some metadata columns about the records in this table.
Image Source: -docs.snowflake.com
Because we can query the stream like a table and have these metadata columns that say which rows were changed, we can write a query that only asks for the kind of changes we’re interested in. For example, if we are interested in new records, we can even write a query to do this: With the query results, we can take our new data and, for example, insert it into another table. The problem is that we need a way to run this query on some schedule.
Finally, we will see how we can run SQL at a scheduled time.
Tasks
We have our stream with the data and a query that selects only the new rows in our table. Using a Snowflake job, we can run this query on a schedule, so as the new data is been loaded in the initial table, we can capture and move it.
Tasks are a way to trigger actions in Snowflake. Typically, this can be an SQL statement or a stored procedure. Tasks provide two scheduling options: internal (in minutes) and cron-based. The cron scheduler is the typical scheduler that you’ll find on most Linux-based systems. The Cron schedule would be used if you wanted to run a job on a specific day or time. For example, if you wanted to insert new data into the target table only every day at 1:00 AM. An interval schedule can be used if you don’t have a specific preference and want the task to run every time after a certain number of minutes. For example, if you want to continuously insert new data into the target table as new data is loaded, you can set an interval schedule of every five minutes.
You might wonder, “Don’t these quests use up many of my Snowflake credits if they run all the time?” And the answer is YES! But … what you should do to avoid exhausting your credit budget if you’re using a stream is to set the WHEN argument using the SYSTEM$STREAM_HAS_DATA function. This way, the task will only act if the stream contains data. The task does not consume any credits while checking the data in the stream. This ensures that your task can run without unnecessarily using up credits.
Conclusion to Snowflake
When you look at Snowflake’s history as a data warehouse and the features that come with it, it’s easy to see what makes Snowflake best-in-class. A winning formula of unmatched performance, cloud-centric architecture, ease of use, and intuitive pricing set the stage for where Snowflake can go next. At Snowflake’s core principles, it’s a best-in-class data lake solution for organizations looking to the power of the cloud. The power of the Snowflake architecture is not unique to the data warehouse; it’s a catalyst for creating a data platform that organizations can rely on and move into the future.
- A data lake is one of the terms in our industry that has changed a lot over the years. When I think of a data lake as a workload that organizations run, my first thought goes back to the days of Hadoop.
- Snowpipe is set up to watch for these notifications and will respond when it sees a new notification in the message queue. Of course, it’s not just for AWS. You can use similar services available in Google Cloud Platform and Microsoft Azure.
- The data stream keeps track of what data has changed in the table – inserted, updated, or deleted. Streams work like any other table object in Snowflake.
- Snowpipe is a service that automatically loads data into Snowflake from cloud storage systems. All you have to do is create a template in the form of a COPY INTO statement that will do the job.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.


.jpg)