
7

Flink集群部署 - 女友在高考
source link: https://www.cnblogs.com/javammc/p/16846245.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

集群 standalone 安装部署
- 下载安装包
下载页面:https://archive.apache.org/dist/flink/flink-1.7.2/
我这里安装的 flink-1.7.2-bin-hadoop27-scala_2.11.tgz 版本。
- 修改配置文件 conf/flink-conf.yaml
修改如下两个参数:
#填你机器的host名
jobmanager.rpc.address: linux2
taskmanager.numberOfTaskSlots: 2
- 修改配置文件/conf/slave
linux2
linux3
linux4
- 将文件发送到其他两个机器
scp -r flink-1.7.2 linux3:/opt/lagou/servers/
scp -r flink-1.7.2 linux4:/opt/lagou/servers/
- 给每台机器配置环境变量
vim /etc/profile
export FLINK_HOME=/opt/lagou/servers/flink-1.7.2
export PATH=$PATH:$FLINK_HOME/bin
配置完成后使配置文件生效
source /etc/profile
- 进入 bin 目录,启动集群
./start-cluster.sh

启动完后我们可以输入网址http://linux2:8081/,验证
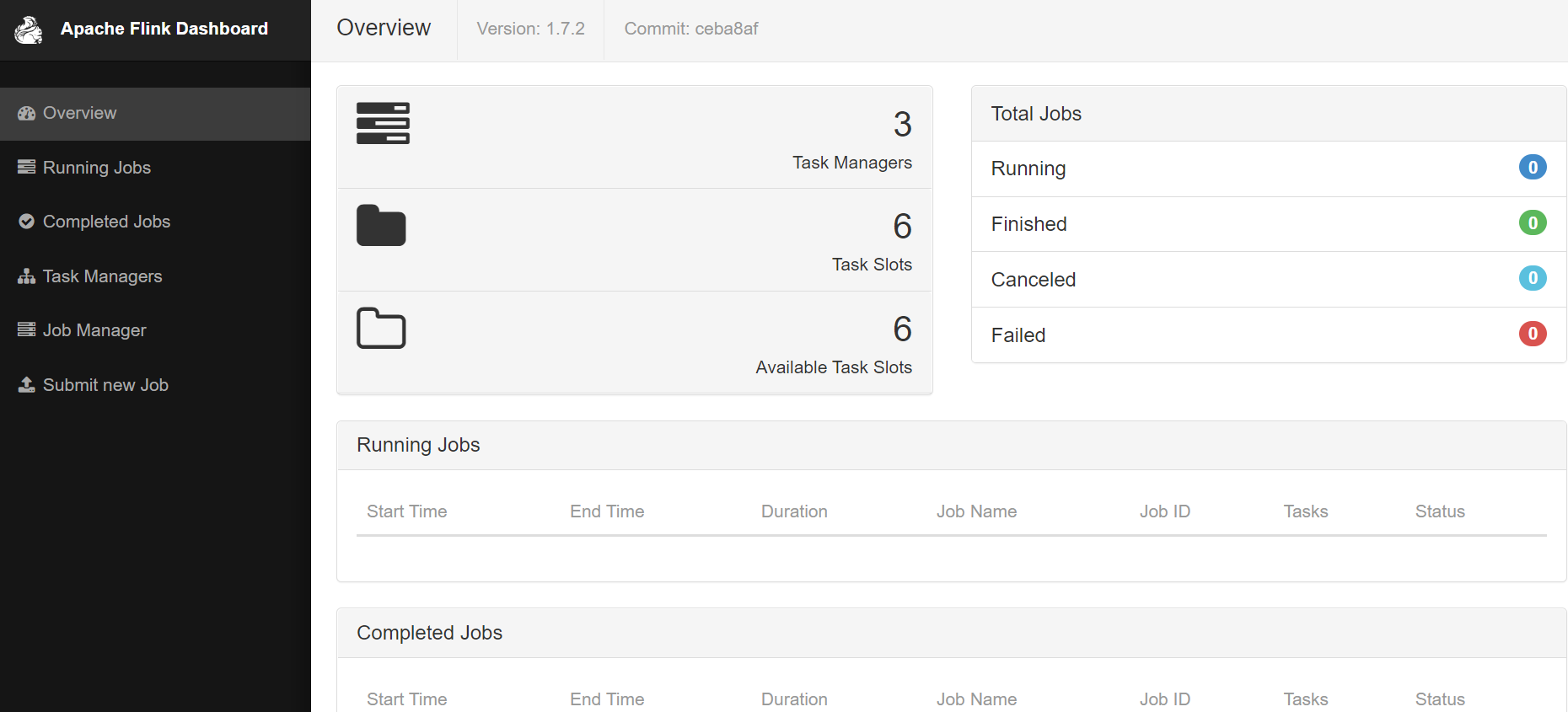
至此,安装完毕。
然后我们将程序放入集群环境测试。首先需要先打 jar 包,需要注意将依赖也打进去,打包插件如下:
<build>
<plugins>
<!-- 打jar插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>

Yarn 模式集群部署
- 配置 yarn-site.xml 文件,增加如下配置:
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>linux2:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>linux2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>linux2:8031</value>
</property>
- 启动 hdfs
start-dfs.sh
- 启动 yarn
start-yarn.sh
- 进入到 flink 的 bin 目录
# -n 2代表2个task manager,tm 800代表内存800m,-s 1代表一个slots,-d代表后台运行
yarn-session.sh -n 2 -tm 800 -s 1 -d
- 在 yarn 上提交 flink 作业
./flink run -c com.mmc.flink.WordCountStream /export/servers/flink/examples/batch/WordCount.jar
# -m jobmanager的地址
# -yn 表示TaskManager的个数
./flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 /export/servers/flink/examples/batch/WordCount.jar
# 找到yarn任务的id,通过命令杀掉
yarn application -kill application_1527077715040_0003
__EOF__
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK