

The Architecture of Google BigQuery and it's Features -
source link: https://www.analyticsvidhya.com/blog/2022/10/the-architecture-of-google-bigquery-and-its-features/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
This article was published as a part of the Data Science Blogathon.
Introduction
The Dotcom boom spawned several web-based companies such as Google, Amazon, Facebook, Twitter, YouTube, and many others. Data generation for web-based companies is significantly greater than for traditional 500 businesses. Every user click, every search performed, every social media post, and every Like button is generated by billions of rows of data every day.

Google BigQuery
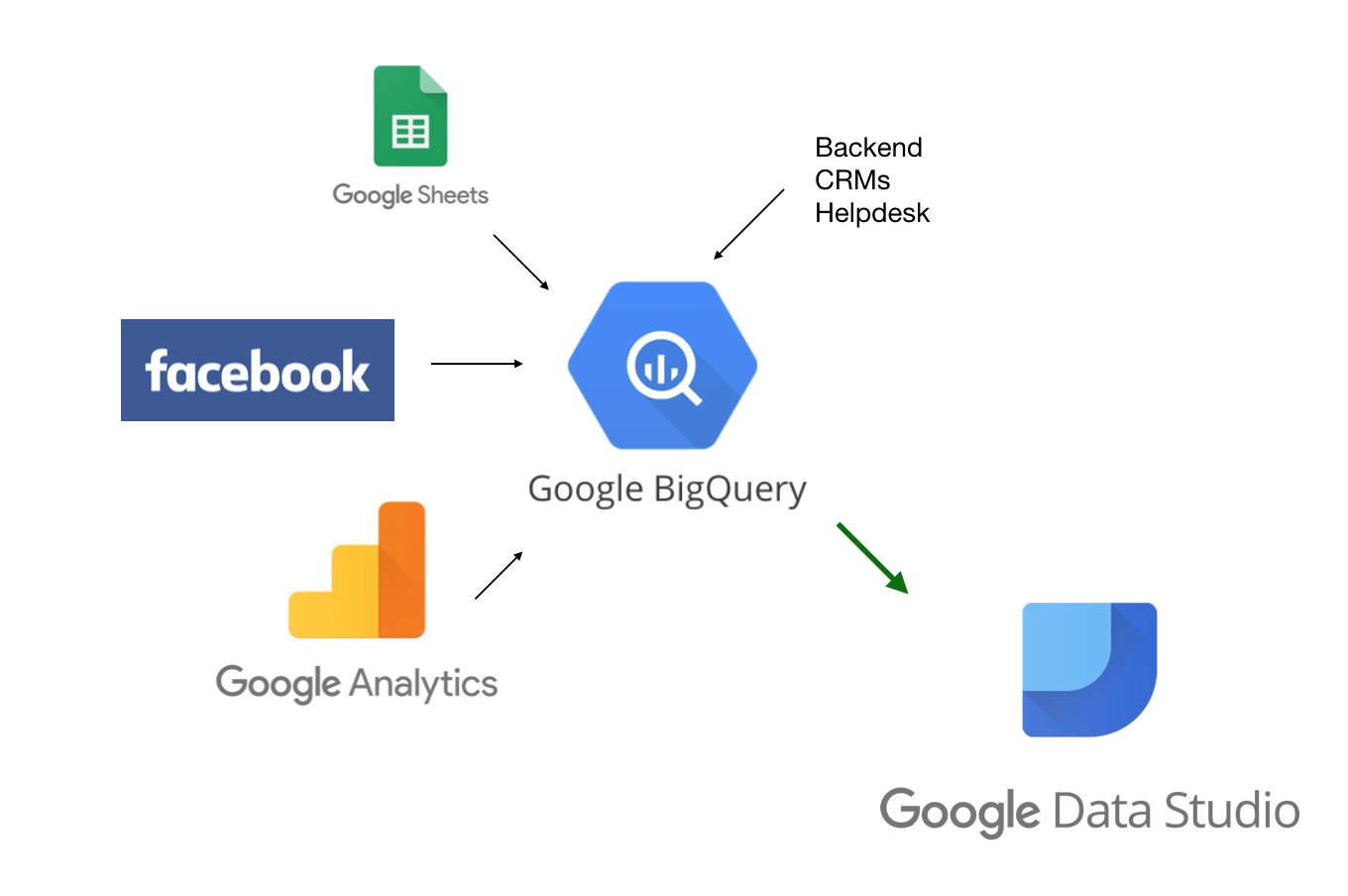
Source: cloud.google.com
It is also the core technology that powers the functionality of many Google services, such as Gmail and Youtube, and is also widely used by thousands of users at Google. It relies on a cluster of computing resources to perform parallel tasks on a massive scale. Based on the incoming request, Dremel dynamically identifies the number of computing resources needed to fulfill the request, pulls those computing resources from the pool of available computing resources, and processes the request. This extensive pooling of computations takes place under the hood, and the operation is fully transparent to the user entering the query. From the user’s point of view, they enter a query and get results at a predictable time every time.
Colossus: Colossus is a distributed file system by Google for many of its products. In each Google data center, Google runs a cluster of storage disks that offer storage capacity for its various services. By selecting appropriate replication and disaster recovery strategies, Colossus ensures that data stored on disks is not lost.
Jupiter Network: The Jupiter Network is the bridge between the Dremel execution machine and the Colossus storage. The network in Google’s data centers offers unprecedented levels of two-way traffic, allowing large volumes of data to move between Dremel and Colossus.

Source: cloud.google.com
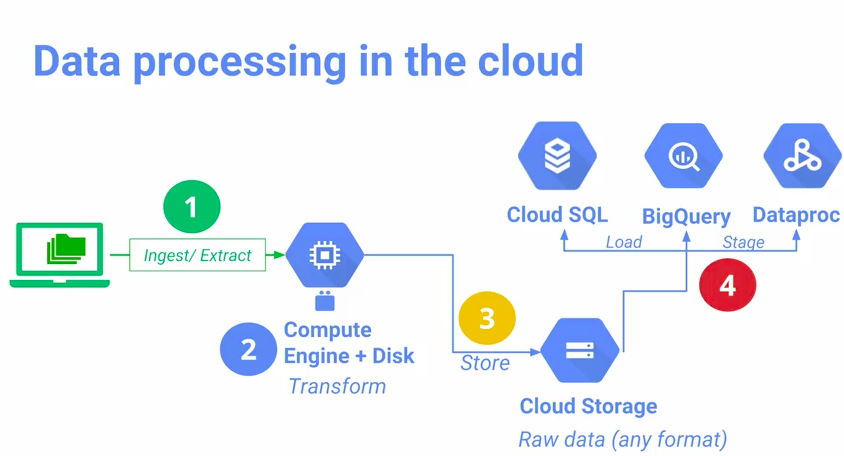
Source: cloud.google.com
Pricing
BigQuery offers flat pricing with an on-demand pricing model. Pricing model decisions can be made based on traffic volume. Due to the segregation between storage and computing, customers with infrequent query requirements, such as a mid-sized company or department, can benefit significantly from the infrequent use of computing resources. It only applies to resources used to process queries. Larger customers can pay for dedicated resources. On-demand polling does not offer the same predictability as the flat rate model, but it still makes sense for many use cases. Click here for a more detailed article on this topic.
Security
Google BigQuery supports several different authentication models. Models based on OAuth and service accounts enable granting access to Google BigQuery resources. Users, groups, or service accounts can be granted access to Google BigQuery resources at different levels. The granularity of access control is limited to the dataset level, and any tables or views below the dataset automatically inherit permissions from the dataset. New data loss prevention features extend BigQuery’s security capabilities by allowing Google BigQuery users to redact, create, and discover sensitive data.
Usability
Google BigQuery offers access patterns expected from a data warehouse. It supports CLI, SDK, ODBC, JDBC, REST API, and Google BigQuery Console, where users can log in and run queries. All of these access patterns invoke the REST API under the covers and return the requested data to the user. Commonly used GUI tools such as DataGrip can be used to connect to the Google BigQuery data warehouse and explore data in Google BigQuery.
Conclusion
- Google search queries take a few seconds to return results; Google’s entire search-based revenue model would be at risk, as users are generally unwilling to wait long to see the results of their actions.
- BigQuery allows users to retrieve data in various formats, such as AVRO, JSON, CSV, and more. The conversion mechanism converts the data loaded into BigQuery into a columnar, internal storage-based representation.
- Google BigQuery supports several different authentication models. Models based on OAuth and service accounts enable granting access to Google BigQuery resources.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Related
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK