

FLINK 基于1.15.2的Java开发-自定义Redis Sink用于连接 Redis Sentinel模式
source link: https://blog.csdn.net/lifetragedy/article/details/127164084
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


 已于 2022-10-14 13:37:52 修改
已于 2022-10-14 13:37:52 修改
 483
483
我们生产用的Redis一般都为sentinel或者为cluster模式。因此如果只是简单的在代码里用flink自带的redis sink,它根本不能用在我们的生产环境。
同时,flink自带的jedis连接源码来看:
它根本没有实现很重要的生产级别使用的:
- 空闲连接检测;
- 空闲连接回收;
- tcp keep alive;
这些高级特性。
同时我们通过上一篇:FLINK 基于1.15.2的Java开发-读文件并把内容 sink到redis_TGITCIC的博客-CSDN博客中得知,flink使用自带redis sink是如下用法:

如果此时我们的需求为:
- 每次先删除原有redis内的key
- 再插入新的timewindows中的内容
亦或者进一步:我们要在redis内生成一个score的数据结构呢?
只有满足了这些需求,我们的代码才具备上生产的条件。这就是为什么因此我们需要自定义自己的Sink组件,然后我们才可以用于实现:
- 连接生产用的redis sentinel模式;
- 可以自定义自己的redis业务逻辑;
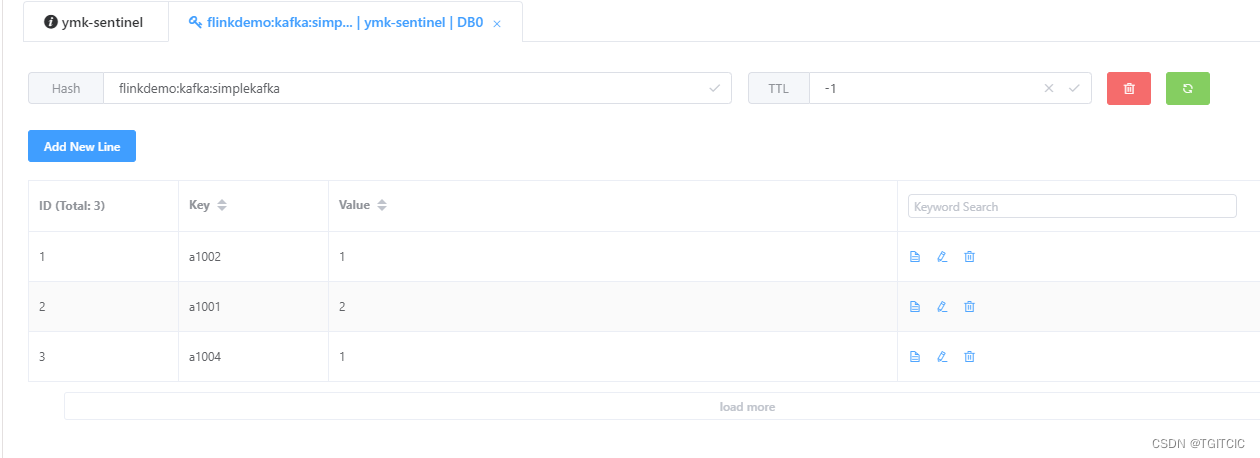
每一个商品被卖出去一条就以以下格式通过kafka发送过来,只对status=101的productId进行统计:
假设每过60s有上述内容被发送过来,那么flink应该会形成以下这样的一个排行榜在Redis内并且随着kafka传送过来的数据变化面实时变化着这个排行榜:
- 需要使用log4j2;
- 各种中间件连接信息全部位于外置的config.properties文件内;
- 使用jedis connection pool连接redis sentinel,同时考虑到团队开发便利性而每个开发们本机的开发环境不可能人人有搭建redis sentinel。那么配置里指定sentinel连接模式,如果该连接为sentinel模式就自动使用sentinel模式;如果配置里指定的是standalone模式那么这个连接可以自动使用standalone模式去做连接,用以“自适应”不同环境;
- kafka数据源推送过来为json格式;
- 每次在redis内生成排行榜时必须清空之前己有排行榜以保持每次在redis内的排行榜为最新内容;
此处,我以架构常用的技术分析手段来分解这个需求。
化大为小、化小为零的技术分析手段
这个需求看似很复杂,并且实际你只有把上述的业务需求、技术需求都实现了,我们才可以说flink你算是入门了、可以开发生产需求了而不只是会一个WordCount就说自己入门了,世界上哪有这么简单的事!
但实际我们也看到了,在之前我们经历过多达10多天的层层学习才能到达这一步。因此需要到达这一步我们需要把整个技术点折成若干可以推进的小步骤,而不要急着眉毛胡子一把抓。
从之前若干天到今日我们已经具备了以下技能:
- flink是什么、可以干什么;
- flink的架构中的定位;
- kafka单机、集群的搭建;
- flink连接kafka;
- flink sink到redis;
- flink读取外部配置文件;
- flink内使用log4j;
- flink的滑动窗口的使用;
- flink中的反序列化使用技巧;
AS-IS 和 TO-BE分析方法论
我们把我们手上到今天为止已经具备的东西全部列出,再来对比这个例子所需要的技术,我们为此制作了两个线轴。
一个线轴叫AS-IS、一个线轴叫TO-BE。这是TOGAF企业架构中常用的一种设计手法。
- AS-IS:现在的情况;
- TO-BE:要到达到的目标的情况;
根据图文的大小,我们一般会把AS-IS和TO-BE放置于一张PPT里要么左右开、要么上下开。然后分别用两种颜色加以区分AS-IS和TO-BE。
这样在视觉上给人以强烈的“冲击”,让人一看给人予一种。。。“哦。。。原来区别在于这些、这些、那些点”的感觉。
这是因为我们的大脑不可能一步到达理性、逻辑思维的地步的,往往理性思维一定是基于人们的感性认识上。那么在架构、技术上的感性认识就是:眼睛。
这就是AS-IS和TO-BE分析手法的作用。它经常会运用在我们用以说服业务型领导或者自我梳理思路时用的一种方法论。

自顶向下的分析、自下向上的知识积累
有了上述的TO-BE和AS-IS分析后,我们知道我们现在要到达我们的目标还缺少哪个环节了。然后我们使用“需求分析自顶向下”而要达到这个需求所要经历的知识积累是一个“自下而上”的过程。
我们看TO-BE这个图,我们按照:最左边的对应于知识积累过程的“最下”面、最右边的对应于知识积累过程的“最上面”。
然后我们可以发觉,越靠近左边(下面)的知识点越接近于我们现在手上所具备的能力。因此我们学习知识必须要:横向上拆分知识点而在纵向上找最接近于你当前能力水平的那个知识点,只有这样才不会“眉毛胡子一把抓”或者是“东西做出来了但是大量复制网上别人的代码但是到了自己的实际生产环境运行一段时间后不是这边有问题就是那边有问题”。
我们需要的是一步一个脚印踏实的奔向我们的目标。这就是对技术人员的要求即:知其然更要知其所以然。
Flink中自定义Redis Sink
回到我们的原文,现在我们就把Flink里如何自定义Redis Sink给搞定
public class MyRedisSink extends RichSinkFunction<Tuple2<String, Integer>> 这个类因为是extends的RichSinkFunction。在此我们需要额外“覆盖”三个方法,它们分别是:
- public void open(Configuration config) {},这个方法 会在flink一开始启动时被执行一次;
- public void invoke(Tuple2<String, Integer> value, Context context) throws Exception {},这个方法会在每一次flink内调用sink输出时被调用一次;
- public void close() throws Exception {},这个方法会在flink以提交方式提交到flink集群内运行时的“stop”,或者是“容器”、“进程”被销毁时执行一次;
解决了这个问题后后面一步就更好办了,即:连接redis sentinel。
在自定义Redis Sink中连接Redis Sentinel
此处我们需要
- 在open()方法中使用jedis connection pool来建立redis sentinel方式,然后设定一个全局的Jedis对象;
- 在每次invoke()方法中执行我们自定义的先清redis再写redis的业务逻辑,这个方法中不要忘记放置一个finally块以用于每次使用完了当前连接把它close掉以避免造成工程项目资源泄漏。
- 在close()方法中对jedis connection pool进行“销毁”;
来看jedis connection pool的使用
自定义的jedis connection pool
以下这个connection pool会通过config.properties中的以下这2行的注释或者是放开来决定当前走的是redis单实例(standalone)模式还是哨兵(sentinel)模式。
它是这么工作的。
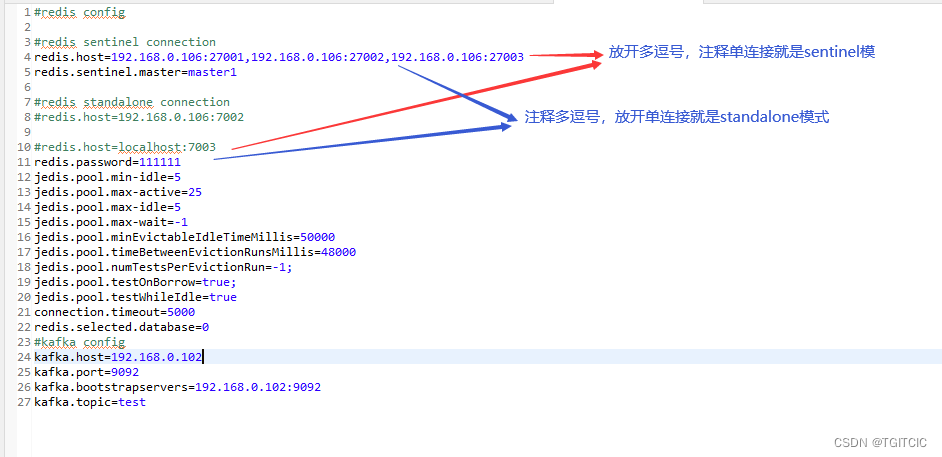
自定义的JedisConfig.java
如何在自定义的redis sink中使用JedisConfig
全代码展示
至此,我们已经补全了所有的需要到达我们的最终目标所需要的“链路节点了”。因此我一次性放出全代码
pom.xml
flink运行用主类ProductJsonTypeStatistics.java
kafka传输后反序化的类ProductBean.java
JedisConfig.java
MyRedisSink.java
config.properties
log4j2.xml
然后我们使用kafka自带的producer来send几条message
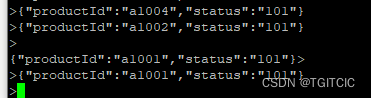
然后我们看我们的redis内的数据如下 ,这个实时排行榜就这样生成完了。
附、使用jedis connection pool中重要的几个参数的说明
很多人在使用了jedis connection pool后会发生要么一开始读写redis时就发生unexpected end of stream或者时不时抛一个unexpected end of stream的问题。
这个问题其实是源于jedis的源码。
有以下几个核心参数很重要:
我们对照一下我们在redis服务端设置的参数

主要看以下这三个参数:
- timeout 60
- tcp-keepalive 30
- connection.timeout=5000
对照着我们的config.properties文件中的:
- jedis.pool.minEvictableIdleTimeMillis=50000
- jedis.pool.timeBetweenEvictionRunsMillis=48000
- connection.timeout=5000
我们可以发觉,在jedis connection pool设置时,必须把这3个值设成如下关系:
- minEvictableIdleTimeMillis< redis里的timeout;
- timeBetweenEvictionRunsMillis必须<minEvictableIdleTimeMillis<redis里的timeout;
- timeout必须<redis里的tcp-keepalive
并且必须设上3个检查项
- jedis.pool.numTestsPerEvictionRun=-1, 对所有的连接进行是否可用进行检查;
- jedis.pool.testOnBorrow=true,这个值不设上面那3个jedis里的超时设计不起作用;
- jedis.pool.testWhileIdle=true,这个值叫启用空闲检查,这个不启用上述jedis里所有的超时设置是不启作用的;
同时在config.properties文件内以下三个参数需要大家高度引起重视:
此处的min-idle参数必须和max-idle参数完全一致。否则也会出现,当jedis客户端得到一个jedis后,而这个jedis被client端已经标记成了“回收“也会导致unexpected stream这个错误。
把这些对照着你的redis server端的配置全设好了,这样你的jedis connection配置才能真正贴合着你的redis服务端起到:
- 保证每次应用拿到的连接是可用的;
- 及时回收空闲连接
否则,就会发生应用在读写redis时不时抛一个:Unexpected end of stream异常。抛这个异常恰恰是因为应用在获得一个jedis连接并在准备使用jedis对象往redis里写东西时,这个jedis连接恰恰被jedis connection pool给回收了。而实际这根连接在redis服务端却还活着。
知其然,更要知其所以然!
恭喜你,至此你可以进入flink的实际需求开发了!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK