

Significant Garbage Collection Improvement For Emacs
source link: https://tdodge.consulting/blog/living-the-emacs-garbage-collection-dream
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

October 21, 2022
Significant Garbage Collection Improvement For Emacs
Reducing Wall Clock Latency For sweep_conses By 50%.
This commit reduces the total wall clock duration forsweep consesexecution by approximately 50%. It does so by reducing branch mispredictions from dereferencing storage blocks while sweeping the cons blocks. Parsing the output from some subprocesses such as LSP servers creates huge amounts of conses, so this commit is significant for increasing the responsiveness for modes such as eglot orcompany-mode.
Caveats
I have only tested this on Mac OS on a processor with a 256 KB L2 cache. I am uncertain if the behavior is the same on other operating systems. There also may be constraints of which I'm unaware that make this not backwards compatible with other setups.
The Commit
This commitchanges BLOCK ALIGNfrom 1 << 10 to 1 << 15.
Testing Procedure
I ran the following program that creates a long chain of conses, and then nils them out to ensure that they get collected in the next call to garbage-collect. The total was arbitrarily picked. The experiment is repeatable, but the results are prone to noise. The effect is large enough to be visible even with these inconsistencies.
(defun test-garbage-collect-large-cons-allocation ()
(garbage-collect)
(setq long-chain (cl-loop for i from 0 below
105910837 collect i))
(garbage-collect)
(redisplay)
(message "%S" (garbage-collect))
(setq gc-cons-threshold most-positive-fixnum)
(let ((head long-chain))
(while head
(let ((tail (cdr head)))
(setcdr head nil)
(setcar head nil)
(setq head tail))))
(setq long-chain nil)
(sleep-for 10)
(let ((start-time (time-to-seconds (current-time))))
(message "Start Garbage Collection")
(setq gc-cons-threshold (car (get 'gc-cons-threshold 'standard-value)))
(message "%S" (garbage-collect))
(let ((duration (- (time-to-seconds (current-time)) start-time)))
(prog1 duration (message "Garbage Collection: %f" duration)))))
Observed Results
The above graph shows that latency decreases whenBLOCK ALIGNincreases. It stops at 1 << 15 because my instance of emacs crashes on startup at that value.
Why Does This Work?
Insweep conses, emacs traverses the cblock linked list. With the current value forBLOCK ALIGN, each block contains less than 1024 conses. Since there are no guarantees of cache locality between blocks, each dereference is a branch misprediction. By increasing the size of these blocks, the total amount of work is decreased from having less total blocks, because there are less branch mispredictions total.
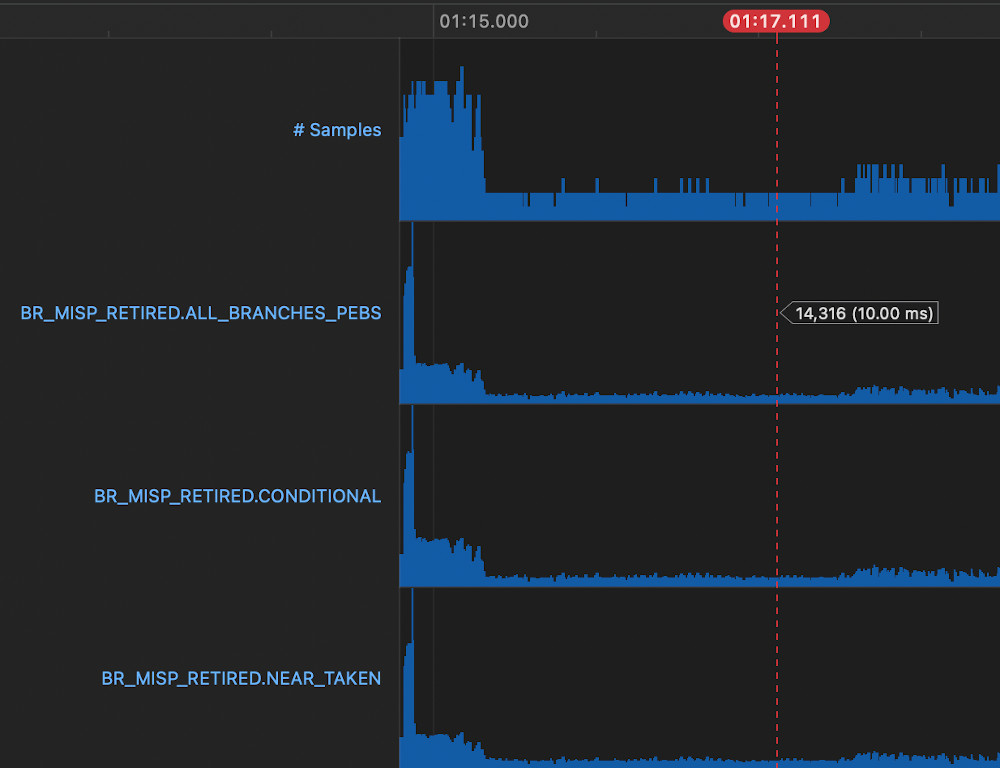
Branch Mispredictions withBLOCK ALIGNat 1 << 10
Picking a representative sample from a run without the change using Instruments.app's performance counter view shows 14316 branch mispredictions sampled.
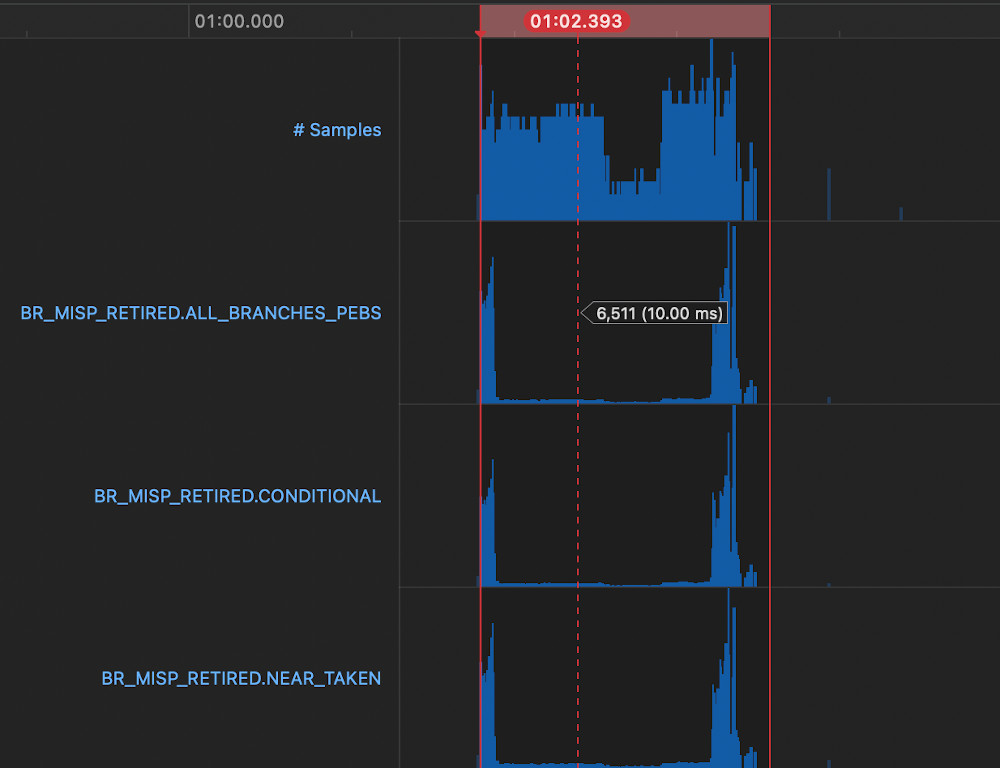
Branch Mispredictions withBLOCK ALIGNat 1 << 15
Whereas with the change picking a representative sample shows 6511 branch mispredictions sampled, which roughly correlates with the difference in latency from the change.
How Was This Found?
I had been profiling emacs using Instruments awhile ago and had observed that the majority of garbage collection time in my use cases tended to be insweep conses. I increasedBLOCK ALIGNin response to that because 1024 is a pretty small number for processors nowadays, and observed that my garbage collection time perceptibly decreased. I had suspected that it could be caused by branch mispredictions from iterating the cons block linked list, but I was not confident in that assertion without direct evidence.
Recently, I learned that CPU Performance Counters are available in Instruments without having to recompile emacs with additional flags and that one of the counters counted branch mispredictions. With that newly acquired knowledge, I decided to run this experiment to confirm that conjecture.
Future Work
- Identify why 1 << 15 is the current limit.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK