

测试覆盖率治不好你的精神内耗 - hh54188
source link: https://www.cnblogs.com/hh54188/p/16820159.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

“Talk is cheap, show me the code”
在测试覆盖率的讨论里我越来越疑惑了。
有人聊起来如数家珍,仿佛它是代码质量的防腐剂,有了它在流水线上把关我们便能无忧无虑地做起甩手掌柜。说实话当他们在争论阈值究竟应该设为60%,70% 亦或是 99%时,我搞不清这些数值背后带来的影响有多大差异。因为我从来没有带目的去尝试达成某个数值,也不知道在达成这些目标之后,会带来何种效应。
在我看来检验他们振振有词是否成立的不二方法,就是亲身体验一回冲刺测试覆盖率的过程,当中经历的付出和收获是最公允的评价。
然而覆盖率目标应该是什么?如果我们都同意测试覆盖率带来的正面效应与数值成正相关的话,那100% 绝对具有说服力。可以想象当达到 100% 时,测试覆盖率在发挥出所有功效的同时弊端也暴露无遗。反过来说,如果 100%测试覆盖率的影响力依然不尽如人意,那么它就是存在缺陷的。
在前段开始思考这个问题时我刚好有一个前端side project 正在进行中,它便是我实践这个想法的最好对象。在写这篇文章的当下它已经上线,并且源码在此。整个项目源代码共计3952行代码,你可以从这个项目它的每一次执行的GitHub Action 里 Run unit tests 环节中看到,它的测试覆盖率从分支到行数都是 100%。
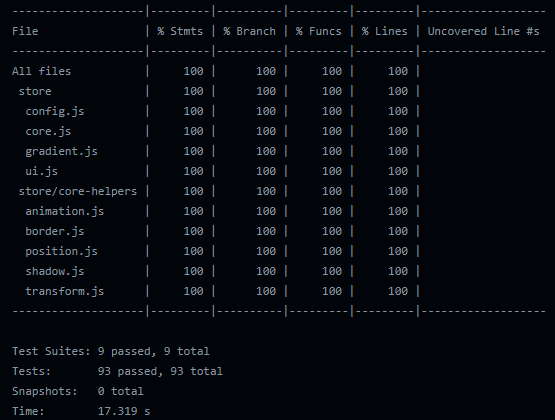
以下记录的文字便是在冲刺测试覆盖率 100%过程中我的感受与发现的问题。我的结论是:我不反对统计测试覆盖率,我反对的是把覆盖率视为不可逾越的教条,以至于让程序员也沦落为二等公民。
覆盖率的原罪
测试都是有条件的,其中最重要的前提便是测试范围,所以测试覆盖率同样有欺骗性。在我们讨论它之前最好问一问自己,我所说的测试究竟处于测试金字塔的哪一层?
以刚刚提到的项目为例,参展整洁架构整体上我把它划分成View(前端组件,React 实现)和 Model(业务逻辑,Zustand 实现)两层,依赖关系上组件只单向依赖业务逻辑 。在编码前端组件时,我有意将它设计为无(业务)状态组件。这样一来表现层便独立于业务层,无论将来打算迁往 Vue 还是 Angular,核心业务逻辑都不用发生变化。
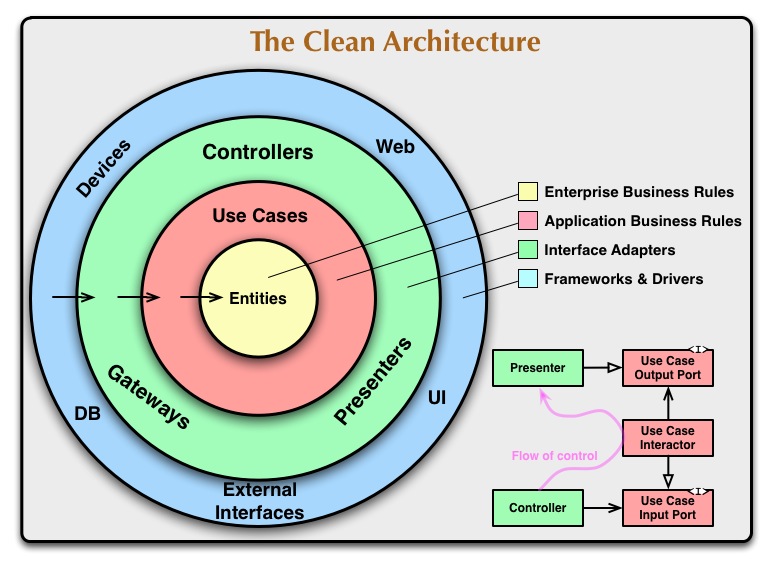
而我所说的100%,其实只覆盖了所有的业务逻辑代码,考虑到我们还可以单独对前端组件进行单元测试,现阶段编写的测试充其量属于单元测试的一个子集。之所以不继续进行组件测试或者将业务逻辑与组件结合起来做功能测试,众所周知这是由成本决定的。当我们越企图向测试金字塔的顶端(端到端测试)移动,测试成本就会越高,在实际工作中我们必须舍弃对部分代码的测试,这便是原罪。
所以当我们讨论 100%时,从测试的广义上看,它可能连 50% 的代码覆盖率都还不一定达到。
原罪不应该得到谴责,因为它是一类必要的恶(necessary evil)。但我们依然有办法将这份恶的伤害减少到最低,这需要回归到对于测试策略的优化上。对于类似的项目来说,把资源全部投入到对于业务逻辑的验证上其实是最优解,一方面因为相比交互上可能出现的问题,业务逻辑的风险更难以被察觉,也更与收益息息相关;另一方面对于交付复杂的应用,穷举所有测试的可能性是不现实的。需要注意的是测试策略的制定不是在完成实现之后的一种补救,而是在整个项目开始前就要纳入规划中。可以想象如果我们在设计整个应用之初就决定不采用第三方状态管理工具,而是直接用利用组件状态去存储业务逻辑,这种测试策略几乎无法实施。
谁为覆盖率买单
如果你追逐的是漂亮数字,恭喜你最终一定会如愿以偿,但可能这个数字早已百孔千疮。不妨看项目里的下面这一条语句:。
state.elementCollection[targetId].border[position][name]= value;
这条语句的本意是从一堆DOM 元素集合(elementCollection)中,修改指定元素(targetId)的特定位置(position)上的边框属性(name)
为了满足行覆盖率,我们必须要让测试代码执行到这一行。「执行到这一行」其实非常容易做到,比如我们把变量填充之后即可:
state.elementCollection["guid"].border["shadow"]["color"] ="Lee";
但这样的执行结果是完全没有意义的,DOM元素的边框样式里根本不存在 shadow 属性,即使存在,你把“Lee”赋值给 color属性也是完全说不通。除此之外对于元素、边框是否存在的可空判断也是很明显的代码缺陷。但测试覆盖率并不关心执行的「意义」和「结果」,它认定「路过」即可。
覆盖率潜在的好处是,理想情况下,当开发人员通过覆盖率发现这行代码被遗漏之后,他应该意识到这行代码是有风险的,需要被及时修正。但开发者同时发现自己面临一个窘境:如果我要修补这个漏洞,就要补充实现代码,新代码又降低了当前的测试覆盖率,为了覆盖率我要继续写更多的测试。
你觉得他愿意按照我们期望的情节去付出吗?
很简单这取决于我们有没有给到他足够的空间。我们追求覆盖率的本质是追求好的产品质量,但你要意识到质量是昂贵的,如果你只是想要覆盖率却把成本给开发者自己承担,大家都不傻,那么你得到也只是数字罢了。
测试表面上是面向过去的:我要验证我之前写的代码;但测试的本质上却是面向未来的:我要怎么把它做得更好;测试覆盖率很容易让人迷失在过去之中。
在项目里有一类代码几乎是毫无技术含量的模板代码,比如我们可以看与这份有关 store 的实现,这个文件里的代码几乎都遵循同一种模式:
export constuseUIStore = create(persist((set) => ({
property: false,
setPropertyValue: (value) => set({property: value }),
})
这种模式在整个文件中被重复了11次,同样如果你去看它所对应的测试文件,它也遵循了某种被重复了11次的测试模式。
抛开这类代码的严谨不说(比如没有对值进行校验),假设有一天我们的实现代码真只有这么简单,我们还有没有必要对其做测试?
我的意见是,如果是出于守护目的进行黑盒测试我赞同(但话说回来用如果要守护做端到端不是应该更好),但是为了满足测试覆盖率没有必要,因为一眼可以看出来这些实现代码毫无风险或者说尽是风险,无论哪种情况追求覆盖率起不到任何效果。
编写这类“低收益”代码让我担心的另一点是,在实际项目中它们所占用的比例会不会过于可观,而我们又难以保证时间投入带来的收益——当我们成倍时间投入了完善的时间之后,我们的 bug数量是否也能得到成倍地减少呢?
以 animation.js 这个脚本为例,在我补全测试的过程中,当我把主线补充完毕之后,我发现剩下的全部都是类似于 if (!value)return之类的语句。但说实话在我看来争取这类代码行的覆盖是没有意义的,因为对于这些边界情况我认为大部分时候 return并不是最好的处理方式,这些测试并不能发现问题,同时也无益于我考虑这个问题。
别被我绕晕了,让我们回归到最简单的逻辑上来:一个拥有30%测试覆盖率的项目当然要比 0%测试覆盖率的项目优秀,但它是否等同于产品层面的优秀以及它能否传达到用户的感知上我表示怀疑。数字是一个很好的指标,它会告诉我们剩下 70%代码可能存在风险,它的急剧波动应该引起我们的警觉,但它不应该成为指导人写代码的标杆。
测试或者 QA不应该是被全组人都寄予希望的质量保险——哪怕在设计产品之初,如果它能更像是拥有按钮的计算器而不是任意拖拽的 Photoshop,它的质量都会更有保证。
你可能会喜欢
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK