

通过tc镜像流量到loopback接口
source link: http://just4coding.com/2022/10/22/tc-lo/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

通过tc镜像流量到loopback接口
2022-10-22 Kernel
近期业务需要通过tc将某些网卡流量通过隧道镜像到其他IP进行分析。实现思路参考这篇文章:
理想情况上,采集网卡和隧道承载网卡应该是不同网卡。然而,一些服务器不具备多块网卡。当它们使用同一网卡时很容易形成环路,如下图(来自上述文章):
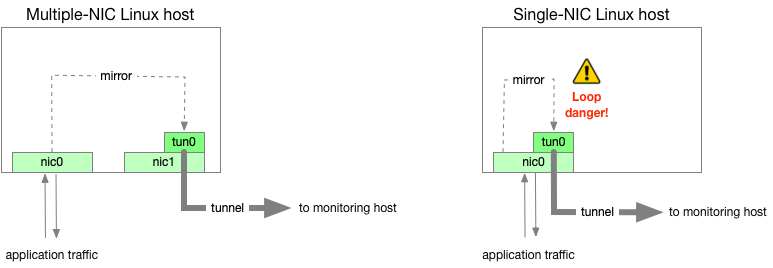
上述文章也提到Linux内核存在BUG,当直接从egress队列镜像到隧道接口时,可能会导致死锁。比如RedHat这个kb链接:
解决方案是可以先将流量镜像到loopback接口, 再从loopback接口镜像到隧道接口。这种方式下,我们可以在lo接口上添加bpf规则避免形成环路,也可以按需求添加bpf规则过滤不需要的流量。
但实际上这样依然存在风险。根据tc官方说明,这么做还是不推荐的:
What NOT to do if you don't want your machine to crash:
------------------------------------------------------
Do not create loops!
Loops are not hard to create in the egress qdiscs.
Here are simple rules to follow if you don't want to get
hurt:
A) Do not have the same packet go to same netdevice twice
in a single graph of policies. Your machine will just hang!
This is design intent _not a bug_ to teach you some lessons.
In the future if there are easy ways to do this in the kernel
without affecting other packets not interested in this feature
I will add them. At the moment that is not clear.
Some examples of bad things NOT to do:
1) redirecting eth0 to eth0
2) eth0->eth1-> eth0
3) eth0->lo-> eth1-> eth0
我们场景的转发路径就是:eth0->lo->vxlan->eth0。根据我们较长时间的实践,确认这样的确会触发BUG。经过研究,我们可以实现额外的loopback接口设备来规避BUG。后续其他文章再来说明该BUG及解决方案,本文来分析镜像流量是否会影响netfilter。
因为我们的服务器上还运行着自开发的netfilter内核模块,那么流量镜像到lo接口后,流量会经过NF_HOOK吗?
为了确定这个问题,开始进行实验调研。
实验机器网卡eth1的IP为:192.168.33.12,在eth1上配置镜像egress方向的TCP端口为9091的流量到lo网卡:
tc qdisc add dev eth1 root handle 1: htb
tc filter add dev eth1 parent 1: prio 1 bpf bytecode "20,40 0 0 12,21 0 6 34525,48 0 0 20,21 0 15 6,40 0 0 54,21 12 0 9091,40 0 0 56,21 10 11 9091,21 0 10 2048,48 0 0 23,21 0 8 6,40 0 0 20,69 6 0 8191,177 0 0 14,72 0 0 14,21 2 0 9091,72 0 0 16,21 0 1 9091,6 0 0 65535,6 0 0 0" flowid 1: action mirred egress mirror dev lo
命令中的bpf字节码可以通过iptables的工具nfbpf_compile来生成:
[root@default bin]# ./nfbpf_compile EN10MB 'tcp port 9091'
20,40 0 0 12,21 0 6 34525,48 0 0 20,21 0 15 6,40 0 0 54,21 12 0 9091,40 0 0 56,21 10 11 9091,21 0 10 2048,48 0 0 23,21 0 8 6,40 0 0 20,69 6 0 8191,177 0 0 14,72 0 0 14,21 2 0 9091,72 0 0 16,21 0 1 9091,6 0 0 65535,6 0 0 0
然后编写实验用的netfilter模块, 它在收到9091端口的数据包时打印设备名称:
#define pr_fmt(fmt) "[%s]: " fmt, KBUILD_MODNAME
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/skbuff.h>
#include <linux/ip.h>
#include <linux/netfilter.h>
#include <linux/netfilter_ipv4.h>
#include <net/tcp.h>
static unsigned int nf_hook_in(const struct nf_hook_ops *ops,
struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
const struct nf_hook_state *state)
{
struct tcphdr *tcph = NULL;
struct iphdr *iph = ip_hdr(skb);
u8 proto = iph->protocol;
if (proto != IPPROTO_TCP) {
return NF_ACCEPT;
}
tcph = (struct tcphdr *) skb_transport_header(skb);
if (htons(tcph->dest) == 9091 || htons(tcph->source == 9091)) {
pr_info("DEV: %s", skb->dev ? skb->dev->name : "(no dev)");
pr_info("[in]: %d->%d\n", htons(tcph->source), htons(tcph->dest));
return NF_ACCEPT;
}
return NF_ACCEPT;
}
static unsigned int nf_hook_out(const struct nf_hook_ops *ops,
struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
const struct nf_hook_state *state)
{
struct tcphdr *tcph = NULL;
struct iphdr *iph = ip_hdr(skb);
u8 proto = iph->protocol;
if (proto != IPPROTO_TCP) {
return NF_ACCEPT;
}
tcph = (struct tcphdr *) skb_transport_header(skb);
if (htons(tcph->source) == 9091 || htons(tcph->dest) == 9091) {
pr_info("DEV: %s", skb->dev ? skb->dev->name : "(no dev)");
pr_info("[out]: %d->%d", htons(tcph->source), htons(tcph->dest));
return NF_ACCEPT;
}
return NF_ACCEPT;
}
static struct nf_hook_ops nfhooks[] = {
{
.hook = nf_hook_in,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_PRE_ROUTING,
.priority = NF_IP_PRI_FIRST,
},
{
.hook = nf_hook_out,
.owner = THIS_MODULE,
.pf = NFPROTO_IPV4,
.hooknum = NF_INET_LOCAL_OUT,
.priority = NF_IP_PRI_FIRST,
},
};
int __init nfqlo_init(void)
{
nf_register_hooks(nfhooks, ARRAY_SIZE(nfhooks));
pr_info("nfqlo module init\n");
return 0;
}
void __exit nfqlo_exit(void)
{
nf_unregister_hooks(nfhooks, ARRAY_SIZE(nfhooks));
pr_info("nfqlo module exit\n");
return;
}
module_init(nfqlo_init);
module_exit(nfqlo_exit);
MODULE_LICENSE("GPL");
MODULE_DESCRIPTION("nfqlo");
MODULE_ALIAS("module netfiler lo checking");
Makefile内容为:
.PHONY: all
obj-m += nfqlo.o
all: kernel
kernel:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clea
编译并加载:
make
insmod ./nfqlo.ko
接着,使用tcpdump在lo接口上抓包,并从该机器上向外访问9091端口来发送TCP syn包:
[root@default ~]# curl http://192.168.33.1:9091 -v
* About to connect() to 192.168.33.1 port 9091 (#0)
* Trying 192.168.33.1...
* Connection refused
* Failed connect to 192.168.33.1:9091; Connection refused
* Closing connection 0
curl: (7) Failed connect to 192.168.33.1:9091; Connection refused
这时lo接口上tcpdump的输出:
[root@default nfqlo]# tcpdump -ilo -nn tcp port 9091
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lo, link-type EN10MB (Ethernet), capture size 262144 bytes
14:38:18.133405 IP 192.168.33.12.52980 > 192.168.33.1.9091: Flags [S], seq 3925822672, win 29200, options [mss 1460,sackOK,TS val 4294940602 ecr 0,nop,wscale 7], length 0
运行dmesg查看内核模块的输出:
[ 273.621144] [nfqlo]: DEV: (no dev)
[ 273.621250] [nfqlo]: [out]: 52980->9091
可以看到,tcpdump在lo上抓到了数据包,而从dmesg输出看到,数据包并未进入netfilter处理。
那么数据包在哪里被丢弃的呢?我们继续分析。
IP协议栈入口函数为ip_rcv, 在执行完NF_HOOK之后会调用ip_rcv_finish,ip_rcv源码(CentOS的linux-3.10.0-1127.el7.x86_64)如下:
/*
* Main IP Receive routine.
*/
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
const struct iphdr *iph;
u32 len;
/* When the interface is in promisc. mode, drop all the crap
* that it receives, do not try to analyse it.
*/
if (skb->pkt_type == PACKET_OTHERHOST)
goto drop;
IP_UPD_PO_STATS_BH(dev_net(dev), IPSTATS_MIB_IN, skb->len);
if ((skb = skb_share_check(skb, GFP_ATOMIC)) == NULL) {
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INDISCARDS);
goto out;
}
if (!pskb_may_pull(skb, sizeof(struct iphdr)))
goto inhdr_error;
iph = ip_hdr(skb);
/*
* RFC1122: 3.2.1.2 MUST silently discard any IP frame that fails the checksum.
*
* Is the datagram acceptable?
*
* 1. Length at least the size of an ip header
* 2. Version of 4
* 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums]
* 4. Doesn't have a bogus length
*/
if (iph->ihl < 5 || iph->version != 4)
goto inhdr_error;
BUILD_BUG_ON(IPSTATS_MIB_ECT1PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_1);
BUILD_BUG_ON(IPSTATS_MIB_ECT0PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_0);
BUILD_BUG_ON(IPSTATS_MIB_CEPKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_CE);
IP_ADD_STATS_BH(dev_net(dev),
IPSTATS_MIB_NOECTPKTS + (iph->tos & INET_ECN_MASK),
max_t(unsigned short, 1, skb_shinfo(skb)->gso_segs));
if (!pskb_may_pull(skb, iph->ihl*4))
goto inhdr_error;
iph = ip_hdr(skb);
if (unlikely(ip_fast_csum((u8 *)iph, iph->ihl)))
goto csum_error;
len = ntohs(iph->tot_len);
if (skb->len < len) {
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INTRUNCATEDPKTS);
goto drop;
} else if (len < (iph->ihl*4))
goto inhdr_error;
/* Our transport medium may have padded the buffer out. Now we know it
* is IP we can trim to the true length of the frame.
* Note this now means skb->len holds ntohs(iph->tot_len).
*/
if (pskb_trim_rcsum(skb, len)) {
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INDISCARDS);
goto drop;
}
skb->transport_header = skb->network_header + iph->ihl*4;
/* Remove any debris in the socket control block */
memset(IPCB(skb), 0, sizeof(struct inet_skb_parm));
/* Must drop socket now because of tproxy. */
skb_orphan(skb);
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, NULL, skb,
dev, NULL,
ip_rcv_finish);
csum_error:
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_CSUMERRORS);
inhdr_error:
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INHDRERRORS);
drop:
kfree_skb(skb);
out:
return NET_RX_DROP;
}
我们使用systemtap工具来查看两个函数的执行情况。编写systemtap脚本hook两个函数:
probe kernel.function("ip_rcv") {
iphdr = __get_skb_iphdr($skb)
saddr = format_ipaddr(__ip_skb_saddr(iphdr), %{ AF_INET %})
daddr = format_ipaddr(__ip_skb_daddr(iphdr), %{ AF_INET %})
protocol = __ip_skb_proto(iphdr)
tcphdr = __get_skb_tcphdr($skb)
if (protocol == %{ IPPROTO_TCP %}) {
dport = __tcp_skb_dport(tcphdr)
sport = __tcp_skb_sport(tcphdr)
if (dport == 9091) {
printf("ip_rcv: skb: %p, %s:%d->%s:%d, dev: %s\n", $skb, saddr, sport, daddr, dport, kernel_string($skb->dev->name))
}
}
}
probe kernel.function("ip_rcv_finish") {
iphdr = __get_skb_iphdr($skb)
saddr = format_ipaddr(__ip_skb_saddr(iphdr), %{ AF_INET %})
daddr = format_ipaddr(__ip_skb_daddr(iphdr), %{ AF_INET %})
protocol = __ip_skb_proto(iphdr)
tcphdr = __get_skb_tcphdr($skb)
if (protocol == %{ IPPROTO_TCP %}) {
dport = __tcp_skb_dport(tcphdr)
sport = __tcp_skb_sport(tcphdr)
if (dport == 9091) {
printf("ip_rcv_finish: skb: %p, %s:%d->%s:%d, dev: %s\n", $skb, saddr, sport, daddr, dport, kernel_string($skb->dev->name))
}
}
}
运行systemtap并再次发送请求后输出如下:
[root@default systemtap]# stap -g -v 1.stap
......
ip_rcv: skb: 0xffff8d6435fad800, 192.168.33.12:52982->192.168.33.1:9091, dev: lo
可以看到ip_rcv被调用了,而ip_rcv_finish没有被调用,可以确认数据包是在ip_rcv函数中被丢弃了。
从源码分析,ip_rcv函数开头部分的pkt_type检查逻辑是最可疑的地方:
/* When the interface is in promisc. mode, drop all the crap
* that it receives, do not try to analyse it.
*/
if (skb->pkt_type == PACKET_OTHERHOST)
goto drop;
修改systemtap脚本,添加pkt_type输出:
printf("ip_rcv_finish: skb: %p, %s:%d->%s:%d, dev: %s, pkt_type: %d\n", $skb, saddr, sport, daddr, dport, kernel_string($skb->dev->name), $skb->pkt_type)
再次运行并发送请求后,确认skb->pkt_type的确为PACKET_OTHERHOST, 数据包被丢弃:
ip_rcv: skb: 0xffff8d6410ced200, 192.168.33.12:52986->192.168.33.1:9091, dev: lo, pkt_type: 3
#define PACKET_OTHERHOST 3 /* To someone else */
那么skb->pkt_type是哪里赋值为PACKET_OTHERHOST的呢?
梳理tc镜像流量的网络路径,有如下这些观察点:
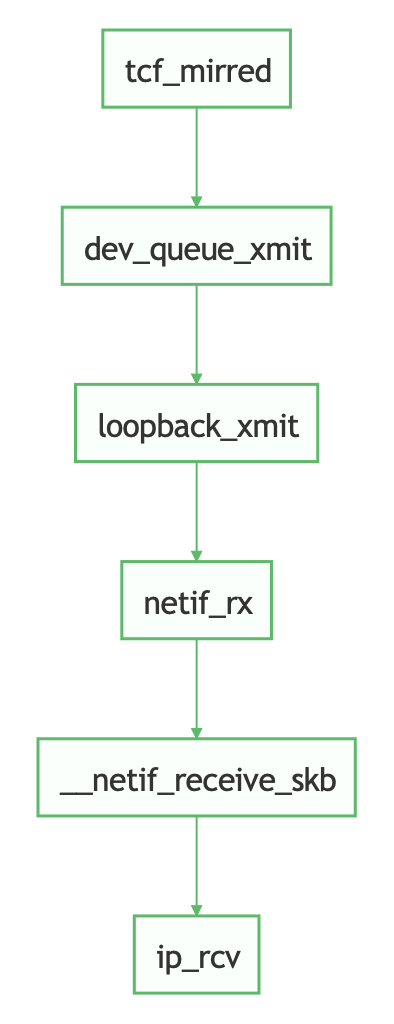
tc镜像流量时会调用tcf_mirred函数- 流量为
egress方向,tcf_mirred会调用dev_queue_xmit dev_queue_xmit最终会调用网卡驱动的.ndo_start_xmit函数,lo网卡的ndo_start_xmit为loopback_xmitloopback_xmit会调用netif_rx函数,最终会调用__netif_receive_skb函数__netif_receive_skb会调用ip_rcv函数
如图所示:
再次修改systemtap脚本:
%{
#include <net/tcp.h>
%}
probe module("act_mirred").function("tcf_mirred") {
iphdr = __get_skb_iphdr($skb)
saddr = format_ipaddr(__ip_skb_saddr(iphdr), %{ AF_INET %})
daddr = format_ipaddr(__ip_skb_daddr(iphdr), %{ AF_INET %})
protocol = __ip_skb_proto(iphdr)
tcphdr = __get_skb_tcphdr($skb)
if (protocol == %{ IPPROTO_TCP %}) {
dport = __tcp_skb_dport(tcphdr)
sport = __tcp_skb_sport(tcphdr)
if (dport == 9091) {
printf("act_mirred: skb: %p, %s:%d->%s:%d, dev: %s, pkt_type: %d\n", $skb, saddr, sport, daddr, dport, kernel_string($skb->dev->name), $skb->pkt_type)
}
}
}
probe kernel.function("dev_queue_xmit") {
iphdr = __get_skb_iphdr($skb)
saddr = format_ipaddr(__ip_skb_saddr(iphdr), %{ AF_INET %})
daddr = format_ipaddr(__ip_skb_daddr(iphdr), %{ AF_INET %})
protocol = __ip_skb_proto(iphdr)
tcphdr = __get_skb_tcphdr($skb)
if (protocol == %{ IPPROTO_TCP %}) {
dport = __tcp_skb_dport(tcphdr)
sport = __tcp_skb_sport(tcphdr)
if (dport == 9091) {
printf("dev_queue_xmit: skb: %p, %s:%d->%s:%d, dev: %s, pkt_type: %d\n", $skb, saddr, sport, daddr, dport, kernel_string($skb->dev->name), $skb->pkt_type)
}
}
}
probe kernel.function("loopback_xmit") {
iphdr = __get_skb_iphdr($skb)
saddr = format_ipaddr(__ip_skb_saddr(iphdr), %{ AF_INET %})
daddr = format_ipaddr(__ip_skb_daddr(iphdr), %{ AF_INET %})
protocol = __ip_skb_proto(iphdr)
tcphdr = __get_skb_tcphdr($skb)
if (protocol == %{ IPPROTO_TCP %}) {
dport = __tcp_skb_dport(tcphdr)
sport = __tcp_skb_sport(tcphdr)
if (dport == 9091) {
printf("loopback_xmit: skb: %p, %s:%d->%s:%d, dev: %s, pkt_type: %d\n", $skb, saddr, sport, daddr, dport, kernel_string($skb->dev->name), $skb->pkt_type)
}
}
}
probe kernel.function("netif_rx") {
iphdr = __get_skb_iphdr($skb)
saddr = format_ipaddr(__ip_skb_saddr(iphdr), %{ AF_INET %})
daddr = format_ipaddr(__ip_skb_daddr(iphdr), %{ AF_INET %})
protocol = __ip_skb_proto(iphdr)
tcphdr = __get_skb_tcphdr($skb)
if (protocol == %{ IPPROTO_TCP %}) {
dport = __tcp_skb_dport(tcphdr)
sport = __tcp_skb_sport(tcphdr)
if (dport == 9091) {
printf("netif_rx: skb: %p, %s:%d->%s:%d, dev: %s, pkt_type: %d\n", $skb, saddr, sport, daddr, dport, kernel_string($skb->dev->name), $skb->pkt_type)
}
}
}
probe kernel.function("__netif_receive_skb") {
iphdr = __get_skb_iphdr($skb)
saddr = format_ipaddr(__ip_skb_saddr(iphdr), %{ AF_INET %})
daddr = format_ipaddr(__ip_skb_daddr(iphdr), %{ AF_INET %})
protocol = __ip_skb_proto(iphdr)
tcphdr = __get_skb_tcphdr($skb)
if (protocol == %{ IPPROTO_TCP %}) {
dport = __tcp_skb_dport(tcphdr)
sport = __tcp_skb_sport(tcphdr)
if (dport == 9091) {
printf("__netif_receive_skb: skb: %p, %s:%d->%s:%d, dev: %s, pkt_type: %d\n", $skb, saddr, sport, daddr, dport, kernel_string($skb->dev->name), $skb->pkt_type)
}
}
}
probe kernel.function("ip_rcv") {
iphdr = __get_skb_iphdr($skb)
saddr = format_ipaddr(__ip_skb_saddr(iphdr), %{ AF_INET %})
daddr = format_ipaddr(__ip_skb_daddr(iphdr), %{ AF_INET %})
protocol = __ip_skb_proto(iphdr)
tcphdr = __get_skb_tcphdr($skb)
if (protocol == %{ IPPROTO_TCP %}) {
dport = __tcp_skb_dport(tcphdr)
sport = __tcp_skb_sport(tcphdr)
if (dport == 9091) {
printf("ip_rcv: skb: %p, %s:%d->%s:%d, dev: %s, pkt_type: %d\n", $skb, saddr, sport, daddr, dport, kernel_string($skb->dev->name), $skb->pkt_type)
}
}
}
运行脚本并再次请求后输出:
dev_queue_xmit: skb: 0xffff8d643ce40af8, 192.168.33.12:52996->192.168.33.1:9091, dev: eth1, pkt_type: 0
act_mirred: skb: 0xffff8d643ce40af8, 192.168.33.12:52996->192.168.33.1:9091, dev: eth1, pkt_type: 0
dev_queue_xmit: skb: 0xffff8d6423433800, 192.168.33.12:52996->192.168.33.1:9091, dev: lo, pkt_type: 0
loopback_xmit: skb: 0xffff8d6423433800, 192.168.33.12:52996->192.168.33.1:9091, dev: lo, pkt_type: 0
netif_rx: skb: 0xffff8d6423433800, 192.168.33.12:52996->192.168.33.1:9091, dev: lo, pkt_type: 3
__netif_receive_skb: skb: 0xffff8d6423433800, 192.168.33.12:52996->192.168.33.1:9091, dev: lo, pkt_type: 3
ip_rcv: skb: 0xffff8d6423433800, 192.168.33.12:52996->192.168.33.1:9091, dev: lo, pkt_type: 3
可以看到skb_clone后的sk_buff地址为0xffff8d6423433800, 它在进入loopback_xmit时,pkt_type为0,在进入netif_rx时,pkt_type变为了3。
再来看loopback_xmit的源码:
/*
* The higher levels take care of making this non-reentrant (it's
* called with bh's disabled).
*/
static netdev_tx_t loopback_xmit(struct sk_buff *skb,
struct net_device *dev)
{
struct pcpu_lstats *lb_stats;
int len;
skb_orphan(skb);
/* Before queueing this packet to netif_rx(),
* make sure dst is refcounted.
*/
skb_dst_force(skb);
skb->protocol = eth_type_trans(skb, dev);
/* it's OK to use per_cpu_ptr() because BHs are off */
lb_stats = this_cpu_ptr(dev->lstats);
len = skb->len;
if (likely(netif_rx(skb) == NET_RX_SUCCESS)) {
u64_stats_update_begin(&lb_stats->syncp);
lb_stats->bytes += len;
lb_stats->packets++;
u64_stats_update_end(&lb_stats->syncp);
}
return NETDEV_TX_OK;
}
可以看到,loopback_xmit在调用netif_rx前调用了eth_type_trans函数。eth_type_trans函数源码如下:
/**
* eth_type_trans - determine the packet's protocol ID.
* @skb: received socket data
* @dev: receiving network device
*
* The rule here is that we
* assume 802.3 if the type field is short enough to be a length.
* This is normal practice and works for any 'now in use' protocol.
*/
__be16 eth_type_trans(struct sk_buff *skb, struct net_device *dev)
{
struct ethhdr *eth;
skb->dev = dev;
skb_reset_mac_header(skb);
skb_pull_inline(skb, ETH_HLEN);
eth = eth_hdr(skb);
if (unlikely(is_multicast_ether_addr(eth->h_dest))) {
if (ether_addr_equal_64bits(eth->h_dest, dev->broadcast))
skb->pkt_type = PACKET_BROADCAST;
else
skb->pkt_type = PACKET_MULTICAST;
}
/*
* This ALLMULTI check should be redundant by 1.4
* so don't forget to remove it.
*
* Seems, you forgot to remove it. All silly devices
* seems to set IFF_PROMISC.
*/
else if (1 /*dev->flags&IFF_PROMISC */ ) {
if (unlikely(!ether_addr_equal_64bits(eth->h_dest,
dev->dev_addr)))
skb->pkt_type = PACKET_OTHERHOST;
}
/*
* Some variants of DSA tagging don't have an ethertype field
* at all, so we check here whether one of those tagging
* variants has been configured on the receiving interface,
* and if so, set skb->protocol without looking at the packet.
*/
if (unlikely(netdev_uses_dsa(dev)))
return htons(ETH_P_XDSA);
if (likely(eth_proto_is_802_3(eth->h_proto)))
return eth->h_proto;
/*
* This is a magic hack to spot IPX packets. Older Novell breaks
* the protocol design and runs IPX over 802.3 without an 802.2 LLC
* layer. We look for FFFF which isn't a used 802.2 SSAP/DSAP. This
* won't work for fault tolerant netware but does for the rest.
*/
if (unlikely(skb->len >= 2 && *(unsigned short *)(skb->data) == 0xFFFF))
return htons(ETH_P_802_3);
/*
* Real 802.2 LLC
*/
return htons(ETH_P_802_2);
}
EXPORT_SYMBOL(eth_type_trans);
可以看到,eth_type_trans函数会比较数据包的目的地址和设备的物理地址,当二者不一致时就会将skb->pkt_type设置为PACKET_OTHERHOST。
if (unlikely(!ether_addr_equal_64bits(eth->h_dest,
dev->dev_addr)))
skb->pkt_type = PACKET_OTHERHOST;
}
至此,我们可以确定整个过程: 当流量被tc镜像到lo接口后,继续走lo设备的发送流程,过程中由于镜像过来的数据包的目的MAC地址和lo接口的MAC地址不一致,从而将skb->pkt_type设置为PACKET_OTHERHOST, 表示数据包不是发送给该接口的。loopback_xmit继续调用netif_rx函数接收数据包,执行到ip_rcv时,由于pkt_type为PACKET_OTHERHOST而被丢弃。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK