

DeepFake从未如此真实!英伟达最新提出的「隐式扭曲」到底有多强?
source link: https://www.51cto.com/article/721066.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

DeepFake从未如此真实!英伟达最新提出的「隐式扭曲」到底有多强?
近年来,计算机视觉领域的生成技术越来越强,相应「伪造」技术也越来越成熟,从DeepFake换脸到动作模拟,让人难辨真假。
最近英伟达又整了个大的,在NeurIPS 2022会议上发表了一个新的隐式扭曲(Implicit Warping)框架,使用一组源图像和驱动视频的运动来制作目标动画。

论文链接:https://arxiv.org/pdf/2210.01794.pdf
从效果上来看,就是生成的图像更逼真了,人物在视频里动,背景也不会发生变化。
输入的多张源图片通常都会提供不同的外观信息,减少了生成器「幻想」的空间,比如下面这两张作为模型输入。
可以发现,和其他模型相比,隐式扭曲不会产生类似美颜效果的「空间扭曲」之术。
因为人物遮挡的关系,多张源图像还可以提供更完善的背景。

从下面的视频中可以看到,如果只有左面的一张图片,背景后面的是「BD」还是「ED」很难猜测出来,就会导致背景的失真,而两张图片就会生成更稳定的图像。
在对比其他模型时,只有一张源图像的效果也要更好。

神奇的隐式扭曲
学术界对于视频模仿最早可以追溯到2005年,很多项目面部再现的实时表情传输、Face2Face、合成奥巴马、Recycle-GAN、ReenactGAN、动态神经辐射场等等多样化地利用当时有限的几种技术,如生成对抗网络(GAN) 、神经辐射场(NeRF)和自编码器。
并不是所有方法都在尝试从单一帧图像中生成视频,也有一些研究对视频中的每一帧进行复杂的计算,这实际上也正是Deepfake所走的模仿路线。
但由于DeepFake模型获取的信息较少,这种方法需要对每个视频片段进行训练,相比DeepFaceLab或FaceSwap的开源方法相比性能有所下降,这两个模型能够将一个身份强加到任意数量的视频片段中。
2019年发布的FOMM模型让人物随着视频动起来,给视频模仿任务再次注入了一针强心剂。
随后其他研究人员试图从单一的面孔图像或者全身表现中获得多个姿势和表情;但是这种方法通常只适用于那些相对没有表情和不能动的主体,例如相对静止的「说话的头」,因为在面部表情或者姿势中没有网络必须解释的「行为突然变化」。

虽然其中一些技术和方法在深度伪造技术和潜在的扩散图像合成方法大火之前获得了公众的关注,但适用范围有限,多功能性受到质疑。
而英伟达此次着重处理的隐式扭曲,则是在多帧之间甚至只有两帧之间获取信息,而非从一帧中获得所有必要的姿势信息,这种设置在其他的竞争模型中都不存在,或者处理得非常糟糕。
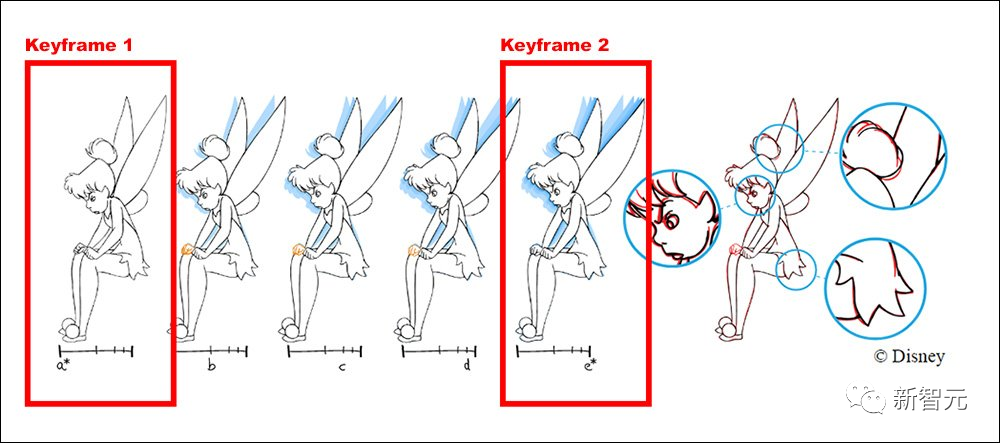
比如迪士尼的工作流程就是由高级动画师绘制主框架和关键帧,其他初级动画师负责绘制中间帧。
通过对以前版本的测试,英伟达的研究人员发现,以前方法的结果质量会随着额外的「关键帧」而恶化,而新方法与动画制作的逻辑一致,随着关键帧数量的增加,性能也会以线性的方式提高。
如果clip的中间发生了一些突然的转变,比如一个事件或者表情在起始帧或者结束帧中都没有表现出来,隐式扭曲可以在这中间点添加一帧,额外的信息会反馈到整个clip的注意机制中。

先前的方法,如 FOMM,Monkey-Net 和face-vid2vid等使用显式扭曲绘制一个时间序列,从源人脸和控制运动中提取的信息必须适应且符合这个时间序列。
在这种模型设计下,关键点的最终映射是相当严格的。
相比之下,隐式扭曲使用一个跨模态注意层,其工作流中包含更少的预定义bootstrapping,可以适应来自多个框架的输入。
工作流也不需要在每个关键点的基础上进行扭曲,系统可以从一系列图像中选择最合适的特性。
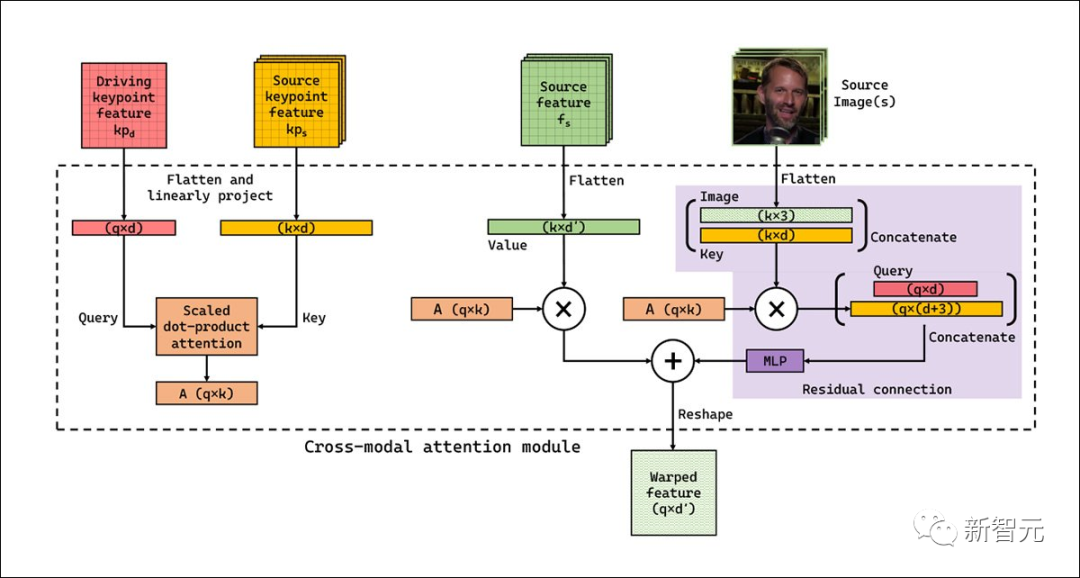
隐式扭曲也复用了一些FOMM框架中的关键点预测组件,最终用一个简单的U-net对派生的空间驱动关键点表示进行编码。另外一个单独的U-net则用来与衍生的空间表示一起对源图像进行编码,两个网络都可以在64px (256px 平方输出)到384x384px 的分辨率范围内运行。
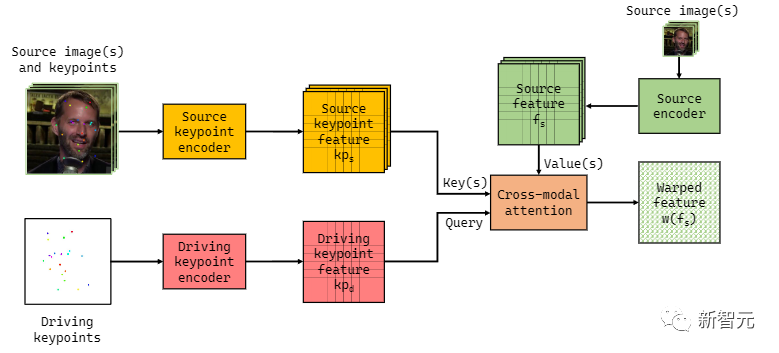
因为这种机制不能自动解释任何给定视频中姿势和运动的所有可能变化,所以额外的关键帧是很必要的,可以临时添加。如果没有这种干预能力,与目标运动点相似度不足的key将自动uprate,从而导致输出质量的下降。
研究人员对此的解释是,虽然它是一组给定的关键帧中与query最相似的key,但可能不足以产生一个好的输出。
例如,假设源图像有一张嘴唇闭合的脸,而驱动图像有一张嘴唇张开、牙齿暴露的脸。在这种情况下,源图像中没有适合驱动图像嘴部区域的key(和value)。
该方法通过学习额外的与图像无关的key-value pairs来克服这个问题,可以应对源图像中缺少信息的情况。
尽管目前的实现速度相当快,在512x512px 的图像上大约10 FPS,研究人员认为,在未来的版本中,pipeline可以通过一个因子化的 I-D 注意力层或空间降低注意力(SRA)层(即金字塔视觉Transformer)来优化。

由于隐式扭曲使用的是全局注意力而不是局部注意力,因此它可以预测之前模型无法预测的因素。
研究人员在 VoxCeleb2数据集,更具挑战性的 TED Talk 数据集和 TalkingHead-1KH 数据集上测试了该系统,比较了256x256px 和完整的512x512px 分辨率之间的基线,使用的指标包括FID、基于 AlexNet的LPIPS和峰值信噪比(pSNR)。
用于测试的对比框架包括FOMM和face-vid2vid,以及AA-PCA,由于以前的方法很少或根本没有能力使用多个关键帧,这也是隐式扭曲的主要创新,研究人员还设计了相似测试方法。
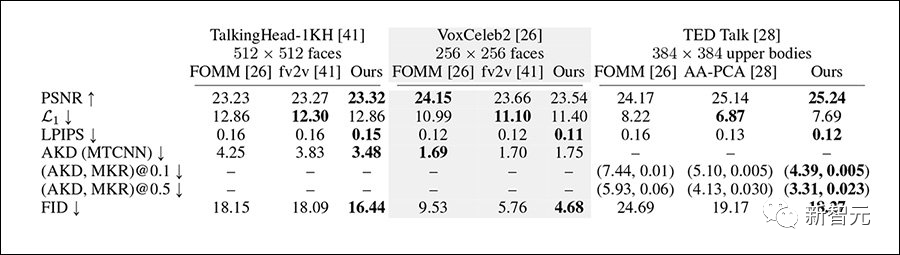
隐式扭曲在大多数指标上表现优于大多数对比方法。
在多关键帧重建测试中,研究人员使用最多180帧序列,并选择间隙帧,隐式扭曲这次获得了全面胜利。
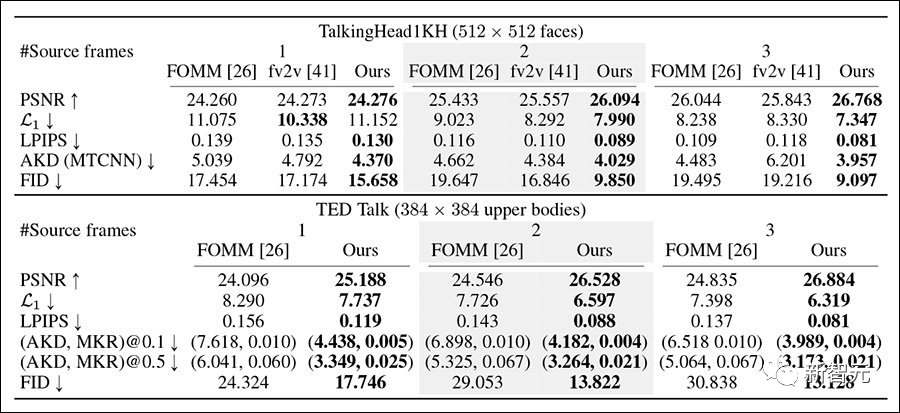
随着源图像数量的增加,该方法可以获得更好的重建结果,所有指标的得分都有所提高。
而随着源图像数量的增加,先前工作的重建效果变差,与预期相反。

通过AMT的工作人员进行定性研究后,也认为隐式变形的生成结果强于其他方法。
如果能够使用这种框架,用户将能够制作出更连贯、更长的视频模拟和全身深度假视频,所有这些都能够展现出比该系统已经试验过的任何框架都要大得多的运动范围。
不过更逼真的图像合成研究也带来了担忧,因为这些技术可以轻易地用于伪造,论文中也有标准的免责声明。
如果我们的方法被用来制造DeepFake产品,就有可能产生负面影响。恶意语音合成透过跨身份转移及传送虚假资料,制作人物的虚假影像,导致身份被盗用或传播虚假新闻。但在受控设置中,同样的技术也可以用于娱乐目的。
论文还指出了该系统在神经视频重建方面的潜力,比如谷歌的Project Starline,在这个框架中,重建工作主要集中在客户端,利用来自另一端的人的稀疏运动信息。
这个方案越来越引起研究界的兴趣,并且也有公司打算通过发送纯运动数据或者稀疏间隔的关键帧来实现低带宽的电话会议,这些关键帧将在到达目标客户端时被解释和插入到完整的高清视频中。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK