

疫情背景下的中长期月度预测方案
source link: https://www.51cto.com/article/721039.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

疫情背景下的中长期月度预测方案
作者 | 晓雯,携程高级算法工程师,关注时间序列预测;Bluewind,关注时间序列预测。
本文将分享一个基于疫情情况下的中长期月度间夜数据预测方法。传统的时间序列模型通过学习历史数据中趋势性和季节性的特征,能对月度数据做出相对有效的预测。而自从2020年以来,不时发生的疫情影响了历史数据相对规律的趋势性和季节性特征,也给基于传统时间序列模型的预测带来了难度。
本文考虑到上述情况,针对疫情,给出了一个改进预测方案,来更好地对数据进行预测,使其能更好地运用于预算、规划、决策等管理目的。
中长期月度间夜预测,主要是预测未来公司1-6月内的间夜,可以帮助公司进行预算、规划、决策等管理行为。
然而,在目前的疫情背景之下,中长期预测面临着新的问题:一方面预测变得更加困难,另一方面预测也变得更加重要。由于疫情的存在,增加了很多未来的不确定性,导致模型的预测困难进一步增加;同时也是因为疫情不确定性的存在,更需要预测相关的手段来帮助获得更多的未来信息,以更好的对未来进行预测、规划和决策。
因此,在疫情背景下的中长期预测变成了一个困难但是重要的问题。
三、面临问题
概括而言,在疫情背景下的中长期预测面临如下问题:
3.1 被预测时间长,导致预测难度增加
由于中长期预测的时间最近是未来一个月,最远是未来半年。而在疫情背景之下,未来是否会发生疫情,是会对实际的间夜产生影响的。但是站在当前节点,是无法预测到未来一个月,甚至半年后的疫情情况的,这就会给预测增加许多的难度。
3.2 数据量少,导致模型可学习模式少
对月度数据而言,一年只有12个数据。而在疫情情况下,不同的月份还面临这不同的疫情影响程度。这就会给模型的学习带来难度。
3.3 疫情影响的量化比较困难
疫情对间夜的影响是一个多方面复合的影响,和确诊人数、当地政策、以及当时的季节都有相关关系,无法简单使用确诊人数来进行评估。比如,疫情之前每年的八月都是间夜高峰,但是疫情之后,随着部分地区中小学要求学生开学前14天不能离开当地,导致疫情之后的八月下半旬的间夜增长就会比往年放缓,这部分的影响是和政策密切相关的,而不会直接体现在确诊人数上。另外,疫情对间夜的影响还存在着滞后性的问题,一个地区可能在最近只有一天出现确诊,但是这一天的确诊可能会持续影响其未来的14天甚至更远。
四、问题定义
4.1 口径定义
我们定义预测的目标值为:全国酒店的月度间夜,并且不包含中途取消的订单。
4.2 问题拆解
我们认为对于未来6个月的月度间夜预测,可以拆解为两个问题。
问题一是中期预测,即只预测未来一个月的月度间夜,即当前为9月份时,预测10月份;当前为10月份时,预测11月份,以此类推。
问题二是长期预测,即预测未来两个月到6个月的月度间夜,即当前为9月份时,预测未来11月份、12月份、来年1月份、来年2月份、来年3月份的月度间夜。
之所以做这种拆解的原因是未来一个月的间夜相对来说和目前的间夜有更强的关联性,将它单独做预测可以提升预测精度。
五、中期预测方案
5.1 问题处理
在中期预测方案之中,主要面对的问题是数据量少导致模型可学习模式少和疫情影响的量化比较困难。针对这两个问题,我们的处理方案如下:
首先,将问题修正为预测未来30天内平均间夜,这样就可以通过滑动窗口来构造数据,从而增加数据的数量。即原来每个月只能有一个样本,现在每个月的每一天到未来30天都是一个样本,可以提升整体的数据数量。
这里可能存在的问题是每个月的天数有些是28天,有些是31天,有些是30天。所以,我们对可能因为天数产生的数据偏差做了计算,结果如下表,可以看到偏差都在千分之三以下,不是很大,所以我们认为这种处理对预测的影响较小。
当月平均值与30天平均值的mape | |
22-7月 | 0.20% |
22-8月 | 0.21% |
22-10月 | 0.03% |
22-12月 | 0.27% |
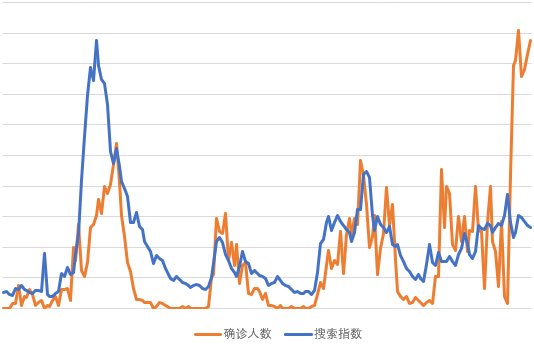
其次,使用搜索引擎提供的疫情指数数据来作为疫情影响的衡量依据。参考下图的确诊人数和搜索指数的关联关系图可见,在疫情开始初期,指数数据会有一个比较集中的反馈,在疫情确诊人数回落之后,搜索指数也不是马上回落,而是逐渐下降。这比较符合我们对疫情的认知:当它开始的时候会对间夜马上产生影响,但是等到清零之后,由于14天潜伏期的考虑,其实间夜的影响是逐步恢复的。
5.2 使用特征
在中期预测之中使用的特征可以主要分为三个部分:
第一部分是时间相关的固定性信息:比如做出预测的日期的星期,做出预测的月份,被预测周期之内是否有节假日,有几天节假日。举例来说,如果是在2022年4月30日预测22年5月1日到5月30日的间夜平均值,那么被预测周期内的节假日就是五一,一共有4天(不包含4月30日)。
第二部分是间夜数据无关的外部信息,包含截止到预测日期的最新日uv以及疫情指数数据等信息,比如在2月11日做对3月份的预测,那么能拿到的数据就是2月10日的uv数据以及疫情指数数据等信息。
第三部分是和间夜数据相关的特征构建,包含去年同期的间夜情况,前年同期的间夜情况,被预测周期的上单情况等。比如在在2022年2月11日做对3月份的预测,那么对应的特征就分别为2021年3月的间夜情况,2020年3月的间夜情况,以及截止2022年2月11日时已有的3月的间夜。
5.3 模型介绍
中期预测使用的预测模型是LSTM,是在RNN基础上的扩展。RNN是基于序列形式构建的神经网络结构,每个神经元的计算元素都是上一个神经元的隐层以及该神经元的输入。如果用时间序列来理解这个问题的话,RNN的每个神经元,都代表一个时间点,每个神经元的输入都是上个时间点(神经元)计算得到的信息+这个时间点的信息。而LSTM则是在RNN的基础上,对每个神经元内部的计算进行了优化,增加了输入门、遗忘门以及输出门机制,来辅助神经元能够更有效的获得传递过来的序列信息。
5.4 评价指标
模型的衡量指标我们采用的是mape,即平均绝对百分误差,计算公式如下:
avg(abs(真实值-预测值)/真实值)mape值越大,模型误差就越大,效果就越不好。
5.5 模型训练与结果
模型训练需要注意防止数据泄露,也就是验证集和训练集之间的时间需要隔开一定时间。比如,训练集是2022年3月1日之前的数据,验证集需要隔开30天,即2022年3月31日才可以。原因是,我们的目标值是未来30天的平均值,所以如果直接拿2022年3月1日之前的数据训练,那么在训练集的目标值中就会包含未来30天的信息,而这部分信息其实是验证集之中需要预测的信息,因此构成了一定程度的信息泄露,所以训练集需要隔开30天。
模型效果如下表展示:
21年9月 | |
21年10月 | 0.08% |
21年11月 | 4.33% |
21年12月 | 3.25% |
可以看到,模型在21年9月到12月的预测之中都表现出了比较好的准确率。
六、长期预测方案
6.1 问题处理
在长期预测方案之中,主要面对的问题是预测周期长,导致间夜极大程度上受到疫情的影响,但是由于疫情不可预测,导致长期预测的难度较高。对此,我们采取的处理方案是使用情景预测的方案,针对不同的疫情情景,给出不同的预测值。
6.2 使用特征
在长期预测方案之中,我们采取的特征如下:
- 去年同期间夜的对数值。比如,预测2023年4月的间夜,那么2022年4月的间夜取对数,就可以得到这个特征。
- 每个被预测月的上单对数值,计算包含取消单的全量单。比如,在2月的时候预测4月的间夜,那么这个数值就是在2月的时候,我们已经有的下单的4月订单之和,并对这个值取对数。
- 按照去年同期上单间夜比构造今年间夜量的对数值。计算公式如下:

- 搜索引擎指数:以“疫情”为关键字的搜索引擎搜索指数平均值,具有滞后性,衡量大众对疫情的关注度。计算公式如下:

这里需要注意的是,在训练背景下可以获得这个搜索数据,但是在预测场景下,是没有实际的搜索数据的,我们将在d部分介绍这部分的变动。
- 每个月总本土确诊人数的天数平均:举例来说,假如3月有31天一共确诊了62名病例,那么这个特征数值就是62/31=2
- 就地过年政策特征:0~1之间的连续值,根据每年春节期间情况设定,1代表严格执行就地过年,0代表完全取消就地过年政策,目前2021年2月该值为1,2022年2月该值为0.5。
6.3 模型步骤介绍
整体预测的逻辑如下:先基于历史没有疫情的情况下学习一个SARIMA模型,这个模型主要是学习在疫情前数据表现出的周期性季节性表现,给出一个假如没有疫情的时候的预测间夜。然后,使用lasso模型来拟合没有疫情时的预测间夜和实际间夜之间的比例,从而得到最终的预测间夜。这样分开预测的好处是可以将疫情的影响比较具象的表现出来。具体分为下面五个步骤:
- 步骤一:对2018/2019两年的数据构造SARIMA模型。
- 步骤二:按照上一步得到的SARIMA模型预测2020起的每月间夜量,记为normal_forecast。
- 步骤三:构造modify_rate,即normal_forecast/真实间夜量。
- 步骤四:利用前面列出的特征拟合modify_rate。
- 步骤五:列出不同疫情情境下的疫情数值,并基于此来预测modify_rate,最后通过normal_forecast/modify_rate计算间夜量预测值。
6.4 模型预测与结果
在预测阶段,我们通过输入高中低三种疫情情景下的特征数值,得到不同疫情情景之下modify_rate预测值,然后通过normal_forecast/modify_rate得到计算的间夜预测值。
目前在特征中,使用到的疫情特征包含两个:每个月总本土确诊人数的天数平均和搜索引擎指数。通过计算这两个特征的历史分位数情况,我们可以得到不同疫情情况下,这两个特征的分布情况,将指定的分位数阈值作为不同情景划分标准。
具体如下表所示,最大值、最小值、60%分位数和90%分位数将产生了三个风险区,低风险代表疫情基本不影响间夜表现的情况,中风险表示有疫情一定程度上产生间夜表现影响,高风险代表疫情极大的影响到了间夜的表现。
低风险下限 | 低风险上限/中风险下限 | 中风险上限/高风险下限 | 高风险上限 | |
平均搜索指数 | 60%分位数 | 90%分位数 | ||
本土确诊人数 | 60%分位数 | 90%分位数 |
我们用21年7月到21年12月这个区间,对这个预测方案进行验证,结果如下表,可以看到,所有区域的实际值都在预测区域之中,并且所属的预测风险区也基本和当时的疫情情况吻合。
实际值是否在预测区域中 | 所属预测风险区 | |
21年7月 | 低疫情风险区 | |
21年8月 | 高疫情风险区 | |
21年9月 | 中疫情风险区 | |
21年10月 | 中疫情风险区 | |
21年11月 | 高疫情风险区 | |
21年12月 | 中疫情风险区 |
七、总结与展望
本文主要基于中期预测和长期预测两个方案介绍了在疫情背景下间夜的预测。在之后的工作中,我们将会从以下几个方向对预测进行进一步的优化:
首先,将会进一步细化疫情量化信息,由于现在的指数数据是使用确诊人数与搜索引擎指数,而这两者在一些特定的情况下不能直接反应疫情影响,比如对于不同的人口密度和旅游需求的省份同样的确诊人数可能带来的影响是不同的。又比如每年年终都会有大量的总结性话题,这个也有可能导致指数信息的计算偏差。所以,后续可以考虑基于这些情况做进一步优化。
其次,考虑基于历史疫情信息,对疫情做预测之后再进行间夜预测。随着疫情常态化的到来,历史已有的疫情变化数据都可以作为我们的参考数据来对未来数据做出预测。所以,我们之后会考虑先判断疫情之后可能的发展方向,基于此来优化我们情景预测的部分。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK