

Interview Questions on Semantic-based Data Mining
source link: https://www.analyticsvidhya.com/blog/2022/10/interview-questions-on-semantic-based-data-mining/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

This article was published as a part of the Data Science Blogathon.
Introduction
Data mining is extracting relevant information from a large corpus of natural language. Large data sets are sorted through data mining to find patterns and relationships that may be used in data analysis to assist solve business challenges. Thanks to data mining techniques and technologies, enterprises can forecast future trends and make more educated business decisions.
Syntax and semantics are the two major components of any written language. Syntax is the rules/grammar should follow by the writer while writing a language, and semantics is the internal meaning of the sentence or phrases the author has written.
So as a result, two types of data mining techniques are widely used in the data science industry today.
Syntax-based data mining: Here, we extract the data based on characters or words in the sentence. Not taking the implicit meaning. E.g. TF-IDF Method.
Pros:
- Easy to implement
- Easy to interpret
Cons:
- Not always accurate
- Not taking the actual context of the data mining scenario
Semantic-based data mining: Here, we are extracting the data based on the internal meaning of the corpus and sentence. Working based on the implicit meaning of the sentence.
Pros:
- Takes the actual context of the data mining scenario
- Can build more trust and robustness with the end user
Cons:
- Hard to implement
- More calculations need for the text matching
As we have seen above, not only do semantic-based data mining applications have many advantages, but also it can make a strong trust connection between the end user.

Many organizations and tech companies working on data mining are now turning from syntax-based data mining processes to semantic base data mining processes. So in this blog, I am describing some interview questions on semantic-based data mining that may chance to ask in the data mining engineer interview process.
Semantics-based Data Mining Interview Questions
1 – What is semantic search? How does it differ from syntactic search?
Ans: Semantic search is a method of data searching in which a search query seeks to identify keywords and ascertain the intent and context of the words being used. Search engines utilise semantic search as a method to try to decipher your search query’s context and intent to provide you with results that are relevant to your search.
Syntactic matching refers to matching search terms to keywords depending on the search terms entered into the search engine. This would be phrase- and exact-matching. Semantic matching matches search queries to keywords based on the intent of the searcher’s input. Broad match applies here.
2- What is the role of embeddings in semantic search?
Ans: In semantic search, the search operations are performed based on the embeddings. There are different types of semantic search is there. E.g., Textual semantic search in the case of natural language systems, Visual semantic search in the case of image processing systems..etc. Whatever the case, we convert the input and corpus objects to numerical fixed-length vectors. And the rest of the matching operations are applied to these vectors. These vectors are called embeddings.
A sample flow diagram is shown below.
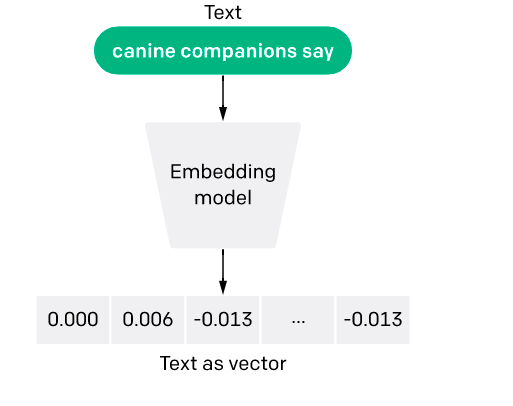
Making the textual sentences into embedding format enables the system to perform mathematical operations faster by retaining the inner meaning. Also, embedding will help systems encode similar sentences to similar encoding vectors with fixed/variable length.
So any semantic search-based system will contain the following 2 modules minimum.
1 – Embedding module
Where the encoding of the objects to embedding takes place
2 – Searching module
Where the actual search/match operations upon the embedding take place
3 – What are the different types of semantic similarity methods?

source: https://www.baeldung.com/cs/semantic-similarity-of-two-phrases
4 – How can we transform natural language sentences into vectors/embeddings?
5 – Describe the vector database and its use cases.
6 – Explain ANN in semantic search
7 – What are the ANN benchmarks?
8 – Compare WEAVIATE, ANNOY, and FIASS
9 – Have you practical coding experience with semantic text search tools?
10- Explain Locality Sensitive Hashing
Conclusion
Semantic search in unstructured data is one of the hottest research domains today. Because all of us like a search engine or an AI application that can read our actual intent while interacting rather than just do – don’t do command manner. Semantic search does the same, operating on all domains, including text, visual, speech, etc. Using this technique, we can extract semantically similar data from large corpora. In this blog, I have covered some common interview questions that may ask in the data mining interview process.
Key Takeaways
- In contrast to lexical search, which focuses on finding exact matches between the query words or their variants without considering the query’s overall meaning, semantic search refers to search with meaning.
- The term “embedding” refers to how words are represented for text analysis, often as a real-valued vector that encodes the word’s meaning.
- To manage the distinct structure of vector embeddings, vector databases were specifically designed. They compare values and select the ones most similar to one another to index vectors for quick search and retrieval.
- Locality-sensitive hashing is an algorithmic technique used in computer science that, with a high degree of probability, hashes similar input items into the same “buckets.”
- It is permitted for an approximate nearest neighbor search algorithm to return points that are at most c times farther away from the query than its nearest points.
I hope this article helped you to strengthen your semantic search fundamental concepts. Feel free to leave a remark below if you have any questions, concerns, or recommendations.
Keep learning.. !
!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Related
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK