

A Practical Introduction to Web Scraping in Python
source link: https://realpython.com/python-web-scraping-practical-introduction/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Scrape and Parse Text From Websites
Collecting data from websites using an automated process is known as web scraping. Some websites explicitly forbid users from scraping their data with automated tools like the ones that you’ll create in this tutorial. Websites do this for two possible reasons:
- The site has a good reason to protect its data. For instance, Google Maps doesn’t let you request too many results too quickly.
- Making many repeated requests to a website’s server may use up bandwidth, slowing down the website for other users and potentially overloading the server such that the website stops responding entirely.
Before using your Python skills for web scraping, you should always check your target website’s acceptable use policy to see if accessing the website with automated tools is a violation of its terms of use. Legally, web scraping against the wishes of a website is very much a gray area.
Important: Please be aware that the following techniques may be illegal when used on websites that prohibit web scraping.
For this tutorial, you’ll use a page that’s hosted on Real Python’s server. The page that you’ll access has been set up for use with this tutorial.
Now that you’ve read the disclaimer, you can get to the fun stuff. In the next section, you’ll start grabbing all the HTML code from a single web page.
Build Your First Web Scraper
One useful package for web scraping that you can find in Python’s standard library is urllib, which contains tools for working with URLs. In particular, the urllib.request module contains a function called urlopen() that you can use to open a URL within a program.
In IDLE’s interactive window, type the following to import urlopen():
>>> from urllib.request import urlopen
The web page that you’ll open is at the following URL:
>>> url = "http://olympus.realpython.org/profiles/aphrodite"
To open the web page, pass url to urlopen():
>>> page = urlopen(url)
urlopen() returns an HTTPResponse object:
>>> page
<http.client.HTTPResponse object at 0x105fef820>
To extract the HTML from the page, first use the HTTPResponse object’s .read() method, which returns a sequence of bytes. Then use .decode() to decode the bytes to a string using UTF-8:
>>> html_bytes = page.read()
>>> html = html_bytes.decode("utf-8")
Now you can print the HTML to see the contents of the web page:
>>> print(html)
<html>
<head>
<title>Profile: Aphrodite</title>
</head>
<body bgcolor="yellow">
<center>
<br><br>
<img src="/static/aphrodite.gif" />
<h2>Name: Aphrodite</h2>
<br><br>
Favorite animal: Dove
<br><br>
Favorite color: Red
<br><br>
Hometown: Mount Olympus
</center>
</body>
</html>
The output that you’re seeing is the HTML code of the website, which your browser renders when you visit http://olympus.realpython.org/profiles/aphrodite:
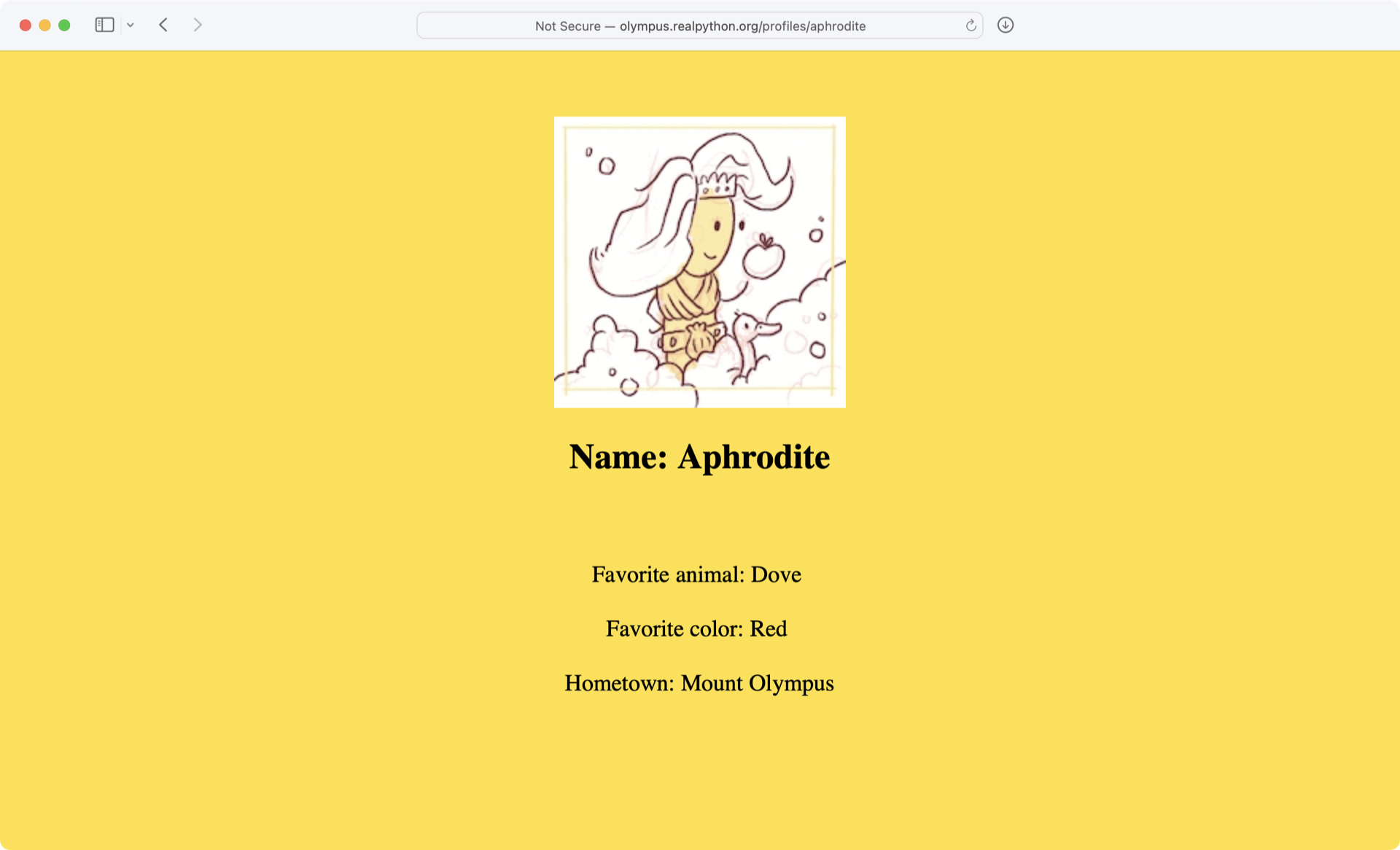
With urllib, you accessed the website similarly to how you would in your browser. However, instead of rendering the content visually, you grabbed the source code as text. Now that you have the HTML as text, you can extract information from it in a couple of different ways.
Extract Text From HTML With String Methods
One way to extract information from a web page’s HTML is to use string methods. For instance, you can use .find() to search through the text of the HTML for the <title> tags and extract the title of the web page.
To start, you’ll extract the title of the web page that you requested in the previous example. If you know the index of the first character of the title and the index of the first character of the closing </title> tag, then you can use a string slice to extract the title.
Because .find() returns the index of the first occurrence of a substring, you can get the index of the opening <title> tag by passing the string "<title>" to .find():
>>> title_index = html.find("<title>")
>>> title_index
14
You don’t want the index of the <title> tag, though. You want the index of the title itself. To get the index of the first letter in the title, you can add the length of the string "<title>" to title_index:
>>> start_index = title_index + len("<title>")
>>> start_index
21
Now get the index of the closing </title> tag by passing the string "</title>" to .find():
>>> end_index = html.find("</title>")
>>> end_index
39
Finally, you can extract the title by slicing the html string:
>>> title = html[start_index:end_index]
>>> title
'Profile: Aphrodite'
Real-world HTML can be much more complicated and far less predictable than the HTML on the Aphrodite profile page. Here’s another profile page with some messier HTML that you can scrape:
>>> url = "http://olympus.realpython.org/profiles/poseidon"
Try extracting the title from this new URL using the same method as in the previous example:
>>> url = "http://olympus.realpython.org/profiles/poseidon"
>>> page = urlopen(url)
>>> html = page.read().decode("utf-8")
>>> start_index = html.find("<title>") + len("<title>")
>>> end_index = html.find("</title>")
>>> title = html[start_index:end_index]
>>> title
'\n<head>\n<title >Profile: Poseidon'
Whoops! There’s a bit of HTML mixed in with the title. Why’s that?
The HTML for the /profiles/poseidon page looks similar to the /profiles/aphrodite page, but there’s a small difference. The opening <title> tag has an extra space before the closing angle bracket (>), rendering it as <title >.
html.find("<title>") returns -1 because the exact substring "<title>" doesn’t exist. When -1 is added to len("<title>"), which is 7, the start_index variable is assigned the value 6.
The character at index 6 of the string html is a newline character (\n) right before the opening angle bracket (<) of the <head> tag. This means that html[start_index:end_index] returns all the HTML starting with that newline and ending just before the </title> tag.
These sorts of problems can occur in countless unpredictable ways. You need a more reliable way to extract text from HTML.
Get to Know Regular Expressions
Regular expressions—or regexes for short—are patterns that you can use to search for text within a string. Python supports regular expressions through the standard library’s re module.
Note: Regular expressions aren’t particular to Python. They’re a general programming concept and are supported in many programming languages.
To work with regular expressions, the first thing that you need to do is import the re module:
>>> import re
Regular expressions use special characters called metacharacters to denote different patterns. For instance, the asterisk character (*) stands for zero or more instances of whatever comes just before the asterisk.
In the following example, you use .findall() to find any text within a string that matches a given regular expression:
>>> re.findall("ab*c", "ac")
['ac']
The first argument of re.findall() is the regular expression that you want to match, and the second argument is the string to test. In the above example, you search for the pattern "ab*c" in the string "ac".
The regular expression "ab*c" matches any part of the string that begins with "a", ends with "c", and has zero or more instances of "b" between the two. re.findall() returns a list of all matches. The string "ac" matches this pattern, so it’s returned in the list.
Here’s the same pattern applied to different strings:
>>> re.findall("ab*c", "abcd")
['abc']
>>> re.findall("ab*c", "acc")
['ac']
>>> re.findall("ab*c", "abcac")
['abc', 'ac']
>>> re.findall("ab*c", "abdc")
[]
Notice that if no match is found, then .findall() returns an empty list.
Pattern matching is case sensitive. If you want to match this pattern regardless of the case, then you can pass a third argument with the value re.IGNORECASE:
>>> re.findall("ab*c", "ABC")
[]
>>> re.findall("ab*c", "ABC", re.IGNORECASE)
['ABC']
You can use a period (.) to stand for any single character in a regular expression. For instance, you could find all the strings that contain the letters "a" and "c" separated by a single character as follows:
>>> re.findall("a.c", "abc")
['abc']
>>> re.findall("a.c", "abbc")
[]
>>> re.findall("a.c", "ac")
[]
>>> re.findall("a.c", "acc")
['acc']
The pattern .* inside a regular expression stands for any character repeated any number of times. For instance, you can use "a.*c" to find every substring that starts with "a" and ends with "c", regardless of which letter—or letters—are in between:
>>> re.findall("a.*c", "abc")
['abc']
>>> re.findall("a.*c", "abbc")
['abbc']
>>> re.findall("a.*c", "ac")
['ac']
>>> re.findall("a.*c", "acc")
['acc']
Often, you use re.search() to search for a particular pattern inside a string. This function is somewhat more complicated than re.findall() because it returns an object called MatchObject that stores different groups of data. This is because there might be matches inside other matches, and re.search() returns every possible result.
The details of MatchObject are irrelevant here. For now, just know that calling .group() on MatchObject will return the first and most inclusive result, which in most cases is just what you want:
>>> match_results = re.search("ab*c", "ABC", re.IGNORECASE)
>>> match_results.group()
'ABC'
There’s one more function in the re module that’s useful for parsing out text. re.sub(), which is short for substitute, allows you to replace the text in a string that matches a regular expression with new text. It behaves sort of like the .replace() string method.
The arguments passed to re.sub() are the regular expression, followed by the replacement text, followed by the string. Here’s an example:
>>> string = "Everything is <replaced> if it's in <tags>."
>>> string = re.sub("<.*>", "ELEPHANTS", string)
>>> string
'Everything is ELEPHANTS.'
Perhaps that wasn’t quite what you expected to happen.
re.sub() uses the regular expression "<.*>" to find and replace everything between the first < and the last >, which spans from the beginning of <replaced> to the end of <tags>. This is because Python’s regular expressions are greedy, meaning they try to find the longest possible match when characters like * are used.
Alternatively, you can use the non-greedy matching pattern *?, which works the same way as * except that it matches the shortest possible string of text:
>>> string = "Everything is <replaced> if it's in <tags>."
>>> string = re.sub("<.*?>", "ELEPHANTS", string)
>>> string
"Everything is ELEPHANTS if it's in ELEPHANTS."
This time, re.sub() finds two matches, <replaced> and <tags>, and substitutes the string "ELEPHANTS" for both matches.
Extract Text From HTML With Regular Expressions
Equipped with all this knowledge, now try to parse out the title from another profile page, which includes this rather carelessly written line of HTML:
<TITLE >Profile: Dionysus</title / >
The .find() method would have a difficult time dealing with the inconsistencies here, but with the clever use of regular expressions, you can handle this code quickly and efficiently:
# regex_soup.py
import re
from urllib.request import urlopen
url = "http://olympus.realpython.org/profiles/dionysus"
page = urlopen(url)
html = page.read().decode("utf-8")
pattern = "<title.*?>.*?</title.*?>"
match_results = re.search(pattern, html, re.IGNORECASE)
title = match_results.group()
title = re.sub("<.*?>", "", title) # Remove HTML tags
print(title)
Take a closer look at the first regular expression in the pattern string by breaking it down into three parts:
-
<title.*?>matches the opening<TITLE >tag inhtml. The<titlepart of the pattern matches with<TITLEbecausere.search()is called withre.IGNORECASE, and.*?>matches any text after<TITLEup to the first instance of>. -
.*?non-greedily matches all text after the opening<TITLE >, stopping at the first match for</title.*?>. -
</title.*?>differs from the first pattern only in its use of the/character, so it matches the closing</title / >tag inhtml.
The second regular expression, the string "<.*?>", also uses the non-greedy .*? to match all the HTML tags in the title string. By replacing any matches with "", re.sub() removes all the tags and returns only the text.
Note: Web scraping in Python or any other language can be tedious. No two websites are organized the same way, and HTML is often messy. Moreover, websites change over time. Web scrapers that work today aren’t guaranteed to work next year—or next week, for that matter!
Regular expressions are a powerful tool when used correctly. In this introduction, you’ve barely scratched the surface. For more about regular expressions and how to use them, check out the two-part series Regular Expressions: Regexes in Python.
Check Your Understanding
Expand the block below to check your understanding.
You can expand the block below to see a solution.
When you’re ready, you can move on to the next section.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK