

系统设计的艺术:当HPC与AI应用成为主流,GPU架构该向何处去?
source link: https://www.51cto.com/article/720568.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

系统设计的艺术:当HPC与AI应用成为主流,GPU架构该向何处去?

我们多年前就曾经提到,配合充足的数据并使用卷积神经网络进行AI工作负载训练正逐渐成为主流,而全球各主要HPC(高性能计算)中心多年来一直把这方面负载交给英伟达的GPU处理。对于模拟和建模等任务,GPU的性能表现可谓相当突出。从本质上讲,HPC模拟/建模与AI训练其实是一种谐波收敛,而GPU作为大规模并行处理器特别擅长执行这类工作。
但自2012年起,AI革命正式爆发,图像识别软件第一次将准确度提升至超越人类的水平。所以我们非常好奇,HPC和AI这种在同类GPU上高效处理的共性还能持续多久。于是在2019年夏季,通过对模型的细化迭代,我们尝试用混合精度数学单元在Linpack基准测试中得出与FP64计算相同的结果。而在英伟达于次年推出“Ampere”GA100 GPU之前,我们再次进行一番HPC与AI的处理性能尝试。当时英伟达还没有推出“Ampere”A100 GPU,所以显卡巨头尚未正式朝着在混合精度张量核心上训练AI模型的方向倾斜。现在的答案当然已经明了,FP64矢量单元上的HPC工作负载需要做点架构调整才能发挥GPU性能,毫无疑问有点“二等公民”的意思了。但在当时,一切还皆有可能。
随着英伟达在今年早些时候推出“Hopper”GH100 GPU,AI与HPC的代际性能改进幅度出现了更大的差距。不仅如此,在最近的秋季GTC 2022大会上,英伟达公司联合创始人兼CET黄仁勋表示,AI工作负载自身也出现了分歧,也迫使英伟达开始探索CPU业务——或者更准确地说,应该叫面向GPU的优化扩展内存控制器。
稍后我们会具体讨论这个问题。
花开两朵,各表一枝
让我们先从最明确的判断说起。如果英伟达想让自己的GPU拥有更强的FP64性能,用以支持天气建模、流体动力学计算、有限元分析、量子色动力学及其他高强度数学模拟等64位浮点HPC应用,那加速器的设计思路应该是这样的:制造一款不设任何张量核心、也不设FP32 CUDA核心(在CUDA架构中主要作为图形着色器)的产品。
但这样的产品恐怕只有几百家客户愿意采购,所以单芯片价格可能在数万甚至数十万美元,只有这样才能覆盖掉设计和制造成本。为了建立起规模更大、而且更具利润空间的业务,英伟达必须设计出更加通用的架构,其矢量数学运算能力只要比CPU强就够了。
所以自从英伟达15年前决定认真为HPC应用设计产品开始,他们就一直专注于使用FP32浮点数学运算的HPC场景——包括地震处理、信号处理和基因组学类负载中使用的单精度数据和处理任务,并逐步提升GPU的FP64功能。
2012年7月推出的K10加速器搭载两个“Kepler”GK104 GPU,与游戏显卡中使用的GPU完全相同。其中设有1536个FP32 CUDA核心,没采用任何专用FP64核心。它的FP64支持纯由软件完成,因此无法实现可观的性能提升:双GK104 GPU在处理FP32任务时性能为4.58 teraflops,而在处理FP64时为190 gigaflops,比率为24比1。而在2012年底的SC12超级计算大会上发布的K20X则采用GK110 GPU,FP32性能为3.95 teraflops,FP64性能为1.31 teraflops,比率提升至3比1。到这个时候,该产品对HPC应用程序以及在学术/超大规模计算领域训练AI模型的用户来说,已经初步具备了可用性。K80 GPU加速卡采用两个GK110B GPU,这是因为英伟达并没有为当时最高端的“Maxwell”GPU添加FP64支持,因此GK110 B就成了当时广受欢迎、最具性价比的选项。K80的FP32性能为8.74 teraflops,FP64性能则为2.91 teraflops,比率仍然保持为3比1。
到“Pascal”GP100 GPU,HPC与AI的差距随FP16混合精度指标的引入而进一步拉开,不过矢量FP32与矢量FP64的比例进一步转化为2比1,而且在“Volta”GV100之后的“Ampere”GA100和“Hopper”GH100等更新GPU中得到了保持。在Volta架构中,英伟达首次引入了具有固定矩阵磊小的张量核心(Tensor Core)矩阵数学单元,显著提升了浮点(及整数)运算能力,并继续在架构中保留矢量单元。
这些张量核心被用于处理越来越大的矩阵,而具体运算精度却越来越低,于是这类设备获得了极为夸张的AI负载吞吐量。这当然离不开机器学习自身的模糊统计性质,同时也跟多数HPC算法要求的高精度数学拉开了巨大差距。下图所示为AI和HPC性能差距的对数表示,相信大家已经能够看到二者间的趋势性差异:
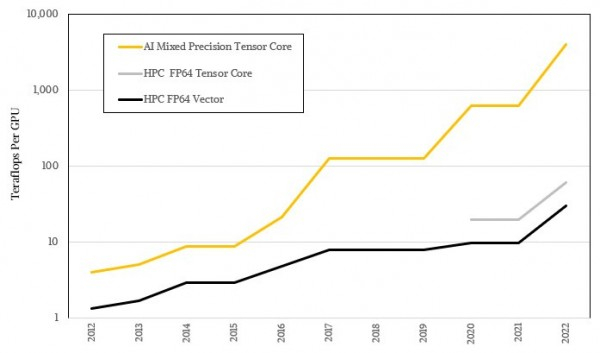
对数形式看着不够震撼,咱们用实际比例再看一遍:
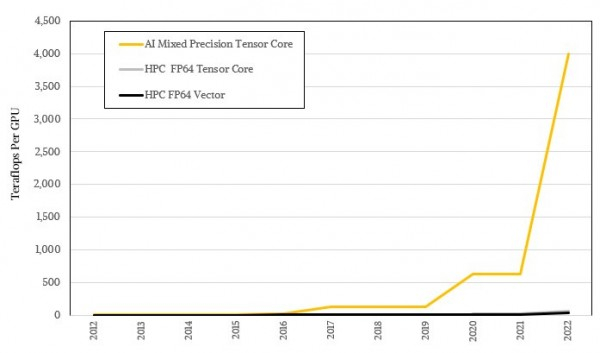
系统设计的艺术:当HPC与AI应用成为主流,GPU架构该向何处去?
并不是所有HPC应用都能针对张量核心进行调整,也不是一切应用程序都能把数学运算移交给张量核心,所以英伟达的GPU架构中仍然保留着一些矢量单元。另外,很多HPC组织其实拿不出像HPL-AI那样的迭代求解器。Linpack基准测试中使用的就是HPL-AI求解器,它采用常规HPL Linpack并配合FP16加FP32运算,再辅以一点点FP64运算来收敛至与纯FP64蛮力计算相同的答案。这种迭代求解器能够在橡树岭国家实验室的“Frontier”超级计算机上提供6.2倍的有效加速,并在RIKEN实验室的“富岳”超级计算机上实现4.5倍的有效加速。如果能有更多HPC应用程序迎来属于自己的HPL-AI类求解器,那AI跟HPC“分家”的难题也就有解了,相信这一天终会到来。
但与此同时,对于很多工作负载,FP64性能仍然是唯一的决定性因素。而凭借强大AI算力赚得盆满钵满的英伟达,短时间内肯定没太多闲心照顾HPC这块市场。
花再开两朵,再各表一枝
可以看到,英伟达的GPU架构主要追求更高的AI性能,同时保持可接受的HPC性能,双管齐下引导客户每三年更新一次硬件。从纯FP64性能的角度来看,在2012年至2022年这十年间,英伟达GPU的FP64吞吐量增长了22.9倍,从K20X的1.3 teraflops到H100的30 teraflops。如果能配合迭代求解器用上张量核心矩阵单元,那增幅则可达到45.8倍。但如果是只需要低精度大规模并行计算的AI训练用户,那从FP32到FP8的性能转变就夸张了,已经由最早的3.95 teraflops FP32算力提升至FP8稀疏矩阵的4 petaflops,也就是提高了1012.7倍。而如果是在当时的K20X GPU上用FP64编码的AI算法来比较(当时的主流作法),那这十年间的性能提升只有可怜的2倍。
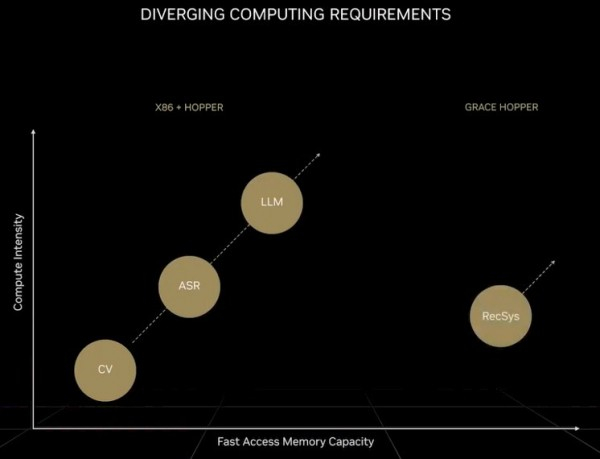
很明显,二者的性能差异已经不能用巨大来形容了。黄仁勋自己也提到,目前的AI阵营本身再次一分为二。一类是基于transformer模型支持的巨型基础模型,也被称为大语言模型。这类模型的参数数量迅猛增长,对硬件的需求也不断提升。与之前的神经网络模型相比,如今的transformer模型完全代表着另一个时代,如下图所示:

请原谅这张图有点模糊,但重点在于:对于第一组不包含transformers的AI模型,计算需求在两年之内增长了8倍;但对于包含transformers的AI模型,其计算需求在两年内增长了275倍。如果用浮点运算来处理,那系统中得有10万个GPU才能满足需求(这还不是太大的问题)。但转向FP4精度会把计算量翻倍,未来GPU采用1.8纳米晶体管时算力又能增加2.5倍左右,所以还是余下了55倍左右的差距。要是能实现FP2运算的话(假设这样的精度足够解决问题)倒是可以把计算量减半,但那也至少得使用25万个GPU。而且,大语言transformer模型往往很难扩展,特别是不具备经济意义上的可行性。所以这类模型就成了巨头级企业的专属,就如同核武器只会被掌握在强国手中一样。
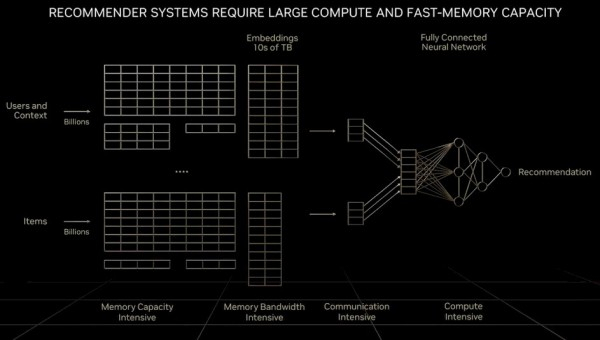
至于作为“数字经济引擎”的推荐系统,它需要的不只是成倍增加的计算量,还需要远超大语言模型、甚至是GPU所能提供内存容量的数据规模。黄仁勋在之前的GTC主题演讲中就曾提到:
“与大语言模型相比,各个计算单元在处理推荐系统时面对的数据量要大出一个量级。很明显,推荐系统不仅要求内存速度更快,而且需要10倍于大语言模型的内存容量。虽然大语言模型随时间推移而保持着指数增长、对算力的需求一刻不停,但推荐系统也同样保持着这样的增长速度,而且不断吞噬更多内存容量。大语言模型和推荐系统可以说是当下最重要的两类AI模型,而且有着不同的计算要求。推荐系统可以扩展至数十亿用户与数十亿个条目,每篇文章、每段视频、每个社交帖都有对应的数字表示,被称为嵌入。每个嵌入表可能包含数十TB的数据,需要由多个GPU协同处理。在处理推荐系统时,既要求网络中的某些部分实现数据并行处理,又要求网络中的其他部分实现模型并行处理,这就对计算机中的各个部分提出了更高要求。”
下图所示,为推荐系统的基本架构:
为了解决定特殊的内存容量与带宽问题,英伟达开发出了“Grace”Arm服务器CPU,并将其与Hopper GPU紧密耦合。我们也开玩笑说,如果需要的主内存量十分巨大,那Grace实际上只是Hopper的内存控制器。但从长远来看,也许把一堆运行有NVLink协议的CXL端口挂入Hooper的下一代GPU就行。
所以英伟达拿出的Grace-Hopper超级芯片,就相当于把一个“儿童”级CPU集群放进了巨大的“成人”级GPU加速集群。这些Arm CPU倒是可以支持传统的C++和Fortran工作负载,但代价是:混合集群当中CPU部分的性能,只相当于集群中GPU性能的十分之一,而成本却是常规纯CPU集群的3到5倍。
顺带一提,我们对于英伟达所做的任何工程选择都尊重且理解。Grace是一款出色的CPU,Hopper也是一款出色的GPU,二者相结合肯定会有不错的效果。但现在的情况是,我们在同一平台上面对着三种截然不同的工作负载,它们各自把架构拉向不同的方向。高性能计算、大语言模型和推荐系统,这三位老哥各有特点,根本没法以符合经济效益的方式同时进行架构优化。
而且很明显,AI这边的优势很大、HPC则逐渐势微,这种状况已经持续了近十年。如果HPC想要完成自我改造,那么其代码就得朝着推荐系统和大语言模型靠拢,而不能继续坚持在FP64上运行现有C++和Fortran代码。而且很明显,跟AI客户相比,HPC客户的每一次运算都有溢价。所以除非HPC专家们摸清了迭代求解器的普适性开发方式,能够以较低的精度对物理世界进行建模,否则这种被动局面将很难得到扭转。
几十年来,我们一直觉得大自然本身其实是不符合数学规律的。我们是在被迫用高精度数学来描述大自然的效应,或者说在用并不适合的语言描述客观现实。当然,大自然也许比我们想象中的更精妙,而迭代求解器反而更接近我们所要建模的现实。如果真是如此,那也许是人类的一种幸运,甚至要比十年前HPC和AI的偶然重合更幸运。
毕竟世上本没有路,走的人多了,也便成了路。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK