

从手工作业到工业革命!Nature文章:生物图像分析被深度学习彻底改变的五个领域
source link: https://www.51cto.com/article/720537.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

从手工作业到工业革命!Nature文章:生物图像分析被深度学习彻底改变的五个领域
一立方毫米,听起来不大,也就是一粒芝麻的大小,但在人类的大脑中,这点儿空间却能够容纳由1.34亿个突触相连接的大约5万条神经线(neural wires)。
为了生成原始数据,生物科学家需要使用连续超薄切片电镜的方法,在11个月内对数以千计的组织碎片进行成像。
而最终获得的数据量也达到了惊人的1.4 PetaBytes(即1400TB,相当于大约200万张CD-ROM的容量) ,对于研究人员来说这简直就是个天文数字。
哈佛大学的分子和细胞生物学家Jeff Lichtman表示,如果用纯手工作业,人类根本不可能手动追踪所有的神经线,地球上甚至都没有足够多的人能够真正有效地完成这项工作。
显微镜技术的进步带来了大量的成像数据,但数据量太大,人手不足,这也是连接组学(Connectomics,一门研究大脑结构和功能连接的学科),以及其他生物领域学科中的常见现象。
但计算机科学的使命正是为解决这类人力资源不足的问题,尤其是经过优化的深度学习算法,可以从大规模数据集中挖掘出数据模式。
麻省理工学院布罗德研究所和哈佛大学剑桥分校的计算生物学家Beth Cimini表示,过去几年中,深度学习在生物学领域有着巨大的推动作用,并开发了很多研究工具。
下面是Nature编辑总结深度学习带来变革的五个生物学图像分析领域。
大规模连接组学
深度学习使研究人员能够从果蝇、老鼠甚至人类身上生成越来越复杂的连接体。
这些数据可以帮助神经科学家理解大脑是如何工作的,以及大脑结构在发育和疾病过程中是如何变化的,但神经连接并不容易绘制。
2018年,Lichtman与谷歌在加州山景城的连接组学负责人Viren Jain联手,为团队所需的人工智能算法寻找解决方案。
连接组学中的图像分析任务实际上是非常困难的,你必须能够追踪这些细线、细胞的轴突和树突,还要跨越很长的距离,传统的图像处理方法在这项任务中会出现很多错误,基本上对这项任务没有用处。
这些神经线可能比一微米还细,延伸数百微米甚至跨越毫米级的组织。
而深度学习算法不仅能够自动化地分析连接组学数据,同时还能保持很高的精度。
研究人员可以使用包含感兴趣特征的标注数据集来训练复杂的计算模型,以便能够快速识别其他数据中的相同特征。
欧洲分子生物学实验室的计算机科学家Anna Kreshuk认为,使用深度学习算法的过程类似于「举个例子」,只要例子够多,你就能把所有问题都解决掉。
但即使是使用深度学习,Lichtman和Jain团队还要完成一项艰巨的任务:绘制人类大脑皮层的片段。
在收集数据阶段,仅仅拍摄5000多个超薄的组织切片就花了326天。
两名研究人员花了大约100个小时来手动标注图像和追踪神经元,创建了一个ground truth数据集以训练算法。
使用标准数据训练后的算法就可以自动将图像拼接在一起,识别出神经元和突触,并生成最终的连接体。
Jain的团队为解决这个问题也投入了大量的计算资源,包括数千个张量处理单元(TPU) ,还耗费了几个月时间来预处理100万TPU小时所需的数据。
虽然研究人员已经获取到当下能收集到最大规模的数据集,能够在非常精细的水平进行重建,但这个数据量大约只占人类大脑的0.0001%
随着算法和硬件的改进,研究人员应该能够绘制出更大的大脑区域,同时能够分辨出更多的细胞特征,比如细胞器,甚至蛋白质。
至少,深度学习提供了一种可行性。
虚拟组织学
组织学(histology)是医学上的一个重要工具,用于在化学或分子染色的基础上诊断疾病。
但是整个过程费时费力,通常需要几天甚至几周的时间才能完成。
先将活组织检查切成薄片,染色显示细胞和亚细胞特征,然后病理学家通过阅读结果并对之进行解释。
加州大学洛杉矶分校的计算机工程师Aydogan Ozcan认为可以通过深度学习的方式对整个过程进行加速。
他训练了一个定制的深度学习模型,通过计算机模拟给一个组织切片上染色,将同一切片上数以万计的未染色和染色的样本喂给模型,并让模型计算出它们之间的差异。
虚拟染色除了有时间优势(瞬间就能完成)外,病理学家通过观察发现,虚拟染色和传统染色几乎毫无区别,专业人士也无法分辨。
实验结果表明,该算法可以在几秒钟内复制乳腺癌生物标志物HER2的分子染色,而该过程在组织学实验室通常需要至少24小时。
三位乳腺病理学家组成的专家小组对这些图像进行了评价,认为它们的质量和准确性与传统的免疫组织化学染色相当。
Ozcan看到了将虚拟染色商业化后在药物研发中的应用前景,但他更希望借此消除组织学对有毒染料和昂贵染色设备的需求。
如果你想从细胞图像中提取数据,那你必须知道细胞在图像中的实际位置,这一过程也称为细胞分割(cell segmentation)。
研究人员需要在显微镜下观察细胞,或者在软件中一张一张地勾勒出细胞的轮廓。
加州理工学院的计算生物学家Morgan Schwartz正在寻求自动化处理的方法,随着成像数据集变得越来越大,传统的手工方法也遇到了瓶颈,有些实验如果不自动化就无法进行分析。
Schwartz的研究生导师、生物工程师David Van Valen创建了一套人工智能模型,并发布在了deepcell.org网站上,可以用来计算和分析活细胞和保存组织图像中的细胞和其他特征。
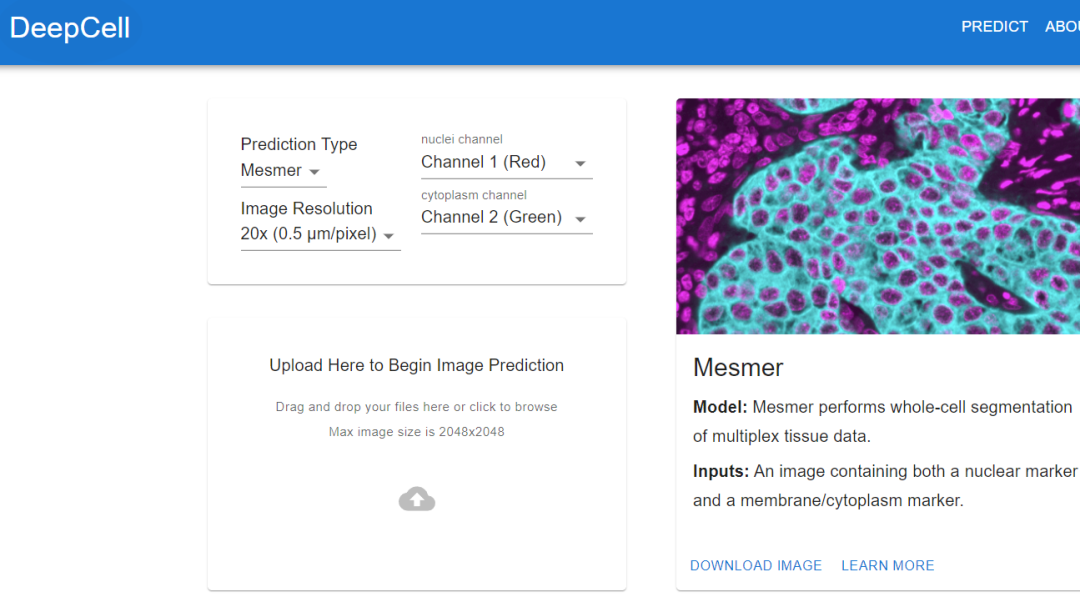
Van Valen与斯坦福大学癌症生物学家Noah Greenwald等合作者一起还开发了一个深度学习模型Mesmer,可以快速、准确地检测不同组织类型的细胞和细胞核。
据Greenwald说,研究人员可以利用这些信息来区分癌症组织和非癌组织,并寻找治疗前后的差异,或者基于成像的变化来更好地了解为什么一些患者会有反应或者没有反应,以及确定肿瘤的亚型。
定位蛋白质
人类蛋白质图谱项目利用了深度学习的另一个应用:细胞内定位。
斯坦福大学的生物工程师Emma Lundberg表示,在过去几十年间,该项目生成了数百万张图像,描绘了人体细胞和组织中的蛋白质表达。
刚开始的时候,项目参与者需要手动对这些图像进行标注,但这种方法不可持续,Lundberg开始寻求人工智能算法的帮助。
过去几年,她开始在Kaggle挑战赛中发起众包解决方案,科学家和人工智能爱好者为了奖金会完成各种计算任务,两个项目的奖金分别为3.7万美元和2.5万美元。
参赛者会设计有监督的机器学习模型,并对蛋白质图谱图像进行标注。
Kaggle挑战赛获得的成果也让项目成员大吃一惊,获胜的模型性能比Lundberg先前在蛋白质定位模式的多标签分类方面要高出约20% ,并且可以泛化到细胞系(cell line)中,还取得了新的行业突破,对存在于多个细胞位置的蛋白质进行准确的分类。
有了模型,生物实验就可以继续推进,人类蛋白质的位置很重要,因为相同的蛋白质在不同的地方表现不同,知道一种蛋白质是在细胞核还是在线粒体中,这有助于理解它的功能。
追踪动物行为
Mackenzie Mathis是瑞士洛桑联邦理工学院校园生物技术中心的神经科学家,长期以来一直对大脑如何驱动行为感兴趣。
为此,她开发了一个名为DeepLabCut的程序,使神经科学家能够从视频中追踪动物的姿势和精细动作,并将「猫咪视频」和其他动物的记录转化为数据。
DeepLabcut提供了一个图形用户界面,研究人员只需点击一个按钮,就可以上传并标注视频并训练深度学习模型。
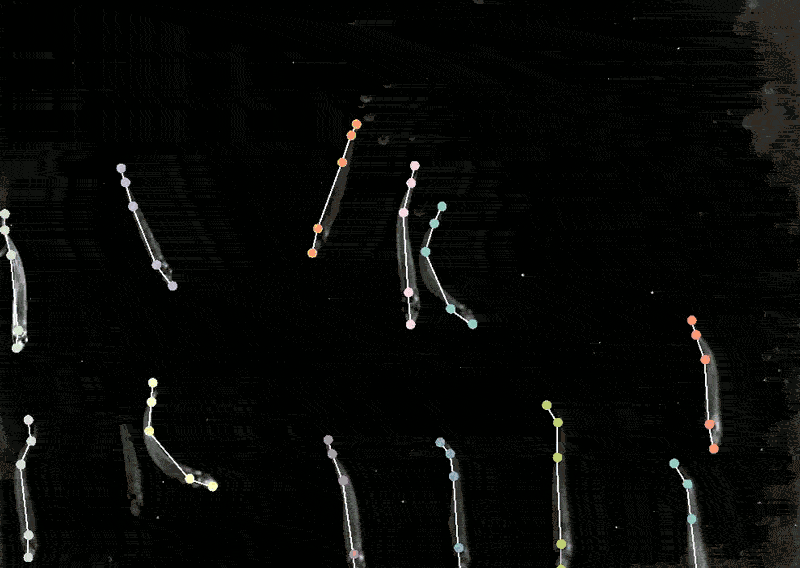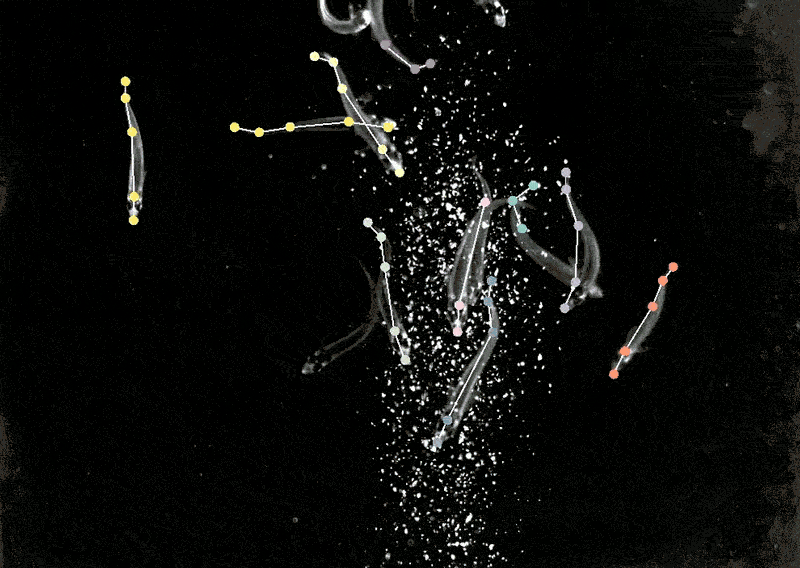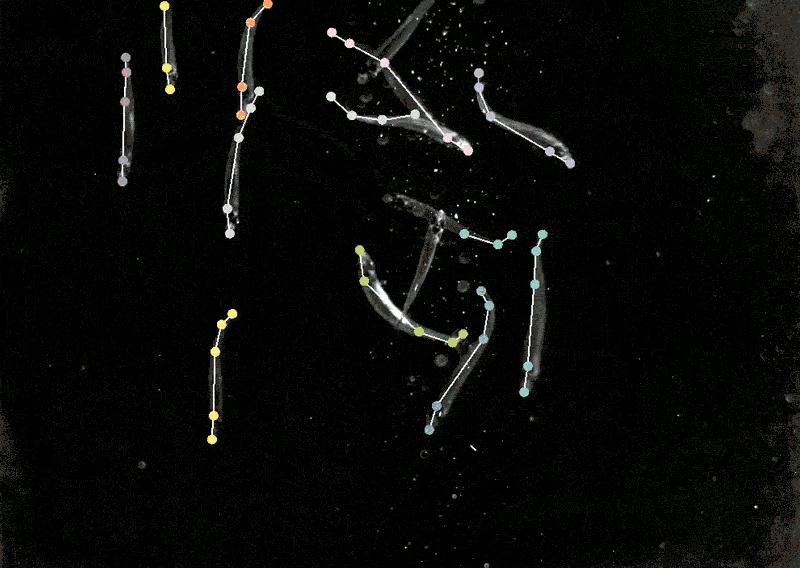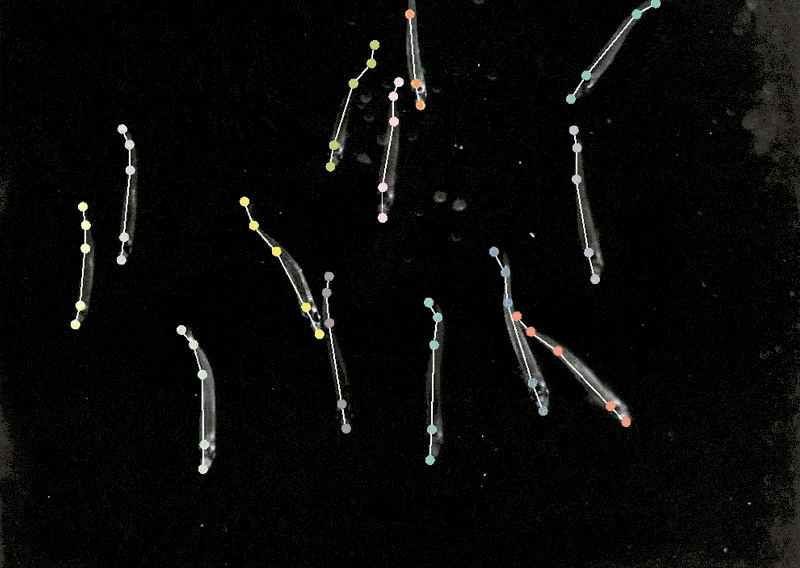
今年4月,Mathis的团队扩展了该软件,可以同时为多种动物估计姿势,这对人类和人工智能来说都是一个全新的挑战。
将DeepLabCut训练后的模型应用到狨猴身上,研究人员发现,当这些动物靠得很近时,它们的身体会排成一条直线,看向相似的方向,而当它们分开时,它们倾向于面对面。
生物学家通过识别动物的姿势,来了解两种动物是如何交互、注视或观察世界的。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK