
0

The Origin and Future Scope of MapReduce in Big Data
source link: https://www.analyticsvidhya.com/blog/2022/10/the-origin-and-future-scope-of-mapreduce-in-big-data/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

This article was published as a part of the Data Science Blogathon.
Introduction
In this digital age era, we are practically swimming in oceans of data. But how did we come to the forefront of this matter? Techniques like MapReduce and Hadoop have somewhat met our data needs; let’s go over some ideas and facts to consider when creating a holistic view of the world we currently inhabitant a fact that everyone is directly or indirectly dependent on data for most of the things we do today?
Let me help you; that little device in your hand, your smartphone, is just another example of you consuming data from different sources. That is not the point, but the question is how the data is processed to be valuable and meaningful to us.
The Current Data Landscape
The advancement in the Internet of Things and some other latest technologies increases concerns about data. Data growth is outpacing the capabilities of traditional computers. Many sources predict exponential data growth through 2020 and beyond. Yet everyone agrees that the size of this digital ocean will double every two years, a 50-fold increase from 2010 to 2020. Human and machine-generated data are collectively experiencing a 10x faster growth rate than traditional business data. And machine data is increasing even faster at a 50x growth rate.
Source: Mapper and Reducer in Big Data
How can we harness these vast data sources and turn them into actionable information? Capturing and analyzing data and transforming it into meaningful insights is a complex workflow that moves beyond data centers to the cloud with a seamless hybrid environment. In addition, the concept of “Big data” has evolved and gained immense recognition as the nature of data has changed from structured to unstructured. Find valuable insights – trends and patterns that can help businesses, research, industry, and humanity. Many techniques have emerged as part of the solution; a few have gained acceptance, while others have been abandoned. So it is very important to adopt the current state of affairs as it becomes paramount to perfect our situation for the materializing reality.
Big Data Image: The Origin of MapReduce
Big data has emerged as a concrete concept and is flourishing, but its origins are uncertain. Diebold (2012) argues that the term “big data” probably originated in lunch conversations at Silicon Graphics Inc. However, technically, big data is meaningless in a vacuum. Its true potential is only known when it is used to make decisions. Organizations need efficient processes to enable such evidence-based decision-making to transform large volumes of fast-moving and diverse data into meaningful insights.
Undoubtedly, techniques like RDBMS, Grid computing, etc., have contributed invaluably to the processing of big data, but they did not fit as a solution. Thus, new techniques to process big data gave rise to various other techniques. The most popular technique is MapReduce, which implements the concept of Map and Reduce using MapReduce programming. Let’s see. Take a look at what led to the development of MapReduce programming.
MapReduce: The Evolution
It was the early 1990s when the Internet was in full bloom; with the advent of Bigdata, MapReduce proved to be the most efficient solution. Let’s see. Look at the timeline of what and how the MapReduce technique has evolved.
Evolutionary Timeline:
1997: Doug Cutting, Yahoo! An employee started writing the first version of Lucene (used for indexing web pages).
2001: Lucene was open-sourced; University of Washington graduate Mike Cafarella teamed up with Dough Cutting to index the entire web; their efforts spawned a new Lucene subproject called Apache Nutch.
While indexing, Cutting, and Cafarella encountered the following problems with the existing file system:
- In schema availability (no concept of rows and columns)
- Missing Endurance (should never be lost once written)
- Failure to withstand faults (CPU, memory, network)
- Non-automated rebalancing (uses disk space)
2003: With the concept of Google File System (GFS) and Java, a new file system was created, which was called NDFS (Nutch Distributed File System).
It fixed several issues, but the following issues were still not resolved:
- Perseverance
- Fault tolerance
To solve these problems, the idea of distributed processing arose. In implementing this, there was a need for an algorithm for NDFS that would integrate parallel processing running on multiple nodes simultaneously.
2004: A paper is Published by google of the name MapReduce; Simple data processing on large clusters. The algorithm mentioned in the article solved problems like:
- Parallelization
- Distribution
- Fault tolerance
The MapReduce technique has evolved as a framework for writing applications that process huge amounts of structured and unstructured data. The word MapReduce is made up of two distinct words, “Map” “and “Re “use.”
In the next part, we demystify what it is. And what is it for?
What is MapReduce?
The MapReduce technique is a linearly scalable programming model implemented using MapReduce programming. To simplify the above statement, MapReduce is a framework for writing applications that process huge amounts of data (multiterabyte datasets and more) in parallel on large clusters (thousands of nodes and more) of commodity hardware in a reliable and fail-safe manner. – tolerant way.
The Programming is based on functions like:
- Map function
- A Reduction function.
Each function defines a mapping from a set of key-value pairs to another. The key-value pair (KVP) is a set of two linked data items:
- Key: It is a unique identifier for some data items and
- Value: This can be one of the following, the data found and a pointer to the location of that data.
These functions do not know the data size or the cluster that runs on. Functions work well for both types of datasets, whether small or massive. If the size of the input data increases, the job will run twice as slowly. But if you double the cluster size, the job will run as fast as the original.
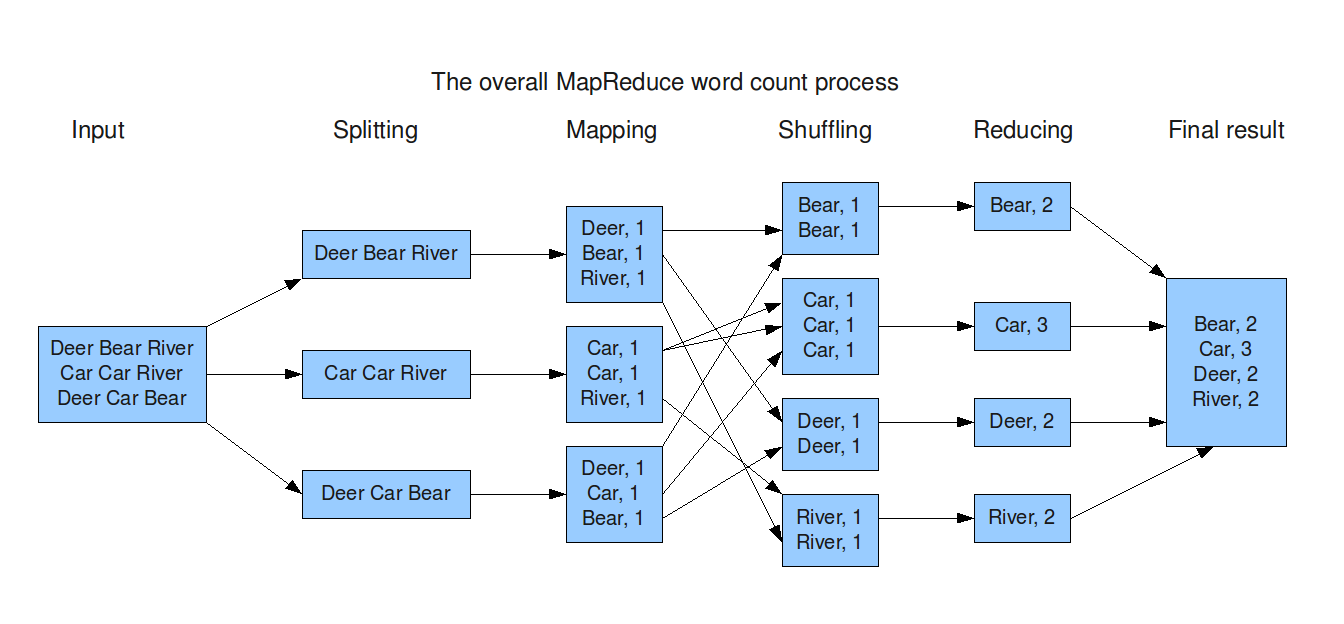
MapReduce: Workflow
Overall, the MapReduce program consists of two phases:
Map Stage:
- The master node takes the input.
- Breaks down the input into smaller subproblems.
- The master node distributes these smaller subproblems to the worker nodes.
- The worker node can do this again, resulting in a multi-level tree structure.
- A worker node processes a smaller problem.
- It forwards the response back to its master node.
Reduction phase:
1. The master node collects the answers to all the subproblems given by the worker nodes.
2. It combines all the answers and forms the output of the original problem
The detailed steps in the MapReduce technique are as follows:
1. Map input preparation: The system selects the map processors, distributes an input key-value pair K1 to work on, and provides that processor with all the input data associated with that key value.
2. Run the user-provided map code ().
3. Execute the Map() code exactly once for each K1 key value and generate output organized by K2 key values.
4. Shuffle map output () into Reduce processors; the MapReduce system selects Reduce processors, assigns a K2 key value to work with, and provides that processor with any Map() generated data associated with that key value.
5. Run the Reduce() code provided by the user – Reduce() is executed exactly once for each K2 key value created in the Map step.
6. To Produce the final output, the MapReduce system collects all the output generated by reducing () and sorts it by the key value of K2 to produce the final result.
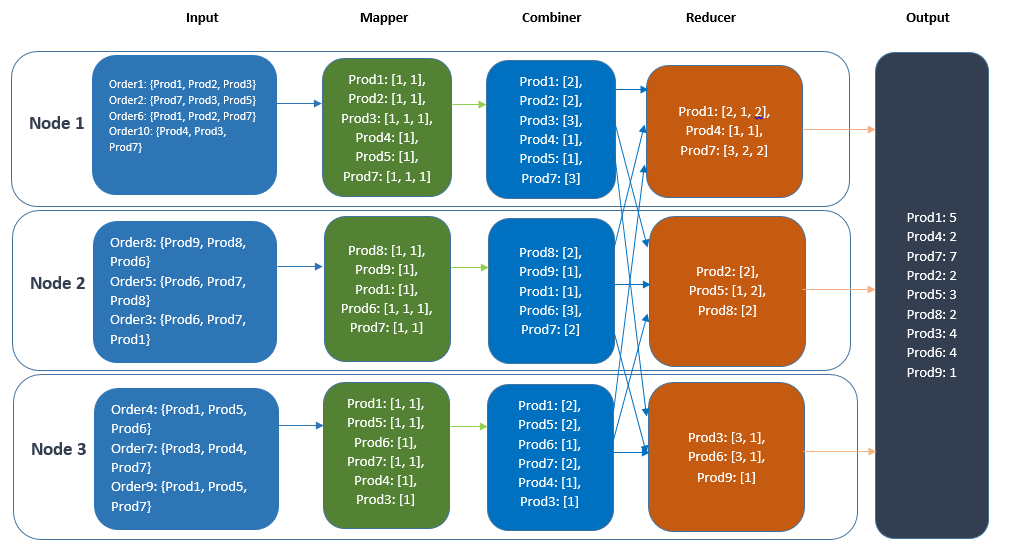
How does MapReduce work?
An example of laptops for sale in the store:
1. Apple, Hp, Lenovo, Fujitsu, Sony, Samsung, Asus
The two datasets with different combinations of laptops are:
1. Data set 1: Asus, Sony, Lenovo, Lenovo, Fujitsu, Hp, Sony, Apple, Samsung
2. Dataset 2: Asus, Fujitsu, Lenovo, Asus, Hp, Sony, Hp, Apple, Asus
Map step
For each record in the dataset, a map (string key, string value), i.e., map (k1, v1)–> list (k2, v2), is created as follows:
1. Asus Sony Lenov” {(“”s” s”,”1”” , (””o” y”,”1”” , (”Le”o” o”,”1”)}
2. Lenovo Fujitsu Hp {(“Lenovo”,”1”), (“Fujitsu”,”1”), (“Hp”,”1”)}
3. Sony Apple Samsun” {(“”o” y”,”1””, (“A”p” e”,”1”” , (”Sam”u” g”,”1”)}
4. Asus Fujitsu Lenov” {(“”s” s”,”1””, (“Fuj”t” u”,”1””, (“Le”o” o”,”1”)}
5. Asus Hp Sony {(“Asus”,”1”), (”Hp”,”1”), (“Sony”,”1”)}
6. Hp Apple Asu” {““” p”,”1””, (“A”p” e”,”1””, (“”s” s”,”1”)}
Nelet’set’s see what is done in the reduce step:
Reduce step
For each of the above map results, the obtained reduce(string key, iterator values), i.e., reduce(k2, list(v2))–>list(v2), is as follows:
1. reduce(“Apple”, )-> 2
2. decrease (“Hp”, )–>3
3. reduce(“Nokia”, )–> 4
4. reduce (“Fujitsu”, )–>2
5. reduce (“Sony”, )–>3
6. reduce (“Samsung”, )–>1
7. reduce(“Asus”, )–> 4
Solving basic computer sales is easy with MapReduce programming. MapReduce programming is at the core of the distributed programming model in many applications for solving big data problems in various real-world industries. There are many challenging problems, such as data analysis, log analysis, recommendation engines, fraud detection, and user behavior analysis, which MapReduce fits as a practical solution.
Applications of MapReduce
functionalities of parallel processing of massive data have resulted in the implementation of MapReduce in various data-intensive environments and used in various industries.
1. Distributed pattern-based search: Using the distributed grep command provided by MapReduce to search for a pattern in a given text distributed over a network.
2. Geo-spatial query processing: With technological advancements in location-based services, MapReduce helps to find the shortest route in the Google map for a given location.
3. Distributed Sort: Using distributed sort in MapReduce to arrange data in a sorted manner distributed among multiple locations.
4. Web Link Graph Traversal: Solving a large graph, also known as a web graph, using MapReduce programming.
5. Machine Learning Applications: MapReduce helps machine learning because it helps build systems that learn from data without requiring explicit programming for all conditions.
6. Data Clustering: Using MapReduce in data clustering to solve the computational complexity that arises due to the voluminous data used in processing by dividing complete data sets into small subsets of data based on certain criteria and many other applications.
Future Scope
1. Framework MapReduce with other technologies will bring new and more accessible programming techniques for working on massive data stores with structured and unstructured data.
2. Many organizations are in the process of inventing, so expect different MapReduce frameworks with added features in the coming years.
3. Much research is going on to extend MapReduce with new features and mechanisms to improve it for a new set of problems.
4. MapReduce seems to be increasing with complex solutions for everyday data problems.
5. Every parallel technology has demands for scalability. MapReduce with additional implementations has real scalability since the last version, extending the node limit to more than 4,000.
Conclusion
Highly scalable data storage with a good parallel programming model has been a challenge for the industry for some time. Meanwhile, it is not wrong to say that the MapReduce programming model does not solve all problems. Nevertheless, it is a powerful solution for many data and related tasks. Finally, the future is such that data needs change over time as our world rapidly approaches the extremes of digitization.
- Big data has emerged as a concrete concept and is flourishing, but its origins are uncertain. Diebold (2012) argues that the t “rm “big data probably originated in lunch conversations at Silicon Graphics Inc. However, technically, big data is meaningless in a vacuum.
- The advancement in the Internet of Things and some other latest technologies increases concerns about data. Data growth is outpacing the capabilities of traditional computers. Many sources predict exponential data growth through 2020 and beyond.
- Using MapReduce in data clustering to solve the computational complexity that arises due to the voluminous data used in processing by dividing complete data sets into small subsets of data based on certain criteria and many other applications.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Related
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK