

【2-9 Golang】Go并发编程—并发编程
source link: https://studygolang.com/articles/35894
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

【2-9 Golang】Go并发编程—并发编程
tomato01 · 大约1小时之前 · 73 次点击 · 预计阅读时间 9 分钟 · 大约8小时之前 开始浏览Go语言为我们提供了基于消息传递CSP并发模型,基于管道 + 协程可以很方便的编写高并发服务,但是在某些场景下,或多或少还是需要使用到锁,本篇文章主要介绍除了管道chan之外的常见并发编程模式。
原子操作 atomic
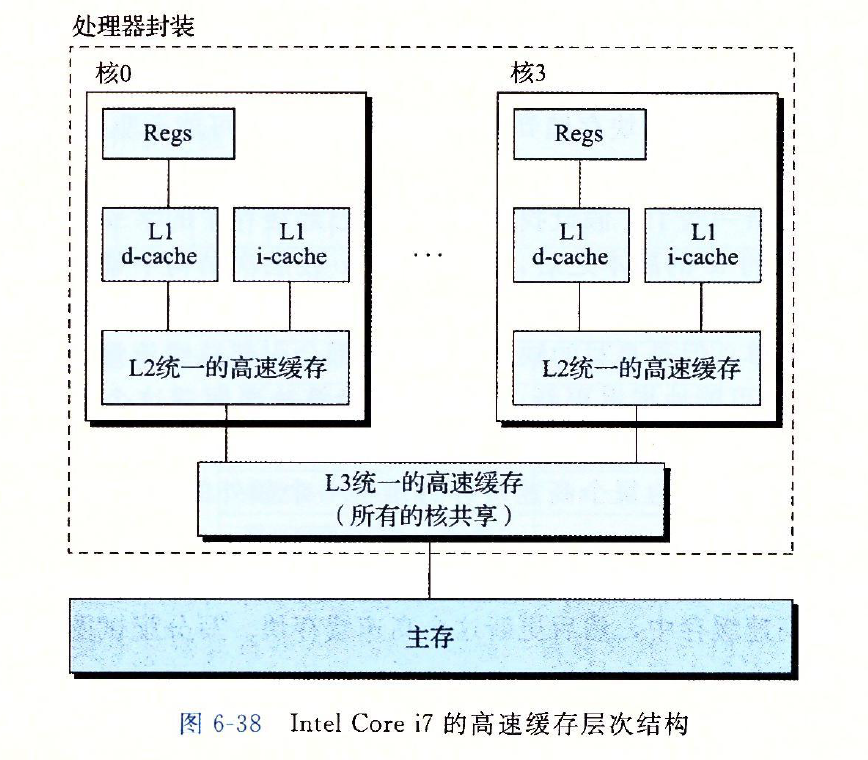
现代计算机都是多核CPU,每个CPU还有自己的高速缓存,主存中部分数据会被缓存在高速缓存中,CPU访问数据时会先从高速缓存中查找。那假如同一块内存地址同时被缓存在核0与核1的L2级高速缓存呢?此时如果核0与核1同时修改该地址内容,则会造成冲突。(参考深入理解计算机系统第六章,以Intel Core i7处理器为例,其有四个核,且每个核都有自己的L1和L2高速缓存)。
平常我们以为的一些原子操作(不会有并发问题的操作),如赋值操作,取值操作等,在多核CPU架构下都有可能产生并发问题;另外还有一些常见语句,如a += b等也有并发问题。所以在某些场景,我们需要想办法避免并发问题,怎么办呢?Go语言sync/atomic包为我们提供了一些常见的原子操作,使用这些方法不用担心并发问题。
//数据加载
func LoadInt32(addr *int32) (val int32)
//数据保存
func StoreInt32(addr *int32, val int32)
//比较交换操作,如果addr地址的数据等于old,则赋值为new
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
//addr地址的数据累加加delta
func AddInt32(addr *int32, delta int32) (new int32)
这些方法底层是怎么实现的呢?数据加载与保存还好理解一些,比较交换以及数据累加,编译成汇编指令后,明显需要好几步操作才能完成,怎么做到原子的呢?其实还有一些我们不知道的指令,语义上虽然比较复杂,但却是一条指令:
/*
* 比较交换指令
* "cmpxchgl r, [m]":
*
* if (eax == [m]) {
* zf = 1;
* [m] = r;
* } else {
* zf = 0;
* eax = [m];
* }
*/
/* 累加指令
* "xaddl r, [m]":
*
* temp = [m];
* [m] += r;
* r = temp;
*/
那上面提到的高速缓存的问题怎么解决呢?目前处理器都提供有lock指令;其可以锁住总线,其他CPU对内存的读写请求都会被阻塞,直到锁释放;不过目前处理器都采用锁缓存替代锁总线(锁总线的开销比较大),即lock指令会锁定一个缓存行。当某个CPU发出lock信号锁定某个缓存行时,其他CPU会使它们的高速缓存该缓存行失效,同时检测是对该缓存行中数据进行了修改,如果是则会写所有已修改的数据;当某个高速缓存行被锁定时,其他CPU都无法读写该缓存行;lock后的写操作会及时会写到内存中。
结合这些知识,实现这些原子操作就非常简单了,参考Go语言CompareAndSwapInt32函数的汇编代码:
//runtime/internal/atomic/atomic_amd64.s
TEXT ·Cas(SB),NOSPLIT,$0-17
MOVQ ptr+0(FP), BX
MOVL old+8(FP), AX
MOVL new+12(FP), CX
//锁缓存行
LOCK
//比较交换
CMPXCHGL CX, 0(BX)
SETEQ ret+16(FP)
RET
锁 sync.Mutex
为什么需要锁呢?当然是为了解决并发问题,如多个协程同时操作同一个变量,这就不得不提一个经典的例子,多个协程累加公共变量,初始值为零,累加1w次,最终结果是什么呢?
package main
import (
"fmt"
"time"
)
var value = 0
func main() {
for i := 0; i <1000; i ++ {
go func() {
value ++
}()
}
//为了等待所有的子协程执行完毕
time.Sleep(time.Second * 10)
fmt.Println(value) //951,输出结果随机
}
明明启动了1000个协程,每个协程都对全局变量value+1,最终value的结果为什么是随机的呢?因为这1000个协程大概率是分配到多个CPU调度执行的,多个CPU并行访问内存变量,value ++操作还不是原子的(实际等于value = value + 1,编译成的汇编指令更是由好几条指令组成),而且每个CPU还有高速缓存的存在(CPU访问到的其实是内存变量的副本),所以当多个协程操作同一个变量时其结果是不确定的。
那如果确实需要多个协程访问同一个变量怎么办?这时候就需要加锁了,操作变量之前加锁,操作变量之后释放锁,锁保证了同一时刻只能有一个协程访问到这个变量:
package main
import (
"fmt"
"sync"
"time"
)
var value = 0
func main() {
lock := sync.Mutex{}
for i := 0; i <1000; i ++ {
go func() {
lock.Lock()
value ++
lock.Unlock()
}()
}
time.Sleep(time.Second * 10)
fmt.Println(value)
}
并发相关的一些工具基本都在sync包,sync.Mutex是一种常用的排他锁,常用来解决并发问题,其只有两个方法且使用非常简单,操作之前加锁lock.Lock(),操作时候释放锁lock.Unlock()。sync.Mutex继承自接口sync.Locker,我们简单了解下sync.Mutex.Lock的实现:
//父接口
type Locker interface {
Lock()
Unlock()
}
type Mutex struct {
//锁的状态
state int32
//信号量
sema uint32
}
func (m *Mutex) Lock() {
// 快速加锁:原子操作cas
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
// 加锁失败,再次慢慢加锁
m.lockSlow()
}
func (m *Mutex) Unlock() {
//快速释放锁
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
//释放失败,再次慢慢释放锁
m.unlockSlow(new)
}
}
注意到,加锁和释放锁的时候,都是先基于原子操作尝试一次(可能失败),失败后才会走到lockSlow函数,该函数核心逻辑是一个for循环,在锁已被其他协程抢占时尝试自旋(避免协程切换),自旋结束后再次尝试获取锁(基于cas),如果还是获取失败,则通过信号量m.sema抢占锁(类似于Semacquire)。
并发map sync.Map
map之前的章节我们已经介绍过,多个协程并发操作map时,可能会导致panic(fatal error: concurrent map writes),这是因为当我们并发写map时,可能导致意料之外的情况发生。那怎么解决呢?Go语言为我们提供了并发sync.Map,使用方式如下:
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var m = sync.Map{}
//创建10个协程
for i := 0; i <= 10; i ++ {
go func() {
//协程内,循环操作map
for j := 0; j <= 100; j ++ {
// 数据读取
v, ok := m.Load(fmt.Sprintf("test_%v", j))
if ok {
//数据写入
m.Store(fmt.Sprintf("test_%v", j), v.(int) + 1)
} else {
m.Store(fmt.Sprintf("test_%v", j), 0)
}
}
}()
}
//主协程休眠3秒,否则主协程结束了,子协程没有机会执行
time.Sleep(time.Second * 3)
fmt.Println(m.Load("test_0"))
}
那是不是每次操作之前都需要加锁呢?这样的话性能是不是会有所降低?这是肯定的,不过Go语言也通过"读写分离"方案(适合读多写少的场景),尽可能的减少锁的开销,如下是sync.Map的定义:
type Map struct {
//锁
mu Mutex
//只读的数据,相当于缓存
read atomic.Value // readOnly
//可写数据,访问需要加锁
dirty map[any]*entry
misses int
}
// readOnly结构定义,也是一个map
type readOnly struct {
m map[any]*entry
//dirty是否存在部分数据,在readonly不存在
amended bool // true if the dirty map contains some key not in m.
}
注意read是只读数据,相当于一份缓存数据,map的增删改依赖于dirty。这样区分之后,map的读写流程当然也需要改变了。
func (m *Map) Load(key any) (value any, ok bool) {
//加载只读数据
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 没有查到数据,dirty还有一些数据时readonly没有的
if !ok && read.amended {
//加锁
m.mu.Lock()
//再次尝试读取readonly
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
// 没有查到数据,dirty还有一些数据时readonly没有的
if !ok && read.amended {
e, ok = m.dirty[key]
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
return e.load()
}
//如果misses次数过多,将dirty数据加载到readonly
func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}
可以看到,读取操作优先查询readonly数据,因为不需要加锁,当然在多次操作之后readonly数据可能和dirty数据不一样,如果misses次数过多,会将dirty数据加载到readonly;另外在写数据时,如果readonly存在key,则尝试写readonly(基于cas,不需要加锁);如果写失败,再加锁,有兴趣的可以自己学习下sync.Map.Store函数的实现逻辑。
并发控制 sync.Waitgroup
设想有这么一个需求:业务需要从三个数据接口查询数据,而且这三个接口互不依赖,传统的编程方式可能就是顺序调用了,这样总的耗时是这三个接口耗时之和,在Go语言中,提供了并发控制sync.Waitgroup,使得我们可以并发请求三个接口,这时候总的耗时等于三个接口耗时的最大值。
package main
import (
"fmt"
"sync"
)
func main() {
//WaitGroup用于协程并发控制
wg := sync.WaitGroup{}
//启动10个协程并发执行任务
for i := 0; i < 10; i ++ {
//标记任务开始
wg.Add(1)
go func(a int) {
fmt.Println(fmt.Sprintf("work %d exec", a))
//标记任务结束
wg.Done()
}(i)
}
//主协程等待任务结束
wg.Wait()
fmt.Println("main end")
}
如上面程序所示,主协程启动了10个协程,但是必须等到10个协程都结束(相当于等待10个子协程请求接口返回响应结果)。sync.WaitGroup使用非常简单,只有三个API,Add方法标识子任务开启,Done方法标识子任务结束,主协程中使用Wait方法,等待所有子任务结束,否则主协程会一直阻塞在这里。
type WaitGroup struct {
// 64-bit value: high 32 bits are counter, low 32 bits are waiter count.
// 64-bit atomic operations require 64-bit alignment, but 32-bit
// compilers only guarantee that 64-bit fields are 32-bit aligned.
// For this reason on 32 bit architectures we need to check in state()
// if state1 is aligned or not, and dynamically "swap" the field order if
// needed.
state1 uint64
state2 uint32
}
sync.WaitGroup结构的定义非常简单,只有两个字段:一个表示并发任务数,一个表示等待者数量,分别用32bit整数表示,只不过在32-bit/64-bit架构下,由于内存对齐方式不太一样,两个字段的访问方式也不太一样。
sync.WaitGroup结构的API方法这里就不做过多介绍了,底层是基于前面介绍的原子操作(LoadUint64、AddUint64、CompareAndSwapUint64)实现的,有兴趣的可以自己学习研究(参考文件sync/waitgroup.go)。
并发检测 race
Go程序日常开发中,如果担心可能存在并发问题,可以使用-race检测潜在的并发问题,以上面的程序为例:
package main
import (
"fmt"
"time"
)
var value = 0
func main() {
for i := 0; i <1000; i ++ {
go func() {
value ++
}()
}
time.Sleep(time.Second * 10)
fmt.Println(value)
}
go run -race test.go
==================
WARNING: DATA RACE
Read at 0x0000011f48a8 by goroutine 8:
main.main.func1()
/test.go:13 +0x29
Previous write at 0x0000011f48a8 by goroutine 7:
main.main.func1()
/test.go:13 +0x44
Goroutine 8 (running) created at:
main.main()
/test.go:12 +0x39
Goroutine 7 (finished) created at:
main.main()
/test.go:12 +0x39
本篇文章重点介绍了Go语言原子操作,互斥锁,并发map以及并发控制的基本使用,当然还有部分并发包没有介绍,如条件变量(cyn.Cond),读写锁(sync.RWMutex)等等,这些有兴趣的可以自己学习研究。
有疑问加站长微信联系(非本文作者))

入群交流(和以上内容无关):加入Go大咖交流群,或添加微信:liuxiaoyan-s 备注:入群;或加QQ群:692541889
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK