

机器学习之旅--线性回归
source link: http://blog.linrty.com/2022/09/15/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E4%B9%8B%E6%97%85--%E7%BA%BF%E6%80%A7%E5%9B%9E%E5%BD%92/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

机器学习之旅--线性回归
阅读数:8次
通过吴恩达机器学习作业一熟悉线性回归的使用
使用一个变量实现线性回归,以预测食品卡车的利润。假设你是一家餐馆的首席执行官,正在考虑不同的城市开设一个新的分店。该连锁店已经在各个城市拥有卡车,而且你有来自城市的利润和人口数据。您希望使用这些数据来帮助您选择将哪个城市扩展到下一个城市。
数据集文件:ex1data1.txt
首先我们需要熟悉如何使用python的库进行数据的加载,使用到了python的pandas库,加载方式如下:
# 引入pandas库,别名pd
import pandas as pd
# 定义好文件路径,相对路径(推荐数据都放在同一个项目下)、绝对路劲都可
path = '.\data\ex1data1.txt'
# 开始加载数据,一般以表格的形式加载txt数据
# header 表示标题,如果没有标题就直接设为None就好了
# names给每一列添加一个表头
data = pd.read_csv(path,header = None, names = ['population','profit'])
我们通过散点图查看一下数据,通过matplotlib库进行绘制,以作业一中ex1的数据展示为例子
# 映入绘图库
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(6,4))
# scatter表示绘制散点图,两种访问数据的方式都可以
ax.scatter(data['Population'], data.Profit, label='Traning Data')
ax.legend(loc=2) # 2表示在左上角
ax.set_xlabel('Population') # x轴坐标标签
ax.set_ylabel('Profit') #y轴坐标标签
ax.set_title('Predicted Profit vs. Population Size') # 图标题
plt.show()

在机器学习的过程中我们会处理大量的数据,所以,如果我们通过循环的方式进行处理的话效率极其低下,通常我们会直接通过矩阵的运算来进行处理,所以需要一点点线性代数的知识,但也不多,了解矩阵的一些基本运算就OK了,在python中矩阵的运算如下
np.dot()
对于二维的array会计算真正意义上的矩阵点乘也就是线性代数中矩阵乘法的定义,对于一维array会计算两者的内积和,具体例子如下:
import numpy as np
array1 = np.array([[1, 2, 3], [4, 5, 6]])
array2 = np.array([[1, 2], [3, 4], [5, 6]])
# 我们可以很轻松的看出,array1是2*3的矩阵,array2是3*2的矩阵
# 需要注意矩阵点乘的基本前提要求(线代知识),即第一个矩阵的列要等于第二个矩阵的行
# 矩阵点乘的结果的行数由第一个矩阵的行数决定,列数由第二个矩阵的列数决定
# 另外np.dot如果第二个矩阵转置后符合点乘条件会自动对后面的矩阵进行转置(不转置不符合条件的前提下)
res = np.dot(array1, array2)
# array1.dot(array2) 也可
# array1 @ array2 也可
# 通过array1.shape可查看矩阵的行列数
print(res)
# [[22 28] [49 64]]
array1 = np.array([1, 2, 3])
array2 = np.array([4, 5, 6])
res = array1.dot(array2)
print(res)
# 32
Matrix
上面我们都是通过array来表示矩阵并直接通过array来进行矩阵的运算,在numpy库中还有matrix它属于array,所以它有array的所有属性,但是,它必须是二维的,而array可以是多维的,比如一维,三维等等,在matrix中的矩阵相乘可以直接使用*符号进行,并且可以使用.H属性直接得到原矩阵的共轭矩阵,.T可以得到转置矩阵(array中也可以)
单变量线性回归
使用一个变量实现线性回归,以预测食品卡车的利润,假设你是一家餐馆的首席执行官,正在考虑不同的城市开设一个新的分店。该连锁店已经在各个城市拥有卡车,而且你有来自城市的利润和人口数据。
假设(hypothesis)函数
通过题目我们可以知道,这是一个典型的回归问题,即我们通过之前的数据预测出一个准确的输出值,对于该题目就是利润,在列出假设函数之前我们先描述一些后面会使用到的符号
- m 代表训练集中给予我们的实例数量
- x 代表训练集中的特征矩阵(即输入参数)
- y 代表目标变量,即我们需要预测的值
- h 代表学习算法的解决方案或函数也成为假设
我们通过输入特征变量x进入h假设函数中输出预测值y,从而带到预测的效果
对于目前这个问题,我们可以先通过一条简单的直线来进行拟合它,即我们假设表达式为
由于这类问题的输入特征变量只有一个,因此也称这类问题为单变量线性回归问题
在python代码中我们通过矩阵来实现hθ(x)hθ(x)的计算如下:
def get_h(x, theta):
# 别忘记为x矩阵添加一列1用于θ_0
return x @ theta
代价函数(cost function)
函数我们已经准备好了,但是我们还需要另一个函数来评价我们的假设函数对数据拟合的好坏程度,因此我们引入一个代价函数类进行评判
假设我们已经拟合出了一个hθ(x)hθ(x),我们计算出hθ(x(i))hθ(x(i))与y(i)y(i)的距离,也就是我们的预测值与实际值的差距,因为有时我们会预测偏高,有时预测偏低,所以距离有正有负,所以我们对该距离进行平方处理,之后对所有的数据都进行检验算出一个差值平方,然后对其进行求和取平均,以此来评判我们假设函数的好坏。
在python代码中实现如下:
def get_cost(x, y, theta):
# 用于计算y的行数也就是实例数
m = np.size(y, 0)
num = h(x, theta)
res = (num.T @ num) / (2 * m)
return res
梯度下降(Gradient Descent)
我们知道了代价函数,那么我们的目的就是要让代价函数尽可能的小,才能让我们的目标函数拟合的效果更好,我们知道函数的导数可以用于求函数的极值,对于我们列出的函数,我们逐个对θθ进行分析,我们发现目标函数针对每个θθ都是一个二次函数,那么我们就可以确定,函数极值就是最值。并且我们知道函数的导数就是函数在此点的切线斜率,因此它从一定程度上呈现了我们下一步的走向(即往哪里迭代),我们再引入αα学习率来控制迭代的步子有多大。
求导后得出
因为我们的θ0θ0对应的x就相当于值为1,所以也可以写成θ1θ1的形式
代码实现:
def get_gradient(x, y, theta, alpha, times):
# times 迭代的次数
m = np.size(y, 0)
costs = np.zeros(times) # 记录每次迭代后的cost
for i in range(times):
temp = theta - (alpha / m) @ (x @ (x @ theta - y))
theta = temp
costs[i] = get_cost(x, y, theta)
# 输出最终的theta以及costs
return theta,costs
绘制图形查看
这里我们的alpha为0.1,tmes为10000
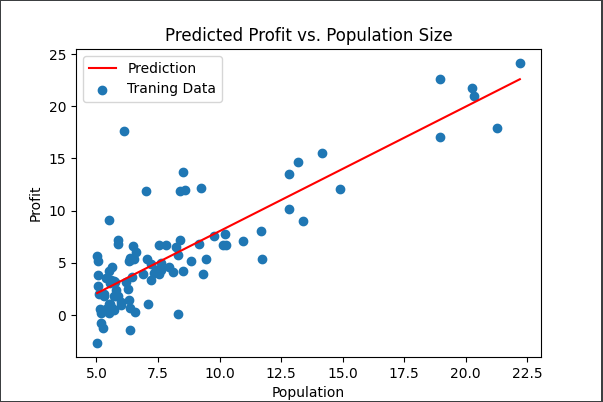
查看一下我们的拟合效果
fig, ax = plt.subplots(figsize=(6,4))
ax.plot(x, f, 'r', label='Prediction')
# 通过方括号和属性的方式均可
ax.scatter(data['Population'], data.Profit, label='Traning Data')
ax.legend(loc=2) # 2表示在左上角
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
plt.show()
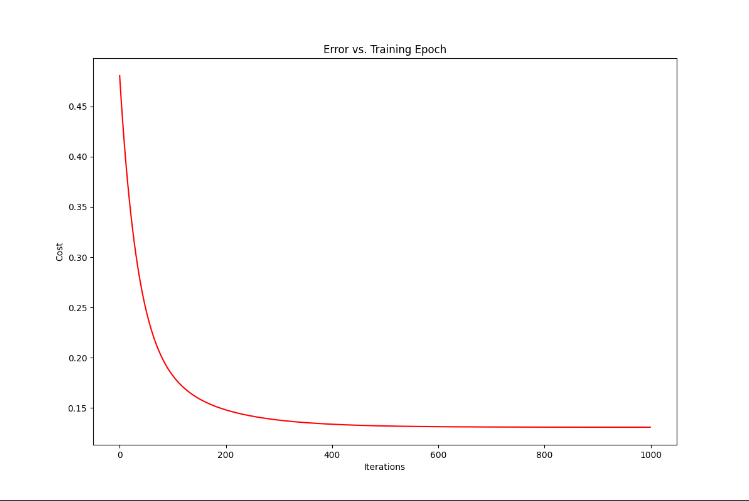
查看一下cost数值的变化过程
fig, ax = plt.subplots(figsize=(8,4))
ax.plot(np.arange(times), costs, 'r') # np.arange()返回等差数组
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title('Error vs. Training Epoch')
plt.show()

多变量线性回归
有2个变量(房子的大小,卧室的数量)和目标(房子的价格)
path = './code/ex1/ex1data2.txt'
data2 = pd.read_csv(path, names=['size', 'bedrooms', 'price'])
归一化操作
# 特征归一化
data2 = (data2 - data2.mean()) / data2.std()
多变量其实和单变量一样的,所以我们可以重复使用单变量中我们定义好的cost和gradient函数,执行的过程也与单变量的一直,因此这块代码就省略了
fig, ax = plt.subplots(figsize=(12, 8))
ax.plot(np.arange(epoch2), cost2, 'r') # np.arange()返回等差数组
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title('Error vs. Training Epoch')
plt.show()
本文链接: http://blog.linrty.com/2022/09/15/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E4%B9%8B%E6%97%85--%E7%BA%BF%E6%80%A7%E5%9B%9E%E5%BD%92/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK