

分布式存储系统之Ceph集群存储池、PG 与 CRUSH - Linux-1874
source link: https://www.cnblogs.com/qiuhom-1874/p/16733806.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

分布式存储系统之Ceph集群存储池、PG 与 CRUSH
前文我们了解了ceph集群状态获取常用命令以及通过ceph daemon、ceph tell动态配置ceph组件、ceph.conf配置文件相关格式的说明等,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/16727820.html;今天我们来聊一聊ceph的存储池、PG以及CRUSH相关话题;
一、关于存储池
我们知道ceph客户端存储对象数据到RADOS集群上,不是客户端直接存储到osd上;首先客户端会根据ceph集群的配置,将客户端存储的对象数据切分多个固定大小的对象数据,然后再将这些固定大小的数据对象通过一致性hash算法将对象数据映射至存储池里的PG,然后由CRUSH算法计算以后,再将PG映射至对应osd,然后由mon返回osd的ID给客户端,客户端拿着mon给的osd相关信息主动联系对应osd所在节点osd进程,进行数据存储操作;
什么是存储池呢?在ceph上,所谓存储池是ceph以“存储池(pool)”的方式,将RADOS存储集群提供的存储服务逻辑分割一个或多个存储区域;我们可以理解为数据对象的名称空间;实践中,管理员可以为特定应用程序存储不同类型数据的需求分别创建专用的存储池,例如rbd存储池、rgw存储池等,也可以为某个项目或某个用户创建专有的存储池;当然,如果我们在一个存储池里存储的数据过多,为了方便管理,存储池还可以进一步细分为一至多个名称空间(namespace);客户端(包括rbd和rgw等)存取数据时,需要事先指定存储池名称、用户名和密钥等信息完成认证,而后将一直维持与其指定的存储池的连接,于是也可以把存储池看作是客户端的IO接口;
Ceph存储池类型
在ceph上,存储池有两种类型;默认情况下,我们不指定什么类型的存储池就是副本池(replicated pool);所谓副本池就是存储在该存储之上的对象数据,都会由RADOS集群将每个对象数据在集群中存储为多个副本,其中存储于主OSD的为主副本,副本数量在创建存储池时 由管理员指定;默认情况下不指定副本数量,对应副本数量为3个,即1主2从;从上面的描述可以看到,当我们存储一份对象数据时,为了冗余备份,我们需要将数据存储3分,即有两份冗余;这也意味着,我们磁盘利用率也只有1/3;于是,为了提高磁盘的利用率的同时,又能保证冗余,ceph还支持纠删码池(erasure code);纠删码池就是把个对象存储为 N=K+M 个块,其中,K为数据块数量,M为编码块数量,因此存储池的尺寸为 K+M ;纠删码是一种前向纠错(FEC)代码通过将K块的数据转换为N块,假设N=K+M,则其中的M代表纠删码算法添加的额外或冗余的块数量以提供冗余机制(即编码块),而N则表示在纠删码编码之后要创建的块的总数,其可以故障的总块数为M(即N-K)个;类似RAID5;纠删码池减少了确保数据持久性所需的磁盘空间量,但计算量上却比副本存储池要更贵一些;但我们在使用纠删码池的时候需要注意不是所有的应用都支持纠删码池,比如,RGW可以使用纠删码存储池,但RBD就不支持纠删码池,它只支持副本池;
副本池IO
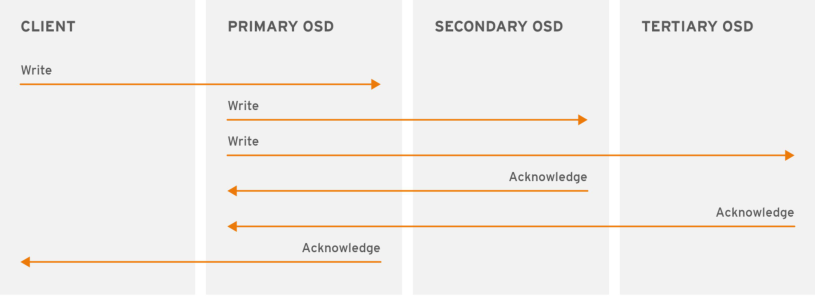
提示:在ceph上,副本池会将一个数据对象存储为多个副本;为此,在写入操作时,ceph客户端使用crush算法来计算对象的PG ID和Primary OSD,然后客户端将数据写入主OSD,主OSD根据设定的副本数、对象的名称、存储池名称和集群运行图(Cluster Map)计算出PG的各辅助OSD,而后由主OSD将数据同步给这些辅助OSD,只有在其他辅助osd和主osd都将对应数据存储好以后,主osd收到对应辅助osd的确认以后,才会给客户端确认;
纠删码池IO
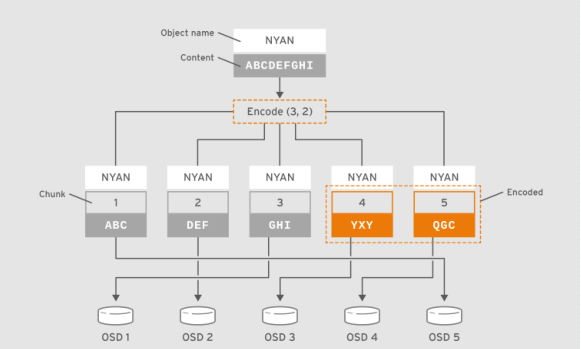
提示:如上图所示客户端把包含数据“ABCDEFGHI”的对象NYAN保存到存储池中时,假设纠删码算法会将内容分割为三个数据块:第一个包含ABC,第二个为DEF,最后一个为GHI,并为这三个数据块额外创建两个编码块:第四个YXY和第五个QGC;在有着两个编码块配置的存储池中,它容许至多两个OSD不可用而不影响数据的可用性。假设,在某个时刻OSD 1和OSD 3因故无法正常响应客户端请求,这意味着客户端仅能读取到ABC、DEF和QGC,此时纠删编码算法会通过计算重那家出GHI和YXY;
二、关于PG
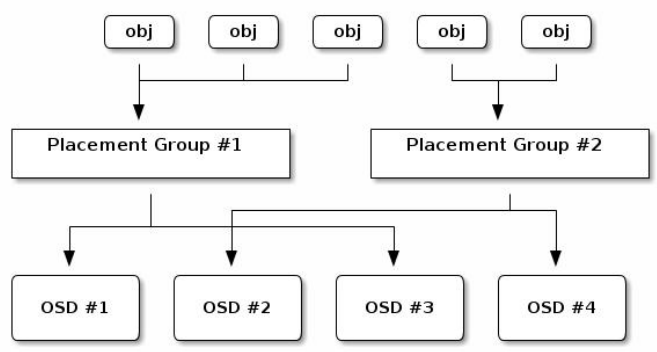
提示:PG是用于跨OSD将数据存储在某个存储池中的内部数据结构;相对于存储池来说,PG是一个虚拟组件,它是对象映射到OSD时使用的虚拟层;出于规模伸缩及性能方面的考虑,Ceph将存储池细分为归置组,把每个单独的对象映射到归置组,并将归置组分配给一个主OSD;存储池由一系列的归置组组成,而CRUSH算法则根据集群运行图和集群状态,将各PG均匀、伪随机地分布到集群中的OSD之上;所谓伪随机是指,在osd都健康数量没有变化的情况下,同一PG始终映射相同的OSD;若某OSD失败或需要对集群进行重新平衡,Ceph则移动或复制整个归置组而无需单独寻址每个对象;归置组在OSD守护进程和Ceph客户端之间生成了一个中间层,CRUSH算法负责将每个对象动态映射到一个归置组,然后再将每个归置组动态映射到一个或多个OSD守护进程,从而能够支持在新的OSD设备上线时动态进行数据重新平衡;
PG数量由管理员在创建存储池时指定,而后由CRUSH负责创建和使用,通常,PG的数量应该是数据的合理颗粒度的子集,例如,一个包含256个PG的存储池意味着每个PG包含大约1/256的存储池数据;当需要将PG从一个OSD移动到另一个OSD时,PG的数量会对性能产生影响;PG数量过少,Ceph将不得不同时移动相当数量的数据,其产生的网络负载将对集群的正常性能输出产生负面影响;即PG过少,那么对应一个PG存储的数据就越多,则移动PG会占用过多的网络带宽,从而影响正常客户端的使用;而在过多的PG数量场景中在移动极少量的数据时,Ceph将会占用过多的CPU和RAM,从而对集群的计算资源产生负面影响。即PG过多,对应每个PG维护的数据较少,但是集群需要花费很多CPU和内存来维护和追踪PG的信息;从而造成集群的计算资源和内存资源造成影响,从而进一步影响客户端使用;所以在ceph上pg的数量不宜过多和过少;
PG数量在群集分发数据和重新平衡时扮演着重要作用,在所有OSD之间进行数据持久存储及完成数据分布会需要较多的归置组,但是它们的数量应该减少到最大性能所需的最小数量值,以节省CPU和内存资源;一般说来,对于有着超过50个OSD的RADOS集群,建议每个OSD大约有50-100个PG以平衡资源使用,取得更好的数据持久性和数据分布,更大规模的集群中,每个OSD大约可持有100-200个PG至于应该使用多少个PG,可通过下面的公式计算后,将其值以类似于四舍五入到最近的2的N次幂;
PG计算公式:(Total OSDs * PGPerOSD)/Replication factor => Total PGs;即一个ceph集群总PG数量=每个OSD上的pg数量×OSD的数量,然后除以副本数量;一个RADOS集群上可能会存在多个存储池,因此管理员还需要考虑所有存储池上的PG分布后每个OSD需要映射的PG数量;即总pg数量/存储池个数,就是平均一个存储的PG数量;简单讲就是所有存储池的PG数量之和应该等于通过上述公式算出来的值四舍五入到最近的2的N次幂;
依据PG当前的工作特性或工作进程所处的阶段,它总是处于某个或某些个“状态”中,最为常见的状态应该为“active+clean”;
PG的常见状态
1、Active:所谓Active状态是指主OSD和各辅助OSD均处于就绪状态,可正常服务于客户端的IO请求所处于的状态;一般,Peering操作过程完成后即会转入Active状态;
2、Clean:是指主OSD和各辅助OSD均处于就绪状态,所有对象的副本数量均符合期望,并且PG的活动集和上行集是为同一组OSD;
活动集(Acting Set):由PG当前的主OSD和所有的处于活动状态的辅助OSD组成,这组OSD负责执行此PG上数据对象的存取操作I/O;
上行集(Up Set):根据CRUSH的工作方式,集群拓扑架构的变动将可能导致PG相应的OSD变动或扩展至其它的OSD之上,这个新的OSD集也称为PG的”上行集(Up Set)“,其映射到的新OSD集可能部分地与原有OSD集重合,也可能会完全不相干; 上行集OSD需要从当前的活动集OSD上复制数据对象,在所有对象同步完成后,上行集便成为新的活动集,而PG也将转为“活动(active)”状态;
3、Peering:一个PG中的所有OSD必须就它们持有的数据对象状态达成一致,而“对等(Peering)”即为让其OSD从不一致转为一致的过程;
4、Degraded:在某OSD标记为“down”时,所有映射到此OSD的PG即转入“降级(degraded)”状态;此OSD重新启动并完成Peering操作后,PG将重新转回clean;一旦OSD标记为down的时间超过5分钟,它将被标记出集群,而后Ceph将对降级状态的PG启动恢复操作,直到所有因此而降级的PG重回clean状态;在其内部OSD上某对象不可用或悄然崩溃时,PG也会被标记为降级状态,直至对象从某个权威副本上正确恢复;
5、Stale:每个OSD都要周期性地向RADOS集群中的监视器报告其作为主OSD所持有的所有PG的最新统计数据,因任何原因导致某个主OSD无法正常向监视器发送此类报告,或者由其它OSD报告某个OSD已经down掉,则所有以此OSD为主OSD的PG将立即被标记为stale状态;
6、Undersized: PG中的副本数少于其存储池定义的个数时即转入undersized状态,恢复和回填操作在随后会启动以修复其副本数为期望值;
7、Scrubbing:各OSD还需要周期性地检查其所持有的数据对象的完整性,以确保所有对等OSD上的数据一致;处于此类检查过程中的PG便会被标记为scrubbing状态,这也通常被称作light scrubs、shallowscrubs或者simply scrubs;另外,PG还偶尔需要进行deep scrubs检查以确保同一对象在相关的各OSD上能按位匹配,此时PG将处于scrubbing+deep状态;
8、Recovering:添加一个新的OSD至存储集群中或某OSD宕掉时,PG则有可能会被CRUSH重新映射进而将持有与此不同的OSD集,而这些处于内部数据同步过程中的PG则被标记为recovering状态;
9、Backfilling:新OSD加入存储集群后,Ceph则会进入数据重新均衡的状态,即一些数据对象会在进程后台从现有OSD移到新的OSD之上,此操作过程即为backfill;
三、关于CRUSH
CRUSH是Controlled Replication Under Scalable Hashing的缩写,它是一种数据分布式算法,类似于一致性哈希算法,用于为RADOS存储集群控制数据分布;在ceph上如果我们把对象直接映射到OSD上会导致二者的耦合度过于紧密;这意味着如果一个OSD的变动,可能导致整个集群的数据的变动;所以,Ceph将一个对象映射进RADOS集群的过程分为两步;首先是以一致性哈希算法将对象名称映射到PG,而后而后是将PG ID基于CRUSH算法映射到OSD;此两个过程都以“实时计算”的方式完成,而非传统的查表方式,从而有效规避了任何组件被“中心化”的可能性,使得集群规模扩展不再受限;
Ceph客户端IO的简要工作流程
在ceph上,客户端存取对象时,客户端从Ceph监视器检索出集群运行图,绑定到指定的存储池,并对存储池上PG内的对象执行IO操作;存储池的CRUSH规则集和PG的数量是决定Ceph如何放置数据的关键性因素,基于最新版本的集群运行图,客户端能够了解到集群中的所有监视器和OSD以及它们各自的当前状态;这对于客户端来说,对象存储在那个位置是一无所知的;执行对象的存取操作时,客户端需要输入的是对象标识和存储池名称;客户端需要在存储池中存储命名对象时,它将对象名称、对象名称的哈希码、存储池中的PG数量和存储池名称作为输入,而后由CRUSH计算出PG的ID及此PG的主OSD;通过将对象标识进行一致性哈希运算得到的哈希值与PG位图掩码进行”与“运算得到目标PG,从而得出目标PG的ID(pg_id),完成由Object至PG的映射; 而后,CRUSH算法便将以此pg_id、CRUSH运行图和归置规则(Placement Rules)为输入参数再次进行计算,并输出一个确定且有序的目标存储向量列表(OSD列表),从而完成从PG至OSD的映射;
Ceph客户端计算PG_ID的步骤
1、首先客户端输入存储池名称及对象名称,例如,pool = pool1以及object-id = obj1;
2、获取对象名称并通过一致性哈希算法对其进行哈希运算,即hash(o),其中o为对象名称;
3、将计算出的对象标识哈希码与PG位图掩码进行“与”运算获得目标PG的标识符,即PG_ID,如1701;计算公式为pgid=func(hash(o)&m,r),其中,变量o是对象标识符,变量m是当前存储池中PG的位图掩码,变量r是指复制因子,用于确定目标PG中OSD数量;
4、CRUSH根据集群运行图计算出与目标PG对应的有序的OSD集合,并确定出其主OSD;
5、客户端获取到存储池名称对应的数字标识,例如,存储池“pool1”的数字标识11;
6、客户端将存储池的ID添加到PG ID,例如,11.1701;
7、客户端通过直接与PG映射到的主OSD通信来执行诸如写入、读取或删除之类的对象操作;
简单来讲,ceph客户端存取对象数据的过程就是,先提取用户要存入的对象数据的名称和存储到那个存储池之上;然后通过一致性哈希算法计算出对象名称的hash值,然后把这个hash值和在对应存储池PG位图掩码做“与”运算得到目标PG的标识符,即PG ID;有了PG_ID,再根据CRUSH算法结合集群运行图和PG对应的OSD集合,最终把PG对应的主OSD确认,然后将对应osd的信息返回给客户端,然后客户端拿着这些信息主动联系osd所在主机进行数据的存取;这一过程中,没有传统的查表,查数据库之类的操作;全程都是通过计算来确定对应数据存储路径;这也就规避了传统查表或查数据库的方式给集群带来的性能瓶颈的问题;
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK