

MongoDB Collections to CockroachDB With FerretDB - DZone Database
source link: https://dzone.com/articles/migrating-mongodb-collections-to-cockroachdb-with
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Previous Article
Using CockroachDB as a Backend for OSS MongoDB Alternative FerretDB
Motivation
Once I completed my first article, I realized there are a lot of possibilities exposed by proxying MongoDB collections through FerretDB backed by CockroachDB. CockroachDB has unique data domiciling capabilities available through multi-region abstractions, inverted and partial indexes, computed columns, and of course strong consistency. Today, we're going to restore a MongoDB collection into CockroachDB via FerretDB and expand on our previous learnings.
High-Level Steps
- Start a 9-node multi-region cluster (CockroachDB Dedicated)
- Start FerretDB (Docker)
- Restore a MongoDB dataset using
mongorestore - Considerations
- Conclusion
Step-By-Step Instructions
Start a 9-Node Multi-Region Cluster (CockroachDB Dedicated)
I am going to use a CockroachDB Dedicated cluster for this tutorial, as I need access to a multi-region cluster. You can get by with a local multi-region cluster via cockroach demo --no-example-database --global --insecure --nodes 9, but with the amount of data I will be ingesting, it may not be viable. This is also an opportunity to demonstrate how FerretDB will behave with CockroachDB certificate authentication. I'm calling my cluster artem-mr and using our brand new cloud CLI to access the cluster.
ccloud cluster sql artem-mr Retrieving cluster info: succeeded Downloading cluster cert to /Users/artem/Library/CockroachCloud/certs/artem-mr-ca.crt: succeeded Retrieving SQL user list: succeeded SQL username: artem SQL user password: ***** Starting CockroachDB SQL shell... # # Welcome to the CockroachDB SQL shell. # All statements must be terminated by a semicolon. # To exit, type: \q. # [email protected]:26257/defaultdb>
Let's quickly glance at the regions participating in the cluster:
SHOW REGIONS FROM CLUSTER;
region | zones
----------------+-------------------------------------------------
aws-us-east-1 | {aws-us-east-1a,aws-us-east-1b,aws-us-east-1c}
aws-us-east-2 | {aws-us-east-2a,aws-us-east-2b,aws-us-east-2c}
aws-us-west-2 | {aws-us-west-2a,aws-us-west-2b,aws-us-west-2c}
Let's verify the region we're accessing the cluster from:
select gateway_region();
gateway_region ------------------ aws-us-east-1
Let's create a database we're going to use to host our MongoDB data.
CREATE DATABASE ferretdb; USE ferretdb;
Start FerretDB (Docker)
I'm going to spin up a Docker Compose instance of FerretDB locally. For the connection string, we will need to navigate to the Cockroach Cloud console and toggle the Connect modal. Under the connection string, we can find all of the necessary info we will need to fill out the Compose file.
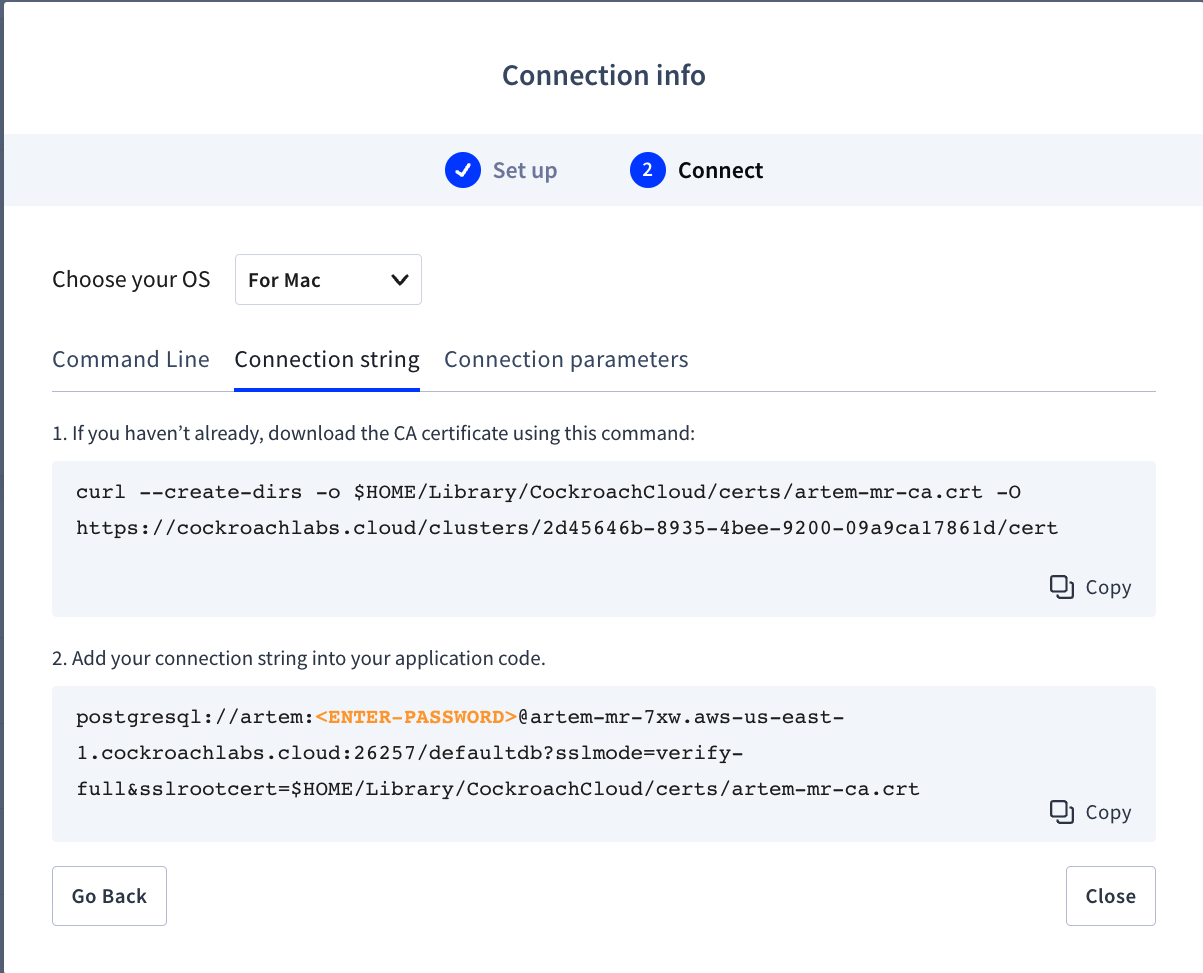
version: "3"
services:
ferretdb:
image: ghcr.io/ferretdb/ferretdb:latest
hostname: 'ferretdb'
container_name: 'ferretdb'
restart: 'on-failure'
command:
[
'-listen-addr=:27017',
## Dedicated multiregion cluster
'-postgresql-url=postgresql://artem:[email protected]:26257/ferretdb?sslmode=verify-full&sslrootcert=/certs/artem-mr-ca.crt'
]
ports:
- 27017:27017
volumes:
- /Users/artem/Library/CockroachCloud/certs/artem-mr-ca.crt:/certs/artem-mr-ca.crt
Keep in mind we need to specify the proper database in the connection string. Since I'm using ferretdb, I include it in my compose file.
We will also need to mount the CA cert you need to connect to CockroachDB. It was automatically downloaded when I first connected via CLI.
Save the file as docker-compose.yml and issue docker compose up -d command to start the container.
docker compose up -d [+] Running 1/1 ⠿ Container ferretdb Started
It's probably a good idea to inspect the FerretDB container logs to make sure we got everything working.
docker logs ferretdb
2022-09-08T13:51:35.456Z INFO pgdb [email protected]/conn.go:354 Exec {"sql": ";", "args": [], "time": "17.351386ms", "commandTag": "", "pid": 1849370} 2022-09-08T13:51:35.456Z DEBUG // 172.24.0.1:63788 -> 172.24.0.2:27017 clientconn/conn.go:437Response header: length: 190, id: 49, response_to: 5362, opcode: OP_MSG 2022-09-08T13:51:35.457Z DEBUG // 172.24.0.1:63788 -> 172.24.0.2:27017 clientconn/conn.go:438Response message: { "Checksum": 0, "FlagBits": 0, "Sections": [ { "Document": { "$k": [ "ismaster", "maxBsonObjectSize", "maxMessageSizeBytes", "maxWriteBatchSize", "localTime", "minWireVersion", "maxWireVersion", "readOnly", "ok" ], "ismaster": true, "maxBsonObjectSize": 16777216, "maxMessageSizeBytes": 48000000, "maxWriteBatchSize": 100000, "localTime": { "$d": 1662645095456 }, "minWireVersion": 13, "maxWireVersion": 13, "readOnly": false, "ok": { "$f": 1 } }, "Kind": 0 } ] }
Since we're not seeing any glaring errors, let's proceed.
Install mongosh locally or add another container for mongosh in Docker Compose. See my previous article for an example.
I have mongosh installed locally. We can access the container by issuing mongosh in a terminal:
mongosh
Or the following:
mongosh mongodb://localhost/
Current Mongosh Log ID: 631a77e81460be94daef222e Connecting to: mongodb://localhost/?directConnection=true&serverSelectionTimeoutMS=2000&appName=mongosh+1.5.4 Using MongoDB: 6.0.42 Using Mongosh: 1.5.4 For mongosh info see: https://docs.mongodb.com/mongodb-shell/ ------ The server generated these startup warnings when booting 2022-09-08T23:16:58.426Z: Powered by FerretDB v0.5.3 and PostgreSQL 13.0.0. 2022-09-08T23:16:58.426Z: Please star us on GitHub: https://github.com/FerretDB/FerretDB ------ test>
Install Mongo tools on the host using the directions. You can also add another container with these tools installed, but I'm leaving it to you as homework.
brew tap mongodb/brew brew install mongodb-database-tools
Let's load data into the database. We'll use the Mflix dataset, but any will do.
In a new terminal window:
wget https://atlas-education.s3.amazonaws.com/sampledata.archive
Restore a MongoDB Dataset Using mongorestore
Restore the archive into FerretDB using the mongodb-database-tools package we installed earlier.
mongorestore --archive=sampledata.archive
2022-09-08T09:57:55.587-0400 preparing collections to restore from 2022-09-08T09:57:55.595-0400 reading metadata for sample_mflix.comments from archive 'sampledata.archive' 2022-09-08T09:57:55.596-0400 reading metadata for sample_mflix.users from archive 'sampledata.archive' 2022-09-08T09:57:55.596-0400 reading metadata for sample_training.grades from archive 'sampledata.archive' 2022-09-08T09:57:55.596-0400 reading metadata for sample_airbnb.listingsAndReviews from archive 'sampledata.archive' 2022-09-08T09:57:55.596-0400 reading metadata for sample_analytics.customers from archive 'sampledata.archive' 2022-09-08T09:57:55.596-0400 reading metadata for sample_restaurants.restaurants from archive 'sampledata.archive' 2022-09-08T09:57:55.596-0400 reading metadata for sample_restaurants.neighborhoods from archive 'sampledata.archive' ... 2022-09-08T09:59:40.537-0400 sample_mflix.comments 278KB 2022-09-08T09:59:43.536-0400 sample_mflix.comments 278KB 2022-09-08T09:59:46.536-0400 sample_mflix.comments 278KB 2022-09-08T09:59:49.536-0400 sample_mflix.comments 278KB 2022-09-08T09:59:52.537-0400 sample_mflix.comments 278KB ...
My FerretDB is local somewhere in northern New Jersey, and our CockroachDB gateway region is aws-us-east-1. Recall we specified it when we set up Docker Compose. it may have some network latency.
Here's a quick test we can do using Cockroach CLI:
SELECT 1;
?column?
------------
1
(1 row)
Time: 20ms total (execution 1ms / network 19ms)
We're dealing with 19ms round trip time, as well as the fact that we are proxying MongoDB via a FerretDB Docker container. Let's do a quick sanity check. In the terminal where you have mongosh running, issue the following commands:
use sample_mflix show collections
test> use sample_mflix switched to db sample_mflix sample_mflix> show collections comments
Let's get a quick row count:
db.comments.count() 4257
Looking at the description of the dataset, we can see if these rows exist:
db.comments.findOne({ "name": "Andrea Le" })
{
_id: ObjectId("5a9427648b0beebeb6957ef5"),
name: 'Andrea Le',
email: '[email protected]',
movie_id: ObjectId("573a1392f29313caabcda653"),
text: 'Odio expedita impedit sed provident at. Mollitia distinctio laborum optio earum voluptates recusandae ad. Voluptates quas et placeat atque.',
date: ISODate("1973-08-07T04:00:34.000Z")
}
The sample dataset is 304MB. I'm unsure what the total record count is, but I know the restore will take a while. Your mileage may vary, so go ahead and grab a cup of coffee in the meantime.
2022-09-08T10:34:07.610-0400 sample_mflix.comments 2.17MB 2022-09-08T10:34:09.218-0400 sample_mflix.comments 2.17MB 2022-09-08T10:34:09.218-0400 finished restoring sample_mflix.comments (7000 documents, 0 failures) 2022-09-08T10:34:09.218-0400 Failed: sample_mflix.comments: error restoring from archive 'sampledata.archive': (InternalError) [pool.go:361 pgdb.(*Pool).InTransaction] read tcp 172.24.0.2:55922->54.208.245.52:26257: read: connection reset by peer 2022-09-08T10:34:09.219-0400 7000 document(s) restored successfully. 0 document(s) failed to restore.
Ok, let me pause for a minute and just say a few words, ignoring the interrupted restore due to what looks like a network error: I am shocked this worked in the first place FerretDB seamlessly and effortlessly proxying a MongoDB collection and restores it as is into CockroachDB at the edge! This is by far the easiest, dare I say, migration I've worked on!
I think I have enough records in the comments collection. Let's restore the other collections from the dataset individually.
mongorestore --archive=sampledata.archive --nsInclude=sample_mflix.movies mongorestore --archive=sampledata.archive --nsInclude=sample_mflix.sessions mongorestore --archive=sampledata.archive --nsInclude=sample_mflix.theaters mongorestore --archive=sampledata.archive --nsInclude=sample_mflix.users
Fortunately, the rest of the collections were small enough that they were loaded in a short time. Let me show you what a successful restore would look like.
2022-09-08T14:53:57.086-0400 sample_mflix.users 28.9KB
2022-09-08T14:54:00.086-0400 sample_mflix.users 28.9KB
2022-09-08T14:54:01.347-0400 sample_mflix.users 28.9KB
2022-09-08T14:54:01.347-0400 finished restoring sample_mflix.users (185 documents, 0 failures)
2022-09-08T14:54:01.373-0400 restoring indexes for collection sample_mflix.users from metadata
2022-09-08T14:54:01.373-0400 index: &idx.IndexDocument{Options:primitive.M{"name":"email_1", "unique":true, "v":2}, Key:primitive.D{primitive.E{Key:"email", Value:1}}, PartialFilterExpression:primitive.D(nil)}
2022-09-08T14:54:01.376-0400 185 document(s) restored successfully. 0 document(s) failed to restore.
Let's compare the document counts in mongosh with the counts in CockroachDB.
sample_mflix> db.comments.count() 7340 sample_mflix> db.movies.count() 3599 sample_mflix> db.sessions.count() 1 sample_mflix> db.theaters.count() 1564 sample_mflix> db.users.count() 185
show tables;
schema_name | table_name | type | owner | estimated_row_count | locality ---------------+--------------------+-------+-------+---------------------+----------- sample_mflix | _ferretdb_settings | table | artem | 1 | NULL sample_mflix | comments_5886d2d7 | table | artem | 6027 | NULL sample_mflix | movies_257fbbf4 | table | artem | 3599 | NULL sample_mflix | sessions_130573cc | table | artem | 1 | NULL sample_mflix | theaters_cf846063 | table | artem | 1493 | NULL sample_mflix | users_5e7cc513 | table | artem | 185 | NULL
I don't trust the estimated_row_count field. Let's quickly glance at the table counts.
select count(*) from sample_mflix.comments_5886d2d7;
count
---------
7340
select count(*) from sample_mflix.movies_257fbbf4;
count
---------
3599
select count(*) from sample_mflix.sessions_130573cc;
count
---------
1
select count(*) from sample_mflix.theaters_cf846063;
count
---------
1564
select count(*) from sample_mflix.users_5e7cc513;
count
---------
185
Looks like everything matches. Let's inspect the schema.
SHOW CREATE TABLE sample_mflix.comments_5886d2d7;
table_name | create_statement
---------------------------------+----------------------------------------------------------------
sample_mflix.comments_5886d2d7 | CREATE TABLE sample_mflix.comments_5886d2d7 (
| _jsonb JSONB NULL,
| rowid INT8 NOT VISIBLE NOT NULL DEFAULT unique_rowid(),
| CONSTRAINT comments_5886d2d7_pkey PRIMARY KEY (rowid ASC)
| )
Let's extract the create table statement and make a few modifications.
SELECT create_statement FROM [SHOW CREATE TABLE sample_mflix.comments_5886d2d7];
CREATE TABLE sample_mflix.comments_5886d2d7 (
_jsonb JSONB NULL,
rowid INT8 NOT VISIBLE NOT NULL DEFAULT unique_rowid(),
CONSTRAINT comments_5886d2d7_pkey PRIMARY KEY (rowid ASC)
)
We see a rowid column, which is a primary key in CockroachDB if one was not specified explicitly, and a _jsonb column containing our documents. We're going to replace the rowid with an id stored in the JSON document. We're going to use computed columns to extract the id. The Mongo ObjectID looks like a hash. We're going to pass it to an md5() function.
select md5(_jsonb->>'_id') from sample_mflix.comments_5886d2d7 limit 5;
md5 ------------------------------------ e15a7dcdd0e149effb3305129a924195
The following steps are part of the flexible CockroachDB schema model, which is complementary to the MongoDB schema-less model.
Considering this is a multi-region cluster, the following schema changes may take a long time to execute while in the background. To speed up these changes, the following query will pin the system database to the local region and make schema changes quicker.
ALTER DATABASE system CONFIGURE ZONE USING constraints = '{"+region=aws-us-east-1": 1}', lease_preferences = '[[+region=aws-us-east-1]]';
Adding a new column to an existing table:
ALTER TABLE sample_mflix.comments_5886d2d7 ADD COLUMN id STRING NOT NULL AS (md5(_jsonb->>'_id')::STRING) VIRTUAL;
We can now change the primary key from an internal rowid to the new computed column, but before we do it, let's truncate the table first. It is not necessary, but let's do it anyway because there are other factors to consider when loading data into CockroachDB. I will talk about it shortly.
TRUNCATE TABLE sample_mflix.comments_5886d2d7;
Let's change the primary key from the internal rowid column to the newly added column.
ALTER TABLE sample_mflix.comments_5886d2d7 ALTER PRIMARY KEY USING COLUMNS (id);
Finally, let's drop the rowid column as we no longer need it.
set sql_safe_updates = false; ALTER TABLE sample_mflix.comments_5886d2d7 DROP COLUMN rowid; set sql_safe_updates = true;
Let's look at the schema again:
SELECT create_statement FROM [SHOW CREATE TABLE sample_mflix.comments_5886d2d7];
create_statement
---------------------------------------------------------------------
CREATE TABLE sample_mflix.comments_5886d2d7 (
_jsonb JSONB NULL,
id STRING NOT NULL AS (md5(_jsonb->>'_id':::STRING)) VIRTUAL,
CONSTRAINT comments_5886d2d7_pkey PRIMARY KEY (id ASC)
)
We returned the behavior in MongoDB with references to the ObjectID. What's left now is to restore the comments collection.
Based on the fact that we now enforce primary keys based on MongoDB ObjectID, we can leverage the CockroachDB consistency and prevent the following errors:
2022-09-01T14:28:11.291-0400 demux finishing when there are still outs (1) 2022-09-01T14:28:11.291-0400 Failed: sample_mflix.comments: error restoring from archive 'sampledata.archive': (InternalError) [pool.go:356 pgdb.(*Pool).InTransaction] [msg_insert.go:108 pg.(*Handler).insert.func1] ERROR: duplicate key value violates unique constraint "comments_5886d2d7_pkey" (SQLSTATE 23505) 2022-09-01T14:28:11.291-0400 0 document(s) restored successfully. 0 document(s) failed to restore.
The fact we have hash primary keys also helps with load distribution. When you start with an empty table, you have a single range, and all read and write requests will hit this range creating hotspots. To achieve uniform distribution and better performance, we need to balance the load across many ranges. Right now, the table is empty and yet it's backed by a single range.
SELECT start_key, end_key, range_id, range_size_mb FROM [SHOW RANGES FROM TABLE sample_mflix.comments_5886d2d7];
start_key | end_key | range_id | range_size_mb ------------+---------+----------+---------------- NULL | NULL | 85 | 0
Let's pre-split the table prior to reloading the data. Since our primary key is now an md5-based ObjectID hash, we can pre-split into 16 ranges.
ALTER TABLE sample_mflix.comments_5886d2d7 SPLIT AT
SELECT
(
first_letter
|| md5(random()::STRING)
)::STRING
FROM
(
SELECT
CASE
WHEN i < 10 THEN i::STRING
WHEN i = 10 THEN 'a'
WHEN i = 11 THEN 'b'
WHEN i = 12 THEN 'c'
WHEN i = 13 THEN 'd'
WHEN i = 14 THEN 'e'
ELSE 'f'
END
AS first_letter
FROM
generate_series(0, 15) AS g (i)
);
The next command will spread the ranges across the cluster:
ALTER TABLE sample_mflix.comments_5886d2d7 SCATTER;
Let's look at the new ranges:
SELECT start_key, end_key, range_id, range_size_mb FROM [SHOW RANGES FROM TABLE sample_mflix.comments_5886d2d7];
start_key | end_key | range_id | range_size_mb ---------------------------------------+--------------------------------------+----------+---------------- NULL | /"0d545f8e17e030f0c5181e1afc5de6224" | 85 | 0 /"0d545f8e17e030f0c5181e1afc5de6224" | /"1cab56eb5ce49a61e99ccf31c5ae19c67" | 86 | 0 /"1cab56eb5ce49a61e99ccf31c5ae19c67" | /"29f6b8beefa6573ec41470968e54bca42" | 106 | 0 /"29f6b8beefa6573ec41470968e54bca42" | /"33a54c6c02a9989a978aa8e5a5f7e9d73" | 107 | 0 /"33a54c6c02a9989a978aa8e5a5f7e9d73" | /"4618f2a8a2cc498d98943c6a19b9c6c7b" | 108 | 0 /"4618f2a8a2cc498d98943c6a19b9c6c7b" | /"5946ca647ea8270a37574c1a898056961" | 109 | 0 /"5946ca647ea8270a37574c1a898056961" | /"6f2112e4bdad3a2237cb00d50acd0e05e" | 125 | 0 /"6f2112e4bdad3a2237cb00d50acd0e05e" | /"793517eb63ea208ad2e5baea51c23ad05" | 126 | 0 /"793517eb63ea208ad2e5baea51c23ad05" | /"8d81118af05e64980c10e5a1625ea250a" | 127 | 0 /"8d81118af05e64980c10e5a1625ea250a" | /"9c293b5d497d94c029f34e288961415b9" | 128 | 0 /"9c293b5d497d94c029f34e288961415b9" | /"a497c26e97b1136fb0b7ae1174cf575e6" | 129 | 0 /"a497c26e97b1136fb0b7ae1174cf575e6" | /"b4fe34ea032cbded1b4004a9548ff1883" | 130 | 0 /"b4fe34ea032cbded1b4004a9548ff1883" | /"c420a9bf42e53d5c980fc18931bf1dc79" | 131 | 0 /"c420a9bf42e53d5c980fc18931bf1dc79" | /"d32739d1ed370496ccee3f23f87c36e01" | 132 | 0 /"d32739d1ed370496ccee3f23f87c36e01" | /"e587ad032ca91e63f1a72999acb6baec5" | 133 | 0 /"e587ad032ca91e63f1a72999acb6baec5" | /"fbb21b41dbeaf54b21a19f4b0b204195c" | 134 | 0 /"fbb21b41dbeaf54b21a19f4b0b204195c" | NULL | 135 | 0
We can now reload the data into the comments table and see if it makes any difference.
mongorestore --archive=sampledata.archive --nsInclude=sample_mflix.comments
We can rerun the show ranges command to see the splitting at work:
start_key | end_key | range_id | range_size_mb ---------------------------------------+--------------------------------------+----------+------------------------- NULL | /"05544a6f1a9e2c370d61e80b08bfc9914" | 450 | 0.39971900000000000000 /"05544a6f1a9e2c370d61e80b08bfc9914" | /"145af2f7d21c2737757f48b85beaac411" | 382 | 1.0964470000000000000 /"145af2f7d21c2737757f48b85beaac411" | /"22f8086dd66f929f2a9f02213d8eb2880" | 383 | 1.0559140000000000000 /"22f8086dd66f929f2a9f02213d8eb2880" | /"340e8a0bbb4340a680a45b6f4d041f338" | 395 | 1.2896460000000000000 /"340e8a0bbb4340a680a45b6f4d041f338" | /"4cd3f28b0d95bcd3be3be03a47cc3e7bf" | 396 | 1.8605330000000000000 /"4cd3f28b0d95bcd3be3be03a47cc3e7bf" | /"500650bb144971c1138805e235a7275b3" | 397 | 0.26009000000000000000 /"500650bb144971c1138805e235a7275b3" | /"6777895c82eab8059a7bbbc3f0953fde3" | 398 | 1.7841590000000000000 /"6777895c82eab8059a7bbbc3f0953fde3" | /"73a828d7661f43b8696cf15103a061b06" | 401 | 0.85725000000000000000 /"73a828d7661f43b8696cf15103a061b06" | /"894c50ca8d93d101ae665c14427bf35ce" | 402 | 1.5699020000000000000 /"894c50ca8d93d101ae665c14427bf35ce" | /"9cdda5fe73ed53904d41ab67a47737a25" | 403 | 1.4688710000000000000 /"9cdda5fe73ed53904d41ab67a47737a25" | /"a94b701dd474c23494ca834eaf9ed8fb6" | 404 | 0.94120900000000000000 /"a94b701dd474c23494ca834eaf9ed8fb6" | /"bfb04e1b2ff37d4188c7722575504ca27" | 575 | 1.6290150000000000000 /"bfb04e1b2ff37d4188c7722575504ca27" | /"cfc85f2b55491a6a480552b135c26d34f" | 576 | 1.1618950000000000000 /"cfc85f2b55491a6a480552b135c26d34f" | /"db4f0c8dfad0c9c478e15b78ddc91834a" | 577 | 0.84471700000000000000 /"db4f0c8dfad0c9c478e15b78ddc91834a" | /"e8a406deefeff94205f867661bfbcd269" | 578 | 1.0015310000000000000 /"e8a406deefeff94205f867661bfbcd269" | /"f7a6e34db298c3e4204ddf43842e06cf1" | 579 | 1.1321730000000000000 /"f7a6e34db298c3e4204ddf43842e06cf1" | NULL | 580 | 0.60192500000000000000
The data is balanced across all of the ranges, thereby giving us better performance overall. We are still relying on a single Docker instance of FerretDB so in your environment, you can do something better about the instance hosting FerretDB. Even better, because CockroachDB scales reads and writes, you can run multiple FerretDB instances and load data in parallel.
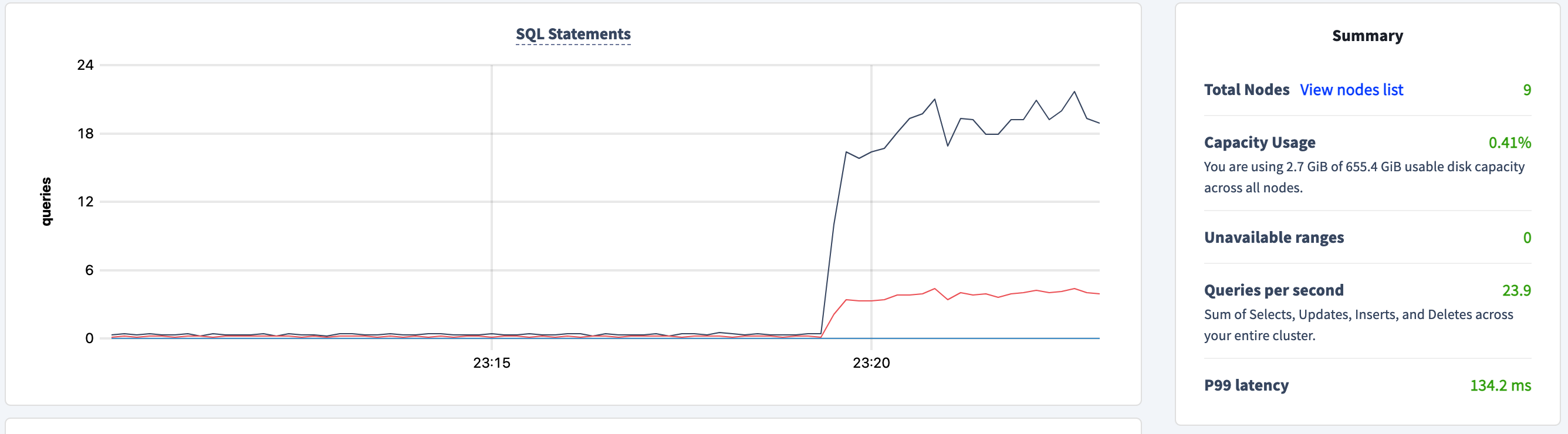
25 qps is nothing to write home about and latency is pretty high as well. I found the following flag --numInsertionWorkersPerCollection=50 useful in driving the performance of mongorestore higher. Play with the number until you reach a good balance.
mongorestore --archive=sampledata.archive --nsInclude=sample_mflix.comments --numInsertionWorkersPerCollection=100
If you happen to receive the following error when you restore the comments collection:
2022-09-09T15:08:16.551-0400 sample_mflix.comments 6.79MB
2022-09-09T15:08:16.551-0400 finished restoring sample_mflix.comments (17017 documents, 0 failures)
2022-09-09T15:08:16.551-0400 demux finishing when there are still outs (22)
2022-09-09T15:08:16.551-0400 Failed: sample_mflix.comments: error restoring from archive 'sampledata.archive': (InternalError) [pool.go:288 pgdb.(*Pool).InTransaction] ERROR: restart transaction: TransactionRetryWithProtoRefreshError: TransactionAbortedError(ABORT_REASON_NEW_LEASE_PREVENTS_TXN): "sql txn" meta={id=cc2e0dc4 key=/Table/121/5/"2ee7d65280b51e55fb4701fdb5787ab1"/0 pri=0.02374602 epo=0 ts=1662749935.838933077,1 min=1662749935.635443487,0 seq=2} lock=true stat=PENDING rts=1662749935.838933077,1 wto=false gul=1662749935.885443487,0 (SQLSTATE 40001)
2022-09-09T15:08:16.551-0400 17017 document(s) restored successfully. 0 document(s) failed to restore.
It means the lease for the range has moved to another region and CockroachDB retried the transaction. Unfortunately, it forces mongorestore to exit. We can pin the lease to the local region and prevent this behavior.
Let's see what the current preferences are:
SHOW ZONE CONFIGURATION FROM TABLE sample_mflix.comments_5886d2d7;
target | raw_config_sql
--------------------+-----------------------------------------------
DATABASE ferretdb | ALTER DATABASE ferretdb CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 600,
| num_replicas = 3,
| constraints = '[]',
| lease_preferences = '[]'
Let's use the CockroachDB multi-region abstractions to achieve the desired outcome:
ALTER DATABASE ferretdb PRIMARY REGION "aws-us-east-1"; ALTER DATABASE ferretdb ADD REGION "aws-us-east-2"; ALTER DATABASE ferretdb ADD REGION "aws-us-west-2";
SHOW ZONE CONFIGURATION FROM TABLE sample_mflix.comments_5886d2d7;
target | raw_config_sql
--------------------+------------------------------------------------------------------------------------------------------
DATABASE ferretdb | ALTER DATABASE ferretdb CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 600,
| num_replicas = 5,
| num_voters = 3,
| constraints = '{+region=aws-us-east-1: 1, +region=aws-us-east-2: 1, +region=aws-us-west-2: 1}',
| voter_constraints = '[+region=aws-us-east-1]',
| lease_preferences = '[[+region=aws-us-east-1]]'
In summary, we are now guaranteed to have a replica in the us-east-1 region, and us-east-1 has a lease_holder who coordinates the reads and writes.
Considerations
While writing this article I've had a hard time getting the comments collection to restore fully. There's a high probability comments collection restore will fail due to various problems like bugs, moving leases, duplicate primary key conflicts, and connection disruptions. I've battled with it for the last two days but all is not lost, the already loaded data is accessible and queryable. My hard lesson from this exercise is to read the documentation. The biggest impact to drive the performance upward came from --numInsertionWorkersPerCollection=100. We were not pushing enough parallel work across. I think splitting the table had helped marginally but at this point, I think it's a red herring. Perhaps I'll try another load without splitting. The lease_holder pinning is necessary as it occurred in the midst of my restore with the --numInsertionWorkersPerCollection=100 flag on. As my final attempt, I've turned on all of the tweaks so far and got to 40044 rows. That's as far as I've been able to get to. There's a lot of work to be done before this is production grade.
2022-09-09T15:49:34.466-0400 sample_mflix.comments 11.1MB 2022-09-09T15:49:36.940-0400 sample_mflix.comments 11.1MB 2022-09-09T15:49:36.940-0400 finished restoring sample_mflix.comments (33079 documents, 0 failures) 2022-09-09T15:49:36.940-0400 Failed: sample_mflix.comments: error restoring from archive 'sampledata.archive': (InternalError) [pool.go:288 pgdb.(*Pool).InTransaction] read tcp 172.29.0.2:52130->3.217.93.138:26257: read: connection reset by peer 2022-09-09T15:49:36.940-0400 33079 document(s) restored successfully. 0 document(s) failed to restore. 2022-09-09T15:49:36.940-0400 demux finishing when there are still outs (21)
That's the output from the very last restore and the counts in CockroachDB and mongosh correspond.
sample_mflix> db.comments.count() 40044
count --------- 40044
Conclusion
As my final thoughts, I'd like to point out that this is an overly simplified example, and make no mistake thinking all migrations are easy. Even so, this is just an experiment and no engineering work is underway to make CockroachDB and FerretDB work better, except maybe if the following issue gets enough votes. There are also future opportunities where FerretDB can also be added as a MongoDB replica set and, who knows, perhaps we can move data to CockroachDB in place, in a so-called online migration? Also, I will reiterate: MongoDB and CockroachDB are not comparable technologies. There's a case to be made for both products. Pick the best tool for the job! I'm merely giving you another option to consider. All things considered, we have ways to go, but I love where this is headed!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK