

啃论文俱乐部---JSON压缩算法解读
source link: https://www.51cto.com/article/719071.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

JSON压缩算法解读
接下来我们进入关于JSON压缩算法的学习。
为什么需要压缩JSON?
尽管JSON数据格式比XML效率要高,但是它仍然是web服务器和浏览器传输过程中比较低效的数据格式。为什么呢?首先,它将所有的内容都转换为了文本,第二是转换之后的文本过度使用引号,这样会给每个字符串添加多两个字节。第三,它本身没有schema的标准格式,比如在一个消息中序列化多个对象的时候,即使每个对象的属性的键名是重复且相同的,但是转换后的文本数据还是会重复每一个键名。
JSON以前的时候有一个优势,就是可以被Javascript引擎直接解析,但因为现在越来越重视安全性,JSON的这个优势也逐渐消失了,但是因为它比XML效率以及性能都更高,所以许多传统的C/S模式都是选择JSON,比如web服务,当有庞大的数据量以及复杂数据结构需要从web浏览器中传输到服务器的时候,JSON压缩就起到了非常大的作用,然而中间就会存在我们刚刚说的三点问题,我们也不能使用传统的gzip压缩算法,因为浏览器不知道服务器是否支持gzip解压。
下面我们就来看看两种常见的JSON压缩算法,cJSON与HPack。
cJSON压缩算法(cJSON Compression Algorithm)
cJSON压缩算法的特点就是可以使用自动类型提取压缩JSON数据格式的内容。它成功解决了一个非常重要的问题,就是我们上一小节提到的第三点,将不断重复的键名舍去了,我们我们来看一个例子:
使用cJSON前的数据格式:
[
{ //表示一个坐标点
"x":100,
"y":100
},
{ //表示一个长方形
"x":100,
"y":100,
"width":200,
"height":150
},
{},//表示一个空对象
... //以下省略数以万计的对象
]上面未经压缩的数据中,我们可以看到有非常多的空间被重复的键名所占据,比如“x”,“y”等等,当数据非常多的时候,这些看起来不起眼的重复键名会给传输效率带来非常大的影响,其实解决思路也非常简单,因为他们是重复的,那我们只存储一次不就好了?下面我们来按照我们的思路看看cJSON处理过后的数据吧。
{
"templates":[
["x","y"], //type1
["x","y","width","height"] //type2
],
"value":[
{ //第一个对象:坐标点
"type":1,
"values":[
100,
100
]
},
{ //第二个对象:矩形
"type":2,
"values":[
100,
100,
200,
150
]
},
{
//第三个空对象
},
//以下省略数以万计的对象......
]
}从上面的数据中我们可以看到,我们格式化了数据,把键名存储了起来,重复的就不存储,然后值通过“type”索引来对应键名,这样在数据量庞大的时候确实减少了不少空间,但是我们仔细看“templates”内的键名依旧有重复的字段存在。说明了我们还存在优化空间,优化完压缩后效果如下:
{ "function": "cjson",
"templates": [
[0, "x", "y"],
[1, "width", "height"]
],
"values": [
[1, 100, 100 ], //第一个对象:坐标点
[2, 100, 100, 200, 150 ], //第二个对象:矩形
[] //第三个空对象
]
} 直接看压缩后的代码结构你可能不太能理解,那我们就来看看他的具体原理,为了解决“template”内键名重复的字段,这个算法采用了树这个数据结构,每遇到一个要传输的对象,就按顺序把键值存入树的节点中(灰色的节点是被标记的结尾节点指针,表示该节点存储的是某个对象最后一个属性的键值),重复的就不存储,这样就解决了我们的问题,这个键值树的变化过程如下:
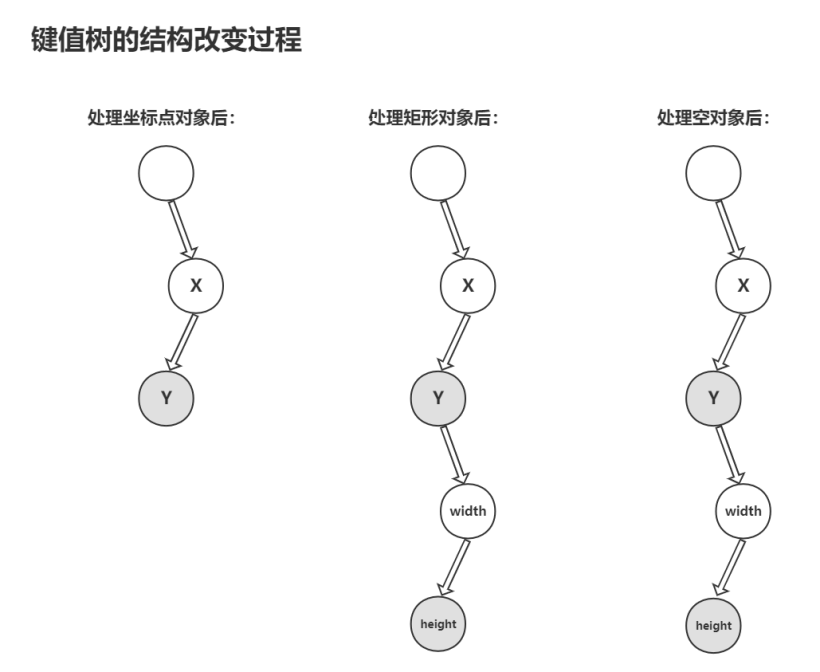
最后数据在匹配键值的时候就根据 “values” 中所标记的结尾节点指针找到对应键值数组,这样就构成了cJSON的压缩算法。
仔细的同学就会发现,如果一个对象中没有"X"和"Y",只有“width”和“height”,或者键值节点顺序是错的,是不是会出问题?答案是对的,会出现无法匹配的键值的情况,所以这种方法只能在特定的场景下应用,存在一定局限性。
总体来说,cJSON在处理非常庞大的数据量的时候效果还是非常客观的。
JSON.HPack压缩算法(HPack Compression Algorithm)
JSON.HPack是一种无损、跨语言、注重性能的JSON数据压缩算法,可以让我们在使用post请求在客户端发送数据到服务器的过程中相对普通JSON格式节省约70%的字符。
其原理本质上也是跟cJSON一样将键值抽离开,举个例子:
使用HPack算法前:
{
"id" : 1,
"sex" : "Female",
"age" : 38,
"classOfWorker" : "Private",
"maritalStatus" : "Married-civilian spouse present",
"education" : "1st 2nd 3rd or 4th grade",
"race" : "White"
}使用HPack算法后:
["id","sex","age","classOfWorker","mari talStatus","education","race"],
[1,"Female",38,"Private","Married-civilian spouse present","1st 2nd 3rd or 4th grade","White"] 可以看到相对于普通JSON以及cJSON少了很多字符,比如引号,各种括号等等,这种压缩算法在数据量庞大的情况下效果也非常可观。
HPack算法提供了几个级别的压缩(从0到4)。等级越高压缩效率越高,每提升一个等级都有引入附加功能。0级压缩通过从结构中分离键值来执行最基本的压缩,并在索引0的元素上创建键名数组,下一个等级就可以通过假设存在重复条目来进一步减小JSON数据的大小。
接下来我们直接用数据来看看这几个压缩算法的压缩效率,我们分别用5组大小不同的JSON文件(50KB~1MB),每个JSON文件将使用servlet容器(tomcat)提供给浏览器,并分别用以下算法进行压缩:
- Original JSON size - 未作修改的JSON数据。
- Minimized - 删除空白和新行(最基本的js优化)。
- Compresse cJSON - 使用CJSON压缩算法进行JSON压缩。
- Compresse HPack - 使用JSON.HPack压缩算法进行JSON压缩。
- Gzipped - 使用gzip和进行JSON压缩。
- Gzipped + Minimized - 使用gzip和删除空白和新行(最基本的js优化)进行JSON压缩。
- Gzipped + Compresse cJSON - 使用gzip和CJSON压缩算法进行JSON压缩。
- Gzipped + Compresse HPack - 使用gzip和JSON.HPack压缩算法进行JSON压缩。
下图(TABLE I.RESULTES)是用以上各种方式处理完后的JSON数据大小(bytes),不同列表示不同的JSON数据集,不同行表示使用不同的压缩方式。
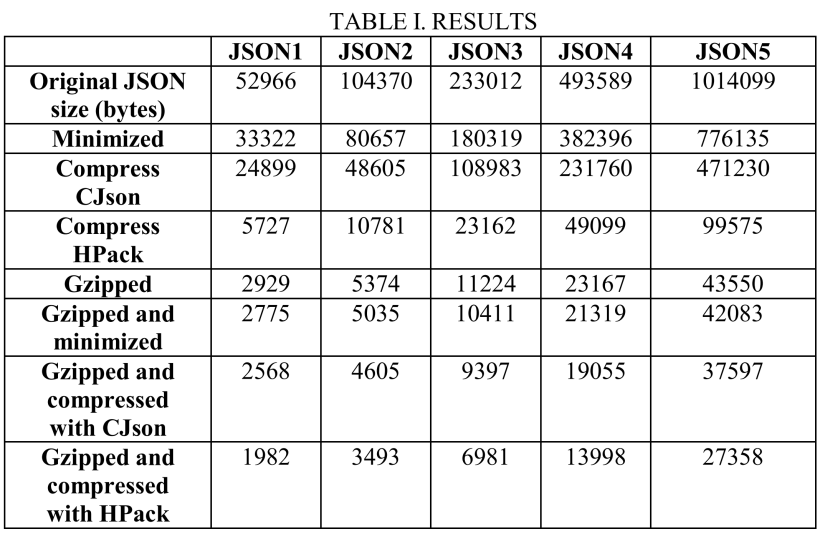
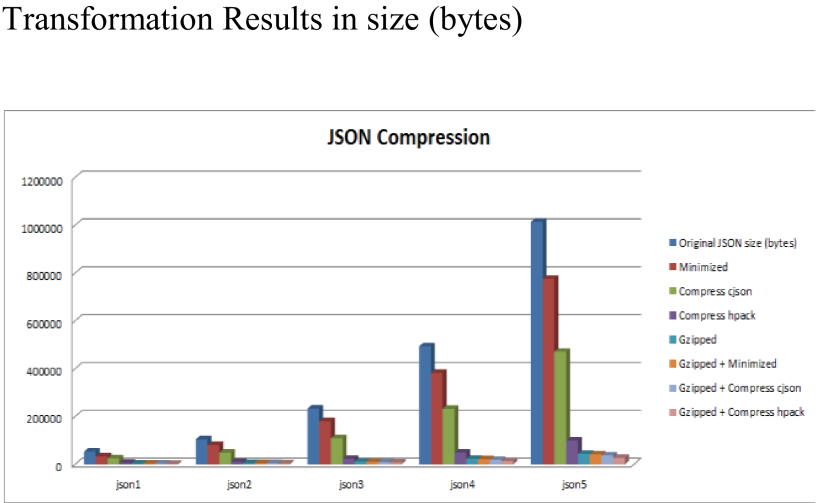
下面第一个图表Y轴表示JSON数据大小(bytes):
第二张图Y轴是JSON数据大小的百分比(%),原始数据为100%:
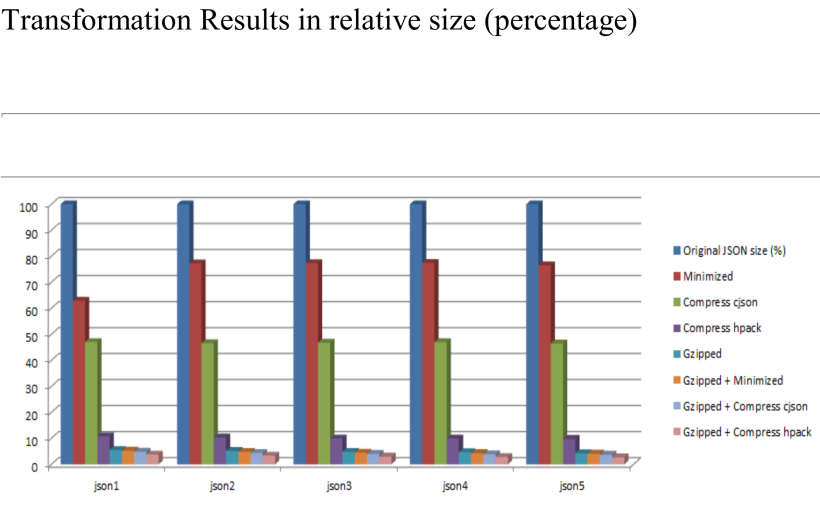
从上面的几个图表中我们可以直观地看到,单独使用cJSON可以把原始数据大小压缩到45%左右,单独使用HPack可以把原始数据大小压缩到8%左右,可见整体上HPack是优于cJSON的。
然而我们可以看到当使用gzip和上面提到的两个压缩算法相结合进行JSON压缩,效果才是最优的,基本可以达到1%~2%的压缩率。
总的来说,HPack比cJSON效率更高,速度也更快,但是在使用压缩算法进行传输的过程中,接收的一端需要进行相应的解压缩操作,否则无法使用被压缩过后的JSON数据,这一步也会存在一定的性能开销,在我们选择使用JSON压缩的时候,也需要考虑到这一点。当可以使用gzip进行压缩的时候,这种方法比其他压缩算法的效率都高,当两者同时结合起来,效果显而易见。
好了,我们这一次完整地了解了JSON序列化的发展,规范,应用以及相关的压缩算法,相信大家不仅对JSON压缩算法有了更深的了解,也对JSON序列化这个技术领域有了深刻的认识。
文章相关附件可以点击下面的原文链接前往下载:
https://ost.51cto.com/resource/2290。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK