

安全生产-系统稳定性建设
source link: https://www.51cto.com/article/718783.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

安全生产-系统稳定性建设
原创作者 | 彭文清(马恪)
安全是产品的底座,是体验的基础,也是企业的一项核心竞争力。安全生产是一项系统性的工作,同时也是一件比较琐碎的事,需要做方方面面的考虑尽一切可能保障系统安全稳定运行。个人之前一直负责商品的稳定性工作,在这方面有比较多的经历和实践。
记得在18年的时候,我们做商品发布的组件化改造,当时正好碰上网站刚开始类目调整,一度连续3个月每个月都有故障,当时稳定性的压力很大。当然那也是一个契机,商品的稳定性建设也是从那个时候开始起步,然后逐步的完善。
安全生产建设大致上可以分为这三个阶段:
事前:故障预防,这里需要考虑的就是怎么通过预先的设计,最大限度的保证质量,降低风险,提升稳定性。
事中:应急处置,出了问题以后怎么处理,快恢手段有哪些,流程是什么。
事后:复盘改进,事后肯定要总结经验,举一反三解决同类的问题,不要被同一棵石头绊倒两次。
魏文王问扁鹊:你医术为啥这么好?扁鹊说:我医术在我三兄弟里面算差的。最好的是我大哥,还没有任何症状就扑灭了,次好是我二哥,一点点轻微的症状就解决了。再次就是我,出了严重的问题我才开始医治,所以虽然我名满天下,但是我医术可比我的大哥二哥差得远啦。
做个类比,故障预防做的好的就是大哥,应急处置做的好的就是二哥,总结复盘做的好的就只能是扁鹊了。所以预防生产事故的发生是最重要的,也是最基础的。
单个技术点在绝大部分时候都可以正常工作,但是当规模和复杂度达到一定程度的时候,失败其实无处不在。--《安全生产指南》
面向失败设计是应对安全生产最重要的方法论和指导方针。只有对各种失败场景有提前的布防才可以在出问题的时候有效应对。那么面向失败设计具体有哪些方式方法?
- 冗余设计避免单点
冗余最早是航空器常用的技术术语,飞机设计最显著的一个特点就是冗余,比如一般大型客机都会有两套甚至四套引擎,类似的还有两套基本同质的主副驾驶系统。为什么要这么设计,还有额外的成本,根本原因还是因为冗余设计可以在一套出现问题时另一套依然能保障系统正常运行。
在ICBU的场景中中美新容灾就是我们最主要的冗余设计,也是稳定性保障最核心的手段。商品是ICBU内第一个构建起中美异地容灾能力的业务场景,也正是因为有了这个能力帮助商品避免了不少的故障发生。
- 服务分治避免雪崩
其实就是做好隔离。中国古代的木船设计有一个很重要的发明叫“水密隔舱”,现在很多军用舰船也有借鉴。典型的像航空母舰据说有2000多个独立的密闭隔仓,作用就是当船舶遭遇意外或者破损进水时,可以通过隔离受损舱室减缓下沉。它是一种安全生产的设计,对我们有借鉴意义,系统要做模块化的设计、薄弱点或者风险点可以被单独隔离和降级,保障整体可用性。我们之前发生过一次问题,因为ES集群中一台物理机故障导致上层应用的线程池被耗尽从而引起服务不可用,根本原因就是隔离没有做好。

服务幂等保证一致服务或接口应该保证幂等,多次调用和一次调用结果应该是一致的,避免重复调用导致数据或逻辑异常。

服务无状态可漂移服务或接口最好设计成无状态模式,从扩展性的角度来讲,无状态模式可以很容易的根据流量情况弹性伸缩。
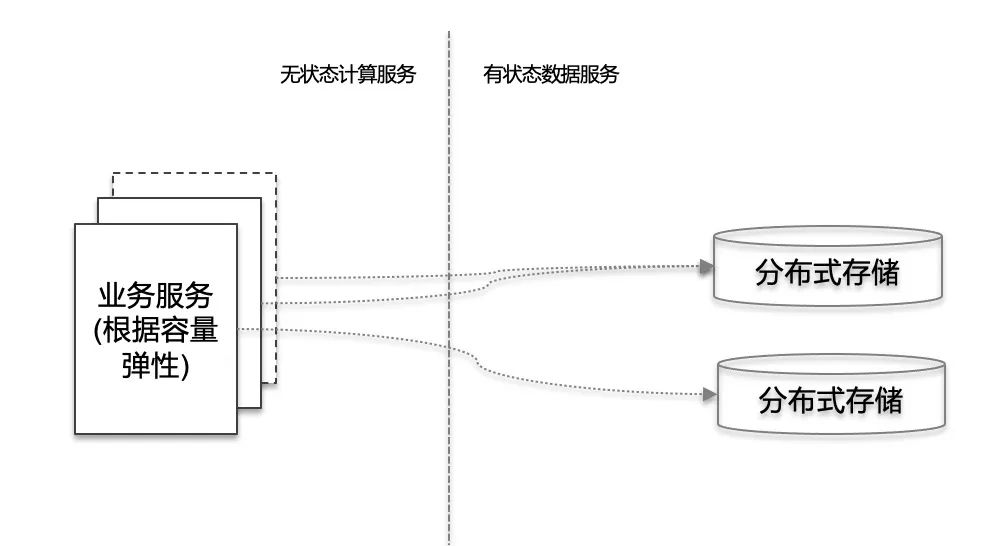
- 运行状态精确监控
把我们的应用系统比做飞机,我们的系统也需要各种传感器和仪表盘去实时监控系统运行状态,系统对于运维人员来说应该是个白盒而不是黑盒。核心的业务或者系统监控有助于提前发现问题,细粒度、多维度的监控有助于快速定位问题。
- 自动化运维管控
最好的处理是不需要处理。核心思路是一切操作标准化、流程化、自动化,降低人为干预、提升操作效率。像商品发布/商品管理都有一些自动容灾预案,可以在出现问题时自动快恢。下面的案例是周末出现的一次风险预警就是通过自动执行快恢避免了线上故障的发生。

另外今年旺铺的一次风险预警,在出现容量性能问题的时候也是通过自动弹性扩容快速解决了问题。
在服务能力受限的情况下,我们需要主动控制客户端并发数。特别是任务型场景,通常有静态限流和动态限流两种选择。静态限流比较简单但有一个局限就是资源利用率不高。动态限流的原理是根据服务端的响应情况动态调整客户端速率,简单来讲就是计算服务超时/异常的数量,超时多了请求就放慢一点。
数据是信息系统中的血液,通过数据的流动才能将一个个业务或功能模块串联在一起。一方面是数据的生产要严格校验保证数据的合法性和准确性。另一方面是数据的消费,需要评估单次处理的数据量、数据处理频次,不要因为高并发、海量数据导致系统内存、负载承压。商品曾经因为这个经历过最惨痛的教训:

批量容错:比如一个列表肯定不能因为某一行有问题而导致整个列表出不来。同样的同步任务也不能因为某一个任务异常而堵塞整个任务队列。所以需要对这些场景做好容错处理,其实还是在强调隔离风险。像商品的引擎同步任务、质量分计算任务都有独立的在线实时队列、实时重试队列、离线队列,目的就是为了不影响实时增量任务的正常执行。
数据兼容:另外有些存量业务,可能已经积累了很多的历史数据。拿商品来举例,今天我们的认知里moq就是最小起订量肯定是数字,包装重量肯定也是数字,但其实之前商品的部分属性是可以自定义的,有些可能是用户随便填的,所以在功能升级迭代的过程中需要考虑对历史数据的兼容。
越简单东西的越可靠,越复杂的东西容错性越低。把简单的事情想复杂,把复杂的事情做简单。少用同步锁:系统设计和编码尽量使用无锁实现,避免引起不必要的死锁问题。商品同样因为同步锁的原因出现过线上问题:

慎用线程池:其实跟同步锁类似,它是一个比较危险的操作,要做好测试和验证。
过载保护过载保护是保障系统整体可用的重要手段之一,设计过载保护可以有效避免因为流量问题导致的系统不可用。所以我们的应用要具备自我防护的能力,web型应用接入流量清洗系统,服务型应用做好服务限流。
依赖降级当前大部分的业务系统都比较复杂,特别是在分布式架构中,一个请求可能依赖多个系统支撑共同完成。调用链路中的任何一个节点都可能影响整体稳定性。所以一方面我们要保证自身服务的稳定性,另外一方面也要考虑在依赖服务出现问题后怎么保证主链路的可用。而依赖降级的前提是先理清依赖关系:
1.弱依赖就自动降级比如校验类的。
2.有一些是强依赖但可以异步处理的就降级后异步重试。
3.有一些是强依赖又不能异步的,就需要产品化了,把降级能力作为产品设计的一部分。
下图是商品发布链路的部分容灾降级点:
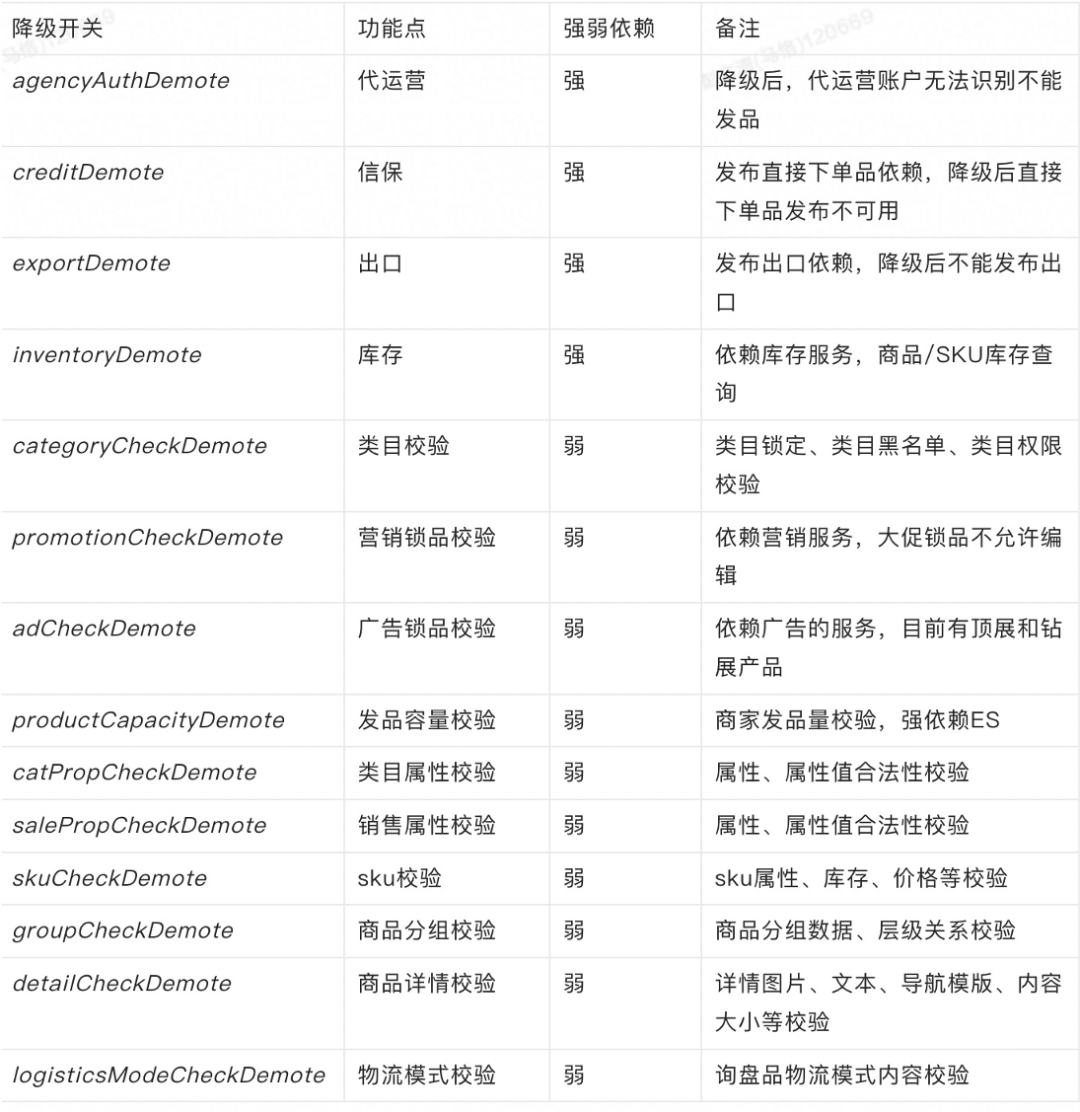
这其中超过95%都从来没有使用过。安全生产的建设就是这样,很多稳定性保障措施大部分时候都默默无闻,但是真正使用到的时候却都是关键的时刻。
- 监控标准化
一堆无意义的"System Error"无济于事,标准错误码和SPM监控是当前比较好的一个实践。
- 预警有效性
召回优先:预警有效性其实比较难做,监控覆盖度越广,预警机制越灵敏,报警量可能就会越多,误报也会越多。商品无人值守样板间在开始时候也是召回优先,误报慢慢收敛,这是一个持续治理的过程。
报警分层:另外可以根据监控场景对报警分层, 通过报警分层一定程度上可以兼顾召回和免打扰。重要的业务系统监控推送到核心预警群,非故障场景或者辅助定位的监控报警可以推送到其他普通预警群。同样也需要对报警通知方式做分层,比如成本率下跌2%可能是钉钉通知,下跌5%就需要电话通知。
测试回归是质量保障很重要的一个环节。
单测我相信有人会怀疑它的价值,而且在刚开始的时候的确比较耗费时间精力,但是它是一个难而正确的事情,这里分享两点:
单测是代码的照妖镜,我们会发现通常单测很难跑起来的往往就是代码设计不合理,耦合过多,单测可以帮助自己优化代码。
单测是质量的保证。前端时间跟我对接的前端同学突然跟我说,“文清,没想到这次项目这么顺利”,这个项目也是我个人第一次在一个项目里写完整的单测代码。从我个人的实践经历来看,单测特别是对于喜欢重构的人来说还是非常有价值的。
- 巡检/流量回放
我们当前的业务大部分都比较复杂,有非常多的分支流程。举个例子商品有5000多个叶子类目,每个类目的商品表单是不一样的,这么多的场景靠人肉是根本覆盖不了的,只能靠机器和自动化去回归。前台页面场景巡检是一个比较好的方式,它可以模拟用户操作。对于后台服务流量回放也是一种可行的方案,商品无人值守样板间也在使用巡检和流量回放来保障发布质量。
新的服务上线前需要评估流量和性能情况,根据预估对服务进行压测以验证是否能够满足需求。同时整个链路能够支撑的QPS上限也需要通过压测确定,帮助我们合理的评估系统水位。
回过头去分析会发现其实我们大部分问题都是变更引入的。商家技术部三规九条里有规定变更发布三原则 “可灰度、可监控、可回滚”。发布之前要做好发布计划和评审,检查是否满足这三个要素。
灰度分为功能灰度和发布灰度,功能灰度可以根据自己的团队情况设计。发布灰度首先从流程上建议增加小流量灰度环境,部分流量可以劫持到小流量环境,一些重大的问题可以在小流量环境提前发现。另外有条件的应用也建议分单元/分区域分开部署,短时间内模拟蓝绿部署,为容灾切流创造条件。
对于回滚,切记要做回滚验证,不要一股脑不暂停回滚完。因为之前碰到过一个案例,越回滚问题越严重,原因是当时的问题是远程缓存异常导致应用启动后出现数据异常,回滚重启后又导致已发布机器本地缓存失效放大了影响面。
故障预防是降低问题发生的概率,不是消灭问题。根据墨菲定律,只要存在可能就一定会发生。所以应急处置就是我们的兜底手段,是保证高可用性的重要一环。
出现故障我们首先需要做的不是定位原因,而是及时止血和快速恢复,而容灾切流往往是快恢的首选,时效性最高。
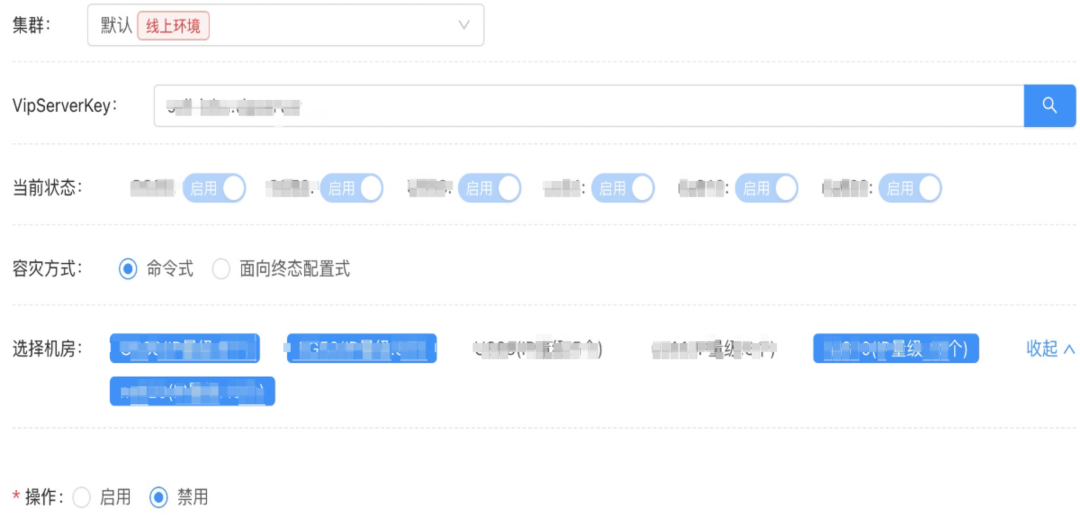
web型应用:当前成熟的方案是vipserver容灾机制。原理也很简单,多单元的机器都挂载到vipserverkey下,正常情况下因为同机房规则生效请求都是单元内调用。当需要容灾时拉黑异常单元下的机器,同机房规则失效流量就会串流到其他单元从而达到跨单元容灾的效果。
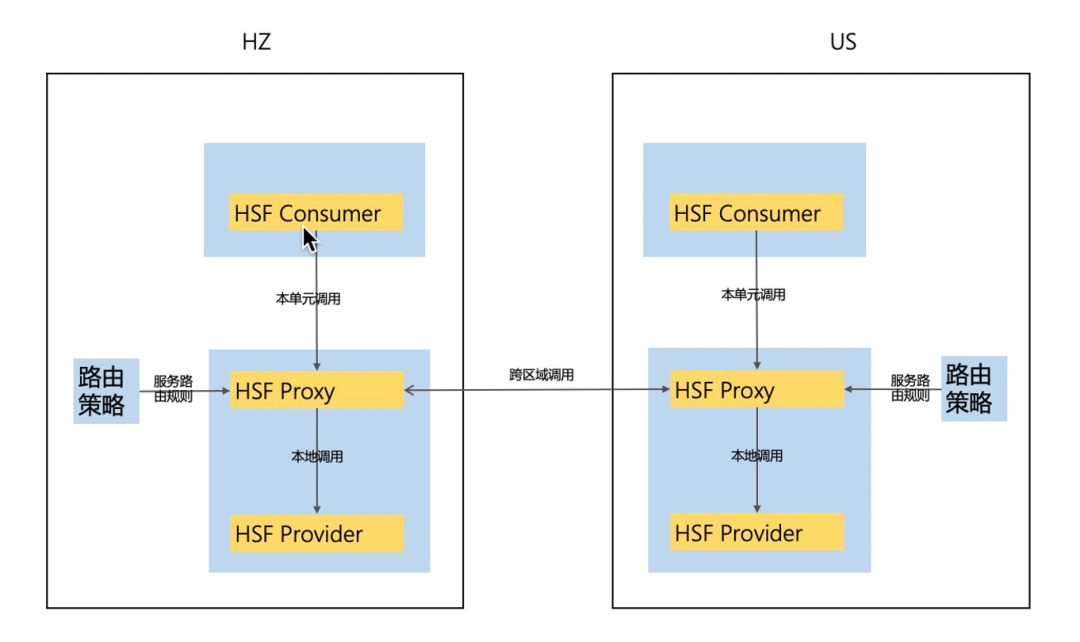
服务型应用:当前还没有特别标准的方案,商品的做法是使用代理服务多地注册,在容灾切流时通过调用不同单元的代理服务来达到跨单元切流的效果。
出现线上问题的时候,如果无法通过容灾切流的手段解决就要看一下有没有变更发布,判断如果可能跟变更有关就先回滚,重要的还是要做好回滚验证。
遇到突发流量、下游系统慢或本身资源容量不足都可能导致应用自身负载承压。在遇到资源瓶颈的时候快速扩容就是首选,这个时候考验的是系统的弹性能力。当前也有一些可行的方案:
- VPA:基于CPU/内存垂直弹性,调整的是cpu核数和内存大小,不过有上限。
- HPA:基于CPU/内存水平弹性,缺点就是扩容速度不够快,还是要经历应用启动的过程,应对突发的流量波峰可能不太可行。
- KPA:基于流量/响应水平弹性,据称是CSE的替代者,猜测应该可以通过回放内存镜像来实现快速扩容。
当无法扩容的时候,重启是解决系统性能问题的另一个重要手段。据不科学的统计,90%的暂不明原因的性能问题可以通过重启暂时解决或一定程度上缓解。
面对容量问题,除了扩容以外另一个选择就是限流和降级,可以根据重要程度优先对边缘应用和非核心场景做限制。
- 分层分场景:我们支撑的业务肯定是有优先级的,有核心的业务,也有边缘场景。当需要做限流降级处置的时候不能一刀切,要根据重要程度先对非重要的应用作限制。
- 分用户粒度:同样我们服务的用户也是有优先级的。以商品为例有付费商家和免费商家,那么在整体资源受限的情况下就可以先对免费商家做降级处理。
- 根据资源占用分层:像商品场景存在品量非常多的商家,这部分用户的某些操作可能对系统资源占用比较大,比较常见的就是引起数据热点或者数据偏移,而这些都是影响性能的因素,所以对资源占用大户也要有对应的处置措施,比如禁读禁写。
如果短时间内无法恢复(参考1-5-10标准),那么就需要挂应急公告减少用户进线,每个业务场景的应急公告应该预先编制完成,在有需要时一键执行。
应急处置的方案有很多,但是在处理线上问题时应该是有优先级的,先做什么其次做什么最后做什么。下图是整理的一份应急处置SOP参考文档。它不是操作手册,不能在出问题时再去查阅,而是每个人脑子里应该有这样一张图,对于线上应急处理流程烂熟于胸。
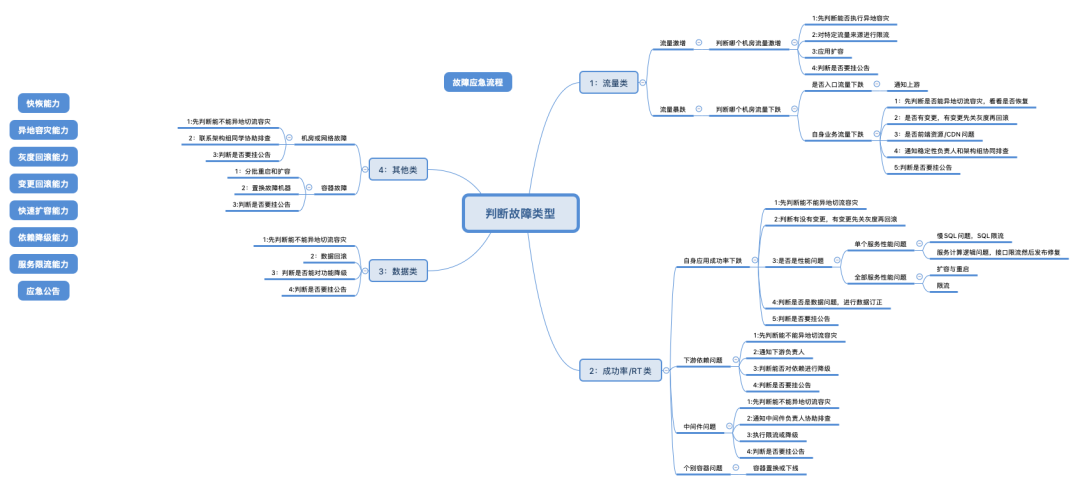
所有的安全生产的措施都做好了,那么怎么验证它可以正常工作,故障演练是很好的手段。一方面可以检验稳定性保障措施的可用性,另外一方面也可以锻炼技术人员的应急处理能力。我看到过不止一次有人在处理故障时很紧张手都在抖。所以常态化的故障演练,特别是突袭演练可以让更多人参与到应急处理的过程中去,多实践才可以在真正发生问题的时候有条不紊。
出问题不可怕,重要的是分析这个过程中存在什么问题,流程机制上有什么漏洞,从而帮助我们做的更好。商品的稳定性措施就是在一次次面对各种问题的过程中总结和实践的。
归纳总结是利己,避免自己再犯相同的错误。经验分享是利他,帮助别人不要掉到同样的坑里。另外技术风险防控平台里的大部分故障都是公开的,可以看看自己的应用有没有同样的风险。
风险意识:做好稳定性最重要的是要有风险意识,对生产保持敬畏之心。有风险意识才会在产研的全流程中关注稳定性的事情。比如新引入了一个依赖,就会考虑它异常了对于自己有什么影响,有没有容灾方案,能不能降级等等。另外有风险意识也会慢慢的形成一些良好的习惯,比如定期Review系统水位,我个人每天早上刚到公司做的第一件事就是看一下监控和报警。
减少损失:应急处置的第一原则是把损失降到最低,先恢复,再定位。
风险自愈:安全生产建设最终的目的应该是具备自愈能力,在系统出现问题时能够及时介入并自动恢复。
向人体学习,他拥有一套三重的免疫系统,这是一个百年的相当稳定的系统。-- 鲁肃
所以事前要有风险意识,事中要及时止损,事后查漏补缺构建风险自愈的能力。更重要的是秉持长期主义的精神,相信最终能够做好安全生产的事情。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK