

openGauss数据库之SQL介绍
source link: https://blog.51cto.com/u_13824494/5655792
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

目录
一、什么是SQL?
1、SQL的概念
2、SQL的特点
3、SQL发展简史
二、openGauss数据库的“SQL”
1、数据类型(常用)
日期/时间类型
2、openGauss数据库SQL基本语法
创建用户(CREATE USER)
创建和管理数据库
创建表(CREATE TABLE)
向表中插入数据
更新表中数据
删除表中数据
三、参考资料
一、什么是SQL?
1、SQL的概念
结构化查询语言(SQL)是用于访问和处理关系型数据库的标准计算机语言。
SQL提供了各种任务的语句,包括:
- 查询数据。
- 在表中插入,更新和删除行。
- 创建,替换,更改和删除对象。
- 控制对数据库及其对象的访问。
- 保证数据库的一致性和完整性。
SQL语言由用于处理数据库和数据库对象的命令和函数组成:
- DDL(data definition language)数据定义语言,用户定义和管理sql数据库中所有对象的语言。 主要命令:create、alter、drop等
- DML(data manipulation language)数据操作语言。 主要命令:select、update、insert、delete等
- DCL(date control language)数据库控制功能。主要命令:grant、deny、revoke、commit、savepoint、rollback等
2、SQL的特点
- SQL语言集数据查询、数据操纵、数据定义和数据控制功能于一体
- 面向集合的语言
- 非过程语言
- 类似自然语言,简洁易用
- 自含式语言,又是嵌入式语言。可独立使用,也可嵌入到宿主语言中。
3、SQL发展简史
SQL发展简史如下:
- 1986年,ANSI X3.135-1986,ISO/IEC 9075:1986,SQL-86
- 1989年,ANSI X3.135-1989,ISO/IEC 9075:1989,SQL-89
- 1992年,ANSI X3.135-1992,ISO/IEC 9075:1992,SQL-92(SQL2)
- 1999年,ISO/IEC 9075:1999,SQL:1999(SQL3)
- 2003年,ISO/IEC 9075:2003,SQL:2003(SQL4)
- 2011年,ISO/IEC 9075:200N,SQL:2011(SQL5)
ANSI是美国国家标准学会(American National Standards Institute)的英文简称,成立于1918年。
ISO:国际标准化组织(International Organization for Standardization)。
IEC:国际电工委员会(International Electrotechnical Commission)。
二、openGauss数据库的“SQL”
openGauss数据库支持的SQL标准,默认支持SQL2、SQL3和SQL4的主要特性。当然了, 一般说到数据库的SQL语句,就离不开两个方面: 一是数据类型,二是sql语句基本语法。下文就此简单阐述一下:
1、数据类型(常用)
openGauss数据库支持的数据类型涵盖非常广, 几乎包含所有形式的数据类型,如:数值类型、货币类型、布尔类型、字符类型、二进制类型、日期/时间类型、几何类型、网络地址类型、位串类型、文本搜索类型、UUID类型、JSON/JSONB类型、HLL数据类型、范围类型、对象标识符类型、伪类型、列存表支持的数据类型、XML类型、账本数据库使用的数据类型等。 但是实际业务场景中大部分类型用到的比较少,具体遇到时可参考官方文档说明。
下文参考并整理了日常应用开发中常用的主要数据类型,主要包含:数值类型、货币类型、布尔类型、字符类型、日期/时间类型等。
表1:整数数据类型
名称 | 描述 | 存储空间 | 范围 |
TINYINT | 微整数,别名为INT1。 | 0 ~ 255 | |
SMALLINT | 小范围整数,别名为INT2。 | -32,768 ~ +32,767 | |
INTEGER | 常用的整数,别名为INT4 / BINARY_INTEGER。 | -2,147,483,648 ~ +2,147,483,647 | |
BIGINT | 大范围的整数,别名为INT8。 | -9,223,372,036,854,775,808 ~ +9,223,372,036,854,775,807 | |
int16 | 十六字节的大范围证书,目前不支持用户用于建表等使用。 | -170,141,183,460,469,231,731,687,303,715,884,105,728 +170,141,183,460,469,231,731,687,303,715,884,105,727 |
说明:TINYINT、SMALLINT、INTEGER、BIGINT和INT16类型存储各种范围的数字,也就是整数。试图存储超出范围以外的数值将会导致错误。
常用的类型是INTEGER,因为它提供了在范围、存储空间、性能之间的最佳平衡。一般只有取值范围确定不超过SMALLINT的情况下,才会使用SMALLINT类型。而只有在INTEGER的范围不够的时候才使用BIGINT,因为前者相对快得多。
表2:任意精度型
名称 | 描述 | 存储空间 | 范围 |
NUMERIC[(p[,s])], DECIMAL[(p[,s])] | 精度p取值范围为[1,1000],标度s取值范围为[0,p]。 p为总位数,s为小数位数。 | 用户声明精度。每四位(十进制位)占用两个字节,然后在整个数据上加上八个字节的额外开销。 | 未指定精度的情况下,小数点前最大131,072位,小数点后最大16,383位。 |
NUMBER[(p[,s])] | NUMERIC类型的别名。 | 用户声明精度。每四位(十进制位)占用两个字节,然后在整个数据上加上八个字节的额外开销。 | 未指定精度的情况下,小数点前最大131,072位,小数点后最大16,383位。 |
说明:与整数类型相比,任意精度类型需要更大的存储空间,其存储效率、运算效率以及压缩比效果都要差一些。在进行数值类型定义时,优先选择整数类型。当且仅当数值超出整数可表示最大范围时,再选用任意精度类型。
使用Numeric/Decimal进行列定义时,建议指定该列的精度p以及标度s。
表3:序列整型
名称 | 描述 | 存储空间 | 范围 |
SMALLSERIAL | 二字节序列整型。 | -32,768 ~ +32,767 | |
SERIAL | 四字节序列整型。 | -2,147,483,648 ~ +2,147,483,647 | |
BIGSERIAL | 八字节序列整型。 | -9,223,372,036,854,775,808 ~ +9,223,372,036,854,775,807 | |
LARGESERIAL | 默认插入十六字节序列整形,实际数值类型和numeric相同。 | 变长类型,每四位(十进制位)占用两个字节,然后在整个数据上加上八个字节的额外开销。 | 小数点前最大131,072位,小数点后最大16,383位。 |
说明:SMALLSERIAL、SERIAL、BIGSERIAL和LARGESERIAL类型不是真正的类型,只是为在表中设置唯一标识做的概念上的便利。因此,创建一个整数字段,并且把它的缺省数值安排为从一个序列发生器读取。应用了一个NOT NULL约束以确保NULL不会被插入。在大多数情况下用户可能还希望附加一个UNIQUE或PRIMARY KEY约束避免意外地插入重复的数值,但这个不是自动的。最后,将序列发生器从属于那个字段,这样当该字段或表被删除的时候也一并删除它。目前只支持在创建表时候指定SERIAL列,不可以在已有的表中,增加SERIAL列。另外临时表也不支持创建SERIAL列。因为SERIAL不是真正的类型,也不可以将表中存在的列类型转化为SERIAL。
表4:浮点类型
名称 | 描述 | 存储空间 | 范围 |
REAL, FLOAT4 | 单精度浮点数,不精准。 | -3.402E+38~3.402E+38,6位十进制数字精度。 | |
DOUBLE PRECISION, FLOAT8 | 双精度浮点数,不精准。 | -1.79E+308~1.79E+308,15位十进制数字精度。 | |
FLOAT[(p)] | 浮点数,不精准。精度p取值范围为[1,53]。 p为精度,表示总位数。 | 4字节或8字节 | 根据精度p不同选择REAL或DOUBLE PRECISION作为内部表示。如不指定精度,内部用DOUBLE PRECISION表示。 |
BINARY_DOUBLE | 是DOUBLE PRECISION的别名。 | -1.79E+308~1.79E+308,15位十进制数字精度。 | |
DEC[(p[,s])] | 精度p取值范围为[1,1000],标度s取值范围为[0,p]。 p为总位数,s为小数位位数。 | 用户声明精度。每四位(十进制位)占用两个字节,然后在整个数据上加上八个字节的额外开销。 | 未指定精度的情况下,小数点前最大131,072位,小数点后最大16,383位。 |
INTEGER[(p[,s])] | 精度p取值范围为[1,1000],标度s取值范围为[0,p]。 | 用户声明精度。每四位(十进制位)占用两个字节,然后在整个数据上加上八个字节的额外开销。 |
货币类型存储带有固定小数精度的货币金额
名称 | 存储容量 | 描述 | 范围 |
money | -92233720368547758.08 到 +92233720368547758.07 |
名称 | 描述 | 存储空间 | 取值 |
BOOLEAN |
|
说明:“真”值的有效文本值是:TRUE、't'、'true'、'y'、'yes'、'1' 、'TRUE'、true、整数范围内12^63-1、整数范围内-1-2^63。“假”值的有效文本值是:FALSE、'f'、'false'、'n'、'no'、'0'、0、'FALSE'、false。
使用TRUE和FALSE是比较规范的用法(也是SQL兼容的用法)。
名称 | 描述 | 存储空间 |
CHAR(n) CHARACTER(n) NCHAR(n) | 定长字符串,不足补空格。n是指字节长度,如不带精度n,默认精度为1。 | 最大为10MB。 |
VARCHAR(n) CHARACTER VARYING(n) | 变长字符串。PG兼容模式下,n是字符长度。其他兼容模式下,n是指字节长度。 | 最大为10MB。 |
VARCHAR2(n) | 变长字符串。是VARCHAR(n)类型的别名。n是指字节长度。 | 最大为10MB。 |
NVARCHAR2(n) | 变长字符串。n是指字符长度。 | 最大为10MB。 |
NVARCHAR(n) | 变长字符串。是NVARCHAR2(n)类型的别名。n是指字符长度。 | 最大为10MB。 |
变长字符串。 | 最大为1GB-1,但还需要考虑到列描述头信息的大小, 以及列所在元组的大小限制(也小于1GB-1),因此TEXT类型最大大小可能小于1GB-1。 | |
文本大对象。是TEXT类型的别名。 | 最大为1GB-1,但还需要考虑到列描述头信息的大小, 以及列所在元组的大小限制(也小于1GB-1),因此CLOB类型最大大小可能小于1GB-1。 |
日期/时间类型
名称 | 描述 | 存储空间 |
日期和时间。 | 4字节(兼容模式A下存储空间大小为8字节) | |
TIME [(p)] [WITHOUT TIME ZONE] | 只用于一日内时间。 p表示小数点后的精度,取值范围为0~6。 | |
TIME [(p)] [WITH TIME ZONE] | 只用于一日内时间,带时区。 p表示小数点后的精度,取值范围为0~6。 | |
TIMESTAMP[(p)] [WITHOUT TIME ZONE] | 日期和时间。 p表示小数点后的精度,取值范围为0~6。 | |
TIMESTAMP[(p)][WITH TIME ZONE] | 日期和时间,带时区。TIMESTAMP的别名为TIMESTAMPTZ。 p表示小数点后的精度,取值范围为0~6。 | |
SMALLDATETIME | 日期和时间,不带时区。 精确到分钟,秒位大于等于30秒进一位。 | |
INTERVAL DAY (l) TO SECOND (p) | 时间间隔,X天X小时X分X秒。
| |
INTERVAL [FIELDS] [ (p) ] | 时间间隔。
| |
reltime | 相对时间间隔。格式为: X years X mons X days XX:XX:XX。 采用儒略历计时,规定一年为365.25天,一个月为30天,计算输入值对应的相对时间间隔,输出采用POSTGRES格式。 | |
abstime | 日期和时间。格式为: YYYY-MM-DD hh:mm:ss+timezone 取值范围为1901-12-13 20:45:53 GMT~2038-01-18 23:59:59 GMT,精度为秒。 |
2、openGauss数据库SQL基本语法
SQL 语法主要分为三个类型DDL、DML、DCL,对应13个动词:
DDL(data definition language)数据定义语言,用户定义和管理sql数据库中所有对象的语言。 主要命令:create、alter、drop等
DML(data manipulation language)数据操作语言。 主要命令:select、update、insert、delete等
DCL(date control language)数据库控制功能。主要命令:grant、deny、revoke、commit、savepoint、rollback等
常见语法示例,主要包括: 创建用户、创建和管理数据库、创建表、插入数据、更新数据、查看数据、删除数据等
创建用户(CREATE USER)
--创建用户jim,登录密码为xxxxxxxxx。
openGauss=# CREATE USER jim PASSWORD 'xxxxxxxxx';
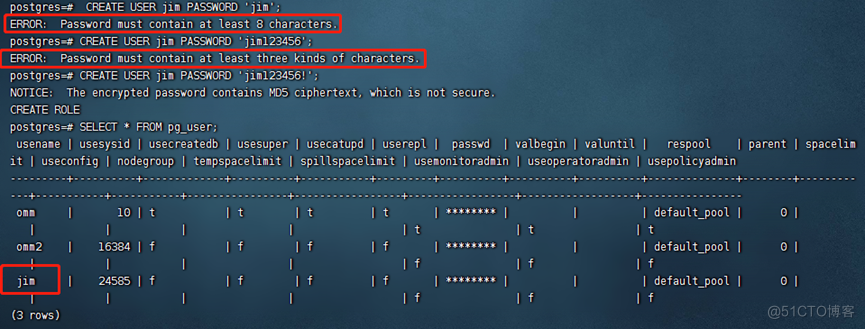
说明:必须至少8个字符,且至少包含3种字符(要符合常规密码安全度设置要求)。
--下面语句与上面的等价。
openGauss=# CREATE USER kim IDENTIFIED BY 'xxxxxxxxx';
--如果创建有“创建数据库”权限的用户,则需要加CREATEDB关键字。
openGauss=# CREATE USER dim CREATEDB PASSWORD 'xxxxxxxxx';

--将用户jim的登录密码由xxxxxxxxx修改为Abcd@123。
openGauss=# ALTER USER jim IDENTIFIED BY 'Abcd@123' REPLACE 'xxxxxxxxx';

说明:新密码不能使用之前用过的密码。
--为用户jim追加CREATEROLE权限。
openGauss=# ALTER USER jim CREATEROLE;
--将enable_seqscan的值设置为on, 设置成功后,在下一会话中生效。
openGauss=# ALTER USER jim SET enable_seqscan TO on;
--重置jim的enable_seqscan参数。
openGauss=# ALTER USER jim RESET enable_seqscan;
--锁定jim帐户。
openGauss=# ALTER USER jim ACCOUNT LOCK;
--删除用户。
openGauss=# DROP USER kim CASCADE;
openGauss=# DROP USER jim CASCADE;
openGauss=# DROP USER dim CASCADE;
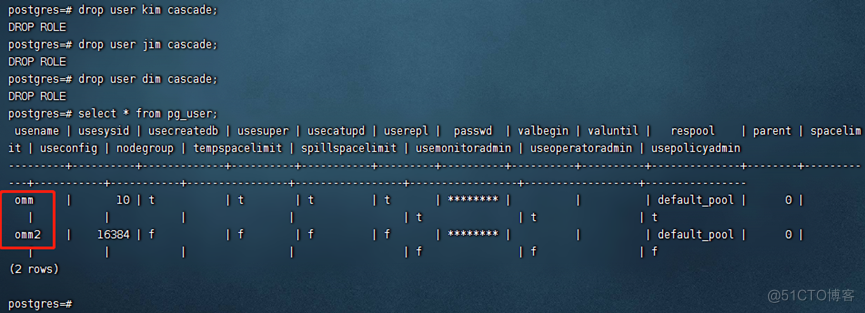
说明:CASCADE,删除用户关联的所有对象。
创建和管理数据库
--使用如下命令创建一个新的数据库db_tpcc。
openGauss=# CREATE DATABASE db_tpcc;
--查看数据库
使用\l元命令查看数据库系统的数据库列表。
openGauss=# \l
使用如下命令通过系统表pg_database查询数据库列表。
openGauss=# SELECT datname FROM pg_database;
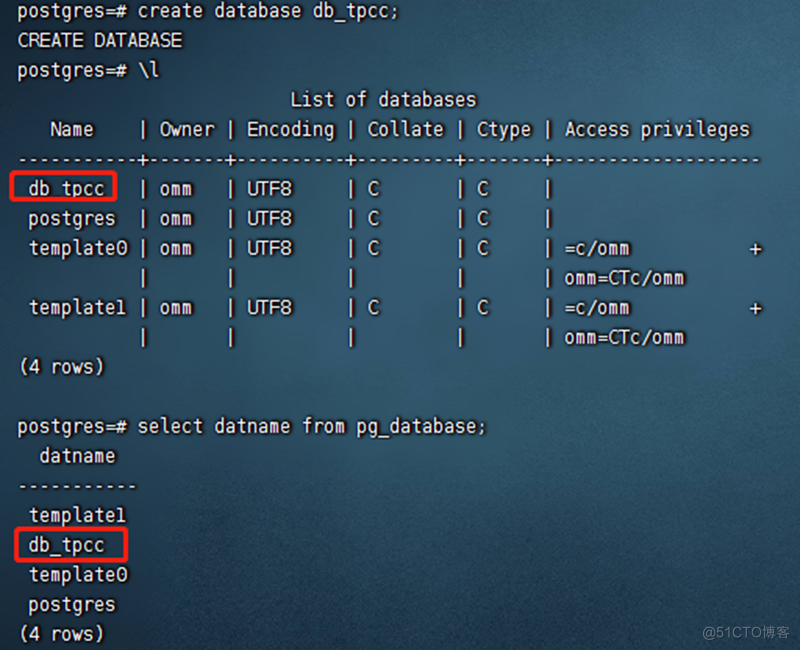
注:数据库名称遵循SQL标识符的一般规则。当前角色自动成为此新数据库的所有者。
如果一个数据库系统用于承载相互独立的用户和项目,建议把它们放在不同的数据库里。
如果项目或者用户是相互关联的,并且可以相互使用对方的资源,则应该把它们放在同一个数据库里,但可以规划在不同的模式中。模式只是一个纯粹的逻辑结构,某个模式的访问权限由权限系统模块控制。
创建数据库时,若数据库名称长度超过63字节,server端会对数据库名称进行截断,保留前63个字节,因此建议数据库名称长度不要超过63个字节。
--修改数据库
用户可以使用如下命令修改数据库属性(比如:owner、名称和默认的配置属性)。
使用以下命令为数据库设置默认的模式搜索路径。
openGauss=# ALTER DATABASE db_tpcc SET search_path TO pa_catalog,public;
--使用如下命令为数据库重新命名。
openGauss=# ALTER DATABASE db_tpcc RENAME TO human_tpcds;
--删除数据库
用户可以使用DROP DATABASE命令删除数据库。这个命令删除了数据库中的系统目录,并且删除了磁盘上带有数据的数据库目录。用户必须是数据库的owner或者系统管理员才能删除数据库。当有人连接数据库时,删除操作会失败。删除数据库时请先连接到其他的数据库。
使用如下命令删除数据库:
openGauss=# DROP DATABASE db_tpcc;
创建表(CREATE TABLE)
--表是建立在数据库中的,在不同的数据库中可以存放相同的表。甚至可以通过使用模式在同一个数据库中创建相同名称的表。创建表前请先规划存储模型。
openGauss=# CREATE TABLE customer_t1
c_customer_sk integer,
c_customer_id char(5),
c_first_name char(6),
c_last_name char(8)
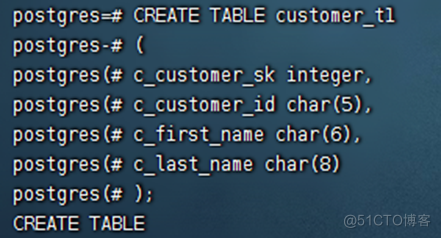
当结果显示为如下信息,则表示创建成功。
CREATE TABLE
其中c_customer_sk 、c_customer_id、c_first_name和c_last_name是表的字段名,integer、char(5)、char(6)和char(8)分别是这四字段名称的类型。
向表中插入数据
--向表中插入数据前,意味着表已创建成功。
向表customer_t1中插入一行:
数据值是按照这些字段在表中出现的顺序列出的,并且用逗号分隔。通常数据值是文本(常量),但也允许使用标量表达式。
openGauss=# INSERT INTO customer_t1(c_customer_sk, c_customer_id, c_first_name) VALUES (3769, 'hello', 'Grace');
如果用户已经知道表中字段的顺序,也可无需列出表中的字段。例如以下命令与上面的命令效果相同。
openGauss=# INSERT INTO customer_t1 VALUES (3769, 'hello', 'Grace');
如果用户不知道所有字段的数值,可以忽略其中的一些。没有数值的字段将被填充为字段的缺省值。例如:
openGauss=# INSERT INTO customer_t1 (c_customer_sk, c_first_name) VALUES (3769, 'Grace');
openGauss=# INSERT INTO customer_t1 VALUES (3769, 'hello');
用户也可以对独立的字段或者整个行明确缺省值:
openGauss=# INSERT INTO customer_t1 (c_customer_sk, c_customer_id, c_first_name) VALUES (3769, 'hello', DEFAULT);
openGauss=# INSERT INTO customer_t1 DEFAULT VALUES;
如果需要在表中插入多行,请使用以下命令:
openGauss=# INSERT INTO customer_t1 (c_customer_sk, c_customer_id, c_first_name) VALUES
(6885, 'maps', 'Joes'),
(4321, 'tpcds', 'Lily'),
(9527, 'world', 'James');
如果需要向表中插入多条数据,除此命令外,也可以多次执行插入一行数据命令实现。但是建议使用此命令可以提升效率。
如果从指定表插入数据到当前表,例如在数据库中创建了一个表customer_t1的备份表customer_t2,现在需要将表customer_t1中的数据插入到表customer_t2中,则可以执行如下命令。
openGauss=# CREATE TABLE customer_t2
c_customer_sk integer,
c_customer_id char(5),
c_first_name char(6),
c_last_name char(8)
openGauss=# INSERT INTO customer_t2 SELECT * FROM customer_t1;
从指定表插入数据到当前表时,若指定表与当前表对应的字段数据类型之间不存在隐式转换,则这两种数据类型必须相同。
删除备份表
openGauss=# DROP TABLE customer_t2 CASCADE;
在删除表的时候,若当前需删除的表与其他表有依赖关系,需先删除关联的表,然后再删除当前表。
更新表中数据
修改已经存储在数据库中数据的行为叫做更新。用户可以更新单独一行,所有行或者指定的部分行。还可以独立更新每个字段,而其他字段则不受影响。
使用UPDATE命令更新现有行,需要提供以下三种信息:
- 表的名称和要更新的字段名
- 字段的新值
- 要更新哪些行
SQL通常不会为数据行提供唯一标识,因此无法直接声明需要更新哪一行。但是可以通过声明一个被更新的行必须满足的条件。只有在表里存在主键的时候,才可以通过主键指定一个独立的行。
建立表和插入数据的步骤请参考创建表和向表中插入数据。
需要将表customer_t1中c_customer_sk为9527的地域重新定义为9876:
openGauss=# UPDATE customer_t1 SET c_customer_sk = 9876 WHERE c_customer_sk = 9527;
这里的表名称也可以使用模式名修饰,否则会从默认的模式路径找到这个表。SET后面紧跟字段和新的字段值。新的字段值不仅可以是常量,也可以是变量表达式。
比如,把所有c_customer_sk的值增加100:
openGauss=# UPDATE customer_t1 SET c_customer_sk = c_customer_sk + 100;
在这里省略了WHERE子句,表示表中的所有行都要被更新。如果出现了WHERE子句,那么只有匹配其条件的行才会被更新。
在SET子句中的等号是一个赋值,而在WHERE子句中的等号是比较。WHERE条件不一定是相等测试,许多其他的操作符也可以使用。
用户可以在一个UPDATE命令中更新更多的字段,方法是在SET子句中列出更多赋值,比如:
openGauss=# UPDATE customer_t1 SET c_customer_id = 'Admin', c_first_name = 'Local' WHERE c_customer_sk = 4421;
批量更新或删除数据后,会在数据文件中产生大量的删除标记,查询过程中标记删除的数据也是需要扫描的。故多次批量更新/删除后,标记删除的数据量过大会严重影响查询的性能。建议在批量更新/删除业务会反复执行的场景下,定期执行VACUUM FULL以保持查询性能。
使用系统表pg_tables查询数据库所有表的信息。
openGauss=# SELECT * FROM pg_tables;
使用gsql的\d+命令查询表的属性。
openGauss=# \d+ customer_t1;
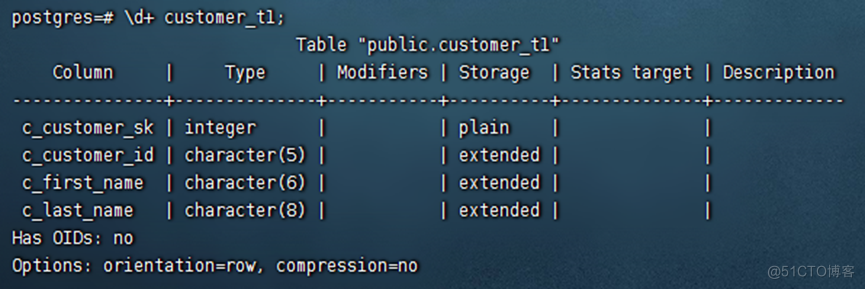
执行如下命令查询表customer_t1的数据量。
openGauss=# SELECT count(*) FROM customer_t1;
执行如下命令查询表customer_t1的所有数据。
openGauss=# SELECT * FROM customer_t1;
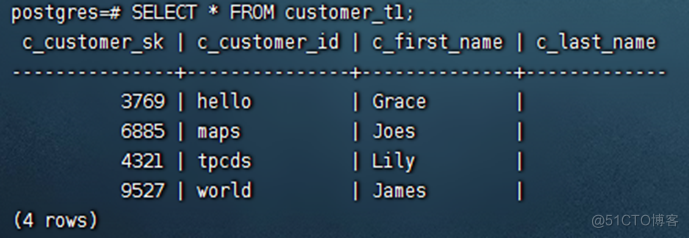
说明:插数据时,没有数值的字段将被填充为字段的缺省值。
执行如下命令只查询字段c_customer_sk的数据。
openGauss=# SELECT c_customer_sk FROM customer_t1;
执行如下命令过滤字段c_customer_sk的重复数据。
openGauss=# SELECT DISTINCT( c_customer_sk ) FROM customer_t1;
执行如下命令查询字段c_customer_sk为3869的所有数据。
openGauss=# SELECT * FROM customer_t1 WHERE c_customer_sk = 3869;
执行如下命令按照字段c_customer_sk进行排序。
openGauss=# SELECT * FROM customer_t1 ORDER BY c_customer_sk;
删除表中数据
在使用表的过程中,可能会需要删除已过期的数据,删除数据必须从表中整行的删除。
SQL不能直接访问独立的行,只能通过声明被删除行匹配的条件进行。如果表中有一个主键,用户可以指定准确的行。用户可以删除匹配条件的一组行或者一次删除表中的所有行。
使用DELETE命令删除行,如果删除表customer_t1中所有c_customer_sk为3869的记录:
openGauss=# DELETE FROM customer_t1 WHERE c_customer_sk = 3869;
如果执行如下命令之一,会删除表中所有的行。
openGauss=# DELETE FROM customer_t1;
openGauss=# TRUNCATE TABLE customer_t1;
全表删除的场景下,建议使用truncate,不建议使用delete。
删除创建的表:
openGauss=# DROP TABLE customer_t1;
三、参考资料:
1.openGauss官方文档3.0.0 开发指南:
https://www.opengauss.org/zh/docs/3.0.0/docs/Developerguide/Developerguide.html
2.SQL实践操作经验
作者:酷哥; 转载:Gauss松鼠会
Recommend
-
28
作者 | 田晓旭 6 月 30 日,华为正式开源单机数据库 openGauss,开源协议采用木兰宽松许可证 v2。 2019 年 5 月,华为发布了...
-
5
openGauss亮相ICDE2021,分享数据库的AI晋级之路 - openGauss的个人空间 - OSCHINA - 中文开源技术交流社区 仅限深圳|现场揭秘:腾讯云原生数...
-
6
上一篇openGauss数据库源码解析系列文章--openGauss简介(上)中,从openGauss概述、应用场景、系统结构、代码结构四个方面对openGauss进行了初步介绍。其中,openGauss的代码结构介绍了数据库系统通信管理、SQL引擎两方面内容,本篇接着从代码结构第三方面的内...
-
6
在openGauss数据库源码解析系列文章——openGauss开发快速入门(中),介绍了openGauss基本使用,本篇将从openGauss的开发和编译、参与openGauss社区开源项目两方面展开具体介绍。 三、 开发和编译 作为openGauss数据库开发者,在基于openGauss...
-
4
深信服以最高安全架构助力openGauss数据库安全能力建设 - IT业界_CIO时代网 - CIO时代—新技术、新商业、新管理深信服以最高安全架构助力openGauss数据库安全能力建设 2021-05-19 15:58:20 来源: 摘要:近...
-
13
请问PHP如何连接openGauss数据库? ...
-
9
总结十点PostgreSQL/openGauss数据库中容易犯的错误。 1.同时设置日志行前缀和csvlog格式 比较常见大家同时配置下面这两个参数 log_line_prefix = '%m %u %d %p' log_destination='csvlog' %m是带毫...
-
5
2021年7月国产数据库排行榜:openGauss成绩依旧亮眼,Kingbase向Top 10发起冲刺 7月份的国产数据库流行度排行榜已经揭晓。本期榜单...
-
4
OLTP、OLAP业务各自对数据库的存储引擎提出了不同的要求,而openGauss能够支持多个存储引擎来满足来自不同场景的业务诉求。本章将逐一介绍各种存储引擎和对应的源码。 4.1 存储引擎整体架构及代码概览 从整个数据库服务的组成构架来看,存...
-
5
一、前言 数据库作为信息系统基础底座软件,在大数据背景下,数据库的数据量和节点规模日益增长,数据库使用方越来越看重系统运行是否稳定、安全和高效,这也使数据库自身的运行与维护的要求也随之增高。是否拥有成熟健全的运行维护体系,支撑团队...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK