

机器学习分类问题:九个常用的评估指标总结
source link: https://www.51cto.com/article/717817.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


对机器学习的评估度量是机器学习核心部分,本文总结分类问题常用的请估指标。
分类问题评估指标
在这里,将讨论可用于评估分类问题预测的各种性能指标。
1. Confusion Matrix
这是衡量分类问题性能的最简单方法,其中输出可以是两种或更多类型的类。混淆矩阵只不过是一个具有两个维度的表,即“实际”和“预测”,此外,这两个维度都有“真阳性(TP)”、“真阴性(TN)”、“假阳性(FP)”和“假阴性(FN)”,如下所示:
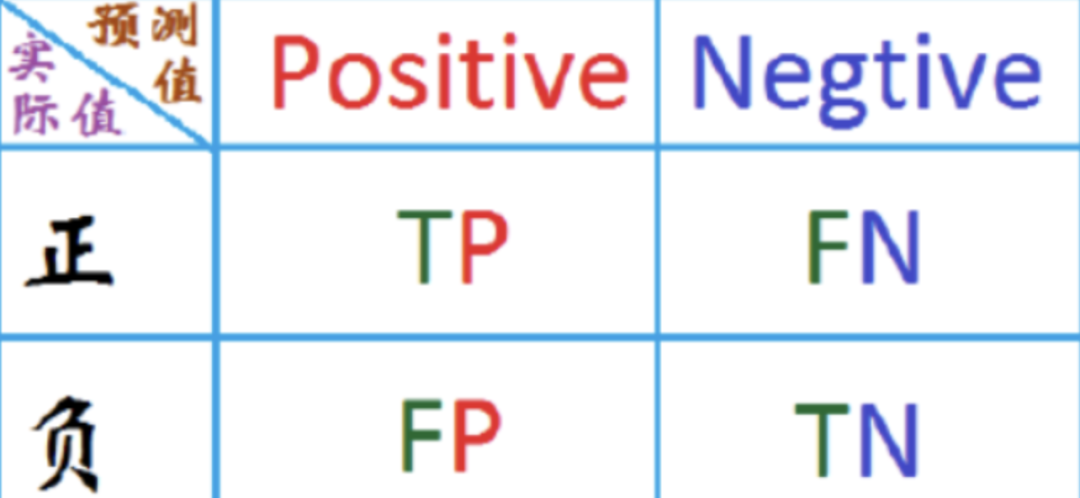
与混淆矩阵相关的术语解释如下:
- 真阳(TP)− 当数据点的实际类别和预测类别均为1
- 真实阴(TN)− 当数据点的实际类和预测类都为0
- 假阳(FP)− 当数据点的实际类别为0,预测的数据点类别为1
- 假阴(FN)− 当数据点的实际类别为1,预测的数据点类别为0
我们可以使用sklearn的混淆矩阵函数confusion_matrix,用于计算分类模型混淆矩阵的度量。
2. Accuracy
它是分类算法最常见的性能度量。它可以被定义为正确预测的数量与所有预测的比率。我们可以通过混淆矩阵,借助以下公式轻松计算:
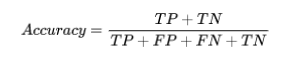
我们可以使用sklearn的accuracy_score函数,计算分类模型准确性的指标
3. Precision
precision定义为ML模型预测结果中:预测正确的正样本数除以所有的预测正样本数:

4. Recall
recall定义为ML模型预测结果中:预测正确的正样本数除以所有的实际正样本数:
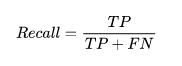
5. Specificity
specificity定义为ML模型预测结果中:预测正确的负样本数除以所有的实际负样本数:
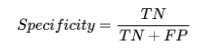
6. Support
支持度可定义为每类目标值中相应的样本数。
7. F1 Score
该分数将为我们提供precision和recall的调和平均值。从数学上讲,F1分数是precision和recall的加权平均值。F1的最佳值为1,最差值为0。我们可以使用以下公式计算F1分数:

F1分数对precision和recall的相对贡献相等。
我们可以使用sklearn的classification_report功能,用于获取分类模型的分类报告的度量。
8. AUC (Area Under ROC curve)
AUC(曲线下面积)-ROC(接收器工作特性)是基于不同阈值的分类问题性能指标。顾名思义,ROC是一条概率曲线,AUC衡量可分离性。简单地说,AUC-ROC度量将告诉我们模型区分类的能力,AUC越高,模型越好。
从数学上讲,可以通过绘制不同阈值下的TPR(真阳性率),即specificity或recall与FPR(假阳性率),下图显示了ROC、AUC,y轴为TPR,x轴为FPR:
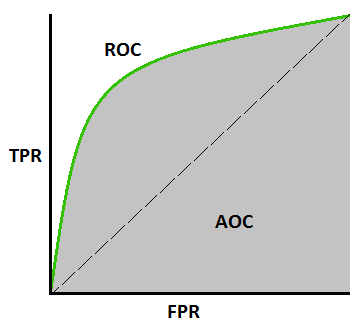
我们可以使用sklearn的roc_auc_score函数,计算AUC-ROC的指标。
9. LOGLOSS (Logarithmic Loss)
它也称为逻辑回归损失或交叉熵损失。它基本上定义在概率估计上,并测量分类模型的性能,其中输入是介于0和1之间的概率值。
通过精确区分,可以更清楚地理解它。正如我们所知,准确度是我们模型中预测的计数(预测值=实际值),而对数损失是我们预测的不确定性量,基于它与实际标签的差异。借助对数损失值,我们可以更准确地了解模型的性能。我们可以使用sklearn的log_loss函数。
下面是Python中的一个简单方法,它将让我们了解如何在二进制分类模型上使用上述性能指标。
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.metrics import roc_auc_score
from sklearn.metrics import log_loss
X_actual = [1, 1, 0, 1, 0, 0, 1, 0, 0, 0]
Y_predic = [1, 0, 1, 1, 1, 0, 1, 1, 0, 0]
results = confusion_matrix(X_actual, Y_predic)
print ('Confusion Matrix :')
print(results)
print ('Accuracy Score is',accuracy_score(X_actual, Y_predic))
print ('Classification Report : ')
print (classification_report(X_actual, Y_predic))
print('AUC-ROC:',roc_auc_score(X_actual, Y_predic))
print('LOGLOSS Value is',log_loss(X_actual, Y_predic))Confusion Matrix :
[
[3 3]
[1 3]
]
Accuracy Score is 0.6
Classification Report :
precision recall f1-score support
0 0.75 0.50 0.60 6
1 0.50 0.75 0.60 4
micro avg 0.60 0.60 0.60 10
macro avg 0.62 0.62 0.60 10
weighted avg 0.65 0.60 0.60 10
AUC-ROC: 0.625
LOGLOSS Value is 13.815750437193334Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK