

AI and ML blog
source link: https://community.arm.com/arm-community-blogs/b/ai-and-ml-blog/posts/how-to-deploy-paddlepaddle-on-arm-cortex_2d00_m-with-arm-virtual-hardware
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Introduction
As one of the key applications in the field of Computer Vision (CV), Optical Character Recognition (OCR) aims at recognizing the text content of a fixed image area. OCR has been widely used in many industry scenarios such as card ticket information extraction and review, manufacturing product traceability, and electronic government medical document processing. Text recognition is a sub-task of OCR. It is the next step after text detection in OCR’s two-stage algorithm, which can convert image information into text information.

Figure 1. Example of English text recognition (Image source: ICDAR2015)
In this blog, we apply Deep Learning (DL) to the OCR text recognition task. We will show you an end-to-end development workflow all the way from model training to application deployment. You will learn how to:
1. Use PaddleOCR to obtain a trained English text recognition model
2. Export the Paddle inference model
3. Compile the Paddle inference model with TVMC for target device
4. Build text recognition application and deploy it on the Arm Virtual Hardware Corstone-300 platform with Arm Cortex-M55
This project highlights a collaboration between Arm and Baidu that fills a previous gap in the workflow of deploying a PaddlePaddle model directly on Arm Cortex-M. This increases the number of deep learning models supported on Cortex-M, providing developers with more choices.
PP-OCRv3
PaddleOCR provides an OCR system named PP-OCR. This is a self-developed practical ultra-lightweight OCR system created by the Baidu Paddle Team. It is a two-stage OCR system, in which the text detection algorithm is called DB, and the text recognition algorithm is called CRNN. As seen in Figure 2, the overall pipeline of PP-OCRv3 is similar to PP-OCRv2 with some further optimizations to the detection model and recognition model. For example, the text recognition model introduces SVTR (Scene Text Recognition with a Single Visual Model) based on PP-OCRv2. The model also uses GTC (Guided Training of CTC) to guide training and model distillation. For more details, please refer to this PP-OCRv3 technical report.
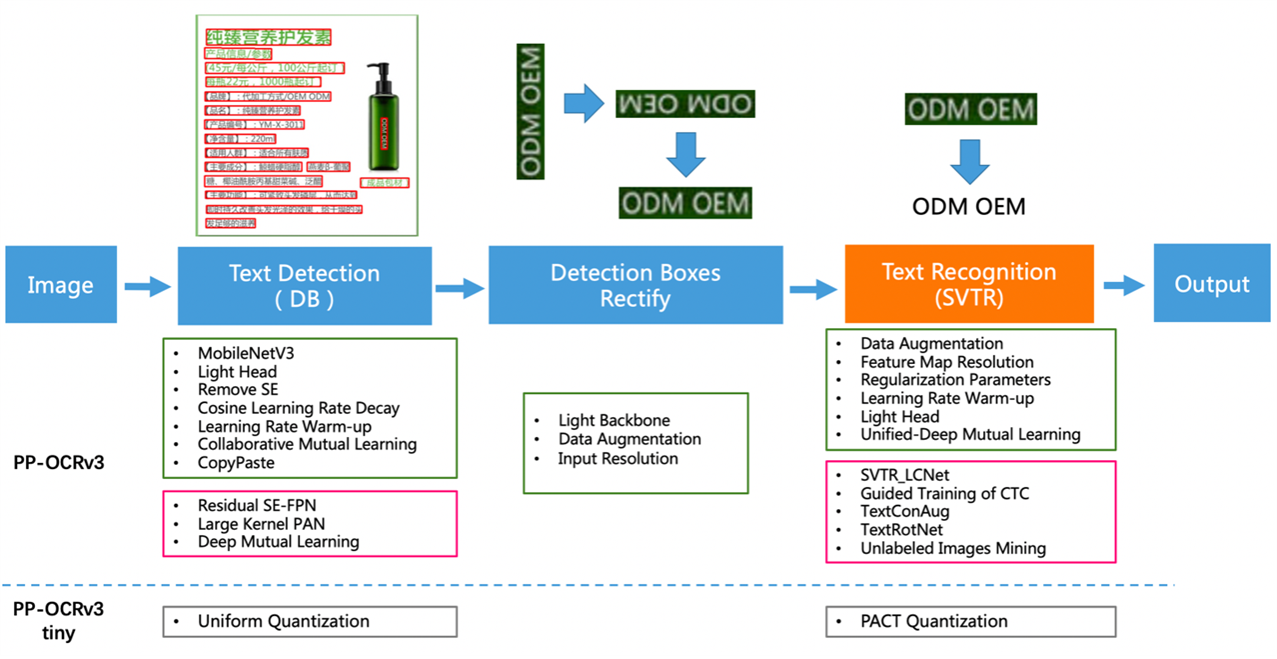
Figure 2. PP-OCRv3 pipeline diagram
Arm Virtual Hardware
As part of core technology of Arm Total Solutions for IoT, Arm Virtual Hardware (AVH) provides cloud-deployable virtual models of Arm devices. AVH solves many of the pain points that testing and development on physical hardware face. These include difficult expansion of testing, high-cost operation and maintenance of board test farms and so on. AVH provides a simple, convenient, and scalable way to free the development of IoT applications from the dependency on physical hardware. It also enables cloud-native technology like Continuous Integration / Continuous Deployment (CI/CD) and other DevOps approaches to be applied in the fields of embedded IoT and Edge/endpoint Machine Learning (ML). Despite the current supply chain crunch, there are many advantages to starting your development instantly with Arm Virtual Hardware without waiting for hardware delivery or access. You can get access to the latest Arm processing IP before it has been implemented into a production silicon design, hugely accelerating overall product development time.
Currently, Arm directly provides two ways to access Arm Virtual Hardware for developers to use. One is Arm Virtual Hardware Corstone and Cortex CPUs and the other is Arm Virtual Hardware 3rd-party hardware. You can see more details at avh.arm.com. In this blog, we use Arm Virtual Hardware Corstone and Cortex CPUs medium which is hosted as Amazon Machine Image (AMI) in AWS and AWS China. Refer to this document to learn how to access and launch AVH AMI instance. In addition, Arm is working with many SAAS developer tool and platform providers to integrate AVH directly into workflows developers are already using today.
End-to-end workflow
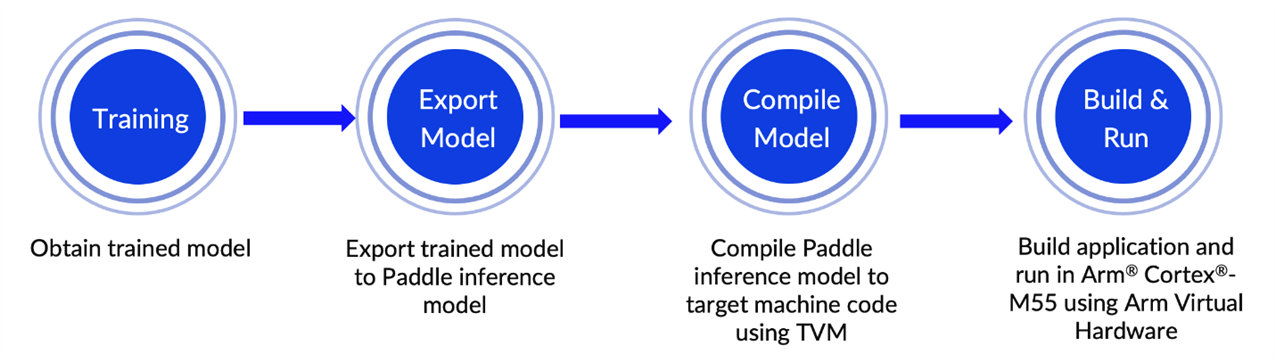
Figure 3. End-to-end workflow
1. Train an English text recognition model with PaddleOCR
PaddleOCR provides many practical OCR tools that help you train models and apply them into practice. PaddleOCR uses configuration files(.yml) to control network training and evaluation parameters. In the configuration file, you can set the parameters for building the model, optimizer, loss function, and model pre- and post-processing. PaddleOCR reads these parameters from the configuration file, and then forms a complete training process to complete the model training. Fine-tuning can also be completed by modifying the parameters in the configuration file, which is simple and convenient. Refer to the Configuration file for a more verbose description.
To obtain the trained model adapted for Cortex-M, we must modify the configuration file used for model training. Unsupported operators, for example LSTM, are removed. To optimize the model, we use BDA (Base Data Augmentation) in the model tuning phase. This includes multiple basic data enhancement methods such as random cropping, random blurring, random noise, and image inversion. Before you start, you must install the PaddleOCR tool first. You can refer to PaddleOCR Quick Start guide for more details.
# Architecture part modification of en_PP-OCRv3_rec.yml file
Architecture:
model_type: rec
algorithm: SVTR
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
last_conv_stride: [1, 2]
last_pool_type: avg
Neck:
name: SequenceEncoder
encoder_type: reshape
Head:
name: CTCHead
mid_channels: 96
fc_decay: 0.00002# Train part modification of en_PP-OCRv3_rec.yml file
Train:
dataset:
name: LMDBDataset
data_dir: MJ_ST
ext_op_transform_idx: 1
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- RecAug:
- CTCLabelEncode:
- RecResizeImg:
image_shape: [3, 32, 320]
- KeepKeys:
keep_keys:
- image
- label
- length
...In this example, we use the open-source datasets MJSynth and SynthText (MJ+ST) and train the model with the following command. The model training period is closely related to the training environment and the size of the dataset. Configure it according to your own situation.
python3 tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o \ Global. save_model_dir=output/rec/ \ Train.dataset.name=LMDBDataSet \ Train.dataset.data_dir=MJ_ST \ Eval.dataset.name=LMDBDataSet \ Eval.dataset.data_dir=EN_eval \
2. Export Paddle inference model
We must export the trained text recognition model to a Paddle inference model that we can compile to generate code which is suitable to run on a Cortex-M processor. Use the following command to export the Paddle inference model:
python3 tools/export_model.py \ -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o \ Global.pretrained_model=output/rec/best_accuracy.pdparams \ Global.save_inference_dir=output/rec/infer
You can use PaddleOCR to verify the inference model with the following command. It usually takes some time to train the model. So for your convenience to experience the complete workflow, you can download an English text recognition model trained and exported by us directly at https://paddleocr.bj.bcebos.com/tvm/ocr_en.tar.
python3 tools/infer/predict_rec.py --image_dir="path_to_image/word_116.png" \ --rec_model_dir="path_to_infer_model/ocr_en" \ --rec_char_dict_path="ppocr/utils/en_dict.txt" \ --rec_image_shape="3,32,320"

Figure 4. word_116.png
We use Figure 4 as a single example of the kind of image you can use to verify the inference results. The recognition results can be seen as follows. It is consistent with the picture text content ‘QBHOUSE’ and has a high confidence score around 0.9867. This indicates that our inference model is ready for the next step.
Predicts of path_to_word_116.png:('QBHOUSE', 0.9867456555366516)3. Compile Paddle inference model with TVMC
We use the deep learning complier TVM for model conversion and adaptation. TVM is an open-source deep learning compiler. It is mainly used to solve the adaptability problem of deploying various Deep Learning frameworks on a wide range of hardware targets. Seen in Figure 5, the TVM compiler accepts models written by classic deep learning training frameworks such as PaddlePaddle. And then converts these models into code that can run inference tasks on the target device.
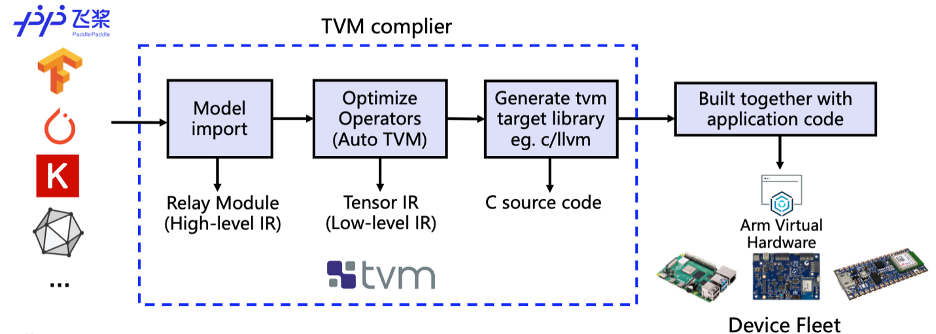
Figure 5. Schematic diagram of compilation process
We use TVM’s Python application TVMC to compile the model. You can use the following command to compile the Paddle inference model. By specifying --target=cmsis-nn,c, the operators supported by Arm’s CMSIS-NN library will be offloaded to a CMSIS-NN kernel. It can make the best use of underlying Arm hardware acceleration. Otherwise, it falls back to standard C library implementations. By specifying --target-cmsis-nn-mcpu=cortex-m55 and --target-c-mcpu=cortex-m55, it compiles the code that is suitable for running on Cortex-M55 processor. For more specific descriptions of each parameter, you can use the command tvmc compile --help after you install the TVM Python package.
python3 -m tvm.driver.tvmc compile \ path_to_infer_model/ocr_en/inference.pdmodel \ --target=cmsis-nn,c \ --target-cmsis-nn-mcpu=cortex-m55 \ --target-c-mcpu=cortex-m55 \ --runtime=crt \ --executor=aot \ --executor-aot-interface-api=c \ --executor-aot-unpacked-api=1 \ --pass-config tir.usmp.enable=1 \ --pass-config tir.usmp.algorithm=hill_climb \ --pass-config tir.disable_storage_rewrite=1 \ --pass-config tir.disable_vectorize=1 \ --output-format=mlf \ --model-format=paddle \ --module-name=rec \ --input-shapes x:[1,3,32,320] \ --output=rec.tar
After compilation, the model file can be found at the directory specified by parameter --output. In this example, it ends up in a file called rec.tar in the current directory.
4. Deploy on the AVH Corstone-300 platform with Arm Cortex-M55
Use the ssh command to connect to the AVH AMI instance you launched beforehand, and you can see the terminal interface below. It shows that you have logged in successfully.
Figure 6. Successfully login page
The steps of model training, exporting, and compiling described in 1-3 can be completed on the local machine or in the AVH AMI environment. Determine it according to your own needs. The complete sample code, that you can run from the command line, is available to download from PaddleOCR’s GitHub repository (under the dygraph branch). This makes it easier for developers to experience the whole workflow, especially the deployment.
After you connect to the AVH AMI instance successfully, you can complete model deployment and view application execution results with the following command.
$ git clone https://github.com/PaddlePaddle/PaddleOCR.git $ cd PaddleOCR $ git pull origin dygraph $ cd deploy/avh $ ./run_demo.sh
The run_demo.sh script automates the entire process we have just described. It takes the following 6 steps to help you automatically build and execute the English text recognition application on Corstone-300 platform with Arm Virtual Hardware.
Step 1. Set up running environment
Step 2. Download PaddlePaddle inference model
Step 3. Use TVMC to compile the model and generate code for the Arm Cortex-M processor
Step 4. Process resources for building the application image
Step 5. Use the Makefile to build the target application
Step 6. Run application binary on Corstone-300 platform integrated in AVH
We can use the image in Figure 4 above (QBHOUSE) as an example to verify the inference results on the AVH Corstone-300 platform with Arm Cortex-M55. The results can be seen as Figure 7 which is highly consistent with the inference results of direct inference on server host. It shows we have successfully deployed PP-OCRv3 English recognition model directly on Arm Cortex-M.
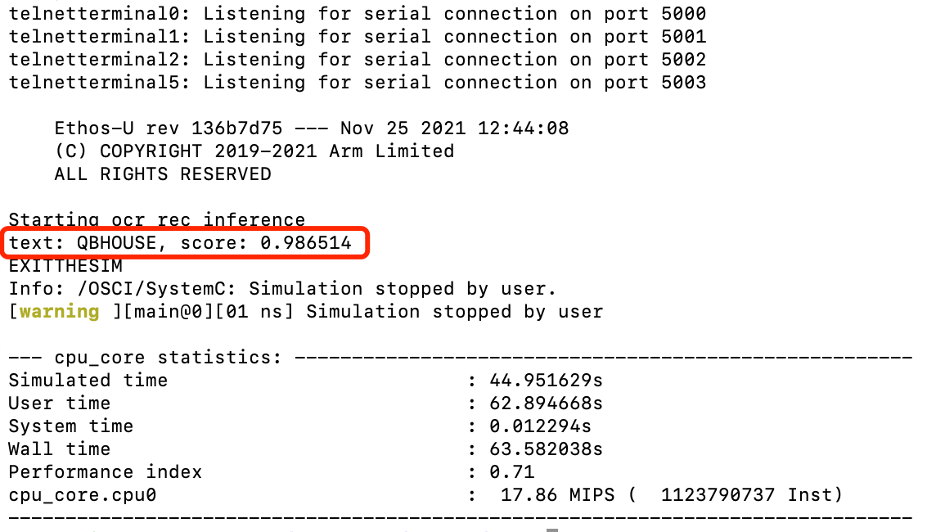
Figure 7. AVH Corstone-300 with Cortex-M55 inference results
Conclusion
In this blog, we showed you how to deploy the English text recognition model released in PP-OCRv3 on the AVH Corstone-300 platform with Cortex-M55. Hopefully, these steps have given you an idea of how fast and easy the entire workflow is, so do not hesitate and try it out today! Embrace the convenience that Arm Virtual Hardware brings to Edge AI development!
Learn more about what Arm and Baidu have been working on and their partnership, in this Blueprint blog post:
Recommend
-
7
Meet WordPress WordPress is open source software you can use to create a beautiful website, blog, or app. Beautiful designs, powerful features, and the freedom to build anything you want. WordPress is both free and priceless...
-
6
Automatic blog publishing using Python and XML-RPCAutomatic blog publishing using Python and XML-RPC Mon 01 December 2008The following piece of code collects links in a Pligg database (but could be any kind of source like RSS feed......
-
9
A blog engine written and proven in Coq January 16, 2015 I present ChickBlog (sources on GitHub), a blog engine written and proven in
-
15
Dynamic and async functionality in JAMstack - LogRocket Blog February 28, 2020 ...
-
11
HomeProductivityI subscribed to Seth Godin’s Blog, and Now I’m a Blogger Again I subscribed to Seth Godin’s Blog, and Now I’m a Blog...
-
5
Scala Scripting and the 15 Minute Blog Engine Posted 2016-07-30The Scala programming language has traditionally been a to...
-
7
Pedestal presentation and example app01 Sep 2016 At the Dutch Clojure Days 2016 in Amsterdam I gave a presentation on building user facing web applicati...
-
9
Datascript and React.js for a Clojure web app30 Apr 2014 When building a web application with Clojure there are a lot of building blocks to choose from. For ClojureScript there has been a particularly interesting new offer with t...
-
5
How to Make an Awesome Blog Using Gatsbyjs and AWS📅 August 07, 2018 – Kyle GalbraithLet's dive into how I stood up my own static website blog, blog.kylegalbraith.com, by using Gats...
-
13
Business Ethics and the “New York Times” Rule On Monday, the front page of the New York Times...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK