
4

hadoop项目之求出每年二月的最高气温(Combiner优化) - 伍点
source link: https://www.cnblogs.com/bfy0221/p/16640855.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

hadoop项目之求出每年二月的最高气温(Combiner优化)
一、项目结构
一、java实现随机生成日期和气温
package com.shujia.weather;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class RandomWeather {
public static void main(String[] args) throws ParseException, IOException {
//创建日期格式
DateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
long start = sdf.parse("2000-01-01 00:00:00").getTime();
long end = sdf.parse("2022-12-31 00:00:00").getTime();
long difference=end - start;
BufferedWriter bw = new BufferedWriter(new FileWriter("F:\\software\\IdeaProjects\\bigdata19-project\\biddata19-mapreduce\\src\\data\\weather.txt"));
for (int i=0;i<10000;i++){
//随机生成时间
Date date = new Date(start + (long) (Math.random() * difference));
//随机生成一个温度
int temperature = -20+(int) (Math.random()*60);
//打印
// System.out.println(date+"\t"+temperature);
bw.write(sdf.format(date)+"\t"+temperature);//将结果写入文件
bw.newLine();
bw.flush();
}
bw.close();
}
}
二、将这个weather.txt文件上传到虚拟机后再上传到hadoop
1、通过xftp上传文件
2、通过命令上传到hadoop
hadoop fs -put weather.txt /路径
三、项目实现
package com.shujia.weather;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
class WeatherMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
/*
2022-06-12 02:40:26 21
2002-01-03 03:49:27 -13
2001-04-21 19:19:22 -16
2005-01-18 01:52:15 10
求出每年二月份的最高气温
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] str = line.split("\t");
String temperature = str[1];
String[] strings = str[0].split("-");
String Month = strings[1];
if ("02".equals(Month)){
context.write(new Text(strings[0]+"-"+Month),new LongWritable(Long.parseLong(temperature)));
}
}
}
class WeatherReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long max=0L;
for (LongWritable value : values) {
long l = value.get();
if (l>max){
max=l;
}
}
context.write(key,new LongWritable(max));
}
}
public class WeatherDemo {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setCombinerClass(WeatherReducer.class);//Combiner优化
job.setJarByClass(WeatherDemo.class);
job.setMapperClass(WeatherMapper.class);
job.setReducerClass(WeatherReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.waitForCompletion(true);
}
}
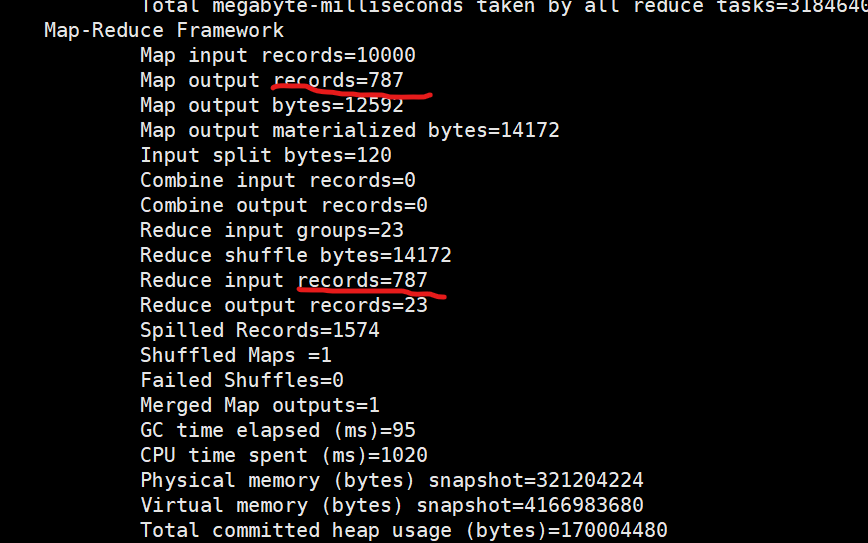
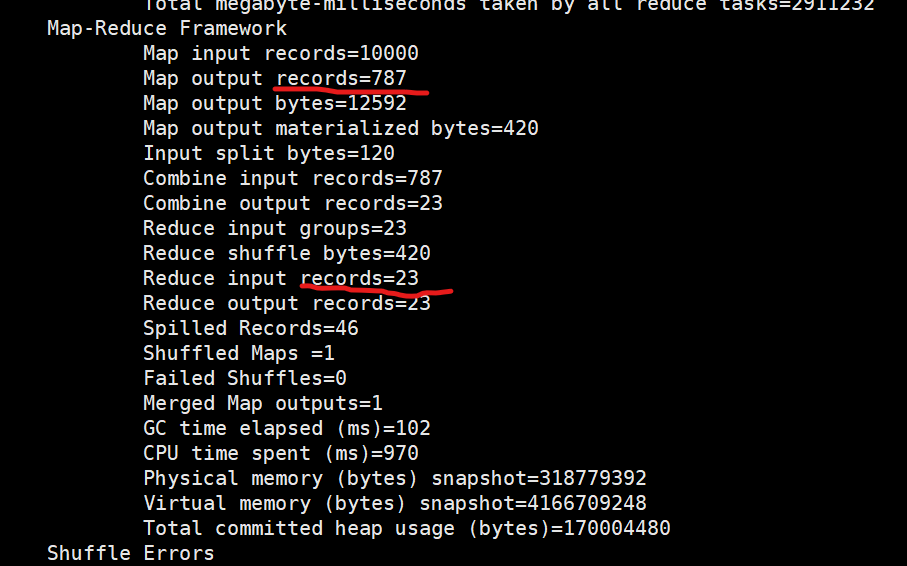
减少了reduce 从map拉取数据的过程,提高计算效率。
hadoop 的计算特点:将计算任务向数据靠拢,而不是将数据向计算靠拢。
注意:将reduce端的聚合操作,放到map 进行执行。适合求和,计数,等一些等幂操作。不适合求平均值,次幂等类似操作
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK