

Apache DolphinScheduler 简单任务定义及复杂的跨节点传参 - 海豚调度
source link: https://www.cnblogs.com/DolphinScheduler/p/16640865.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Apache DolphinScheduler 简单任务定义及复杂的跨节点传参
点亮 ⭐️ Star · 照亮开源之路
GitHub:https://github.com/apache/dolphinscheduler

Apache DolphinScheduler是一款非常不错的调度工具,可单机可集群可容 器,可调度sql、存储过程、http、大数据等,也可使用shell、python、java、flink等语言及工具,功能强大类型丰富,适合各类调度型任务,社区及项目也十分活跃,现在Github中已有8.5k的star👍
阅读本文前建议您先阅读下官方的文档
文档链接:https://dolphinscheduler.apache.org/zh-cn/docs/latest/user_doc/guide/parameter/context.html
在这里,先准备下sql表资源,以下为postgresql的sql脚本:
CREATE TABLE dolphinscheduler.tmp (
id int4 NOT NULL,
"name" varchar(50) NULL,
"label" varchar(50) NULL,
update_time timestamp NULL,
score int4 NULL,
CONSTRAINT tmp_pkey PRIMARY KEY (id) );
INSERT INTO tmp (id,"name","label",update_time,score) VALUES
(3,'二狗子','','2022-07-06 21:49:26.872',NULL),
(2,'马云云','',NULL,NULL),
(1,'李思','','2022-07-05 19:54:31.880',85);
我这里使用的 postgresql 的数据库,如果您是 mysql 或者其他数据的用户,请自行更改以上表和数据并添加到库中即可~
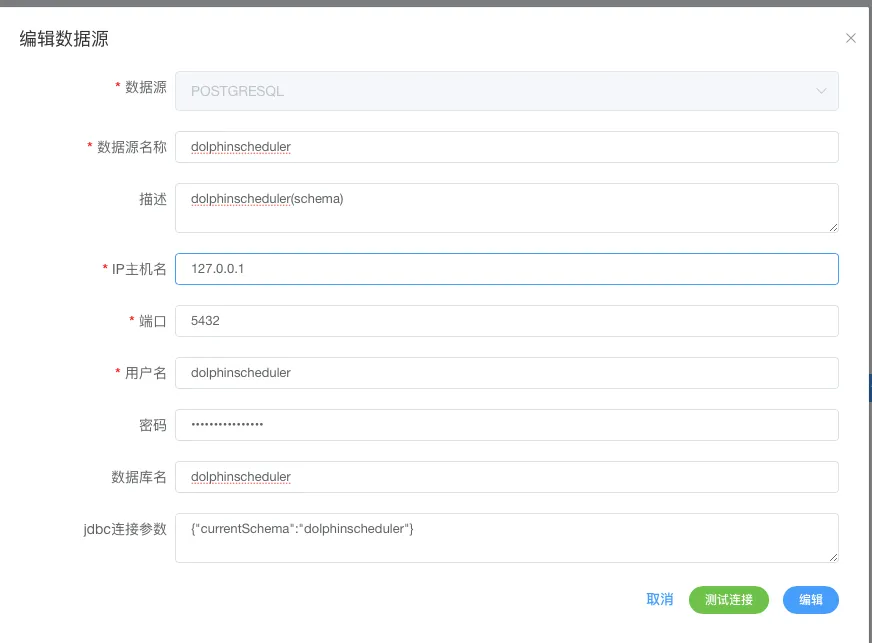
表及数据入库,请将tmp所属的库配置到 DS后台->数据源中心->创建数据源 ,以下是我的配置,记住,这里面的所有数据库配置均遵守所属数据库类型的jdbc 的 driver 的配置参数,配置完成也会在DS的数据库生成一条 jdbc 的连接地址,这点要明白~
简单的项目创建及说明
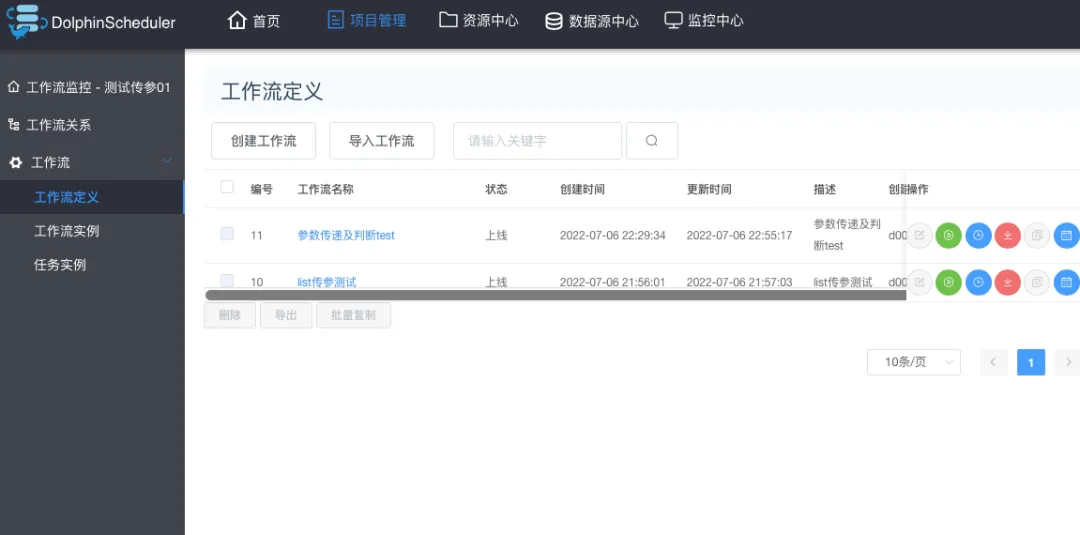
因为DolphinScheduler的任务是配置在项目下面,所以第一步得新建一个项目,这样:DS后台->项目管理->创建项目,这是我创建的请看下图:
准备完项目之后,鼠标点进去,并进入到工作流定义菜单 页面,如下图:
简单解释下DS的基本结构
首先,DS一般部署在 linux 服务器下,创建任务的用户需要在 admin账户 下创建,重要的是创建的每个工作账户需要与操作系统用户一一对应.
比如你创建了一个 test 的DS账户,那所在的服务器也必须有一个test的账户才可行,这是DS的规则。
每个用户下(除了admin外)所能创建的调度任务均在各自创建的项目下,每个项目又分为多个任务(工作流定义),一个任务下又可分为多个任务节点。
下图为任务定义
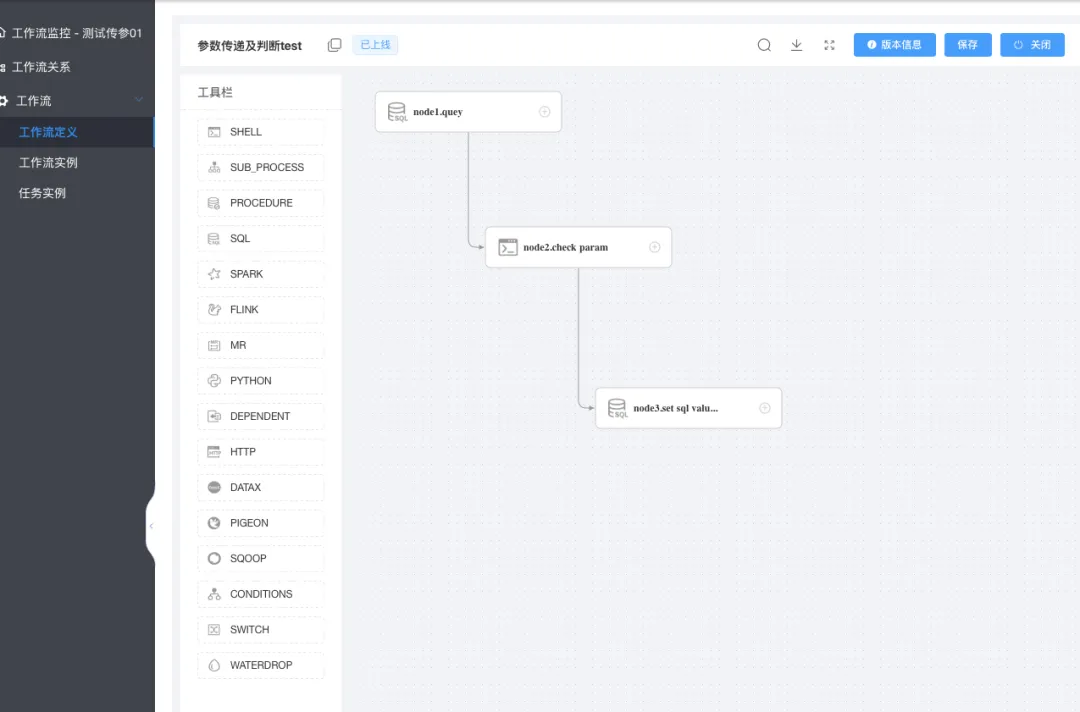
ok,如果已经准备好以上步骤,下面开始继续定义一个简单的调度任务~
简单的参数传递
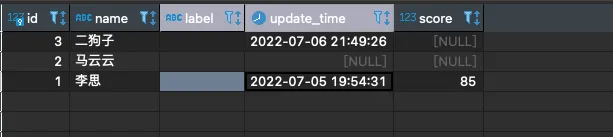
如图我们先做个简单的:
如果二狗子的本名叫李思,需要取** id=1 的 name 放到id=3 **的 label 中,并且更新 update_time
在工作流定义列表,点击 创建工作流 就进入一个具体的任务(工作流)的定义,同时我们使用的是sql任务,需要从左侧拖动一个sql任务到画布中(右侧空白处):
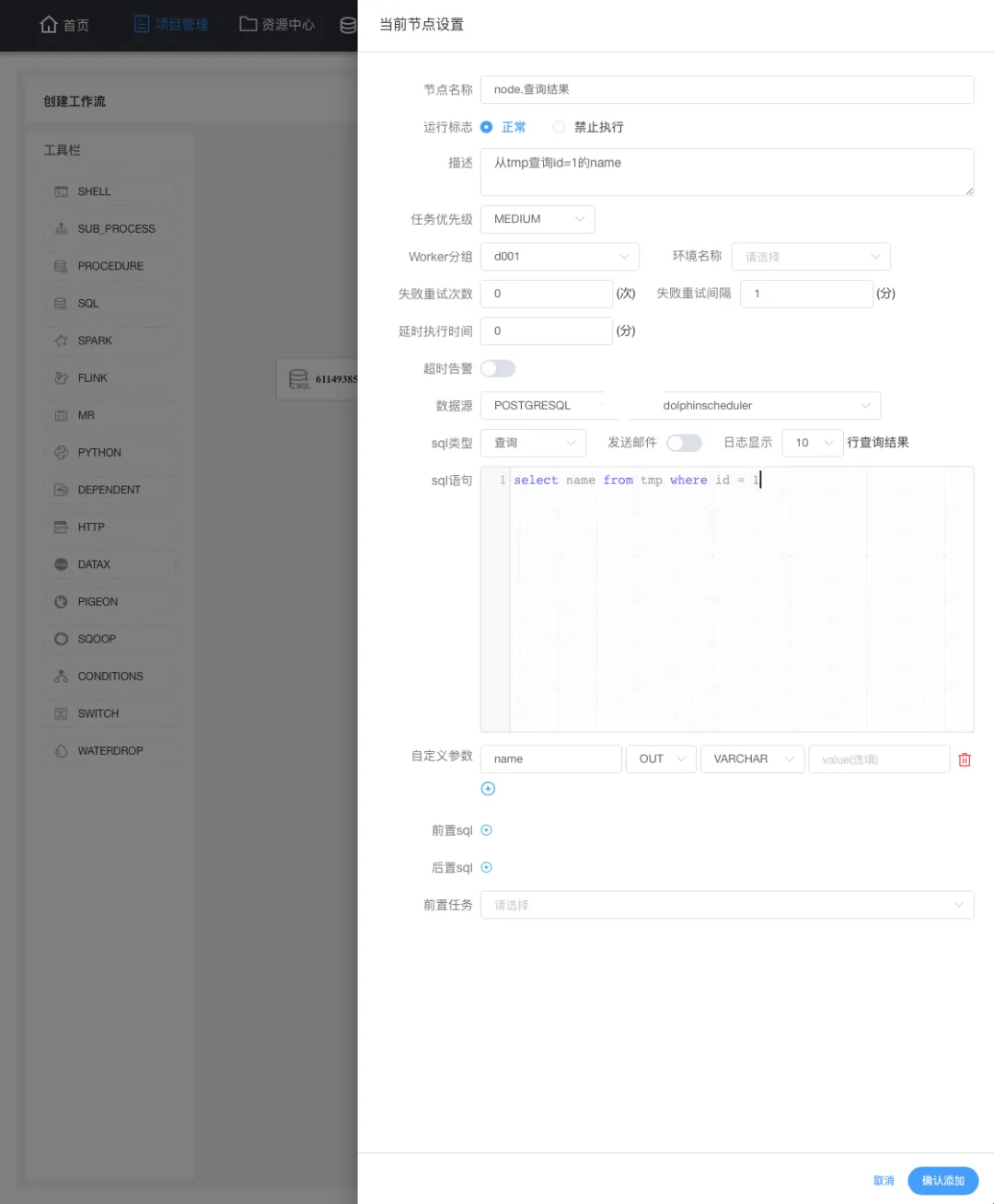
拖动 sql任务 到画布会自动弹出节点定义,上图为当前节点的一个定义,重点是:数据源、sql类型、sql语句,如官方所说,如果将 name 传递到下游,则需要在自定义参数重定义这个 name 为 out方向 类型为varchar。
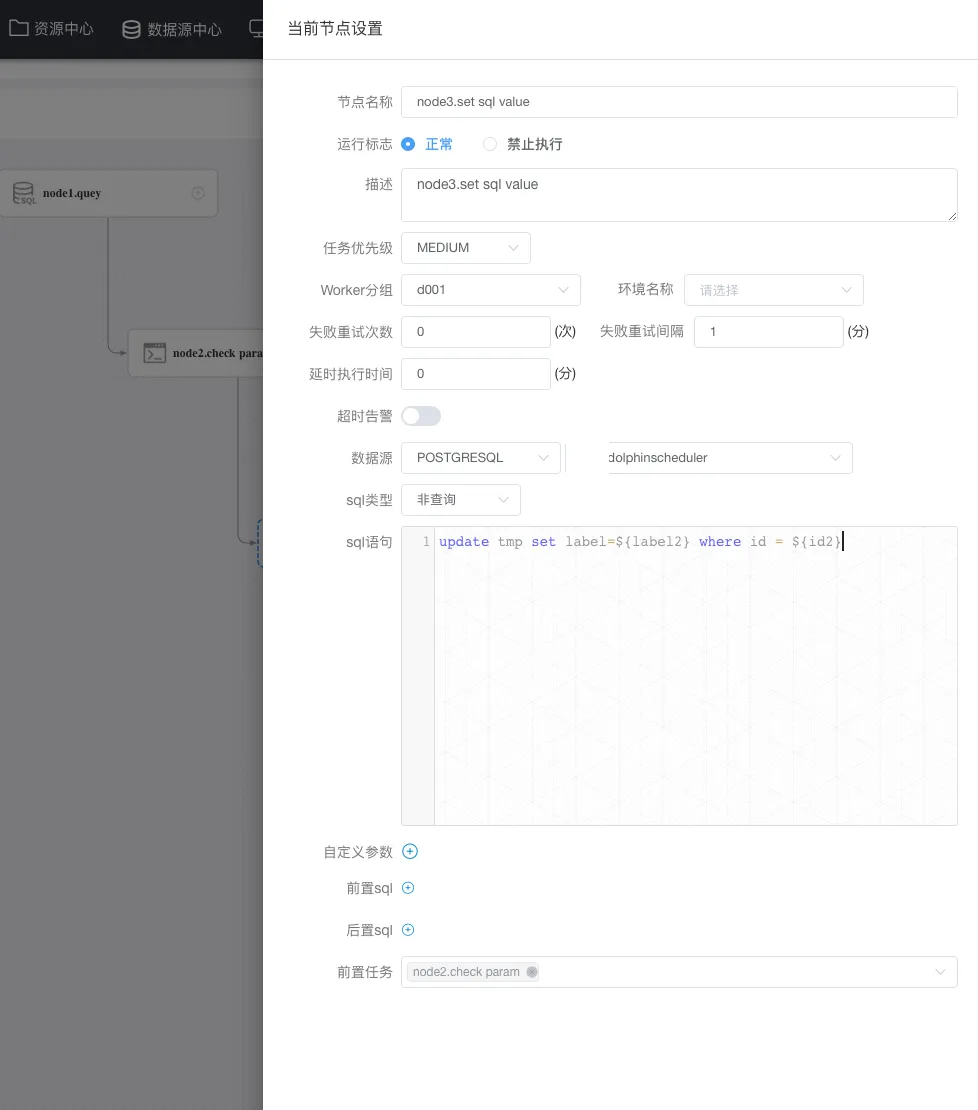
因为传递到参数需要写入到表,这里我们再定义一个节点,这个节点负责接收上游传递到name,执行update 时使用这个 name ,以下是我的定义:
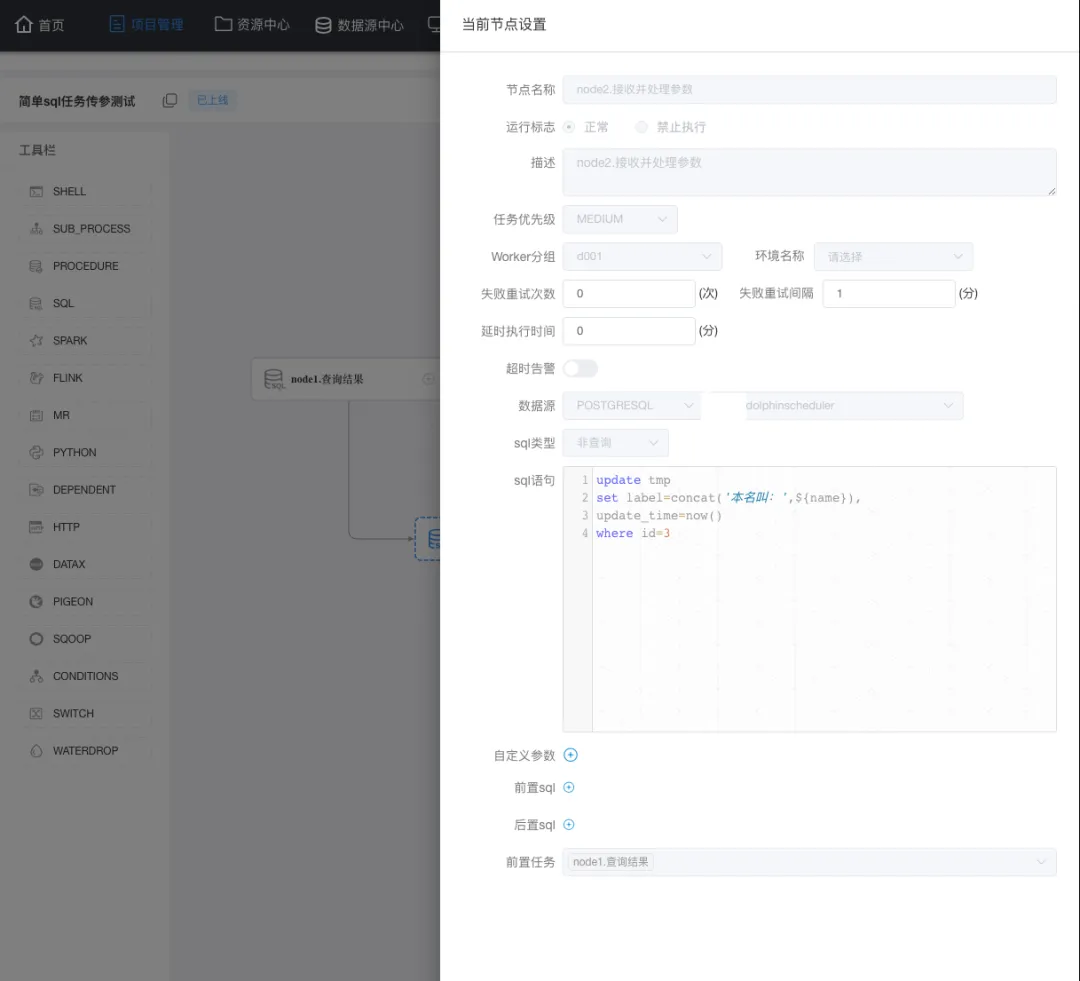
这里不仅仅要注意 sql类型 (sql类型与sql语句是一一对应的,类型不能错) ,还有就是前置任务一定要选中(上面定义的) node1节点。另外,需要注意的是当前任务是上下游传参,所以在node2 中是直接使用 node1中定义的 name 这个参数。
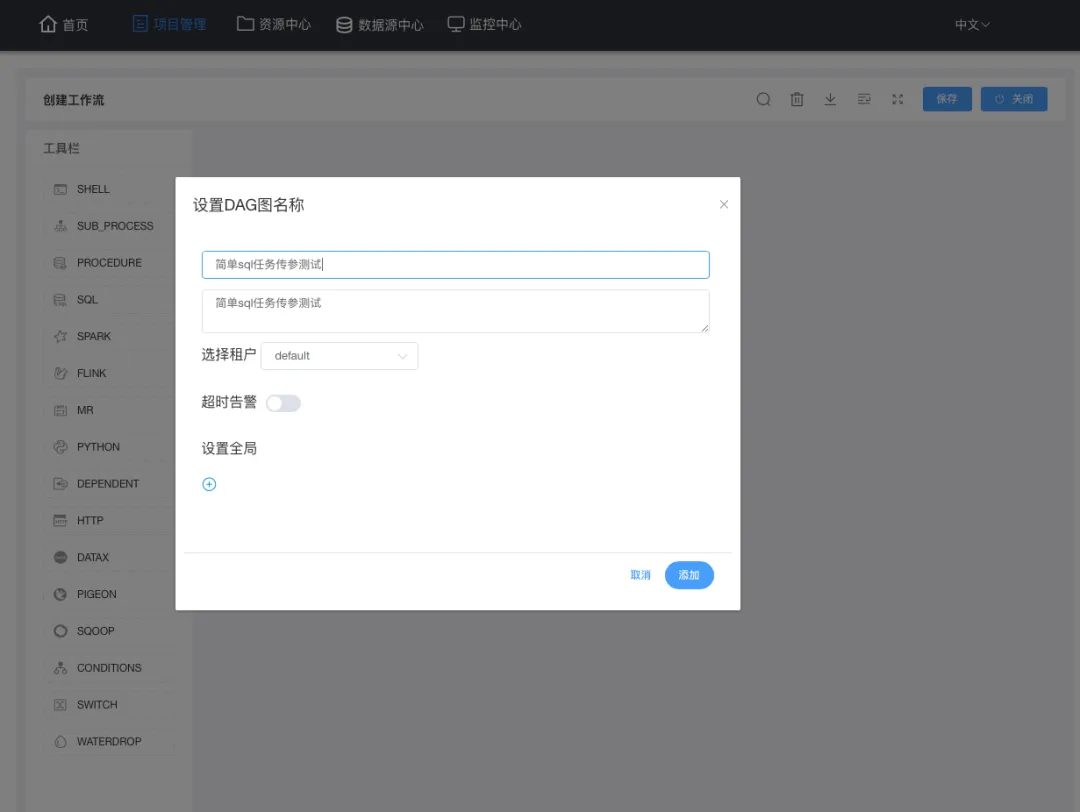
定义完成当前任务需要保存:点右上角保存,填写并保存后点关闭以退出定义;
定义的任务需要上线了才可执行,所以在工作流定义列表先点该任务的黄色按钮(任务上线),然后才是点绿色按钮(执行任务):
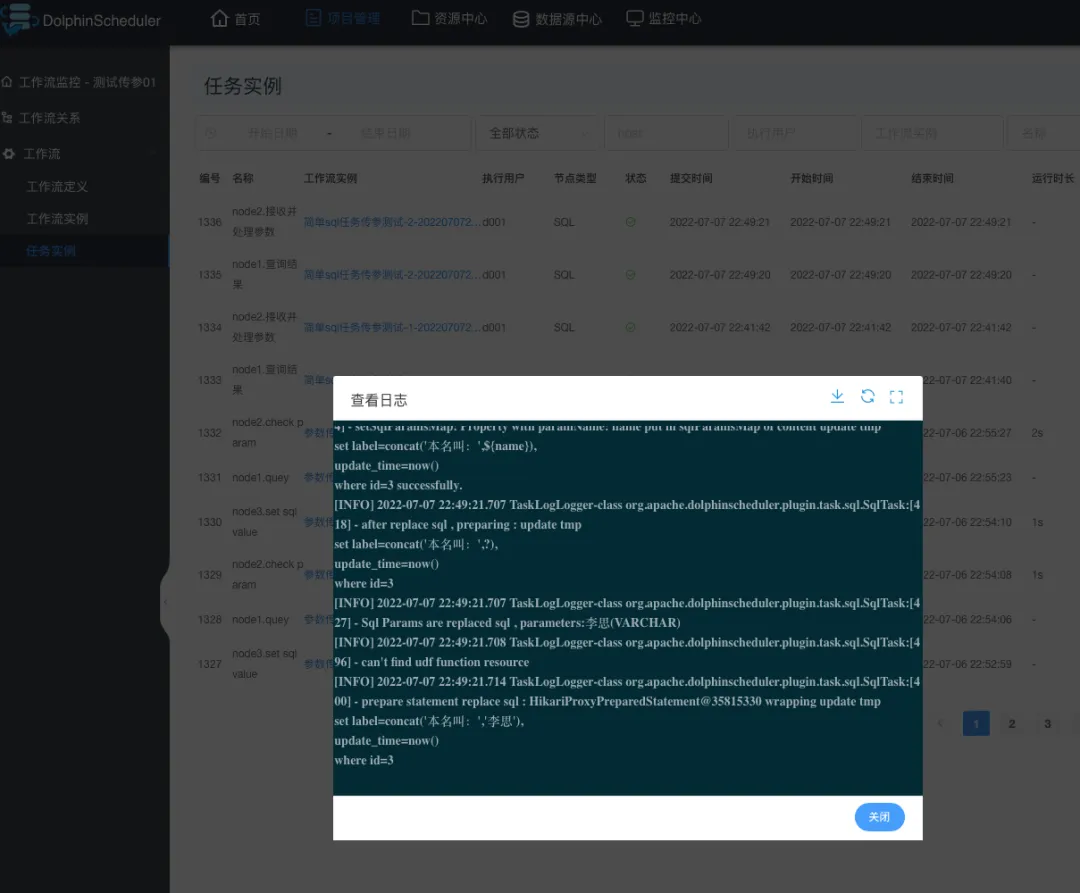
任务执行成功与否,具体得看任务实例,这是执行 node2节点 的日志:
顺带再看看数据库表是否真实成功:
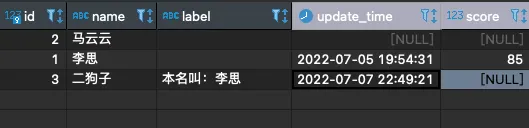
复杂的跨节点传参
首先看表:
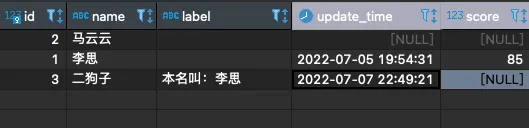
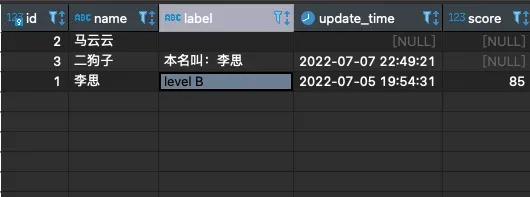
思考一个问题:可以看到李思的score是85,根据score应该被评为 B(>=90的为A)并写入到 label字段,该怎么办呢?如果这个分数是90分又该怎么办呢?如果根本没有score(分值) 这个任务是不是就不需要更新李思的label(评分)呢?
对于上面问题可以有一些偏门的解决方法,比如在sql中塞一个异常值,这样看似不错,不过作为调度工具建议还是在condition节点或者switch节点处理是最好的,目前我用的2.0.5版本对于这两类任务节点是没法接收参数的,这是一个遗憾;
个人觉得较好的方式是在写入节点之前增加一个判断节点,将错误抛出(没有score的)最好~,对于此,我使用了一个shell的中间节点。
下面是我定义的三个节点:
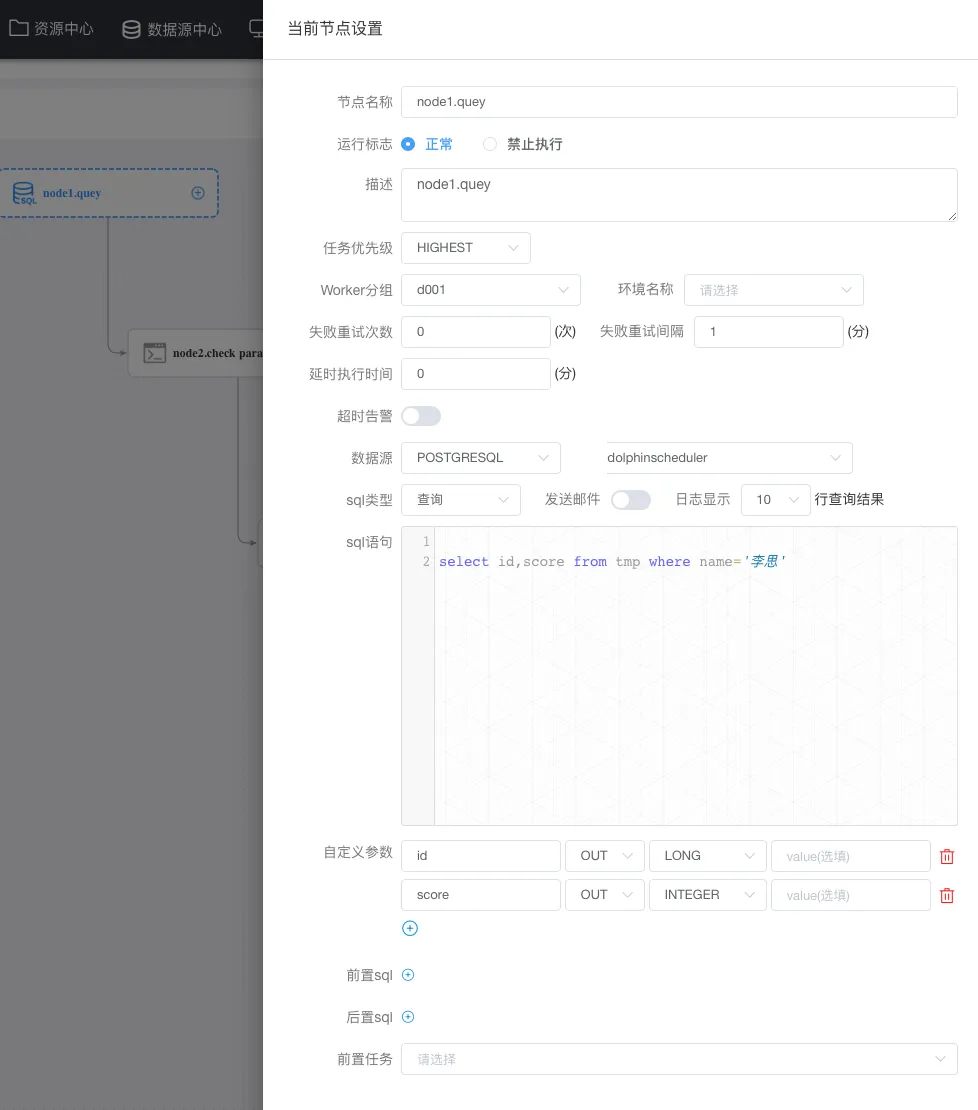
node1节点定义:
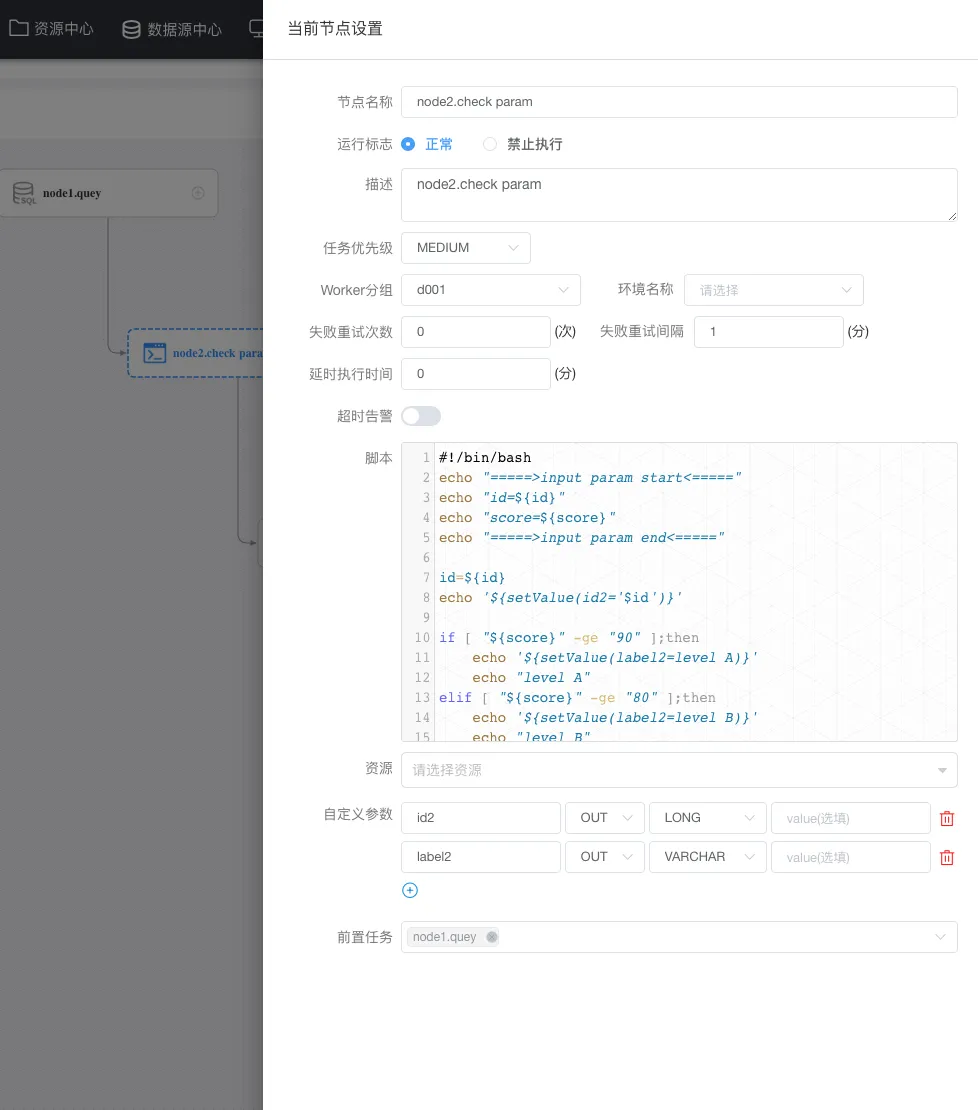
node2节点定义:
脚本内容
#!/bin/bash echo "=====>input param start<=====" echo "id=${id}" echo "score=${score}" echo "=====>input param end<=====" id=${id} echo '${setValue(id2='$id')}' if [ "${score}" -ge "90" ];then echo '${setValue(label2=level A)}' echo "level A" elif [ "${score}" -ge "80" ];then echo '${setValue(label2=level B)}' echo "level B" elif [ "${score}" -ge "60" ];then echo '${setValue(label2=level C)}' echo "level C" elif [ "${score}" -ge "0" ];then echo '${setValue(label2=F!)}' echo "F!" else echo "NO score ,please check!" exit 1 fi
node3节点定义:
看一眼结果🤓:
1、对于shell脚本不熟悉的,判断节点其实还是有一些难度的,这是很重要的一点;
2、**node2(判断节点)不能有重复的参数,不管局部的还是node1(上一级)**传递过来的,均不能重复;
3、因为在node2(判断节点)需要将 id 以及 label 继续往下传(to node3),这时候就需要给 id 以及 label定义一个映射的out变量(id2、label2);
3、node2中重新设置参数麻烦,**需要在 shell 中重新定义变量(id2、label2),**同时需要在shell任务内使用拼接的方式赋值(如:echo '${setValue(id2='$id')}');
4、sql类型以及不同节点下不同参数时常搞错,不是任何节点都可以接收上级节点参数,以及局部变量与传递变量以及全局变量优先级区别及可能造成冲突;
5、DS列表传参(2.0是不可以的)很鸡肋,对于列表传参又不能在下一级节点做循环赋值,这点对于DS是有改进的空间的;
DolphinScheduler还有很多可扩展的地方(因为实际需要),我还做了一些二次开发😂,后面会聊...大家期待哟😚
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。
参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A"volunteer+wanted"
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区Leonard-ds ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
< 🐬🐬 >
点亮 ⭐️ Star · 照亮开源之路
GitHub:[https://github.com/apache/dolphinscheduler](https://github.com/apache/dolphinscheduler)

Apache DolphinScheduler是一款非常不错的调度工具,可单机可集群可容 器,可调度sql、存储过程、http、大数据等,也可使用shell、python、java、flink等语言及工具,功能强大类型丰富,适合各类调度型任务,社区及项目也十分活跃,现在Github中已有8.5k的star👍
# 准备工作
阅读本文前建议您先阅读下官方的文档
文档链接:[https://dolphinscheduler.apache.org/zh-cn/docs/latest/user_doc/guide/parameter/context.html](https://dolphinscheduler.apache.org/zh-cn/docs/latest/user_doc/guide/parameter/context.html)
在这里,先准备下sql表资源,以下为`postgresql`的`sql`脚本:
## 表结构
```CREATE TABLE dolphinscheduler.tmp (
id int4 NOT NULL,
"name" varchar(50) NULL,
"label" varchar(50) NULL,
update_time timestamp NULL,
score int4 NULL,
CONSTRAINT tmp_pkey PRIMARY KEY (id) );
```
## 表数据
```INSERT INTO tmp (id,"name","label",update_time,score) VALUES
(3,'二狗子','','2022-07-06 21:49:26.872',NULL),
(2,'马云云','',NULL,NULL),
(1,'李思','','2022-07-05 19:54:31.880',85);
```
我这里使用的 postgresql 的数据库,如果您是 mysql 或者其他数据的用户,请自行更改以上表和数据并添加到库中即可~
表及数据入库,请将tmp所属的库配置到 DS后台->数据源中心->创建数据源 ,以下是我的配置,记住,这里面的所有数据库配置均遵守所属数据库类型的jdbc 的 driver 的配置参数,配置完成也会在DS的数据库生成一条 jdbc 的连接地址,这点要明白~
# 简单的项目创建及说明
因为DolphinScheduler的任务是配置在项目下面,所以第一步得新建一个项目,这样:`DS后台`->`项目管理`->`创建项目`,这是我创建的请看下图:

准备完项目之后,鼠标点进去,并进入到工作流定义菜单 页面,如下图:

## 简单解释下DS的基本结构
首先,DS一般部署在 linux 服务器下,创建任务的用户需要在 admin账户 下创建,重要的是创建的每个工作账户需要与操作系统用户一一对应.
比如你创建了一个 test 的DS账户,那所在的服务器也必须有一个test的账户才可行,这是DS的规则。
每个用户下(除了admin外)所能创建的调度任务均在各自创建的项目下,每个项目又分为多个任务(工作流定义),一个任务下又可分为多个任务节点。
下图为任务定义

ok,如果已经准备好以上步骤,下面开始继续定义一个简单的调度任务~
# 简单的参数传递
先看表:

如图我们先做个简单的:
如果二狗子的本名叫李思,需要取** id=1 **的 name 放到**id=3 **的 label 中,并且更新 update_time
### 01
在工作流定义列表,点击 创建工作流 就进入一个具体的任务(工作流)的定义,同时我们使用的是sql任务,需要从左侧拖动一个sql任务到画布中(右侧空白处):

拖动 sql任务 到画布会自动弹出节点定义,上图为当前节点的一个定义,重点是:数据源、sql类型、sql语句,如官方所说,如果将 name 传递到下游,则需要在自定义参数重定义这个 name 为 out方向 类型为varchar。
### 02
因为传递到参数需要写入到表,这里我们再定义一个节点,这个节点负责接收上游传递到name,执行update 时使用这个 name ,以下是我的定义:

这里不仅仅要注意 sql类型 (sql类型与sql语句是一一对应的,类型不能错) ,还有就是前置任务一定要选中(上面定义的) node1节点。另外,需要注意的是当前任务是上下游传参,所以在node2 中是直接使用 node1中定义的 name 这个参数。
### 03
定义完成当前任务需要保存:点右上角保存,填写并保存后点关闭以退出定义;

### 04
定义的任务需要上线了才可执行,所以在工作流定义列表先点该任务的黄色按钮(任务上线),然后才是点绿色按钮(执行任务):
### 05
任务执行成功与否,具体得看任务实例,这是执行 node2节点 的日志:

顺带再看看数据库表是否真实成功:

完美😊
# 复杂的跨节点传参
首先看表:

思考一个问题:可以看到李思的score是85,根据score应该被评为 B(>=90的为A)并写入到 label字段,该怎么办呢?如果这个分数是90分又该怎么办呢?如果根本没有score(分值) 这个任务是不是就不需要更新李思的label(评分)呢?
对于上面问题可以有一些偏门的解决方法,比如在sql中塞一个异常值,这样看似不错,不过作为调度工具建议还是在condition节点或者switch节点处理是最好的,目前我用的2.0.5版本对于这两类任务节点是没法接收参数的,这是一个遗憾;
个人觉得较好的方式是在写入节点之前增加一个判断节点,将错误抛出(没有score的)最好~,对于此,我使用了一个shell的中间节点。
下面是我定义的三个节点:
node1节点定义:

node2节点定义:

**脚本内容**
```#!/bin/bash echo "=====>input param start<=====" echo "id=${id}" echo "score=${score}" echo "=====>input param end<=====" id=${id} echo '${setValue(id2='$id')}' if [ "${score}" -ge "90" ];then echo '${setValue(label2=level A)}' echo "level A" elif [ "${score}" -ge "80" ];then echo '${setValue(label2=level B)}' echo "level B" elif [ "${score}" -ge "60" ];then echo '${setValue(label2=level C)}' echo "level C" elif [ "${score}" -ge "0" ];then echo '${setValue(label2=F!)}' echo "F!" else echo "NO score ,please check!" exit 1 fi```
node3节点定义:

看一眼结果🤓:

# 小结
1、对于**shell脚本**不熟悉的,判断节点其实还是有一些难度的,这是很重要的一点;
2、**node2(判断节点)**不能有重复的参数,不管局部的还是**node1(上一级)**传递过来的,均不能重复;
3、因为在**node2(判断节点)**需要将 id 以及 label 继续往下传**(to node3),**这时候就需要给 id 以及 label定义一个映射的**out变量(id2、label2);**
3、node2中重新设置参数麻烦,**需要在 shell 中重新定义变量(id2、label2),**同时需要在shell任务内使用拼接的方式赋值(如:echo '${setValue(id2='$id')}');
4、**sql类型**以及不同节点下不同参数时常搞错,不是任何节点都可以接收上级节点参数,以及局部变量与传递变量以及全局变量优先级区别及可能造成冲突;
5、DS列表传参(2.0是不可以的)很鸡肋,对于列表传参又不能在下一级节点做循环赋值,这点对于DS是有改进的空间的;
DolphinScheduler还有很多可扩展的地方(因为实际需要),我还做了一些二次开发😂,后面会聊...大家期待哟😚
# 参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。
## 欢迎关注
参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:[https://github.com/apache/dolphinscheduler/issues/5689](https://github.com/apache/dolphinscheduler/issues/5689)
非新手问题列表:[https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A"volunteer+wanted"](https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22)
如何参与贡献链接:[https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html](https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html)
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区Leonard-ds ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手时请说明想参与贡献。
**来吧,开源社区非常期待您的参与。**
< 🐬🐬 >
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK