

手把手教你搭建JAVA分布式爬虫 - K太狼
source link: https://www.cnblogs.com/kaiblog/p/16637456.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
在工作中,我们经常需要去获取一些数据,但是这些数据可能需要从第三方平台才可以获取到。这个时候,爬虫系统就可以帮助我们来完成这些事情。
提到爬虫系统,很多人都会想到使用python。但实际上,语言只是一种工具,其背后的设计思想和技术原理才是精髓,这篇关于Java分布式爬虫的文章会带着大家一步一步搭建一个适合Java开发者的爬虫系统。
第一部分:搭建一个简单的爬虫系统
现在,我们就来尝试下通过自动化方法来获取https://www.cnblogs.com/的首页内容。在正式开始编写代码之前,我们需要安装两个重要的程序,一个是chromedriver,一个是chrome。
chrome浏览器的下载地址:https://chrome.en.softonic.com/
chromedriver下载地址:http://chromedriver.storage.googleapis.com/index.html
注意:在安装这两个软件的时候,它们的版本需要对应起来才能正常work。
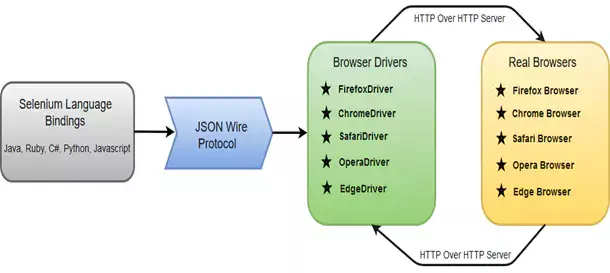
接下来我要给大家介绍一下Selenium webdriver这个开源组件,Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。Selenium webdriver是编程语言和浏览器之间的通信工具,它的工作流程如下图所示。
环境搭建好之后,我们就开始进入实际开发环节。首先,我们创建一个WebDriverFactory。
@Servicepublic class WebDriverFactory { @Value("${chrome.path}") private String chromePath; @Autowired private ProxyPool proxyPool; public WebDriver createWebDriver(boolean useProxy) { System.setProperty(ChromeDriverService.CHROME_DRIVER_EXE_PROPERTY, "/Users/****/Downloads/chromedriver"); ArrayList<String> arguments = Lists.newArrayList("--no-sandbox", "--disable-dev-shm-usage", "--disable-web-security", "--ignore-certificate-errors", "--allow-running-insecure-content", "--allow-insecure-localhost", "--disable-images", "--disable-gpu", "--disable-blink-features=AutomationControlled", "--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.16 Safari/537.36", "--cache-control=no-cache"); ChromeOptions options = new ChromeOptions(); options.setHeadless(true); options.addArguments(arguments); /** 设置使用代理 **/ if (useProxy) { Proxy proxy = proxyPool.getProxy(); options.setProxy(proxy); } Map<String, Object> prefs = Maps.newHashMap(); prefs.put("profile.default_content_settings.popups", 1); prefs.put("profile.default_content_setting_values.notifications", 1); options.setExperimentalOption("prefs", prefs); ChromeDriver webDriver = new ChromeDriver(options); Map<String, Object> params = Maps.newHashMap();// params.put("source", "Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"); params.put("source", "() => {" + " if (navigator.webdriver === false) {" + " continue" + " } else if (navigator.webdriver === undefined) {" + " continue" + " } else {" + " delete Object.getPrototypeOf(navigator).webdriver" + " }" + " }"); webDriver.executeCdpCommand("Page.addScriptToEvaluateOnNewDocument", params); webDriver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS).pageLoadTimeout(20, TimeUnit.SECONDS) .setScriptTimeout(10, TimeUnit.SECONDS); return webDriver; }}
上面具体到参数和配置,我们后续会进行详细解释,现在我们直接运行相关的代码获取https://www.cnblogs.com/的首页内容。
@Test public void testGrabPage() { WebDriver webDriver = null; try { String currentPageUrl = "https://xiaozhuanlan.com/"; webDriver = webDriverFactory.createWebDriver(false); webDriver.get(currentPageUrl); Thread.sleep(1000); String html = webDriver.getPageSource(); System.out.println(html); } catch (Exception e) { e.printStackTrace(); } finally { webDriver.quit(); } }
通过上面的代码,我们可以打印出博客园网站首页的全部信息。
第二部分:模拟用户行为
在上一个部分中,我们可以获取到“博客园”首页的完整内容,在这一篇文章中我们将实现在百度网站自动化搜索“博客园“,并且跳转到“博客园”首页。
在实现模拟登录之前,我们需要掌握如何定位到自己关心的元素。Selenium中有8种方法可以定位到元素。具体的定位方法可以查看org.openqa.selenium.By这个类。假设我们现在需要定位到如下一个元素:
<tagName attributeName='attributeValue'></tagName>
那么我们可以根据以下的方法进行定位:
- driver.findElement(By.name("attributeName"),根据元素的属性名称进行定位
- driver.findElement(By.tagName("tagName"),根据元素的名称来进行定位
- driver.findElement(By.xpath("tagName[@attributeName='attributeValue']")),根据元素的xpath表达式来进行定位
- driver.findElement(By.cssSelector("tagName[attributeName='attributeValue']")),根据元素的CSS选择器来进行定位
上述介绍的元素定位方法如果发现有多个元素可以匹配的,则会选择该页面中第一个符合条件的元素。
接下来,我们编写模拟用户搜索“博客园”行为的代码,
@Test public void searchTest() { FenbiChromeDriver webDriver = null; try { webDriver = (FenbiChromeDriver) webDriverFactory.createWebDriver(false); String currentPageURL = "http://www.baidu.com"; webDriver.get(currentPageURL); Thread.sleep(2000); WebElement searchInputElem = webDriver.findElement(By.xpath("//*[@id=\"kw\"]")); searchInputElem.sendKeys("博客园"); WebElement searchButtonElem = webDriver.findElement(By.xpath("//*[@id=\"su\"]")); searchButtonElem.click(); Thread.sleep(2000); WebElement searchResultList = webDriver.findElement(By.xpath("//*[@id=\"content_left\"]")); WebElement xiaozhuanlanElem = searchResultList.findElement(By.xpath("//*[@id=\"1\"]/div/div[1]/h3/a")); xiaozhuanlanElem.click(); Thread.sleep(2000); System.out.println(webDriver.getPageSource()); } catch (Exception e) { e.printStackTrace(); } finally { webDriver.quit(); } }
结合上一部分中的WebDriverFactory,并运行上面的代码,我们就可以自动跳转到博客园网站的首页了。
第三部分:判断元素是否加载完毕
当我们需要判断我们关注的元素是否加载完毕的时候,在Selenium框架下有隐式等待和显式等待两种方式。
隐式等待是在创建webdriver的时候设置的超时时间,在整个的webdriver生命周期内都是有效的。设置了隐式等待后,Selenium在执行findElement的DriverCommand时候会一直等待,直到获取到对应的元素。设置隐式等待的方法如下:
webDriver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS).pageLoadTimeout(20, TimeUnit.SECONDS).setScriptTimeout(10, TimeUnit.SECONDS);webDriver.findElement(By.xpath("//*[@id=\"kwddddd\"]"));
接下来,我们跟随Selenium的隐式等待模式来看看Selenium抓取网页的处理流程是什么样的。
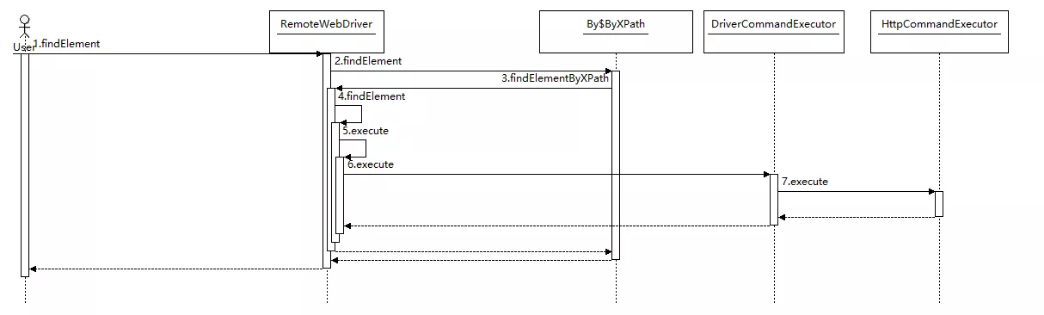
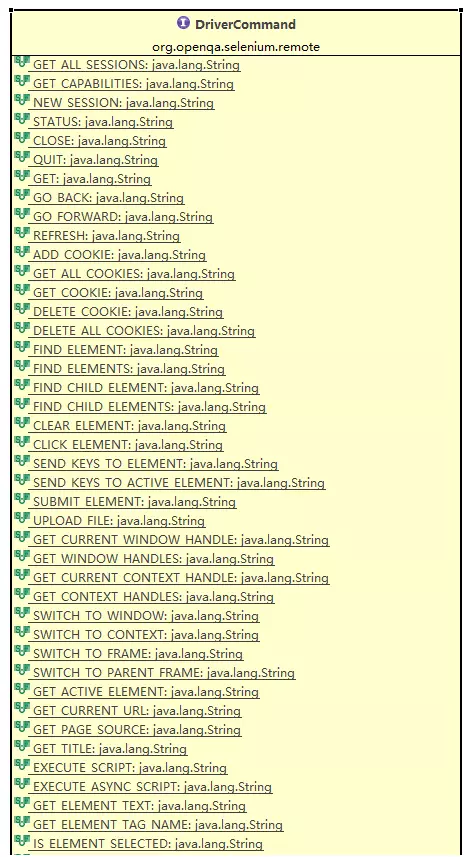
从上面的处理时序图我们可以看出,Selenium与webdriver的交互主要是通过RemoteWebDriver,DriverCommandExecutor和HttpCommandExecutor这三个类来完成的。另外一个比较重要的interface是DriverCommand,这个接口里面列举了webdriver支持的所有命令。
显示等待是使用WebDriverWait通过不断轮询的方式来完成的,示例代码如下所示,
@Test public void webDriverWaitTest() { FenbiChromeDriver webDriver = null; try { webDriver = (FenbiChromeDriver) webDriverFactory.createWebDriver(false); new WebDriverWait(webDriver, 20).until((Function<WebDriver, Boolean>) driver -> { String currentPageURL = "http://www.baidu.com"; driver.get(currentPageURL); String html = driver.getPageSource(); if(html.contains("hello word")) { return true; } else { return false; } }); } catch (Exception e) { e.printStackTrace(); } finally { webDriver.quit(); } }
显示等待的处理逻辑主要是在FluentWait类中的until方法中来完成的,默认情况下until方法会每隔500ms去执行Function实现类中的逻辑,检查执行结果是否为True,如果为True,则返回。如果为False,则sleep 500ms,直到结果为True,或者直到超时。

上面until方法的参数比较有意思,它需要是Function接口的实现类,范型接口Function<F, T>是google公司的开源组件Guava中的一个接口。这个接口只有一个内部方法apply,其中的F是apply方法的输入参数,T是apply方法的返回值。通过Function接口,Selenium就为WebDriverWait提供了一个很好的扩展点。我们在日常的开发中也可以借鉴这样的开发方法。
好了,今天就先和大家聊到这里吧,一个完善的爬虫还有很多其他的处理逻辑需要添加和处理。例如:如何应对反爬虫机制,如何实现用户的自动登录,如何对页面进行截图等等。感兴趣的小伙伴儿可以加我们的技术交流群或者加我的微信。


Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK