

技术基建如何降本增效——云迁移 - 叶小钗
source link: https://www.cnblogs.com/yexiaochai/p/16636896.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

技术基建如何降本增效——云迁移
原创不易,求分享、求一键三连
互联网寒冬大背景下,降本增效尤其是降本成了大部分公司的选择,我们公司也不例外,但显然困难很大!因为刚发生了团队合并行为...具体困难有以下几点:
- 两个团队初期规模300多人,当前两个APP同时维护,而后优化到不足100人;
- A团队使用腾讯云;B团队使用阿里云;
- A团队后端技术栈为Java;B团队后端技术栈是golang,还有部分php;
- A团队APP体系之前可能放弃治疗了,居然使用的是原生+Flutter+Hybrid;B团队使用的原生+RN;
- 前端体系Vue、React都在用...
这条船真的不好开!!!技术人员减少了,而服务规模未减少,在人员急剧减少的情况下需要研发侧从工程建设、团队管理、服务资源、需求控制等四方面进行降本增效的规划且同时还要稳固团队来保障业务稳定增长,所以在资源有限的情况下需要做什么,先做什么,后做什么?
这真的很难,不做是死,做也很难受,这里选择的答案是什么呢?
答案是:向钱看!因为腾讯对我们有技术投资,所以腾讯云非常非常便宜,为节约每年400万的阿里云研发费用,我们决定先将业务从阿里云迁移到腾讯云,也就有了云迁移这个项目。
整个云迁移项目耗时5个月,共53人参与(包含2位外包),涉及产品、开发、测试、工程、IT、客服、财务等多个团队和部门,涉及的云资源包含
- ECS 185台(共1511核);
- MySQL实例(含自建) 16个;
- Redis实例(含自建) 11个;
- MongoDB实例(含自建) 3个;
- ES(含自建)实例 4个;
- kafka集群2个;
整个项目耗时5个月(4月1日 - 8月31日),项目里程碑:
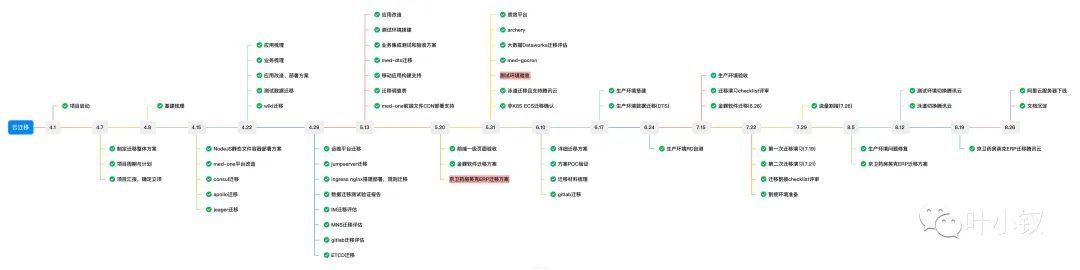
整个项目经历了:
- 项目调研立项->
- 基建平台迁移->
- 业务改造->
- 测试环境搭建->
- 生产环境搭建->
- 生产环境正式割接->
- 测试环境切换->
- 三方ERP系统迁移->
- 阿里云资源下线
共9个关键节点,期间组织了16次大型周会,整个项目进度和质量均符合预期,以下是一些实操经验,分享给大家。
- 是否需要外包
根据团队现状,没有任何一位研发过往有过云迁移的经历,同时团队在数据迁移这块缺乏经验,加上研发人力吃紧,最终决定与腾讯云云迁移外包团队合作,通过借鉴专业团队的经验来增加项目的成功率。
- 是否需要搭建测试环境
既然已经与外包团队合作了,为什么还需要搭建测试环境?目的是为了认知对齐,保证公司内部团队对云迁移整个事情有相对完整的认识和预期,提前识别项目中的一些关键风险点,毕竟外包团队只是有成熟的云迁移方法论,但不熟悉业务,迁移方案还是需要根据业务具体情况来制定实施。
- 目标是什么
出现问题在所难免,需要集中力量办大事。整个项目目标从一开始就很明确:保证迁移过程中,核心业务核心链路核心功能不出问题;并没有设定一个大而全的目标:保证迁移过程中,业务不出问题。
- 历史债务如何处理
在不影响项目交付的前提下,对一些技术债务、架构不合理的点,要及时优化,降低整套业务系统的熵;对于一些耗时耗力的债务,应果断放弃,不能过于增加云迁移项目本身的复杂度。
- 业务改造方案怎么定
涉及业务改动的点应足够少,影响范围足够小,这样能更好地控制项目进度,同时应准备好业务迁移改造指引文档,提高业务开发改造效率,同时保证业务稳定性。
云迁移项目整体复杂度高,需要层层拆解,化整为零,个个击破:

由于历史原因,阿里云集群规划不合理:经典网络与VPC并存,容器部署与ECS部署并存,生产集群安全组由于网段原因无法完全禁止外网访问数据库,安全性差,维护成本高。为保证安全性和架构统一,迁移腾讯云时,对集群和网络做了重新规划:
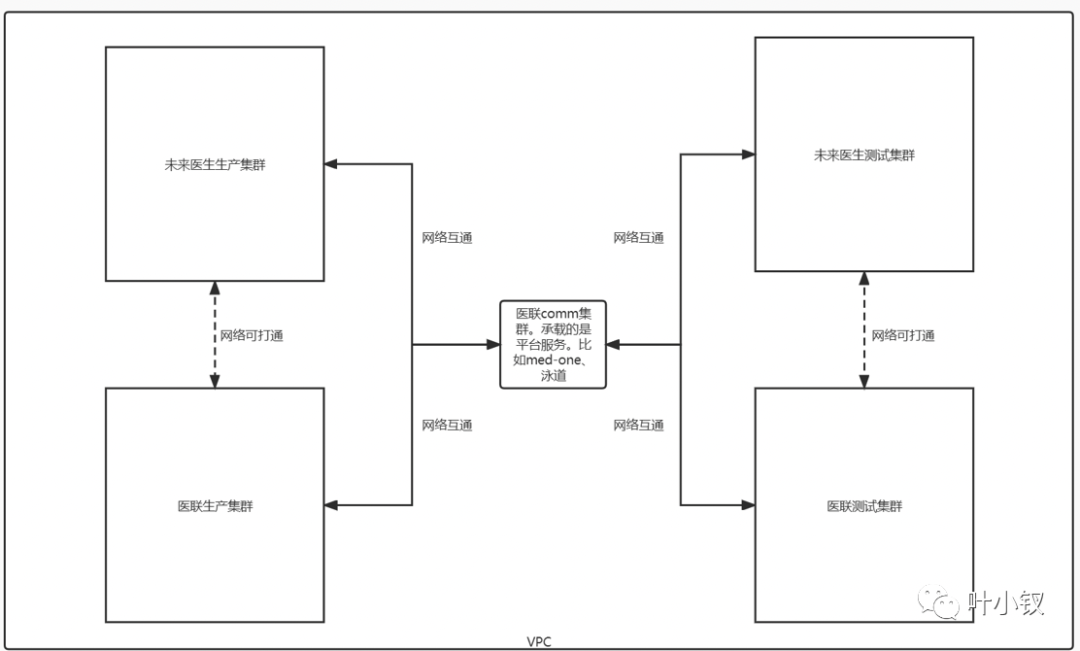
新集群统一使用Kubernetes作为基础设施,统一走容器化部署;集群也按基建、业务分别建了集群,清晰明了,互不影响。
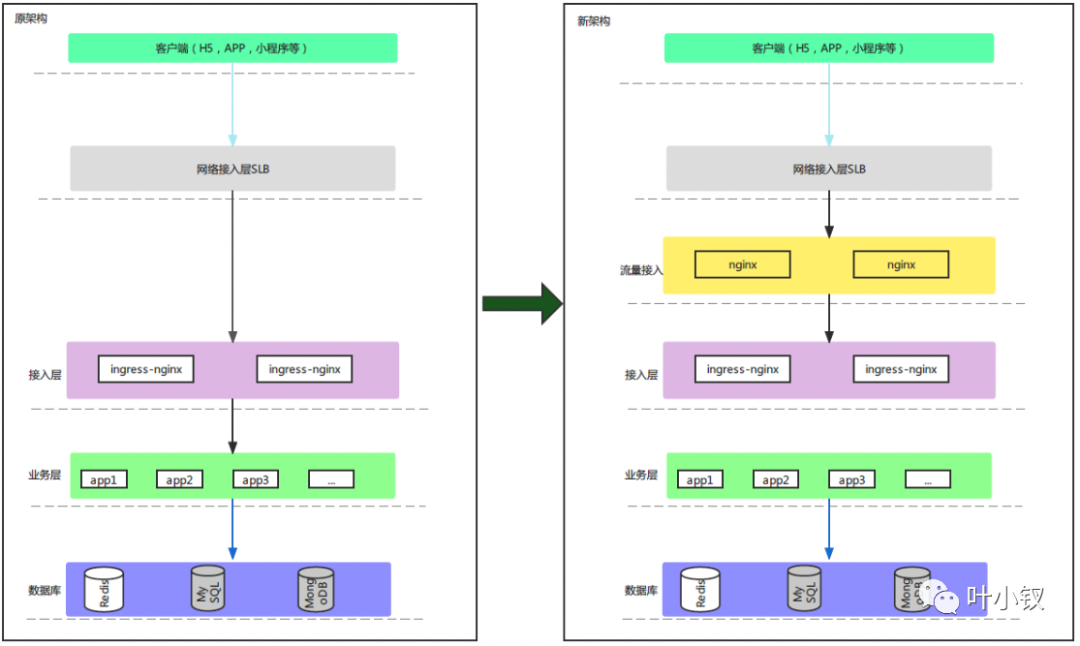
从Nginx到Kubernetes ingress
当前Nginx存在牵一发而动全身的问题,任何一项配置变更均为全局变更,有引发全站故障的风险。为保障业务的稳定性,使用Kubernetes ingress替代Nginx,路由配置变更从全局变更变为局部变更,从而降低风险。当然,ingress与Nginx存在兼容性问题,需要业务来配合调整部署方案。
前端静态文件容器化部署
当前前端静态文件是通过NAS挂载的方式与Nginx联动,使得Nginx变成有状态应用。当前架构:
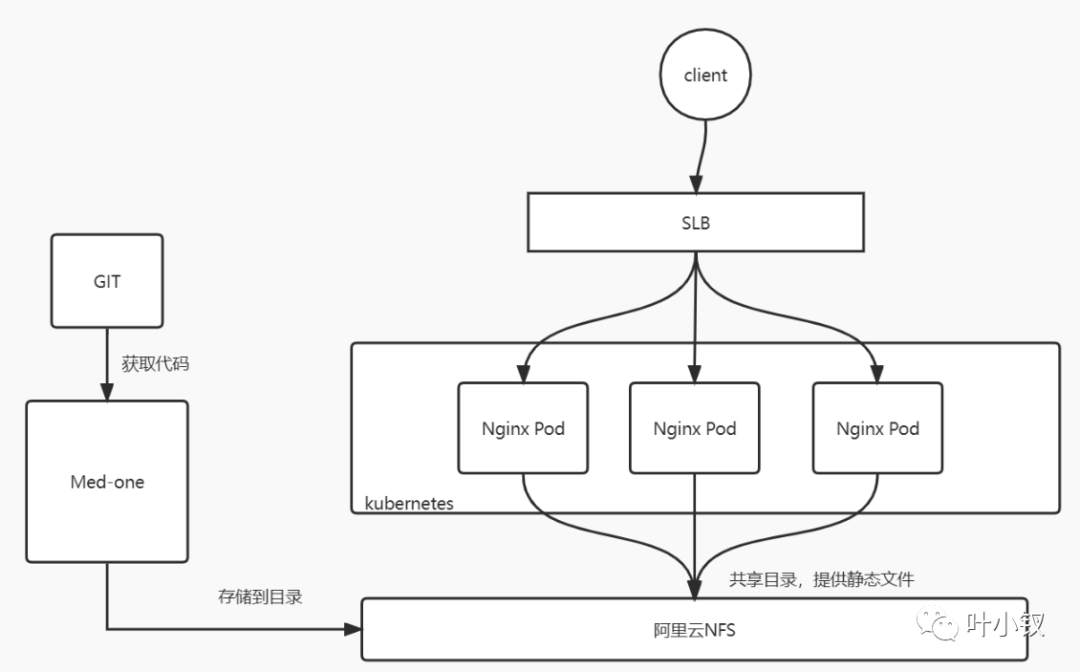
由于ingress是无状态的,且不支持挂载目录的方式,同时为了保证架构统一,将前端静态文件部署改为容器化部署,新架构:
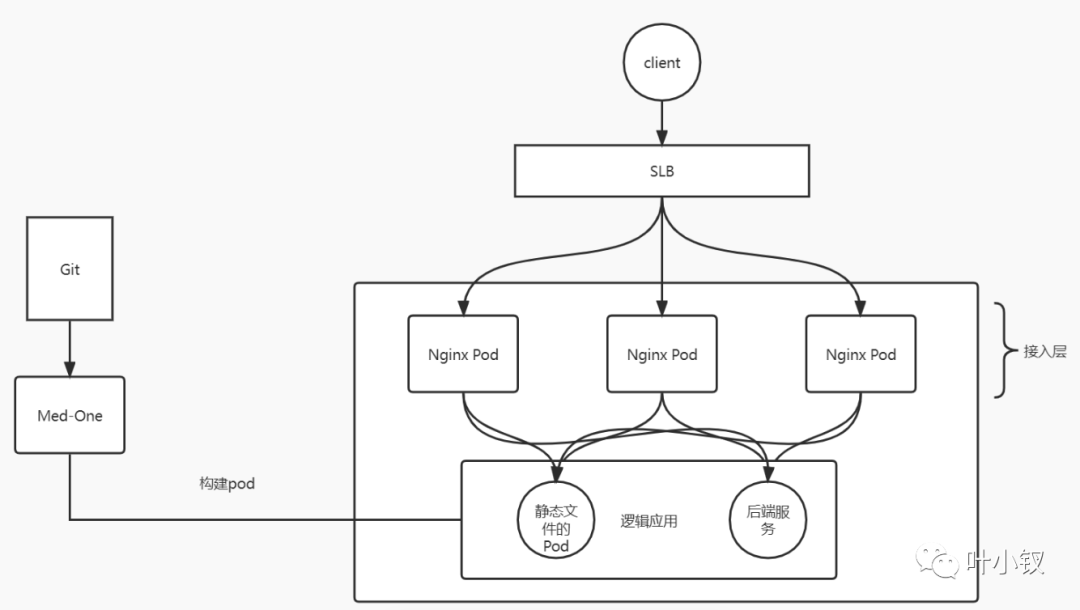
新架构统一了前后端应用部署方式,架构变得更加简洁统一,维护成本降低。
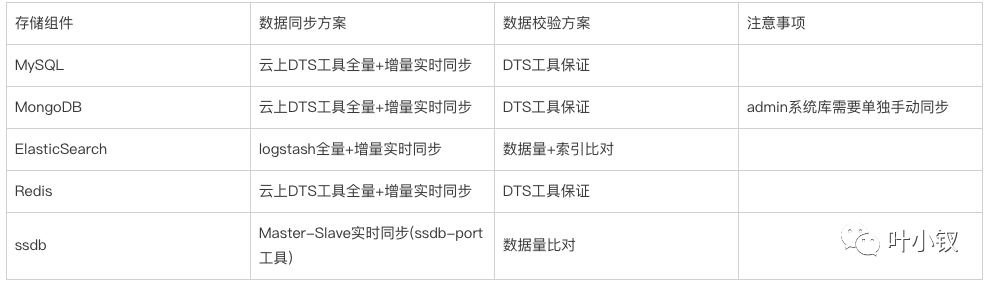
数据迁移最关键的是保证数据的完整性与一致性,这里均采用业界成熟的数据实时同步方案来完成数据迁移:
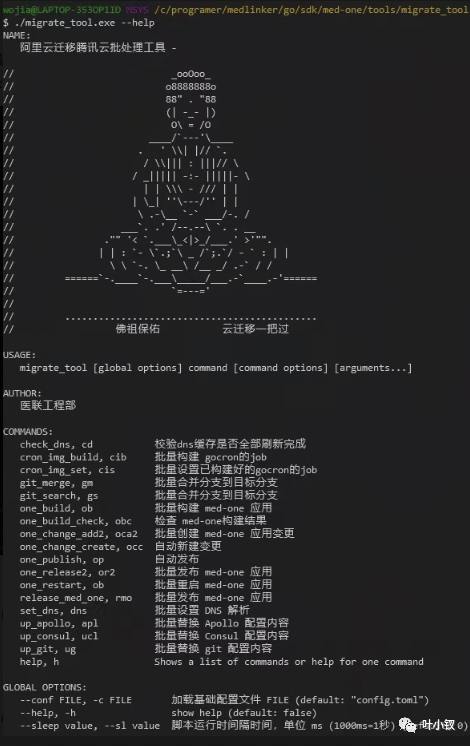
自动化工具
云迁移涉及很多批量操作,包括批量构建、批量发布、批量修改配置、批量重启、批量切换DNS等,为保证迁移的效率和操作的稳定性,所有批量操作都工具化,下图是小伙伴批跑的工具集:
部署标准化
代码、CI配置、CD配置分离,Dockerfile、启动脚本(start.sh)交由DevOps平台管理,标准化、易维护。
MNS更换为CMQMNS是阿里云专有的消息中间件,支付中心有使用,为了保证业务改动量最小,采用了腾讯云对标的消息中间件CMQ,仅支付中心改造,业务调用服务修改配置即可
med-dts应用迁移业务侧有直接使用DTS数据订阅进行消费的链路,由于阿里云与腾讯云DTS订阅服务数据协议的差异,对应的消费者应用med-dts需要做协议适配改造
业务配置迁移由于历史原因,配置中心有两套:consul + git仓库;apollo配置中心。业务配置迁移之后涉及数据库等配置的修改,而且需要考虑批量更新配置。对于consul + git仓库的配置中心,采用git patch的方式保证配置的准确性;对于apollo配置中心,采用批量替换工具全量替换的方式保证准确性
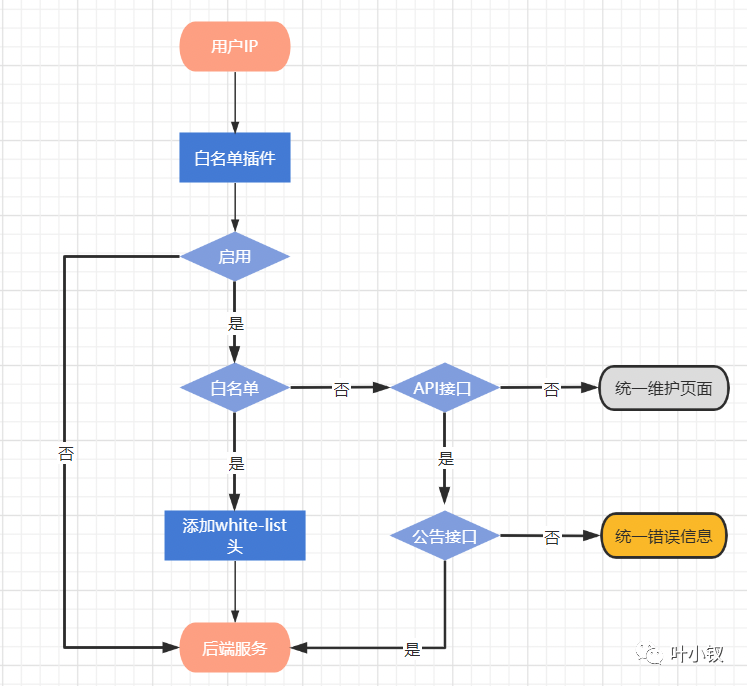
业务停服公告
迁移割接采用停服的方式进行迁移,需要提前公告通知;同时,停服进行业务验证期间,只允许办公网流量和供应商回调的流量进入系统,需要提供IP白名单功能。这里在架构上增加一层代理层,做白名单控制:
第三方供应商测试方案
做生产环境无自然流量业务验收时,整套生产环境的架构变成两套生产环境(腾讯云、阿里云)对接一套供应商生产环境,医联和供应商的数据一致性、接口回调均有问题:腾讯云发起的测试订单在阿里云侧没有、供应商的订单回调也只会回调到阿里云生产。该场景主要涉及订单中心、支付中心,解决方案:
- 订单库订单表自增id跳id 1000万,用于区分不同云环境订单,有业务逻辑依赖自增id。若需要多次测试,则每次订单数据都需要备份,且订单库订单表自增id每次都需要跳id 1000万
- 支付中心直接从腾讯云导入测试的支付单数据即可,不依赖自增id。若需要多次测试,则每次支付数据都需要备份
- 正式流量割接前,备份业务验收的测试订单、支付数据,割接成功后再导入数据库
生产快速验收方案
生产环境流量割接需要在天窗时间进行,并向业务方承诺8小时内(23:00 - 7:00)完成割接,需要制定割接后的业务快速验收方案,由QA团队负责制定与执行:
云上Redis Cluster版本特性差异导致自研延时队列无法回调业务
阿里云与腾讯云的Redis Cluster多分片(8分片)版本存在命令不兼容的情况,延时队列有使用MULTI; SET a b; SET b c;EXEC命令,在腾讯云上命令无法执行,阿里云可正常执行。详见官方文档:Redis不同版本兼容命令列表。定位到问题原因后,将Redis Cluster更换为标准架构版本,问题解决
部署方式差异,导致延时队列重启后无法处理重启前的数据
将延时队列从StatefulSets部署变为Deployments部署(方便平台维护),重启后发现延时队列无法load存量的延时任务,经过排查,发现延时队列的Redis SortedSet名依赖了Pod Name,当作为Deployment部署时,每次重启Pod Name就会发生变化,进而无法从Redis load存量的延时任务。解决方案:
- 合并所有SortedSet的数据到SortedSet 0和1(两个实例)
- 将延时队列改为StatefulSets部署,保证Pod Name不会因重启发生变化
不太稳定的腾讯云DTS,导致割接延期
腾讯云MongoDB DTS数据同步过程中发生过MongoDB主从切换导致DTS同步失败、CPU负载过高导致DTS进程僵死的问题,不够稳定,导致正式割接延期一天。出现问题后,紧急拉腾讯云开发来支持解决问题,通过升配 + 增大DTS同步并发数,快速将数据同步完成。
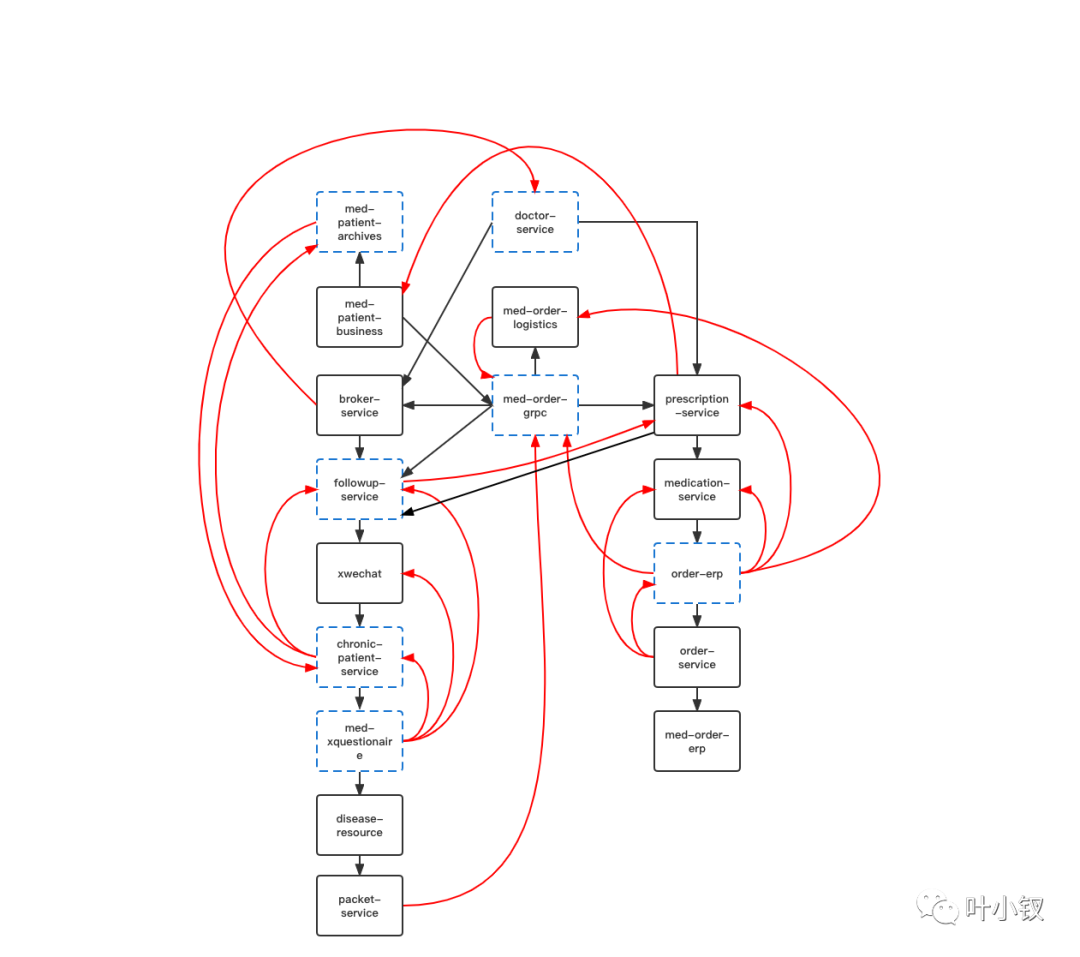
令人无奈的循环依赖
批量部署应用时,发现很多应用存在循环依赖导致应用无法启动成功,需要修改代码,无奈,只能一个个解决,解环。图中蓝色虚框即表示修改过的服务:
虽然割接方案也来来回回评审了3次,割接演习了两次,演习过程也挺顺利,但正式割接时,还是出了一些突发状况,包括DTS数据订阅创建失败(kafka topic资源割接时达到上限)、DNS域名解析切换全网生效时长超过演习时、代理白名单机制遗漏CMQ公网IP等问题。这些问题在割接过程中引起了一些小波澜,但都非阻塞性问题,快速解决后,最终生产割接在承诺时间内顺利完成:

- 高效决策环境
项目参与人员过多时,很难保证信息同步和透明。为保证项目快速推进和决策,需要组建一个核心决策团队,包含各合作团队负责人、项目核心成员,项目所有关键信息都需要在团队及时同步,有问题共同快速协商、决策、解决。
- 去中心化决策
目标一致的前提下,寻找合作者,而非执行者,实行"我们一起干,共同把项目做成"的王道,而非"你来配合我做这做那"的霸道;
不影响目标和进度的前提下,尽可能满足合作方诉求,调动积极性;尊重人性,尊重不同的声音,站在同一目标下理性讨论方案;决策权下放,每个人熟悉掌握的领域有限,要把具体的任务项给最合适的人去决策执行,项目负责人控制好进度和风险即可。
- 高效执行团队
除了高效决策,高效执行也是必需的。组建一支短小精悍的执行团队,可以保证方案的试验、问题的解决都能快速落地。同时,快速的阶段性成功反馈可大大增加核心成员对于项目推进的信心,减少项目推进的阻力,保证项目更平稳地推进下去。
- 项目决策者、赞助者、执行者保持充分沟通
项目推行过程中,出现了项目人力与业务需求人力冲突和封板通知未及时同步到产品负责人的情况,导致业务推进过程中出现了被动的局面。
作为项目负责人(执行者),应该定时与部门领导(决策者、赞助者)保持沟通,同步风险;也能提前争取到部门领导对外的支持与协调,获取业务部门反馈,及时调整策略,避免出现被动局面,保证项目稳定有序推进。
- 拆解目标,化整为零
整个项目复杂度高,周期长。需要拆解总体目标,不断交付阶段性目标,持续反馈和调整,形成正循环。
- 提前和云厂商团队沟通,获取专人支持
云迁移涉及公司所有业务,通常复杂度都会比较高,割接前提前与云厂商沟通,争取专人支持,可快速解决云上的一些问题,提高迁移成功率和效率。
- 外包虽好,但不可过度依赖
云迁移外包团队丰富的云迁移经验可以帮助团队少走很多弯路,但外包团队不熟悉公司业务,项目的整体计划和方案还是需要公司内部团队来主导和把控,这样可以减少迁移问题和风险。
- 预留演习的时间
正式割接前,一定要演习,最好演习2-3次,增加割接操作的熟练与稳定,期间暴露的问题也可以提前解决,做割接方案的最后补足。
- 项目阶段性任务延期
关注延期风险,延期任务对项目目标的影响,如果影响不大或者无影响,可以先舍弃,优先保证目标按期达成。
- 项目复盘
不管项目成功还是失败,都应做好复盘,从项目各个角色、各个岗位,思考总结提升大型架构活动成功率的方法论,好的经验需要沉淀下来改进流程,甚至改进文化;不好的应及时纠正,防止下次出错。
- 谨慎造轮子
对于业务在云上的公司,应尽量使用云上的基础组件,对于造轮子保持克制与谨慎的态度,组织架构变动、人员离职都很有可能让轮子无人维护,一旦出问题很可能就是大问题。
- 持续解决重要不紧急问题
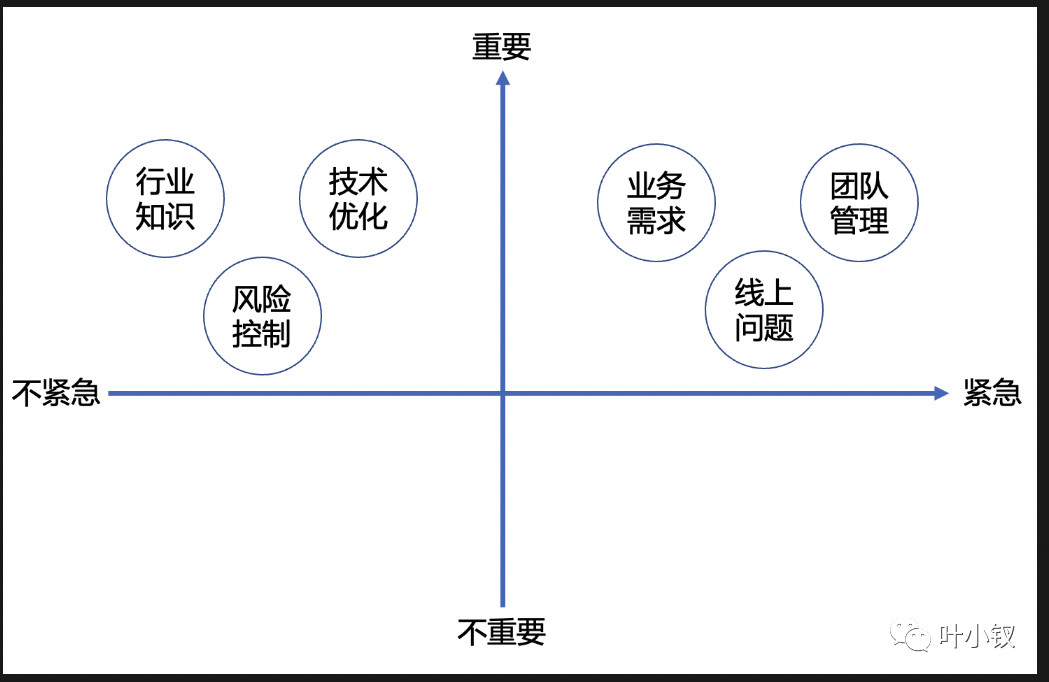
优秀的技术管理者需要时刻与系统熵增做斗争,将系统的熵控制在一定范围,持续关注第二象限的事,积极修炼"内功"。做好第一象限是本职,做好第二象限方显功力。
好了,今天的分享就到这。如果本文对你有帮助的话,欢迎点赞&评论&在看&分享,这对我非常重要,感谢🙏🏻。
想要更多交流可以加我微信:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK