

ClickHouse与Elasticsearch压测实践 - 京东云开发者
source link: https://www.cnblogs.com/Jcloud/p/16635096.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

1 需求分析
1.1 分析压测对象
1)什么是ClickHouse 和Elasticsearch
ClickHouse 是一个真正的列式数据库管理系统(DBMS)。在 ClickHouse 中,数据始终是按列存储的,包括矢量(向量或列块)执行的过程。只要有可能,操作都是基于矢量进行分派的,而不是单个的值,这被称为«矢量化查询执行»,它有利于降低实际的数据处理开销。
Elasticsearch是一个开源的分布式、RESTful 风格的搜索和数据分析引擎,它的底层是开源库Apache Lucene。 它可以被这样准确地形容:
- 一个分布式的实时文档存储,每个字段可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
2)为什么要对他们进行压测
众所周知,ClickHouse在基本场景表现非常优秀,性能优于ES,但是我们实际的业务查询中有很多是复杂的业务查询场景,甚至是大数量的查询,所以为了在双十一业务峰值来到前,确保大促活动峰值业务稳定性,针对ClickHouse 和Elasticsearch在我们实际业务场景中是否拥有优秀的抗压能力,通过这次性能压测,探测系统中的性能瓶颈点,进行针对性优化,从而提升系统性能。
1.2 制定压测目标

为什么会选择这个(queryOBBacklogData)接口呢?
1)从复杂度来看,接口(queryOBBacklogData)查询了5次,代码如下:
/*** 切ck-queryOBBacklogData* @param queryBO* @return*/public OutboundBacklogRespBO queryOBBacklogDataCKNew(OutboundBacklogQueryBO queryBO) {log.info(" queryOBBacklogDataCK入参:{}", JSON.toJSONString(queryBO));// 公共条件-卡最近十天时间String commonStartTime = DateUtils.getTime(DateUtil.format(new Date(), DateUtil.FORMAT_DATE), DateUtils.ELEVEN_AM, 1, -10);String commonEndTime = DateUtils.getTime(DateUtil.format(new Date(), DateUtil.FORMAT_DATE), DateUtils.ELEVEN_AM, 1, 1);// 越库信息-待越库件数&待越库任务数WmsObCrossDockQueryBo wmsObCrossDockQueryBo = wmsObCrossDockQueryBoBuilder(queryBO,commonStartTime, commonEndTime);log.info("queryOBBacklogDataCK-wmsObCrossDockQueryBo: {}", JSON.toJSONString(wmsObCrossDockQueryBo));CompletableFuture<OutboundBacklogRespBO> preCrossDockInfoCF = CompletableFuture.supplyAsync(() -> wmsObCrossDockMapper.preCrossDockInfo(wmsObCrossDockQueryBo), executor);// 集合任务信息-待分配订单WmsObAssignOrderQueryBo wmsObAssignOrderQueryBo = wmsObAssignOrderQueryBoBuilder(queryBO, commonStartTime, commonEndTime);log.info("queryOBBacklogDataCK-wmsObAssignOrderQueryBo: {}", JSON.toJSONString(wmsObAssignOrderQueryBo));CompletableFuture<Integer> preAssignOrderQtyCF = CompletableFuture.supplyAsync(() -> wmsObAssignOrderMapper.preAssignOrderInfo(wmsObAssignOrderQueryBo), executor);// 拣货信息-待拣货件数&待拣货任务数WmsPickTaskQueryBo wmsPickTaskQueryBo = wmsPickTaskQueryBoBuilder(queryBO, commonStartTime, commonEndTime);log.info("queryOBBacklogDataCK-wmsPickTaskQueryBo: {}", JSON.toJSONString(wmsPickTaskQueryBo));CompletableFuture<OutboundBacklogRespBO> prePickingInfoCF = CompletableFuture.supplyAsync(() -> wmsPickTaskMapper.pickTaskInfo(wmsPickTaskQueryBo), executor);// 分播信息-待分播件数&待分播任务WmsCheckTaskDetailQueryBo wmsCheckTaskDetailQueryBo = wmsCheckTaskDetailQueryBoBuilder(queryBO, commonStartTime, commonEndTime);log.info("queryOBBacklogDataCK-wmsCheckTaskDetailQueryBo: {}", JSON.toJSONString(wmsCheckTaskDetailQueryBo));CompletableFuture<OutboundBacklogRespBO> preSowInfoCF = CompletableFuture.supplyAsync(() -> wmsCheckTaskDetailMapper.checkTaskDetailInfo(wmsCheckTaskDetailQueryBo), executor);// 发货信息-待发货件数WmsOrderSkuQueryBo wmsOrderSkuQueryBo = wmsOrderSkuQueryBoBuilder(queryBO, commonStartTime, commonEndTime);log.info("queryOBBacklogDataCK-wmsOrderSkuQueryBo: {}", JSON.toJSONString(wmsOrderSkuQueryBo));CompletableFuture<Integer> preDispatchCF = CompletableFuture.supplyAsync(() -> wmsOrderSkuMapper.preDispatchInfo(wmsOrderSkuQueryBo), executor);return processResult(preCrossDockInfoCF, preAssignOrderQtyCF, prePickingInfoCF, preSowInfoCF, preDispatchCF);} |
2)接口(queryOBBacklogData),总共查询了5个表,如下:
wms.wms_ob_cross_dock wms.wms_ob_assign_order wms.wms_picking_task. wms.wms_check_task_detail wms.wms_order_sku
3)查询的数据量,如下:
select (ifnull(sum(m.shouldBeCrossedDockQty), 0) - ifnull(sum(m.satisfiedCrossedDockQty), 0)) as preCrossStockSkuQty, count(m.docId) as preCrossStockTaskQty from wms.wms_ob_cross_dock m final prewhere m.createTime >= '2021-12-03 11:00:00' and m.createTime <= '2021-12-14 11:00:00' and m.warehouseNo = '279_1' and m.orderType = '10' and tenantCode = 'TC90230202' where m.deleted = 0 and m.deliveryDestination = '2' and m.shipmentOrderDeleted = 0 and m.status = 0

从上面SQL截图可以看出,查询待越库件数&待越库任务数,共读了720817行数据
select count(distinct m.orderNo) as preAssignedOrderQty from wms.wms_ob_assign_order m final prewhere m.createTime >= '2021-12-03 11:00:00' and m.createTime <= '2021-12-14 11:00:00' and m.warehouseNo = '361_0' and tenantCode = 'TC90230202' where m.taskassignStatus = 0 and m.deliveryDestination = 2 and m.stopProductionFlag = 0 and m.deleted = 0 and m.orderType = 10

从上面SQL截图可以看出,查询集合任务信息-待分配订单,共读了153118行数据
select minus(toInt32(ifnull(sum(m.locateQty), toDecimal64(0, 4))), toInt32(ifnull(sum(m.pickedQty), toDecimal64(0, 4)))) as prePickingSkuQty, count(distinct m.taskNo) as prePickingTaskQty from wms.wms_picking_task m final prewhere m.shipmentOrderCreateTime >= '2021-12-03 11:00:00' and m.shipmentOrderCreateTime <= '2021-12-14 11:00:00' and m.warehouseNo = '286_1' and tenantCode = 'TC90230202' where m.pickingTaskDeleted = 0 and m.deliveryDestination = 2 and m.pickLocalDetailDeleted = 0 and m.shipmentOrderDeleted = 0 and m.orderType = 10 and (m.operateStatus = 0 or m.operateStatus = 1)

从上面SQL截图可以看出,查询拣货信息-待拣货件数&待拣货任务数,共读了2673536行数据
select minus(toInt32(ifnull(sum(m.locateQty), toDecimal64(0, 4))), toInt32(ifnull(sum(m.pickedQty), toDecimal64(0, 4)))) as prePickingSkuQty, count(distinct m.taskNo) as prePickingTaskQty from wms.wms_picking_task m final prewhere m.shipmentOrderCreateTime >= '2021-12-03 11:00:00' and m.shipmentOrderCreateTime <= '2021-12-14 11:00:00' and m.warehouseNo = '279_1' and tenantCode = 'TC90230202' where m.pickingTaskDeleted = 0 and m.deliveryDestination = 2 and m.pickLocalDetailDeleted = 0 and m.shipmentOrderDeleted = 0 and m.orderType = 10 and (m.operateStatus = 0 or m.operateStatus = 1)

从上面SQL截图可以看出,查询分播信息-待分播件数&待分播任务,共读了1448149行数据
select ifnull(sum(m.unTrackQty), 0) as unTrackQty
from wms.wms_order_sku m final
prewhere
m.shipmentOrderCreateTime >= '2021-12-03 11:00:00'
and m.shipmentOrderCreateTime <= '2021-12-14 11:00:00'
and m.warehouseNo = '280_1'
and m.orderType = '10'
and m.deliveryDestination = '2'
and tenantCode = 'TC90230202'
where m.shipmentOrderDeleted <> '1'
and m.ckDeliveryTaskDeleted <> '1'
and m.ckDeliveryTaskDetailDeleted <> '1'
and m.ckDeliveryTaskStatus in ('1','0','2')

从上面SQL截图可以看出,查询发货信息-待发货件数,共读了99591行数据
2 测试环境准备
为了尽可能发挥性能压测作用,性能压测环境应当尽可能同线上环境一致,所以我们使用了和线上一样的环境
3 采集工具准备
- http://origin.jd.com/ :监控JVM,方法级别监控(提供秒级支持)
- http://console.jex.jd.com/ :提供异常堆栈监控,火焰图监控、线程堆栈分析
- http://x.devops.jdcloud.com/ :支持查看clickhouse/Elasticsearch数据库服务每个节点的cpu使用率
- http://dashboard.fireeye.jdl.cn/ :监测应用服务器cpu使用率、内存使用率
4 压测执行及结果分析
4.1 编写压测脚本工具
Forcebot(http://forcebot.jd.com) 是专门为开发人员、测试人员提供的性能测试平台,通过编写脚本、配置监控、设置场景、启动任务、实时监控、日志定位、导出报告一系列操作流程来完成性能测试,灵活的脚本配置满足同步、异步、集合点等多种发压模式。
帮助文档(http://doc.jd.com/forcebot/helper/)
4.2 设计压测数据
4.2.1 前期压测中名词解释
- DBCP:数据库连接池,是 apache 上的一个Java连接池项目。DBCP通过连接池预先同数据库建立一些连接放在内存中(即连接池中),应用程序需要建立数据库连接时直接到从接池中申请一个连接使用,用完后由连接池回收该连接,从而达到连接复用,减少资源消耗的目的。
- maxTotal:是连接池中总连接的最大数量,默认值8
- max_thread:clickhouse中底层配置,处理SQL请求时使用的最大线程数。默认值是clickhouse服务器的核心数量。
- coordinating:协调节点数,主要作用于请求转发,请求响应处理等轻量级操作
- 数据节点:主要是存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等。数据节点对cpu,内存,io要求较高, 在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点
4.2.2 压测数据
clickhouse数据服务:32C128G6节点2副本
应用服务器:4核8G2
maxTotal=16
注:每次压测前,一定要观察每个数据节点的cpu使用率
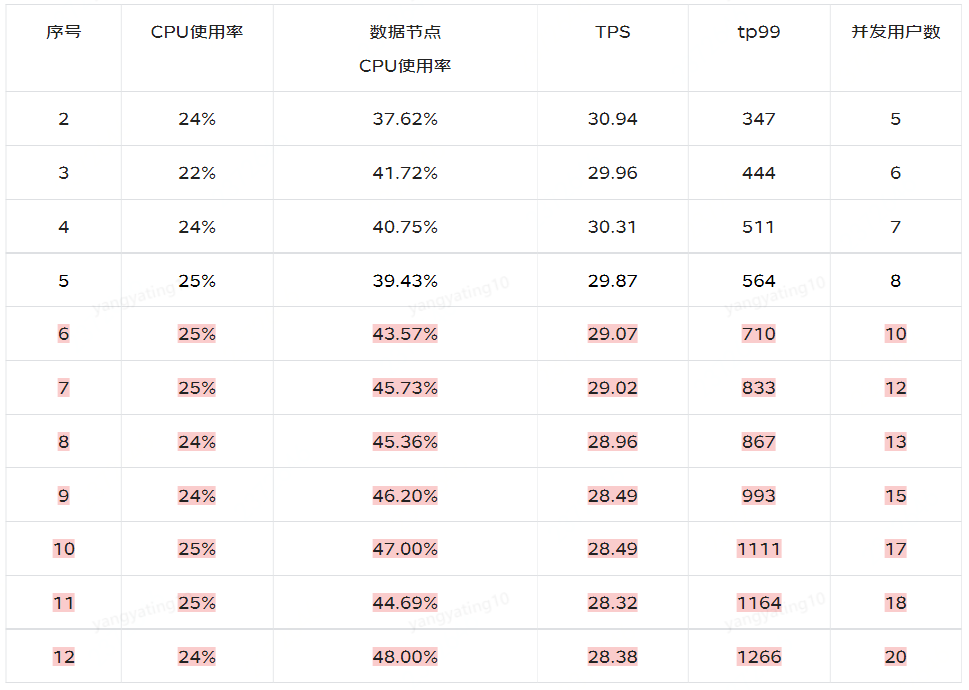
注:从上面压测过程中,序号6-12可以看出,并发用户数在增加,但tps没有幅度变化,检查发现bigdata dbcp数据库链接池最大线程数未配置,默认最大线程数是8,并发用户数增加至8以后,clickhouse cpu稳定在40%~50%之间不再增加,应用服务器CPU稳定在25%左右。
之后我们调整maxTotal=50,通过调整max_thread不同的值,数据库节点CPU使用率保持在50%左右,来查看相应的监测数据指标:应用服务CPU使用率、TPS、TP99、并发用户数。
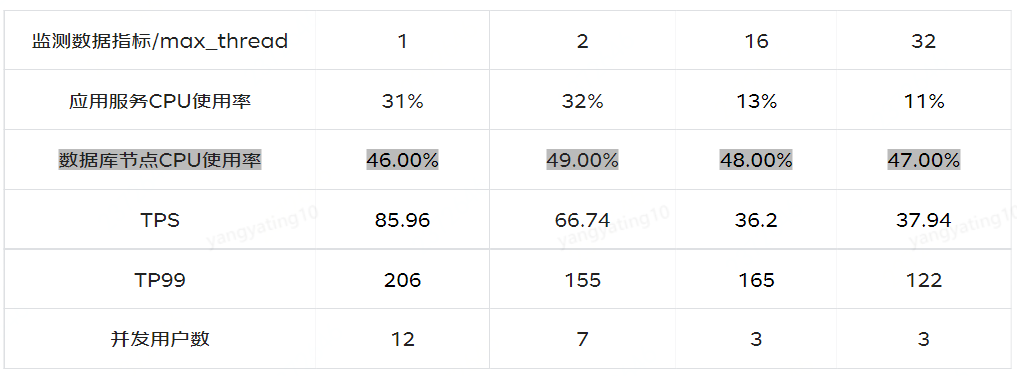
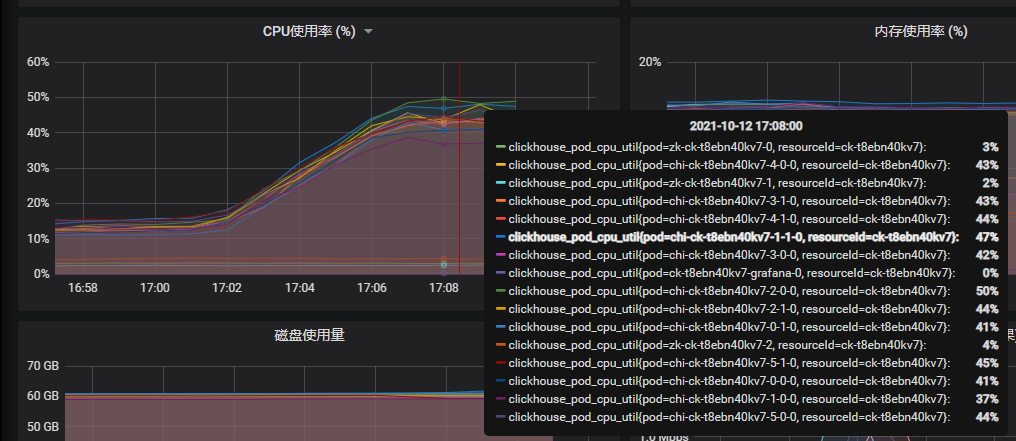
clickhouse数据节点,CPU使用率:
Elasticsearch数据服务:32C128G6节点2副本
应用服务器:4核8G2
Elasticsearch同样保持数据库服务CPU使用率达到(50%左右),再监控数据指标tps、tp99
调整指标如下:coordinating协调节点数、 数据节点、poolSize
指标1:coordinating=2,数据节点=4,poolSize=400

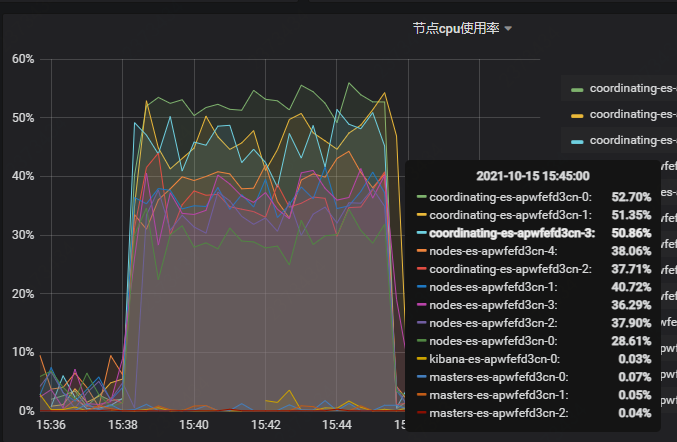
注:在压测的过程中发现,coordinating节点的cpu使用率达到51.69%,负载均衡的作用受限,所以协调节点需扩容2个节点
指标2:coordinating=4,数据节点=5,poolSize=800

注:在压测的过程中,发现CPU使用率(数据库)ES数据节点在40%左右的时候,一直上不去,查看日志发现activeCount已经达到797,需要增加poolSize值
指标3:coordinating=4,数据节点=5,poolSize=1200

注:压测过程中,发现coordinating协调节点还是需要扩容,不能支持现在数据节点cpu使用率达到50%
Elasticsearch数据节点及协调节点,CPU使用率:
我们在压测的过程中发现一些之前在开发过程中没发现的问题,首先bdcp数bigdata应用服务器,使用的线程池最大线程数为8时,成为瓶颈,用户数增加至8以后, clickhouse的cpu稳定在40%~50%之间不在增加,应用服务器CPU稳定在25%左右,其次warehouse集群协调节点配置低,协调节点CPU使用率高,最后是clickhouse-jdbc JavaCC解析sql效率低。
4.3 结果分析
4.3.1 测试结论
1)clickhouse对并发有一定的支持,并不是不支持高并发,可以通过调整max_thread提高并发
- max_thread=32时,支持最大TPS 是37,相应TP99是122
- max_thread=2时,支持最大TPS 是66,相应TP99是155
- max_thread=1时,支持最大TPS 是86,相应TP99是206
2)在并发方面Elasticsearch比clickhouse支持的更好,但是相应的响应速度慢很多
- Elasticsearch:对应的TPS是192,TP99是3050
- clickhouse:对应的TPS 是86,TP99是206
综合考量,我们认为clickhouse足以支撑我们的业务诉求
4.3.2 优化建议
- 对ES协调节点进行扩容
- bigdata应用线程池最大线程数调高至200
- bigdata应用 dbcp线程池maxTotal设置成50
- 读取配置文件工具类增加内存缓存
作者:潘雪艳
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK